![]()
Mathematics is a peer-reviewed, open-access journal that provides an advanced forum for studies related to mathematics. It is published online by MDPI semimonthly. The European Society for Fuzzy Logic and Technology (EUSFLAT) and the International Society for the Study of Information (IS4SI) are affiliated with Mathematics, and their members receive a discount on article processing charges.
- Open Access— free for readers, with article processing charges (APC) paid by authors or their institutions.
- High Visibility: indexed within Scopus, SCIE (Web of Science), RePEc, and other databases.
- Journal Rank: JCR – Q1 (Mathematics) / CiteScore – Q1 (General Mathematics)
- Rapid Publication: manuscripts are peer-reviewed, and a first decision is provided to authors approximately 16.9 days after submission; acceptance to publication is undertaken in 2.6 days (median values for papers published in this journal in the second half of 2023).
- Recognition of Reviewers: reviewers who provide timely, thorough peer-review reports receive vouchers entitling them to a discount on the APC of their next publication in any MDPI journal in appreciation of the work done.
- Sections: published in 13 topical sections.
- Companion journals for Mathematics include: Foundations, AppliedMath, Analytics, International Journal of Topology, Geometry and Logics.
Impact Factor: JCR – Q1 (Mathematics) / CiteScore – Q1 (General Mathematics)
Special Issue: Multi-Objective Optimization: Theory, Methods, and Applications
A special issue of Mathematics (ISSN 2227-7390). This special issue belongs to the section «E: Applied Mathematics«.
Deadline for manuscript submissions: 28 February 2027

Special Issue Editors
Interests: multiobjective optimization; structures optimization; lifecycle assessment; social sustainability of infrastructures; reliability-based maintenance optimization; optimization and decision-making under uncertainty
Special Issues, Collections and Topics in MDPI journals
Interests: structural analysis; optimization; engineering optimization; linear programming; mathematical programming; heuristics; structural optimization; concrete; combinatorial optimization; structural engineering; multiobjective optimization; reinforced concrete; optimization methods; discrete optimization; optimization theory; optimization software
Special Issues, Collections and Topics in MDPI journals
Interests: optimization; deep learning; operations research; artificial intelligence applications to industrial problems
Special Issues, Collections and Topics in MDPI journals
Special Issue Information
Dear Colleagues,
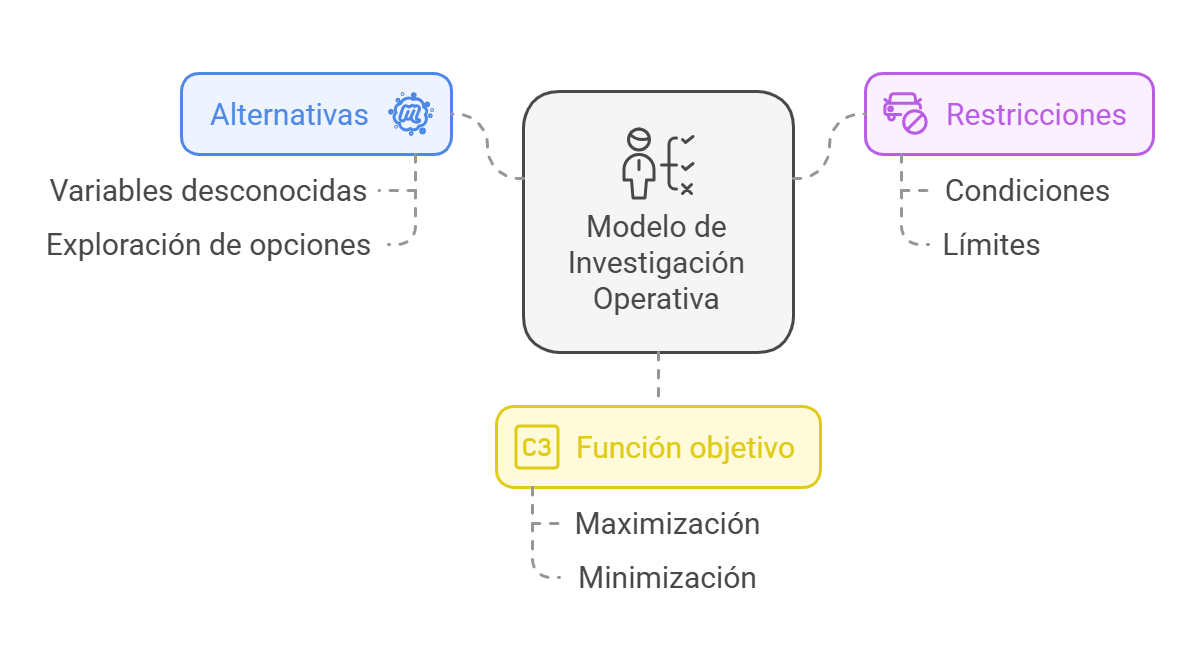
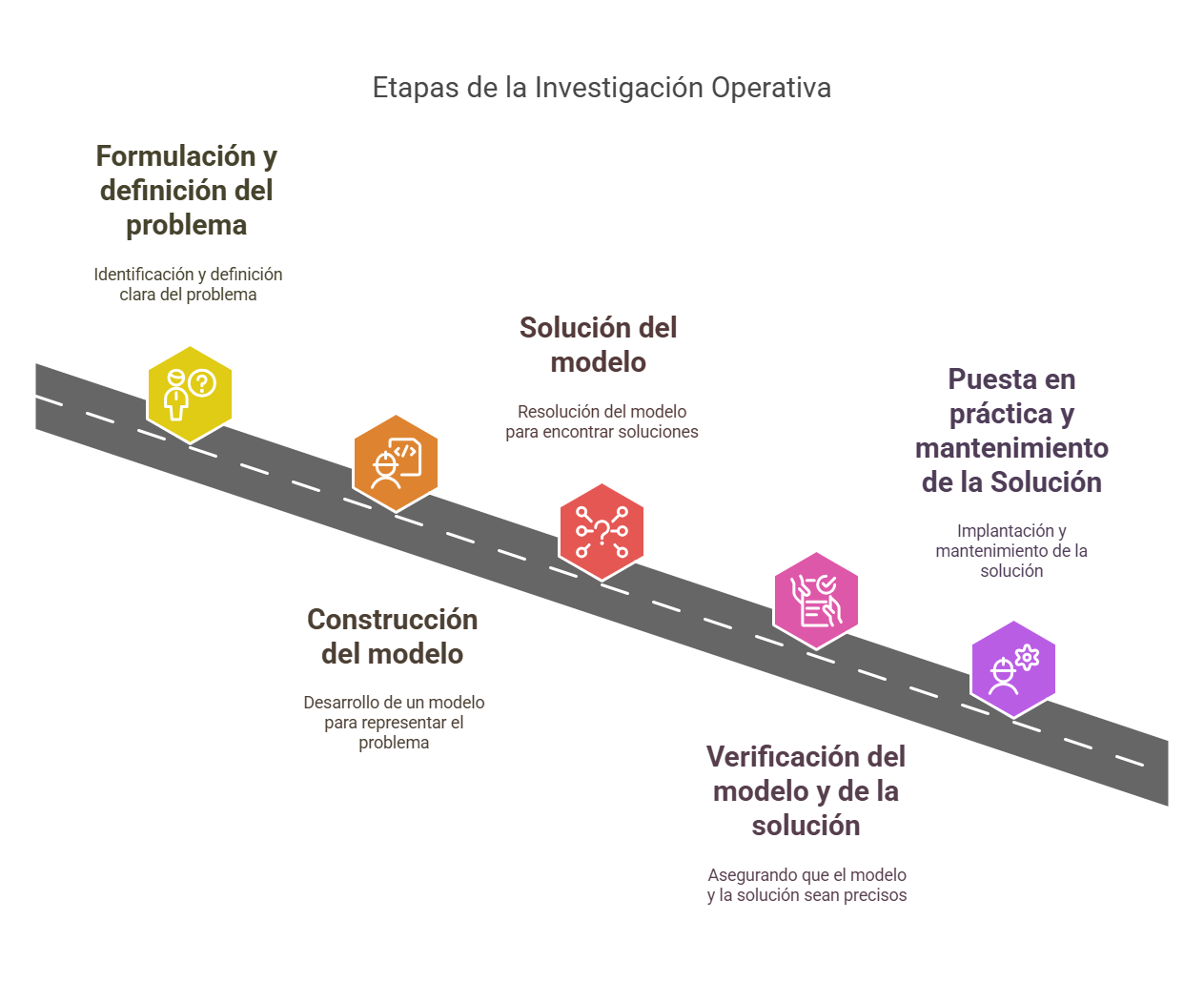
As a result of increased competitiveness driven by globalization, the use of optimization techniques has increased in recent decades. With the development of new methods and the greater availability of computer resources, applications across the most diverse fields of knowledge have spread, from academic research to the day-to-day operations of companies. However, a more realistic approach can be achieved if several objectives are integrated into the process. Thus, an exciting strategy cannot only meet cost requirements, for example, but must also address durability, efficiency, reliability, and sustainability. Given that several objectives are involved, which are usually in conflict with each other, new strategies are needed, along with new, more complete applications. In this sense, the Special Issue, titled “Multi-Objective Optimization: Theory, Methods, and Applications”, aims to provide a platform for the dissemination of knowledge related to multi-objective optimization. Research articles that employ efficient, innovative optimization methods and explore new applications across diverse areas of expertise are sought, promoting the exchange of ideas and trends related to the subject.
Prof. Dr. Víctor Yepes
Prof. Dr. Moacir Kripka
Dr. José Antonio García
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the special issue website. Research articles, review articles, and short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for manuscript submission is available on the Instructions for Authors page. Mathematics is an international, peer-reviewed, open-access, semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript. The Article Processing Charge (APC) for publication in this open-access journal is 2600 CHF (Swiss Francs). Submitted papers should be well-formatted and written in good English. Authors may use MDPI’s English editing service prior to publication or during author revisions.
Keywords
- multi-objective optimization
- optimization methods
- optimization applications
- innovative methods and algorithms