El mito del algoritmo universal: una humillación necesaria.
El mito del algoritmo universal: una humillación necesaria.
Durante décadas, la comunidad científica persiguió con arrogancia el «santo grial»: el algoritmo de optimización universal. Se soñaba con una «caja negra», ya fuera basada en elegantes procesos evolutivos o en redes neuronales profundas, capaz de resolver cualquier problema, desde el diseño de un puente atirantado hasta la logística del viajante, con una eficiencia superior.
Sin embargo, esta búsqueda no solo era ambiciosa, sino que también era fundamentalmente errónea. La revelación de que no existe una inteligencia algorítmica absoluta supuso un golpe de humildad para quienes creían haber capturado la esencia del aprendizaje, cuando en realidad solo habían logrado un ajuste estadístico fortuito.
La revelación matemática: todos los algoritmos son, en promedio, iguales.
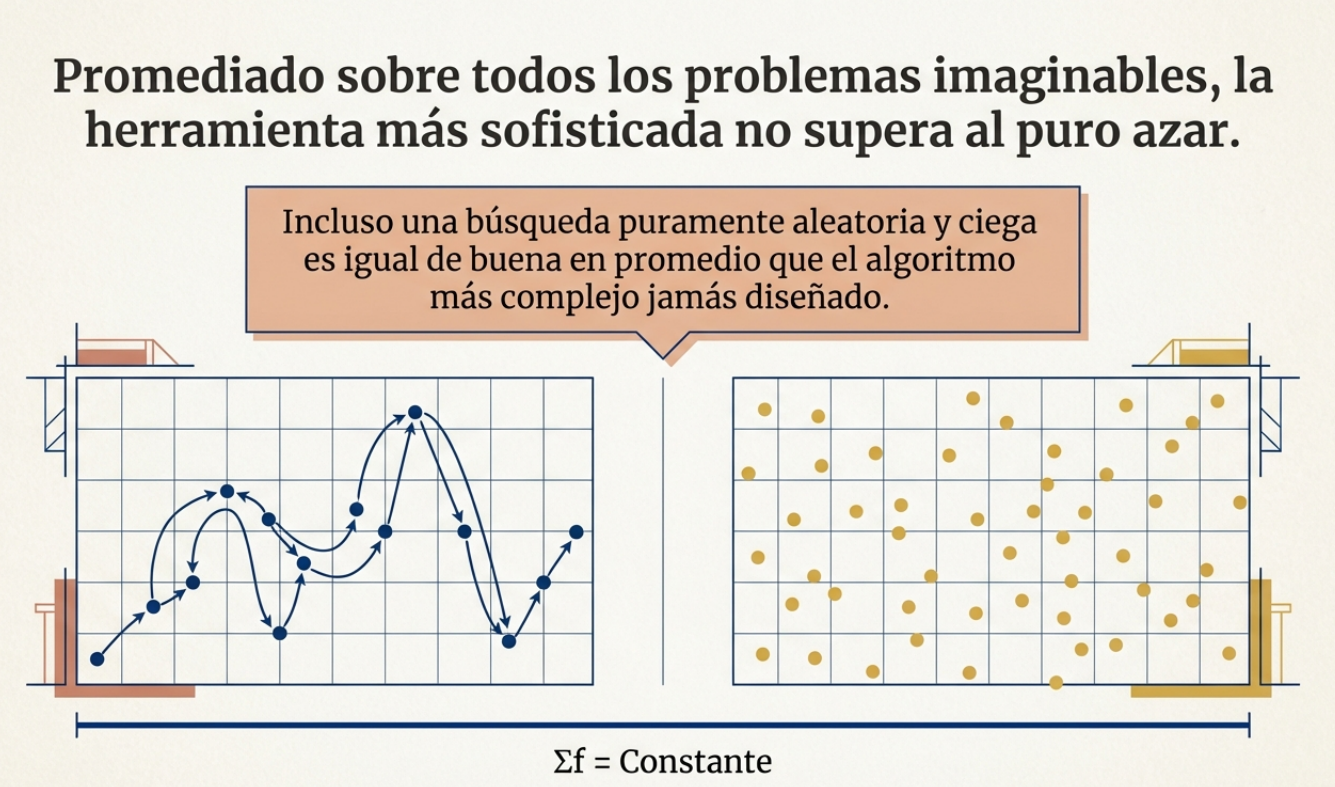
Este mito fue desmentido en 1997 por David Wolpert y William Macready. Sus teoremas «No Free Lunch» (NFL) establecieron una igualdad matemática absoluta que rompe el ego de cualquier programador: si promediamos el rendimiento sobre el conjunto de todos los problemas posibles, cualquier algoritmo sofisticado es idéntico a una búsqueda aleatoria.
Lo que un algoritmo gana en un tipo de problemas, lo paga inevitablemente con un fracaso estrepitoso en otro. No hay «comida gratis»: la superioridad de un algoritmo genético de última generación frente a un proceso de búsqueda ciega es una ilusión que solo se sostiene cuando ignoramos la inmensidad del espacio de funciones posibles.

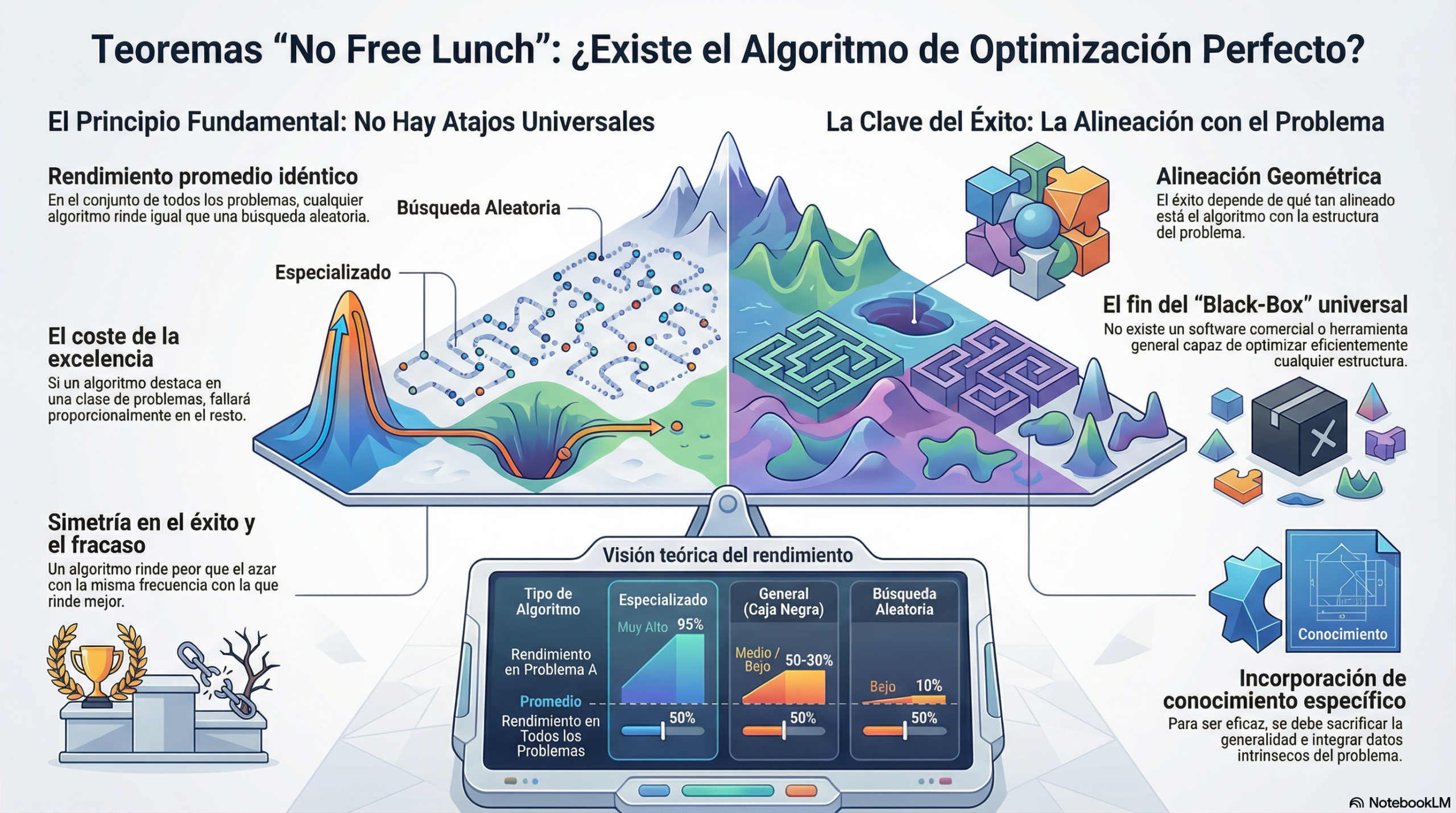
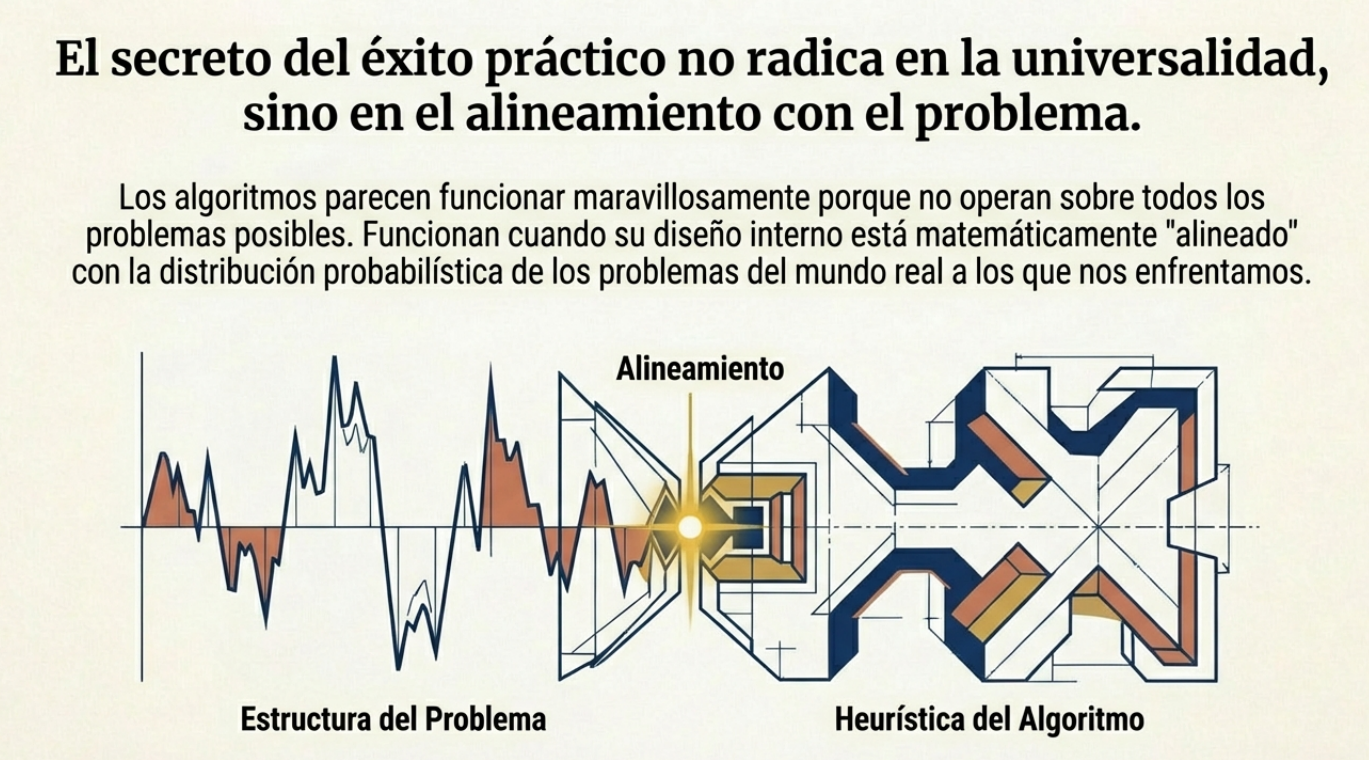
La geometría del éxito: el problema de la «alineación».
Para comprender la optimización del éxito, debemos abandonar la idea de la «fuerza bruta» y abrazar la geometría. Imagine el espacio de todas las funciones posibles como una esfera gigantesca. En este espacio, cada algoritmo es un vector v y la distribución de los problemas que deseamos resolver es otro vector p.
Estar «bien adaptado» a un problema significa que el vector del algoritmo apunta en la misma dirección que el del problema.
- Alineación geométrica: que el vector del algoritmo apunte en la misma dirección que el del problema. El rendimiento es, en esencia, el producto interno de ambos vectores.
- Sacrificio de la generalidad: un algoritmo «generalista» apunta hacia todas partes y, por tanto, su proyección (su éxito) en un punto concreto es nula.
- Curvatura del conocimiento: el éxito no reside en el código, sino en cómo este «se dobla» para encajar con la estructura lógica y física del problema.
Los investigadores del problema del viajante no han creado algoritmos «mejores» en términos absolutos, sino que han esculpido herramientas íntimamente alineadas con la geometría específica de las rutas y las distancias.
El golpe al ego: el algoritmo aleatorio como juez de paz.
Los teoremas 5 y 6 de Wolpert y Macready introducen un estándar de rigor que actúa como un «mínimo ético» para la ciencia. Si un algoritmo no consigue que el coste disminuya más rápido que con una búsqueda aleatoria, el investigador habrá fracasado.
Esta métrica es el antídoto contra el fraude intelectual del ajuste fino o manual. Muchos de los éxitos que se describen en la literatura no son más que el resultado de forzar un algoritmo a un puñado de problemas específicos sin superar el umbral de una búsqueda ciega. Superar al «juez de paz» aleatorio es la única prueba de que el algoritmo ha logrado capturar alguna estructura real del problema.
Consecuencias prácticas: el fin del experto generalista.
En ingeniería civil, las implicaciones del NFL son tajantes. No existen programas comerciales que puedan optimizar cualquier estructura de forma indiscriminada. Las herramientas generales (como las toolboxes estándar de Matlab) suelen ser ineficaces porque carecen del «conocimiento del hormigón».
Esta realidad ha provocado una «carrera armamentística» hacia la especialización.
- Hibridación: La respuesta de la ingeniería moderna consiste en combinar metaheurísticas con técnicas de deep learning y redes neuronales para «aprender» la estructura del dominio.
- Alineación estructural: un matemático brillante fracasará al optimizar un puente atirantado si no comprende la resistencia de los materiales. No se trata de falta de cálculo, sino de que su algoritmo no está alineado con la «curvatura» física del problema. El conocimiento experto es lo que permite al algoritmo encontrar el camino en un espacio de búsqueda que, de otro modo, sería un desierto uniforme.

El dilema del observador: la ceguera del éxito pasado.
Incluso cuando un algoritmo ha funcionado bien hasta ahora, el teorema 10 (sección VII) nos da un jarro de agua fría: observar el rendimiento pasado no garantiza el éxito futuro sin un conocimiento adicional sobre la función de coste. Sin conocer la estructura, no vemos el siguiente paso.
En este estado de «oscuridad estructural», un procedimiento de elección «irracional» (cambiar un algoritmo que ha funcionado bien por otro que ha funcionado mal) es tan válido como uno «racional». Sin suposiciones sobre la relación entre el algoritmo y la función, el comportamiento pasado es un predictor pobre. La lógica solo surge cuando el observador aporta información que no está presente en los datos.

Conclusión: hacia una optimización consciente.
Debemos aceptar una verdad incómoda: nuestra inteligencia artificial es un reflejo limitado del conocimiento que somos capaces de codificar en ella. La ciencia de la optimización ya no debe buscar el «algoritmo perfecto», sino métodos más profundos para transferir el conocimiento del dominio al proceso de búsqueda.

Si el rendimiento de nuestras máquinas depende por completo de lo que ya sabemos sobre el mundo, ¿no será que la «inteligencia artificial general» es un mito termodinámico, similar a la máquina de movimiento perpetuo? Quizás el mayor descubrimiento de Wolpert y Macready no fue matemático, sino filosófico: la inteligencia no es más que el conocimiento del problema disfrazado de código.
En esta conversación puedes escuchar las ideas más interesantes sobre este tema.
Este vídeo resume bien los conceptos más importantes tratados.
Referencias:
GARCÍA, J.; YEPES, V.; MARTÍ, J.V. (2020a). A hybrid k-means cuckoo search algorithm applied to the counterfort retaining walls problem. Mathematics, 8(4), 555.
MARTÍNEZ-MUÑOZ, D.; GARCÍA, J.; MARTÍ, J.V.; YEPES, V. (2022). Optimal design of steel-concrete composite bridge based on a transfer function discrete swarm intelligence algorithm. Structural and Multidisciplinary Optimization, 65:312. DOI:10.1007/s00158-022-03393-9
NEGRÍN, I.; CHAGOYÉN, E.; KRIPKA, M.; YEPES, V. (2025). An integrated framework for Optimization-based Robust Design to Progressive Collapse of RC skeleton buildings incorporating Soil-Structure Interaction effects. Innovative Infrastructure Solutions, 10:446. DOI:10.1007/s41062-025-02243-z
WOLPERT, D.H.; MACREADY, W.G. (1997). No Free Lunch Theorems for Optimization. IEEE Transactions on Evolutionary Computation, 1(1):67-82.
YEPES-BELLVER, L.; BRUN-IZQUIERDO, A.; ALCALÁ, J.; YEPES, V. (2025). Surrogate-assisted cost optimization for post-tensioned concrete slab bridges. Infrastructures, 10(2): 43. DOI:10.3390/infrastructures10020043.
A continuación os dejo el artículo original «No Free Lunch Theorems for Optimization». Se ha convertido en un clásico de optimización heurística.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.