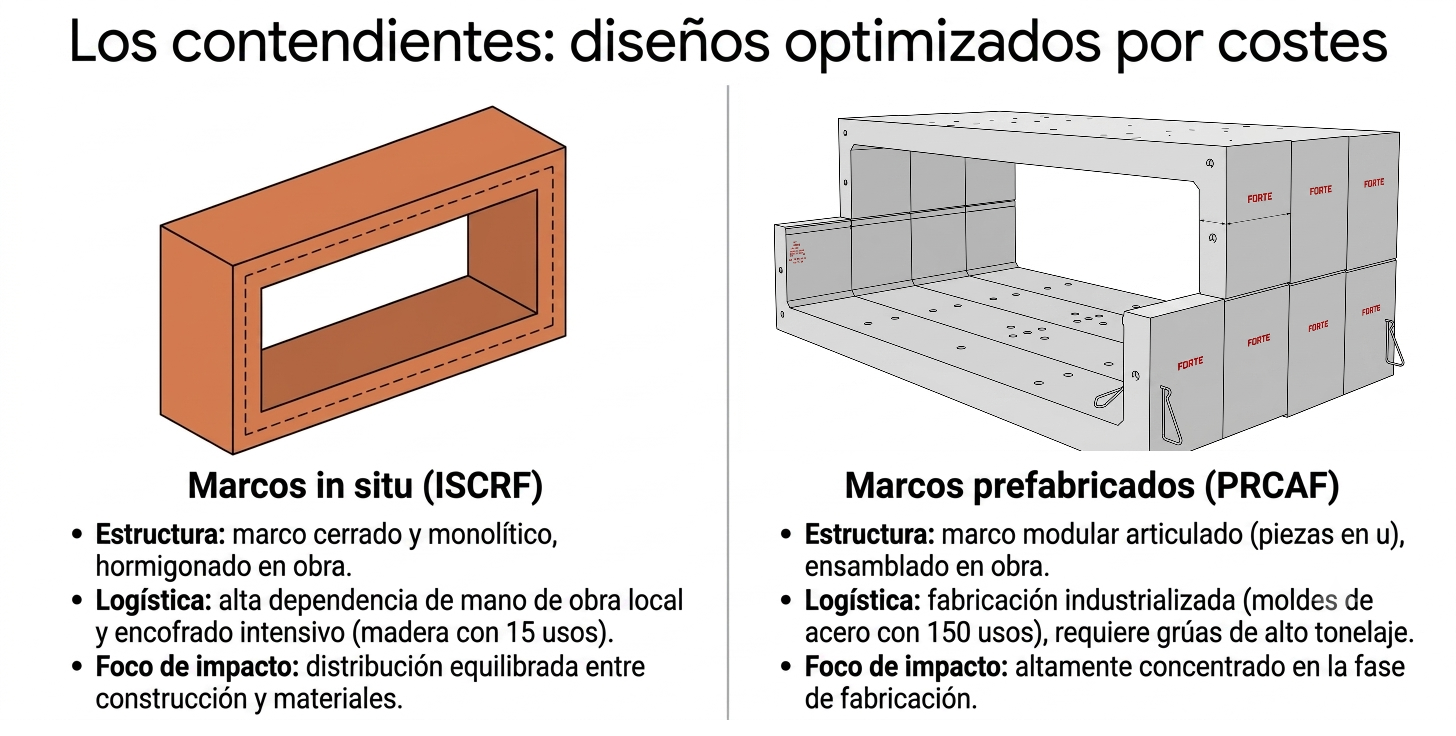
La verticalización es una respuesta indispensable para alcanzar la densidad urbana necesaria en un planeta sobrepoblado; sin embargo, el método de construcción actual no resulta eficaz. Según el informe Global Status Report for Buildings and Construction 2024/2025, la industria de la construcción consume el 32 % de la energía global y es responsable del 34 % de las emisiones de CO₂. Con el acero y el hormigón representando el 18 % de ese total, la urgencia de un cambio de paradigma es absoluta.
La verticalización es una respuesta indispensable para alcanzar la densidad urbana necesaria en un planeta sobrepoblado; sin embargo, el método de construcción actual no resulta eficaz. Según el informe Global Status Report for Buildings and Construction 2024/2025, la industria de la construcción consume el 32 % de la energía global y es responsable del 34 % de las emisiones de CO₂. Con el acero y el hormigón representando el 18 % de ese total, la urgencia de un cambio de paradigma es absoluta.
Como ingenieros, nos enfrentamos a una pregunta crítica: ¿es posible seguir elevando nuestras ciudades sin destruir el ecosistema? La respuesta reside en la ingeniería de precisión y en la optimización de las columnas CFST (columnas tubulares de acero rellenas de hormigón), una solución técnica que está redefiniendo la eficiencia estructural y la sostenibilidad.
A continuación, os presentamos algunas ideas clave, fruto del trabajo de Alves y su equipo (2026), sobre la optimización multiobjetivo sostenible de columnas tubulares mixtas de acero y hormigón de alta resistencia. El trabajo se enmarca en el proyecto de investigación RESILIFE, que dirijo como investigador principal en la Universitat Politècnica de València, y es fruto de la estancia de investigación del profesor Élcio C. Alves en nuestra universidad.
1. Por qué el hormigón de alta resistencia es sorprendentemente la opción más ecológica.
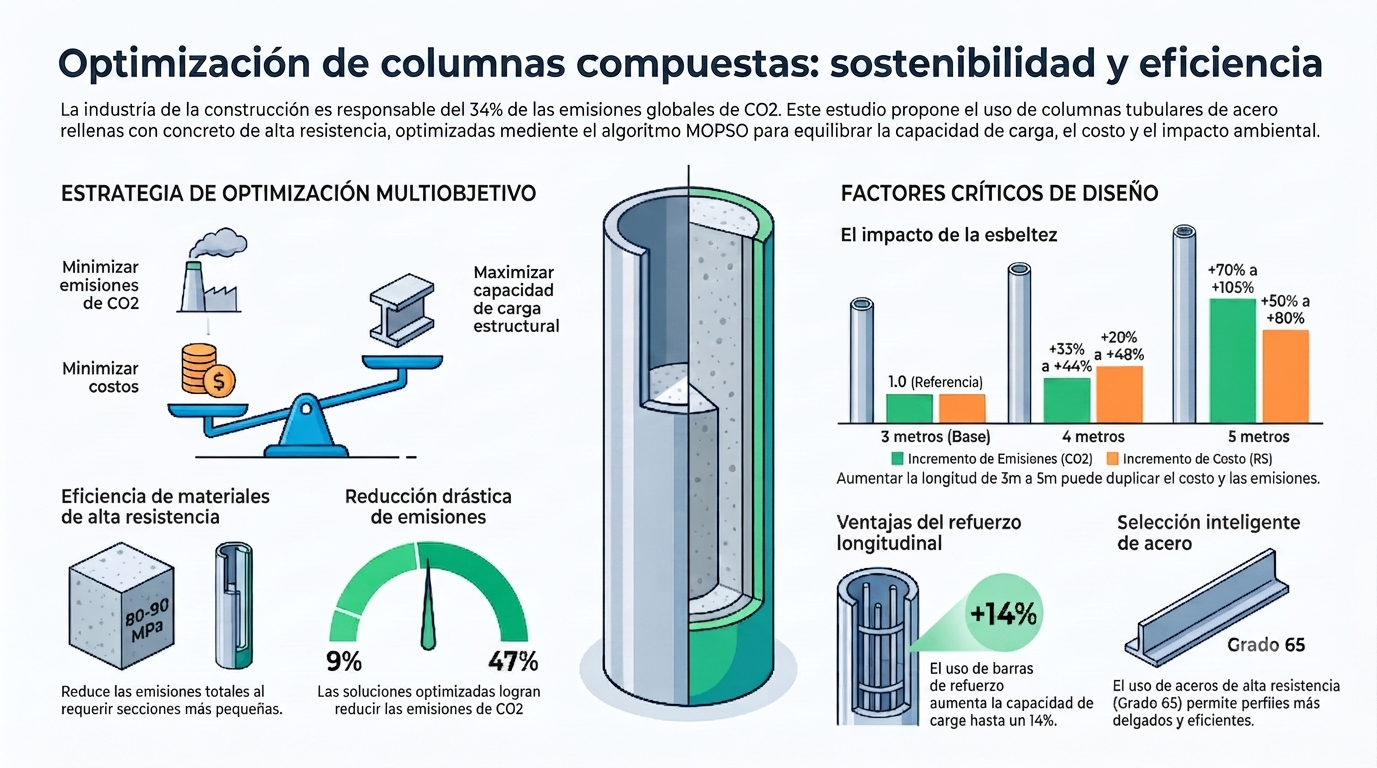
Un hallazgo contraintuitivo, pero fundamental, del estudio de Alves (2026) es que el uso de hormigón de alta resistencia (HSC, por sus siglas en inglés) de 80 MPa o 90 MPa resulta ser la opción más sostenible. Aunque la producción de un metro cúbico de hormigón de alta resistencia emite más CO₂ que la de uno convencional, su mayor capacidad portante permite una reducción volumétrica significativa.
Al reducir el tamaño de las columnas, no solo se gana espacio útil en la arquitectura, sino que la disminución total del uso de materiales compensa con creces la huella de carbono de cada uno de ellos. Es una lección de diseño: el material más «caro» ambientalmente por unidad puede ser el que menos impacto tiene en el sistema en su conjunto.
«El uso de hormigón de alta resistencia (80 MPa o superior) y aceros de alto grado está plenamente justificado por la reducción significativa de las emisiones finales de la columna, lo que supera el impacto inicial de producir materiales más costosos». — Alves et al. (2026).

2. MOPSO: inteligencia colectiva para equilibrar costes y emisiones.
El diseño tradicional suele ser un proceso manual que prioriza el coste directo. No obstante, en proyectos de alta complejidad, la ingeniería moderna recurre a la optimización mediante un enjambre de partículas con múltiples objetivos (MOPSO). Este algoritmo de «enjambre de partículas» simula comportamientos sociales para encontrar el equilibrio ideal, conocido como el frente de Pareto.
El MOPSO no proporciona una única solución, sino un conjunto de opciones óptimas que equilibran tres aspectos críticos: la minimización de costes, la reducción de kgCO₂ y la maximización de la capacidad de carga. El algoritmo ajusta simultáneamente variables técnicas como:
- El diámetro y el espesor del tubo de acero.
- El número y el diámetro de las barras de refuerzo internas.
- El uso de aceros HSLA (High-Strength Low-Alloy), como el ASTM A572 Gr. 65 o el avanzado ASTM A913 Gr. 70.
Confiar en estos algoritmos permite encontrar geometrías que un diseñador humano difícilmente alcanzaría y optimizar cada gramo de acero para que cumpla su función estructural máxima.
3. La esbeltez: el factor que puede duplicar el coste de tu proyecto.
La altura de una columna no es un factor lineal en cuanto al impacto. Al analizar el paso de columnas de 3 a 5 metros, surge un «impuesto invisible» impulsado por la física: los efectos de segundo orden.
Según el método B1 de la norma NBR 8800:2008, al aumentar la longitud, la columna es más susceptible al pandeo. Esto obliga a incrementar drásticamente la sección de acero o a utilizar materiales con una resistencia mucho mayor para compensar la inestabilidad. Los resultados de esta transición son masivos:
- Emisiones de CO₂: el incremento de 3 m a 5 m puede disparar las emisiones entre un 70 % y un 105 %.
- Costes materiales: el presupuesto puede incrementarse entre un 50 % y un 80 %.
La esbeltez no solo supone un reto estético, sino también un riesgo financiero y medioambiental que exige una optimización matemática rigurosa para evitar duplicar la huella de carbono de la estructura.
Del papel a la práctica: superando estándares anteriores.
La evolución de los modelos de optimización está dando frutos tangibles. Al comparar los resultados de Alves et al. (2026) con investigaciones previas (como la de Correia et al., 2025), se observa que el uso de aceros de alto grado y modelos actualizados permite reducir las emisiones hasta en un 47 %.
| Escenario de carga (Mxd/Myd) | Correia et al. (2025) (kgCO₂) | Alves et al. (2026) (kgCO₂) |
| Uniaxial (30/0 kNm) | 286,44 | 233,89 |
| Uniaxial alta (270/0 kNm) | 446,26 | 265,94 |
| Oblicua (27/27 kNm) | 248,16 | 131,74 |
Lo más impresionante es que estas reducciones (que oscilan entre el 9 % y el 47 %) se lograron aumentando la capacidad de carga hasta en un 14 % en columnas reforzadas, mientras se reducía el área transversal de acero. Este hito ha sido posible gracias a la transición hacia aceros de mayor rendimiento, como el ASTM A913 Gr. 70.

Conclusión: hacia una ingeniería de precisión.
Los resultados son concluyentes: el uso de materiales HSC y de algoritmos MOPSO ya no es un lujo para proyectos experimentales, sino una necesidad imperativa para la sostenibilidad urbana. La ingeniería de precisión nos permite construir estructuras más resistentes y esbeltas con una fracción del impacto ambiental asociado a los métodos tradicionales.
La industria se encuentra ante una encrucijada técnica y ética: ¿estamos listos para abandonar las «recetas» de diseño tradicionales en favor de la optimización matemática?
Si pudieras reducir a la mitad la huella de carbono de tu próxima estructura simplemente ajustando la resistencia del hormigón y aplicando algoritmos de precisión, ¿por qué no lo harías?
En esta conversación puedes escuchar las ideas más interesantes sobre esta investigación.
En este vídeo se resume el contenido del artículo.
Sustainable_Vertical_Optimization
Referencia:
ALVES, E.C.; YEPES-BELLVER, L.; KRIPKA, M.; YEPES, V. (2026). Sustainable Multi-Objective Optimization of Tubular Composite Columns with High-Strength Steel and Concrete. Congress on Project Management and Engineering, AEIPRO, 7-9 de julio, Castellón (Spain).
CORREIA, L.; RODRIGUES, M. C. A.; ALVES, E. C. (2025). Multi-Objective Optimization of Steel and Concrete Tubular Composite Columns. Proceedings CILAMCE 2025, Vitória – ES – Brazil.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.