Hoy quiero dar las gracias, con toda sinceridad, a todos los colegiados y colegiadas, pero especialmente a los del Sector 4 (Docencia e Investigación) del Colegio de Ingenieros de Caminos, Canales y Puertos por su participación en estas elecciones. Este sector ha experimentado un incremento muy notable en el nivel de implicación, y eso, por sí solo, ya es una gran noticia para todos.
Gracias también por el apoyo masivo que ha recibido mi candidatura, que me permite continuar, por tercera vez, como vuestro Consejero. Es un honor y, sobre todo, una responsabilidad que asumo con el mismo compromiso del primer día.
Seguiré trabajando para defender los intereses del colectivo de ingenieros e ingenieras de caminos que desarrollamos nuestra labor en este ámbito, a todos y todas, sin excepción. La docencia y la investigación son pilares esenciales de nuestra profesión y así seguiré defendiéndolos.
Quiero aprovechar también para felicitar muy sinceramente a todos los compañeros y compañeras que han sido elegidos en el resto de los sectores como consejeros, a quienes han sido elegidos en las juntas de gobierno de las demarcaciones, a los representantes provinciales y al presidente, vicepresidente y vocales de la Junta de Gobierno del Colegio. Enhorabuena a todos por la confianza depositada en vosotros.
Ahora, superado el proceso electoral, toca remar juntos. Os pido a todos y todas un trabajo común y conjunto, para que nuestra profesión siga ocupando el lugar que le corresponde y siga aportando valor a la sociedad.
Gracias de nuevo por la confianza. Vamos a por ello. 💪
La docencia y la investigación son pilares esenciales para garantizar el futuro de la Ingeniería de Caminos, Canales y Puertos y para fortalecer el vínculo entre la Universidad, la profesión y la sociedad. Durante este mandato como consejero del Sector 4 (Docencia e Investigación) del Colegio de Ingenieros de Caminos, Canales y Puertos, he trabajado para que la voz del ámbito académico cuente con una presencia activa en las decisiones estratégicas que afectan a nuestra profesión.
Como miembro de la Comisión de Educación y Universidades del Colegio y único ingeniero de caminos que forma parte de la Comisión C15 (Ingeniería Civil) de ANECA, responsable de la acreditación de profesores titulares y catedráticos en nuestra disciplina, he impulsado iniciativas para reconocer el valor de la experiencia profesional en la carrera académica, reforzar la calidad de la formación y estrechar la conexión entre la universidad y el ejercicio profesional. Con la experiencia acumulada y el trabajo realizado como base, solicito de nuevo vuestra confianza para seguir representando al Sector 4 y consolidar las iniciativas emprendidas en beneficio de toda la comunidad académica y profesional.
En este contexto, considero oportuno compartir el balance de la actividad desarrollada por la Comisión de Educación y Universidades durante el periodo 2024-2026. Durante este mandato he tenido el honor de presidir el Grupo de Trabajo 1, dedicado a la acreditación del profesorado, desde el cual hemos elaborado propuestas para mejorar el reconocimiento de la experiencia profesional en los procesos de evaluación académica. Asimismo, el respaldo y la confianza de mis compañeros de la Comisión, que me han animado a presentar de nuevo mi candidatura como consejero del Sector 4, constituyen un estímulo para seguir trabajando con el objetivo de que el Colegio disponga de información directa, rigurosa y permanentemente actualizada sobre la evolución de los criterios y procedimientos de acreditación del profesorado universitario. El resumen que se presenta a continuación recoge las principales actuaciones, iniciativas y resultados alcanzados por la Comisión, fruto del compromiso y del trabajo conjunto de todos sus integrantes.
Plan de Actuación de la Comisión de Educación y Universidades para el periodo 2024-2026
La Comisión de Educación y Universidades afrontó el periodo 2024-2026 con el propósito de impulsar una estrategia orientada al fortalecimiento de la formación, la excelencia académica y la proyección de la Ingeniería de Caminos, Canales y Puertos. Integrada por un equipo multidisciplinar de expertos y representantes de las distintas Demarcaciones del Colegio, la Comisión desarrolló un plan de actuación sustentado en objetivos estratégicos, líneas de trabajo definidas y acciones concretas que contribuyeron a responder a los retos presentes y futuros de la profesión.
La Comisión estuvo presidida por Esther Real, directora de la Escuela Técnica Superior de Ingeniería de Caminos, Canales y Puertos de la Universitat Politècnica de Catalunya (UPC), quien lideró este proyecto con una visión orientada a la innovación, la colaboración y la obtención de resultados. La acompañaron en el equipo directivo la vicepresidenta, Ana Rivas, directora de la Escuela Técnica Superior de Ingeniería de Caminos, Canales y Puertos de la Universidad de Castilla-La Mancha y presidenta de CODICAM (Conferencia de Directores de Ingeniería de Caminos, Canales y Puertos y de Ingeniería Civil), y la secretaria, Ángeles Martín, responsable de Empleo y Formación del CICCP, quienes coordinaron el desarrollo de las iniciativas y velaron por el cumplimiento de los objetivos establecidos.
Formaron parte asimismo de la Comisión Héctor Andrés (USAL), José Atienza (UPM), José Baraibar (UNICAN), Jorge Bernabeu (UPM), Daniel Castro (UNICAN), Antoni Cladera (UIB), Marta García (UNEX), Belén González (UDC), Isabel Martínez (UDC), Juan Miquel (UPC), Enrique Mirambell (UPC), Jose Moura (UNICAN), Fermín Navarrina (UDC), Eugenio Pellicer (UPV), Pedro Plasencia (UNIOVI), M. Rodríguez (UE), M. Rubio (UGR), Rita Ruiz (UCLM), Ángel Sampedro (UAX), Antonio Tomás (UPCT) y Víctor Yepes (UPV).
La diversidad de trayectorias y la amplia experiencia de sus integrantes en los ámbitos de la docencia, la investigación, la gestión universitaria y el ejercicio profesional constituyeron un activo esencial para el desarrollo de este plan de actuación. Su trabajo conjunto favoreció la generación de propuestas de alto valor, el fortalecimiento de la relación entre los ámbitos académico y profesional y la consolidación de una formación de excelencia, alineada con las necesidades de la sociedad y los desafíos del futuro.
Balance de la Comisión
La Comisión de Educación y Universidades ha mantenido durante el ejercicio 2025 un firme compromiso con el fortalecimiento de la conexión entre el ámbito profesional de la ingeniería y el entorno académico. En el marco del Plan de Actuación 2024-2026, la Comisión ha centrado sus esfuerzos en mitigar la desconexión detectada entre el conocimiento teórico impartido en las Escuelas y las habilidades prácticas de alto nivel exigidas por el mercado laboral actual. El contexto de este año ha estado marcado por la preocupación ante la excesiva teorización de los currículos académicos y por la necesidad de que la Agencia Nacional de Evaluación de la Calidad y la Acreditación (ANECA) reconozca de manera efectiva la experiencia profesional en la acreditación del profesorado.
Asimismo, la Comisión ha seguido de cerca la reestructuración de las comisiones de evaluación de la ANECA tras la división de la antigua comisión C13 en las nuevas C15 (Ingeniería Civil) y C16 (Arquitectura y Construcción), velando por una representación adecuada de los ingenieros de caminos en dichos órganos.
Actividades realizadas
A lo largo del año 2025, la Comisión ha desarrollado su actividad mediante tres reuniones plenarias virtuales, celebradas el 17 de febrero, el 9 de mayo y el 3 de diciembre, además de múltiples sesiones internas de trabajo de sus grupos especializados.
La Comisión ha estructurado su trabajo en cuatro Grupos de Trabajo (GT) con logros significativos:
GT1: Acreditación del profesorado. Ha liderado la elaboración de una propuesta técnica para integrar la experiencia profesional en el sistema de acreditación. Entre sus planteamientos destaca la sustitución de las estancias de investigación de nueve meses por dos años de ejercicio profesional especializado y la equiparación de la dirección de proyectos de ingeniería singulares a artículos científicos indexados.
GT2: Homologaciones y convalidaciones. Ha realizado un análisis exhaustivo de los retrasos administrativos en la homologación de títulos extranjeros, que pueden alcanzar entre tres y cinco años. Como solución, se ha propuesto que el Colegio actúe como representante legal de los solicitantes para agilizar la gestión inicial ante el Ministerio.
GT3: Formación permanente y continua. Ha avanzado en la recopilación de la oferta de microcredenciales de las Escuelas de Caminos, orientadas a profesionales de entre 25 y 64 años, con el objetivo de coordinar la formación subvencionable de bajo coste y corta duración.
GT4: Promoción de los estudios. Ha iniciado el diseño de campañas de difusión para visibilizar el valor de la ingeniería de caminos en todas las comunidades autónomas.
Acuerdos y reuniones institucionales realizadas
La comisión ha contado con la participación activa del presidente del Colegio, Miguel Ángel Carrillo, en la reunión de cierre anual de diciembre. En dicha sesión se ha acordado una estrategia institucional escalonada que incluye reuniones con el secretario general de Universidades y con la dirección de ANECA para presentar formalmente las propuestas para la valoración de la experiencia profesional. Además, la Comisión ha colaborado con la Comisión de Defensa de la Profesión para actualizar el «Libro Blanco de la Ingeniería de Caminos«, incorporando nuevas competencias en resiliencia, cambio climático y digitalización, entre otras. También se ha abordado con preocupación la evaluación de títulos españoles por agencias externas (como la de Kazajistán), instando a una mayor coordinación entre universidades y agencias evaluadoras.
Publicaciones y documentos técnicos realizados
Durante 2025, la Comisión ha generado los siguientes documentos de referencia:
Documento de Reflexiones sobre la Experiencia Profesional: un informe detallado que justifica la necesidad de un cambio en la valoración del profesorado universitario.
Guía de Homologaciones y Convalidaciones: un documento explicativo que recoge de forma ordenada las vías de homologación, las fases del procedimiento y el rol de los organismos implicados para orientar a escuelas y titulados extranjeros.
Para concluir este ejercicio, la Comisión programó una reunión presencial en Madrid en enero de 2026, con el fin de consolidar el posicionamiento del Colegio antes de su traslado formal ante las autoridades ministeriales.
Espacio de diálogo
Si eres profesor, investigador o estás vinculado al ámbito universitario de la Ingeniería de Caminos, te invitamos a participar en un encuentro abierto para compartir ideas, propuestas e inquietudes de cara a las elecciones del Sector 4 (Docencia e Investigación) del Colegio de Ingenieros de Caminos.
Será un espacio de diálogo en el que podremos debatir los retos que afrontan los ingenieros de caminos dedicados a la docencia y la investigación, intercambiar puntos de vista y explicar las propuestas de nuestra candidatura para reforzar la presencia y el papel de este colectivo dentro del Colegio.
📅 Jueves, 9 de julio
🕦 11:30 h
📍 Sede del Colegio en Madrid (Sala Torán) y también en formato telemático.
En el acto participarán Víctor Yepes, candidato al Sector 4; Carmen Castro, candidata a vocal de la Junta de Gobierno; Ricardo Martín de Bustamante, consejero en Dragados y ACS Servicios y Concesiones; Martín de Bustamante-Villarroya, candidato territorial por Murcia; y Antonio Tomás Espín, candidato al Consejo General.
Porque un Colegio más fuerte también se construye escuchando a quienes forman e investigan para las próximas generaciones de ingenieros.
Os esperamos para conversar, debatir y construir juntos el futuro del Sector 4.
Aún está fresca la tinta del último libro que acabo de publicar. Como he señalado en otras ocasiones, mi mayor aspiración es culminar una «Enciclopedia de la ingeniería de la construcción» antes de jubilarme. Es un proyecto de enorme envergadura que, en los tiempos que corren, puede parecer incluso una rareza, pues el actual sistema de evaluación del profesorado universitario concede escaso reconocimiento a este tipo de obras, privilegiando casi exclusivamente los artículos científicos. Aun así, inspirado por el legado de los grandes catedráticos que han marcado el rumbo de nuestra profesión, continúo dedicando, con la humildad de quien sabe que siempre queda mucho por aprender, una parte esencial de mi tiempo a este ilusionante desafío.
En este caso, se trata de un Manual de Referencia (revisado por el sistema doble ciego) de la Universitat Politècnica de València. Se trata de un libro de 452 páginas, con 214 ilustraciones y 200 preguntas de autoevaluación, titulado «Fabricación y puesta en obra del hormigón». Su referencia es el número 441 y, si os interesa, lo podéis conseguir en este enlace: https://www.lalibreria.upv.es/portalEd/UpvGEStore/control/product?product_id=441-5-1
Sin embargo, no me he podido resistir a compartir el prólogo que he escrito para este libro y que, además de presentarlo, sirve como reflexión sobre la docencia de la asignatura «Procedimientos de Construcción», actualmente impartida en los grados de ingeniería civil y de ingeniería de obras públicas de la Escuela Técnica Superior de Ingeniería de Caminos, Canales y Puertos de Valencia.
Prólogo
La docencia de una asignatura como Procedimientos de Construcción conlleva una dificultad singular: no se trata solo de explicar conceptos, sino de enseñar cómo se ejecutan realmente las obras, lo que implica abordar no solo las fases constructivas, sino también aspectos esenciales como el conocimiento de la maquinaria y los medios auxiliares, la seguridad y salud, el impacto ambiental y, sobre todo, los fundamentos técnicos necesarios —geotecnia, resistencia de materiales, mecánica, cálculo de estructuras, gestión empresarial, planificación y economía— que permiten seleccionar el proceso constructivo más adecuado para cada caso.
Además, todo ello debe transmitirse a estudiantes cuya experiencia directa en obra es, en la mayoría de los casos, escasa o inexistente. Entonces surge una pregunta inevitable: ¿cómo llevar la obra al aula?
Es evidente que nada sustituye a la experiencia directa. Las visitas a obras y las prácticas en empresa resultan imprescindibles para la formación del futuro profesional. Sin embargo, aun siendo necesarias, no son suficientes para adquirir las competencias y la visión global que exige el ejercicio de la ingeniería.
La dificultad aumenta cuando estas asignaturas se imparten en los primeros cursos del grado. En planes de estudio anteriores, Procedimientos Generales de Construcción y Organización de Obras se cursaba en los últimos años, incluso en paralelo con la asignatura de Proyectos. Esto permitía al estudiante integrar los conocimientos adquiridos y comprender con mayor profundidad la lógica constructiva. Pero independientemente del momento en que se imparta, el reto de acercar la realidad de la obra al estudiante sigue siendo el mismo.
Recuerdo cuando cursé esta asignatura en el cuarto curso de Ingeniería de Caminos, Canales y Puertos, en 1986. El profesor D. Hermelando Corbí Abad utilizaba entonces todos los recursos disponibles: proyector de opacos, fotografías que circulaban de mano en mano, catálogos de maquinaria y de empresas y, sobre todo, mucha pizarra. Tomábamos apuntes con esmero y disponíamos de textos mecanografiados que nos servían de guía. Las clases se complementaban con numerosas visitas a obras y excursiones técnicas que no solo ampliaban nuestros conocimientos, sino que también fortalecían el compañerismo y alimentaban nuestra vocación por esta apasionante profesión.
Cuando en 1994 comencé a impartir la asignatura, ya como profesor asociado y tras varios años de experiencia en los sectores público y privado, recurrí a los medios que entonces estaban a nuestro alcance: vídeos en VHS, transparencias, fotografías y catálogos. Las visitas a obra seguían siendo un pilar fundamental. No obstante, el problema persistía. Las técnicas constructivas evolucionaban con rapidez y la maquinaria y los medios auxiliares cambiaban a un ritmo que resultaba difícil de seguir con los recursos disponibles.
La llegada de los ordenadores personales, las presentaciones digitales y, sobre todo, de internet y de la inteligencia artificial supusieron un punto de inflexión. Con el cambio de milenio, la información comenzó a multiplicarse exponencialmente. Las fotografías, los vídeos y los documentos se acumulaban en el disco duro sin un orden claro. Era necesario estructurar y sistematizar todo el material.
El 5 de marzo de 2012 inicié una bitácora digital con el propósito de organizar esa información dispersa. Así nació el «Blog de Víctor Yepes», concebido inicialmente como una herramienta personal de organización y que pronto se convirtió en un recurso abierto para estudiantes y profesionales. La posibilidad de estructurar contenidos en entradas, incorporar material gráfico, enlazar documentos y facilitar el acceso permanente a la información transformó por completo mi forma de enseñar. Los estudiantes podían no solo repasar lo explicado en clase, sino también profundizar y ampliar sus conocimientos de forma autónoma. Con el tiempo, el blog se ha ampliado hasta convertirse en un repositorio dinámico y extenso de contenidos sobre la construcción, con más de 2400 artículos dedicados a la ingeniería de la construcción.
El siguiente paso fue natural: depurar, revisar y sistematizar ese material para convertirlo en textos docentes estructurados. Así surgieron los Manuales de Referencia, editados por la Universitat Politècnica de València, entre los cuales se enmarca la presente obra.
Este libro es fruto de un esfuerzo de recopilación, ordenación y actualización del conocimiento, con el objetivo de ofrecer un recurso integral y actualizado tanto para estudiantes como para profesionales. Cada generación de docentes tiene la responsabilidad de renovar y mantener actualizados los contenidos de sus asignaturas, incorporando los avances técnicos y normativos. Las leyes y reglamentaciones que afectan a las estructuras y medios auxiliares evolucionan con el tiempo, por lo que en estas páginas se han destacado especialmente los principios fundamentales, aquellos que permanecen más allá de los cambios coyunturales.
La fabricación y la puesta en obra del hormigón constituyen una fase decisiva en el proceso constructivo, pues de ellas depende que las prestaciones previstas en el proyecto se materialicen correctamente en la obra. A diferencia de las asignaturas de materiales, centradas en la caracterización y las propiedades del hormigón, o de las de cálculo de estructuras, orientadas a su dimensionamiento, este ámbito se ocupa de los procesos reales de dosificación, transporte, vertido, compactación, curado y control. En definitiva, es el puente entre la teoría y la realidad física que garantiza la durabilidad, la seguridad y la calidad final de la estructura.
La naturaleza práctica de esta obra responde a la necesidad de cubrir un vacío editorial. Aunque existen excelentes textos sobre geotecnia, resistencia de materiales, cálculo de estructuras o hidráulica, son escasas las publicaciones que abordan con suficiente profundidad y actualidad los procedimientos constructivos, la maquinaria y los medios auxiliares que hacen posible materializar los proyectos.
Una de las mayores dificultades a la hora de elaborar este libro ha sido la recopilación y selección del material gráfico, indispensable para comprender adecuadamente los elementos descritos. En el ámbito de la construcción, la imagen no es un simple complemento, sino una herramienta fundamental para el aprendizaje.
El libro está organizado en capítulos que abordan de forma sistemática la fabricación del hormigón, incluidos sus procesos y la maquinaria empleada, su transporte y vertido en obra, las operaciones de compactación y curado, así como las técnicas de reparación. También se dedica un apartado específico a los hormigones especiales y un capítulo final a los pavimentos de hormigón empleados en carreteras. La obra se completa con referencias bibliográficas y una serie de preguntas tipo test, con respuestas incluidas, para que el lector pueda evaluar su comprensión. Un índice temático final facilita la localización rápida de los contenidos.
El reto de esta obra ha consistido en integrar información dispersa, combinar técnicas tradicionales con otras plenamente actuales y describir maquinaria que, año tras año, deja obsoletos los modelos anteriores. Es posible, e incluso deseable, que dentro de algunos años parte de lo aquí expuesto se convierta en testimonio de una etapa superada por la robotización, la inteligencia artificial, los gemelos digitales y otras tecnologías emergentes que transformarán profundamente nuestra forma de concebir y ejecutar las obras.
Aunque se ha realizado una revisión minuciosa del manuscrito, es posible que persista alguna errata propia de una primera edición. Asumo la responsabilidad por cualquier error u omisión y agradezco de antemano las sugerencias que contribuyan a mejorar futuras ediciones.
A partir de este momento, el libro deja de pertenecer a su autor y pasa a ser del lector. Espero que estas páginas sirvan de ayuda a estudiantes y profesionales en su acercamiento al apasionante mundo de la construcción y, en particular, al desafío diario que supone la fabricación y la puesta en obra del hormigón para hacer realidad cada proyecto.
Valencia, mayo de 2026.
Referencia:
YEPES, V. (2026). Fabricación y puesta en obra del hormigón. Colección Manual de Referencia, serie Ingeniería Civil. Editorial Universitat Politècnica de València, 452 pp. Ref. 441. ISBN: 978-84-1396-418-8
En las aulas de hoy se libra una batalla silenciosa. Por un lado, el temor a que la inteligencia artificial (IA) despoje al aprendizaje de su esencia humana y, por otro, la realidad agotadora de los instructores que no disponen de tiempo suficiente para ofrecer retroalimentación detallada sobre cada borrador. Estamos ante una encrucijada: ¿automatizamos la enseñanza o encontramos una forma de que la tecnología nos haga más humanos?
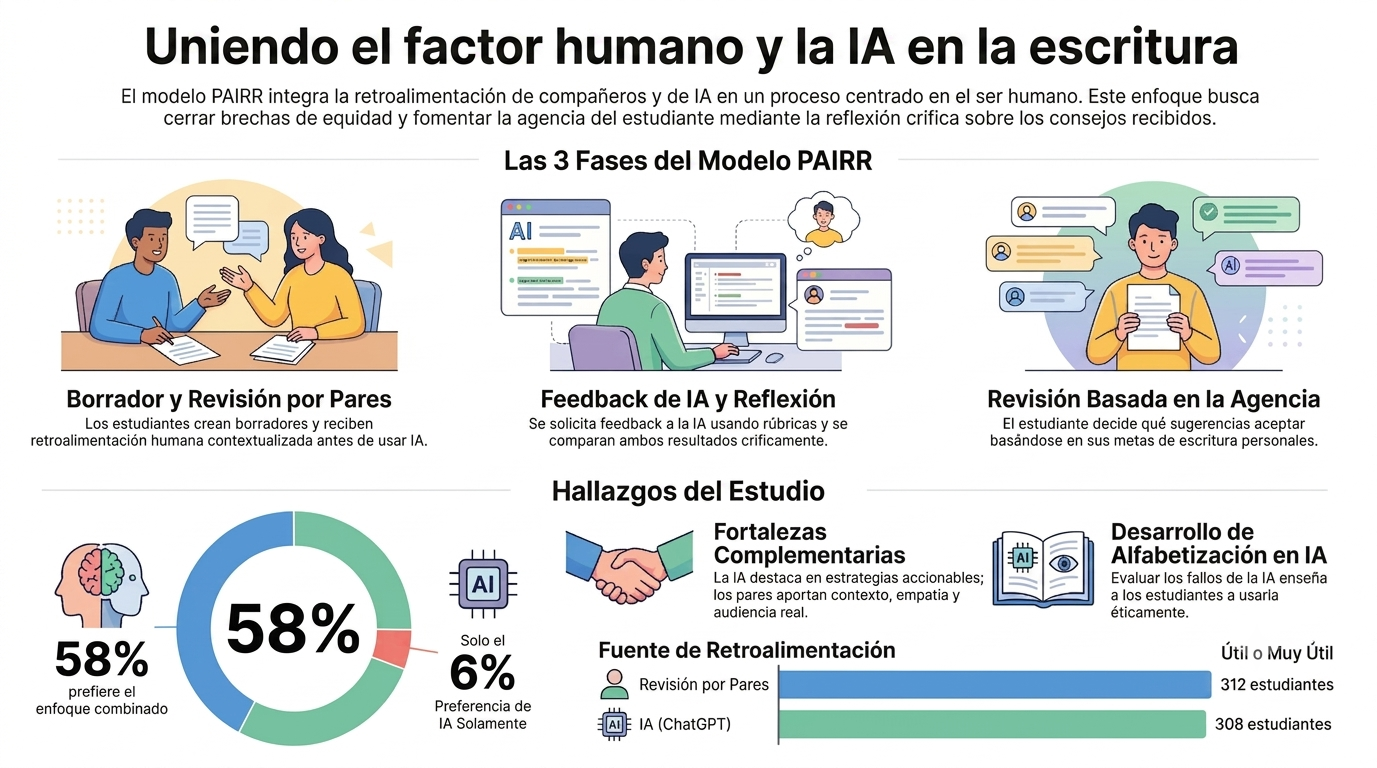
Investigadores de la Universidad de California han arrojado luz sobre este dilema mediante el modelo PAIRR (Peer and AI Review + Reflection). No se trata de una capitulación ante las máquinas, sino de una estrategia centrada en el ser humano que demuestra que la clave no es elegir entre «IA» y «humano», sino potenciar el binomio «IA + humano». Los estudiantes lo tienen claro: no quieren elegir entre el código y el corazón; quieren ambos.
El «combo» ganador: validación y lentes complementarios.
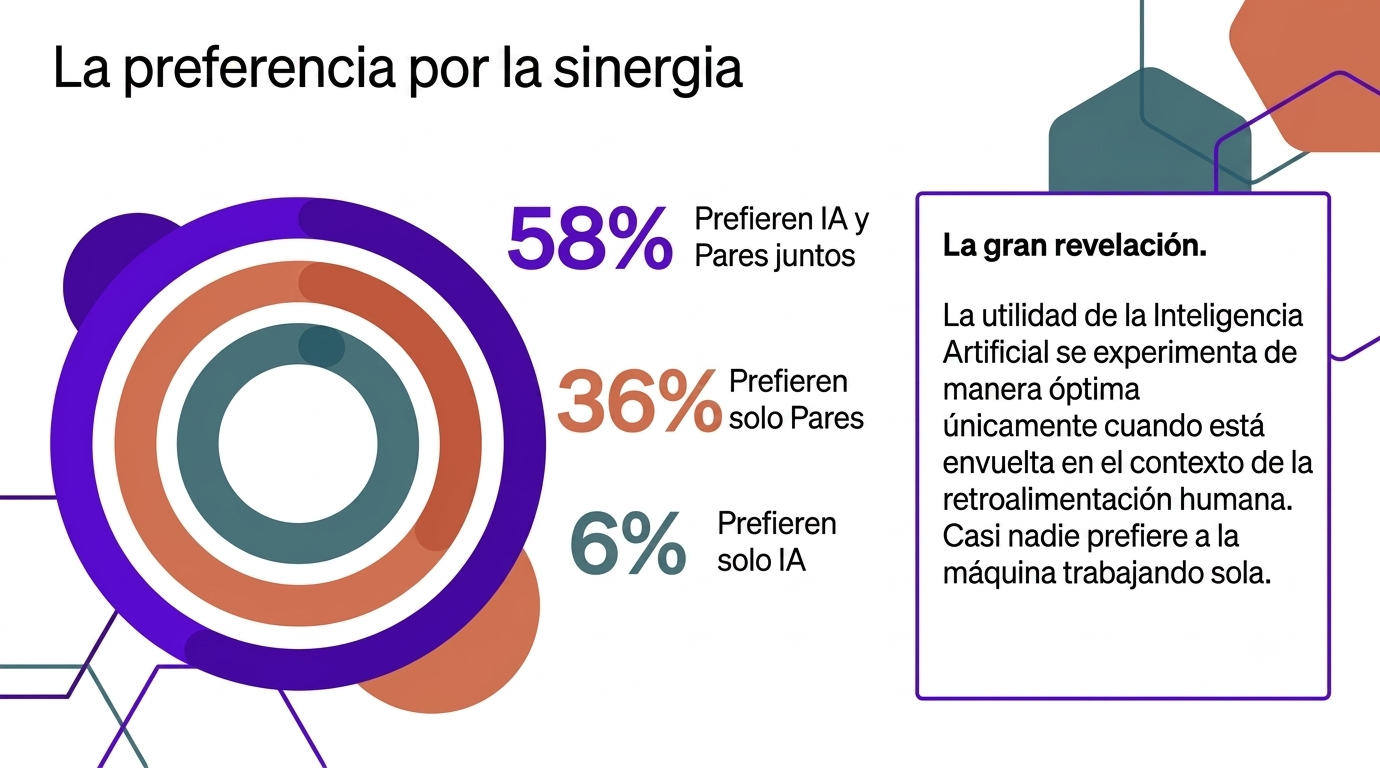
Los datos del estudio (N = 361) son contundentes y desafían la idea de que los jóvenes buscan la automatización como un camino fácil. El 58 % de los estudiantes prefiere recibir retroalimentación combinada de la IA y de sus compañeros, mientras que un rotundo 36 % aún prefiere únicamente la retroalimentación humana. Solo un minúsculo 7 % optaría por recibir comentarios exclusivamente de una IA.
¿Por qué esta preferencia masiva por el modelo híbrido? La ciencia apunta a dos mecanismos psicológicos:
Refuerzo y validación: cuando la IA y un compañero coinciden, el estudiante siente una «reaseguración». El comentario deja de ser una opinión aislada para convertirse en una verdad comprobada.
Perspectivas complementarias: la IA y los humanos miran el texto con lentes distintos. Mientras la IA actúa como un arquitecto de la estructura, los compañeros actúan como lectores sensibles al matiz.
La IA como el entrenador de rúbricas que nunca duerme.
Una de las grandes fortalezas de modelos como ChatGPT es su capacidad para ofrecer estrategias de revisión accionables basadas estrictamente en la rúbrica. Mientras que un compañero puede ser vago en sus sugerencias, la IA destaca por identificar problemas de organización y de flujo con una frialdad técnica que constituye su mayor virtud.
Pero su mayor impacto radica en su disponibilidad. Consideremos el caso de Elizabeth, una estudiante de redacción científica. Para ella, la IA no es un sustituto del profesor, sino un «coach» disponible en los momentos de mayor soledad creativa:
«Me dio la retroalimentación que necesitaba para seguir revisando de inmediato… definitivamente me ayudó a mantenerme comprometida con mis trabajos, incluso a la 1 a. m.».
Esa inmediatez elimina el bloqueo del escritor. En lugar de enfrentarse a una página en blanco mientras espera a la clase del lunes, Elizabeth utiliza la IA para identificar patrones recurrentes, lo que hace que su flujo de trabajo sea mucho más eficiente.
Lo que la IA no puede sentir: el peso de la humanidad.
A pesar de su precisión algorítmica, la IA tiene límites insalvables. El estudio revela un contraste fascinante: la IA suele centrarse en preocupaciones de «alto orden» (la estructura, el esqueleto del argumento), mientras que los humanos aportan la «carne» y el contexto.
Hay tres elementos que la IA simplemente no puede replicar:
Conocimiento contextual: los estudiantes comprenden los desafíos específicos del curso y lo que el profesor realmente valora.
Empatía y tono alentador: un algoritmo no puede motivar a un estudiante que duda de sus capacidades.
Audiencia auténtica: un ser humano reacciona emocionalmente. Elizabeth lo comprobó cuando un compañero le confesó que su texto sobre el cuidado de pacientes sonaba «aterrador» y «desalentador». Esa respuesta subjetiva, vital para la conciencia retórica, es algo que la IA jamás podrá sentir.
De copiar y pegar a la «decisión ejecutiva».
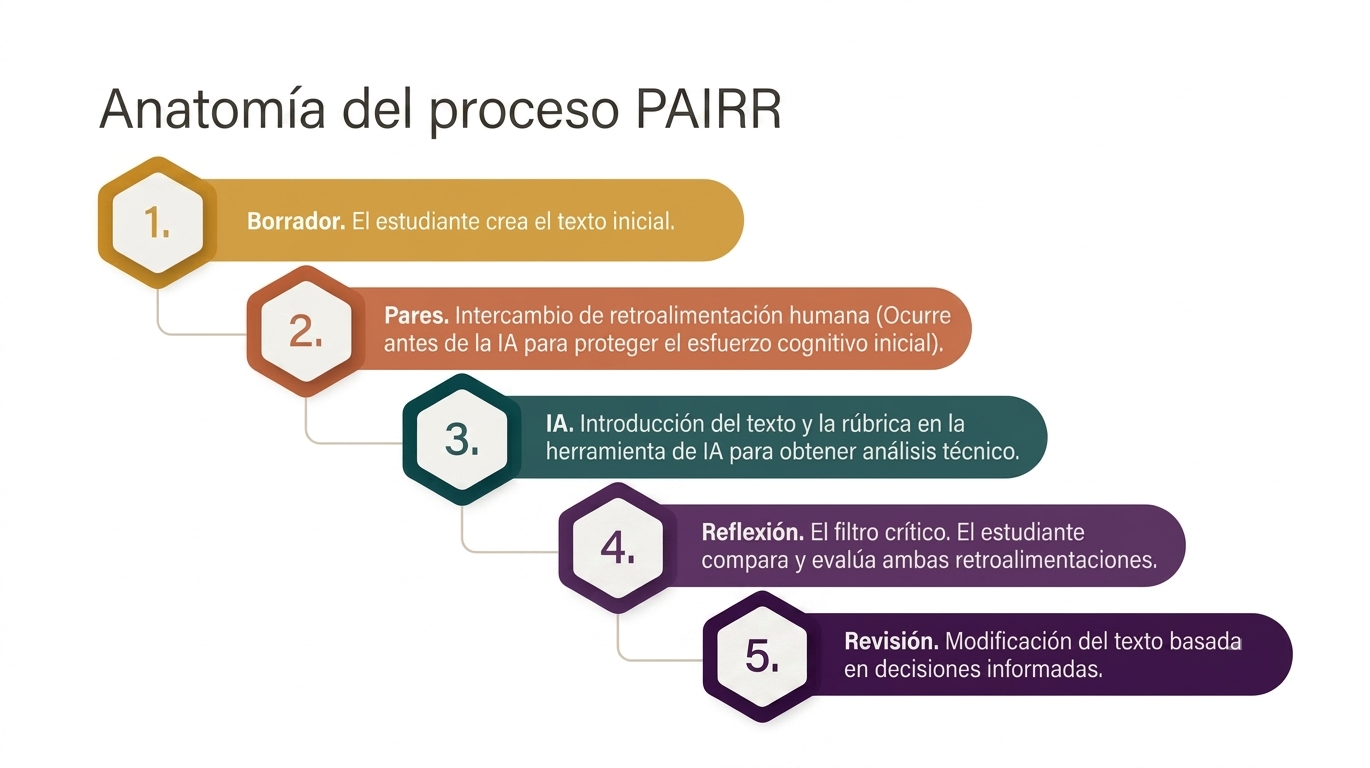
El modelo PAIRR no fomenta la pereza, sino la alfabetización en IA. El objetivo es que el estudiante no acepte ciegamente lo que dice la máquina, sino que ejerza su agencia como escritor. Al verse obligado a comparar dos fuentes de comentarios, el estudiante debe tomar lo que los investigadores llaman una «decisión ejecutiva».
El proceso PAIRR se consolida en cinco pasos críticos:
Borrador: creación de la versión inicial.
Feedback de pares: obtención de la perspectiva humana y emocional.
Feedback de IA: uso de la rúbrica para realizar un análisis técnico y estructural.
Reflexión: análisis comparativo en el que el autor decide a quién creer.
Revisión: ajustes finales basados en el juicio crítico del estudiante.
Cerrando la brecha de equidad.
La IA tiene el potencial de ser un gran nivelador. Para escritores multilingües como Irina, para quien el inglés es su tercer idioma, la IA ofrece un espacio seguro. Irina utiliza la tecnología para pulir la gramática y las normas del inglés académico estándar antes de someterlo a la revisión humana, lo que reduce la intimidación inicial.
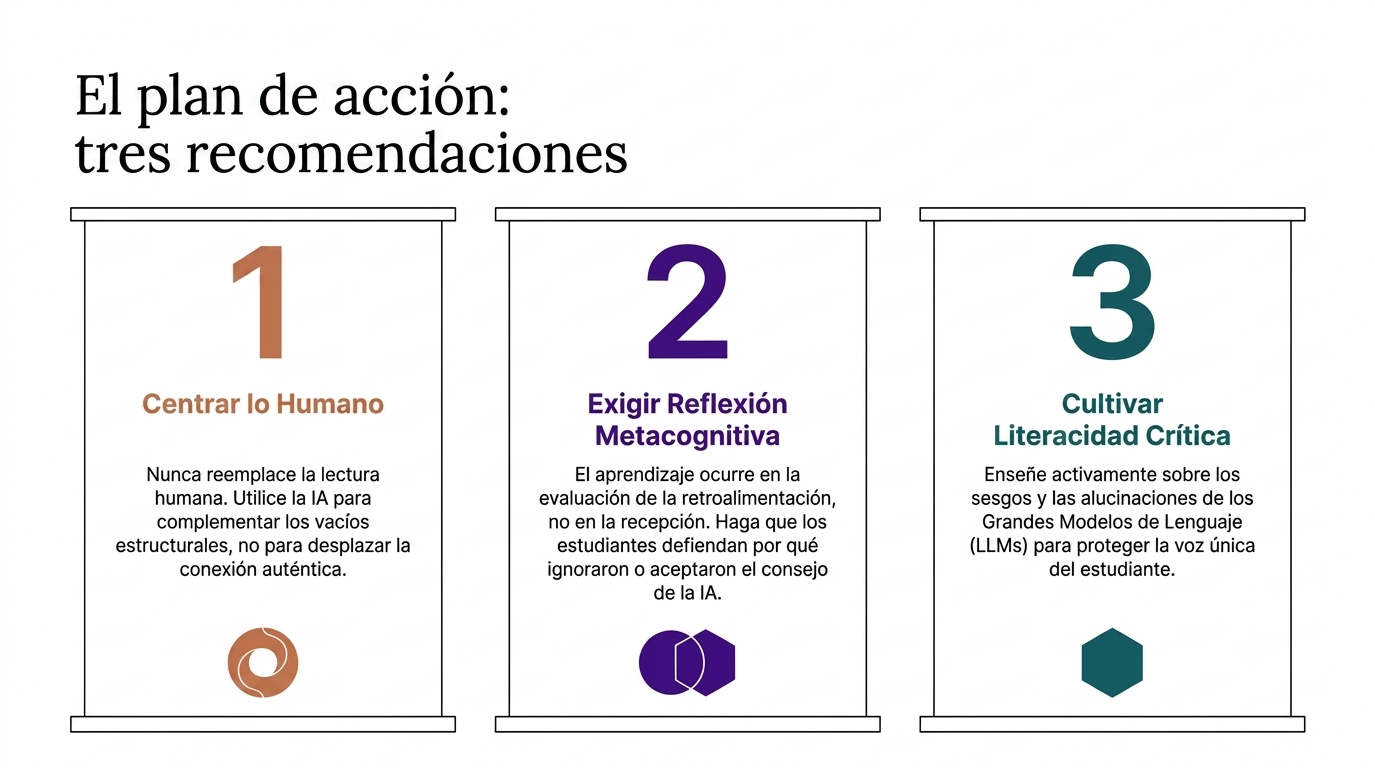
Sin embargo, el estudio no ignora los riesgos. Los modelos de lenguaje pueden perpetuar los sesgos lingüísticos de los grupos dominantes. Por eso, el modelo PAIRR es fundamental: en lugar de prohibir la tecnología y permitir que los estudiantes la utilicen a escondidas, los profesores los guían para que aprendan a evaluar el sesgo en lugar de aceptarlo ciegamente.
Conclusión y reflexión final.
El hallazgo más importante de la Universidad de California es que la tecnología no crea entornos de aprendizaje ricos, sino que son los profesores y las relaciones humanas quienes los hacen. La IA es una herramienta «infaliblemente útil», pero su valor solo florece cuando hay un ser humano en el centro que toma las decisiones.
En el mundo laboral del mañana, la habilidad más valiosa no será escribir de forma aislada, sino colaborar con la IA de manera ética, crítica y analítica.
Pregunta de cierre: ¿qué pasaría con la calidad de nuestras ideas si dejáramos de ver la IA como una herramienta de reemplazo y empezáramos a usarla como a un colega que nos obliga a justificar cada una de nuestras decisiones?
En esta conversación puedes escuchar las ideas más interesantes sobre este tema.
Este vídeo resume bien los conceptos básicos de este artículo.
Dentro del proyecto de innovación docente PROFUNDIA, hemos realizado una investigación cualitativa sobre la percepción de los estudiantes respecto de la capacidad de la inteligencia artificial para resolver problemas de ingeniería. Se realizó mediante una variante de la técnica de «focus group» en una clase de 10 alumnos del Máster Universitario en Ingeniería del Hormigón de la Universitat Politècnica de València. A continuación describimos cómo se realizó la investigación y adelantamos algunas de las conclusiones más interesantes.
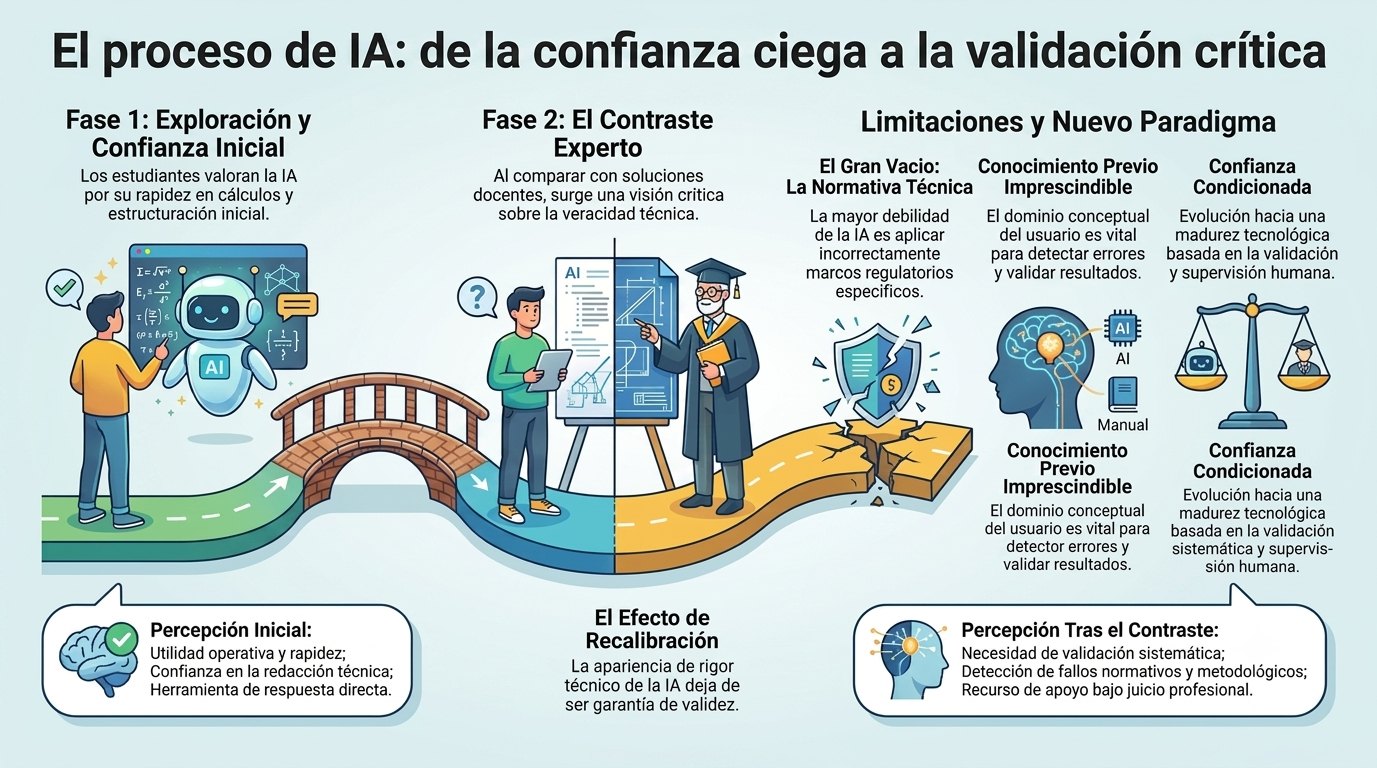
La presente investigación tuvo como objetivo analizar cómo perciben los estudiantes universitarios la capacidad de la inteligencia artificial generativa (IAG) para resolver problemas de ingeniería y, en especial, cómo evolucionan dichas percepciones cuando tienen la oportunidad de contrastar las respuestas proporcionadas por la IA con una solución correcta validada por el profesorado.
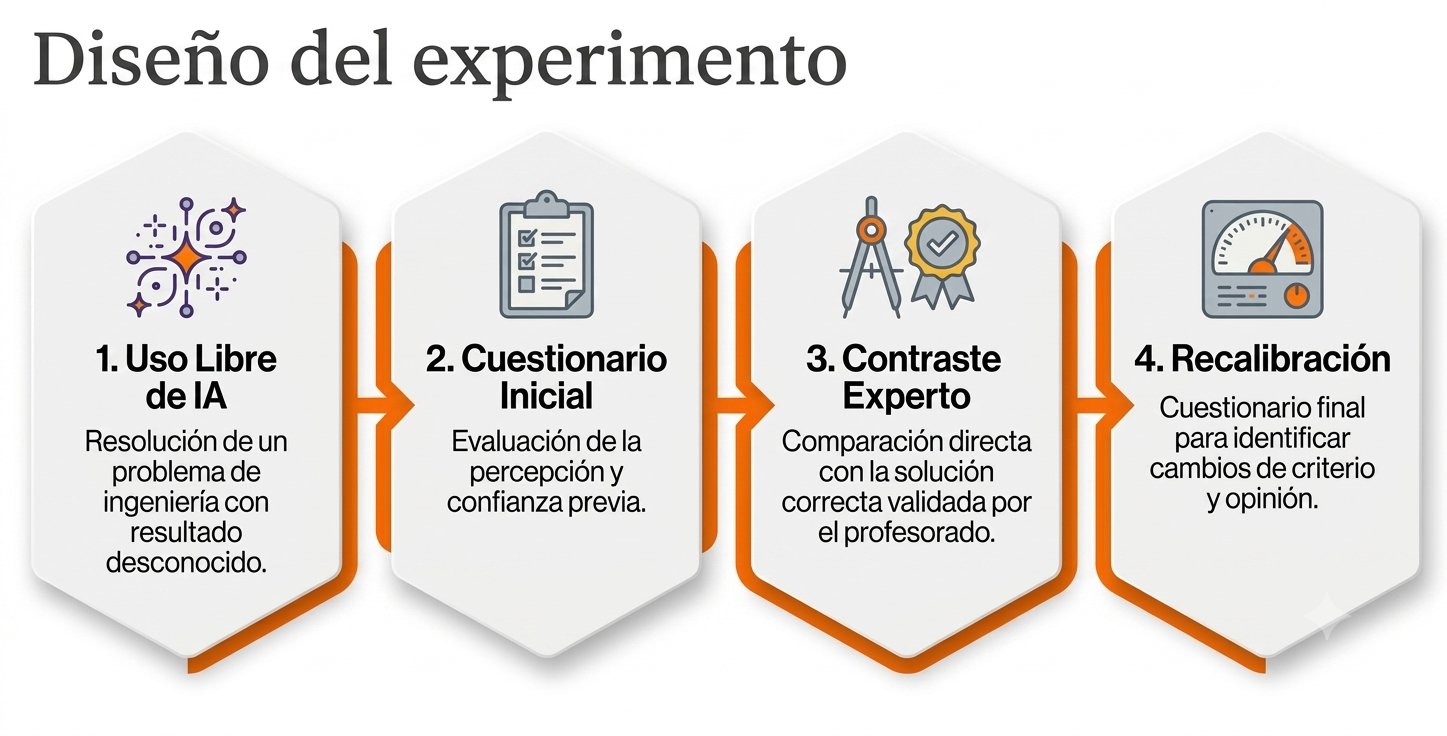
Para ello, se diseñó una experiencia en dos fases. En la primera, los participantes utilizaron libremente herramientas de inteligencia artificial para resolver un problema de ingeniería cuyo resultado desconocían y, posteriormente, respondieron a un cuestionario de preguntas abiertas. En la segunda fase, una vez facilitada la resolución correcta del problema, los estudiantes compararon ambos resultados y completaron un nuevo cuestionario orientado a identificar posibles cambios en sus opiniones, niveles de confianza y criterios de valoración.
Los resultados muestran que los estudiantes parten de una actitud generalmente favorable hacia la inteligencia artificial. La mayoría considera que estas herramientas son útiles para apoyar el aprendizaje, agilizar los cálculos, estructurar procedimientos o proporcionar orientación inicial en la resolución de problemas técnicos. Sin embargo, incluso antes de conocer la solución correcta, ya se observa una percepción relativamente madura de sus propias limitaciones. Los participantes manifiestan reiteradamente que las respuestas obtenidas deben ser verificadas mediante la normativa técnica, la bibliografía especializada o el propio razonamiento, lo que evidencia una confianza condicionada más que una aceptación acrítica de los resultados generados por la IA.
La comparación posterior con la resolución correcta produjo un efecto significativo de recalibración de la confianza. Los estudiantes comprobaron que la inteligencia artificial era capaz de generar respuestas técnicamente plausibles y bien redactadas, pero no necesariamente correctas desde el punto de vista normativo o metodológico. Esta constatación reforzó la percepción de que la apariencia de rigor técnico no constituye una garantía de validez. Tras la experiencia, las opiniones evolucionaron de una valoración centrada en la utilidad operativa de la herramienta a una visión más crítica, basada en la necesidad de validar sistemáticamente cualquier resultado antes de aceptarlo como correcto.
Uno de los hallazgos más relevantes del estudio es la identificación de la normativa técnica como uno de los ámbitos en los que los estudiantes perciben mayores limitaciones al uso de la inteligencia artificial. Numerosos participantes señalaron que las respuestas generadas no incorporaban adecuadamente los criterios establecidos en las normas aplicables, omitían condicionantes relevantes o utilizaban referencias incorrectas. En consecuencia, la principal fuente de error detectada no se relacionó tanto con la capacidad de cálculo de la herramienta como con su dificultad para interpretar y aplicar correctamente los marcos regulatorios específicos. Esta percepción resulta especialmente relevante en el ámbito de la ingeniería, donde la adecuación normativa constituye un requisito esencial para la validez de cualquier solución técnica.
El análisis también revela una comprensión creciente por parte de los estudiantes del funcionamiento y de las limitaciones inherentes de los sistemas de inteligencia artificial. A medida que reflexionaban sobre los errores detectados, los participantes identificaban fenómenos como la generación de respuestas plausibles sin fundamento suficiente, la tendencia a proporcionar una respuesta incluso cuando la información disponible es insuficiente o la dependencia de fuentes cuya calidad no siempre puede verificarse. Esta toma de conciencia constituye un indicio del desarrollo de competencias de alfabetización en inteligencia artificial y de una comprensión más sofisticada de los riesgos asociados a su uso.
Otro aspecto especialmente significativo es que los estudiantes concluyen prácticamente de manera unánime que el uso eficaz de la inteligencia artificial requiere sólidos conocimientos previos sobre la materia consultada. Lejos de considerar que estas herramientas puedan sustituir el aprendizaje o el criterio profesional, los participantes afirman que la capacidad para detectar errores, formular preguntas adecuadas y validar resultados depende directamente del dominio conceptual del usuario. Desde esta perspectiva, la IA se percibe como una herramienta de apoyo cuyo valor aumenta cuando se utiliza desde una posición de conocimiento y de pensamiento crítico.
En términos educativos, la experiencia pone de manifiesto el potencial formativo de actividades basadas en la comparación entre respuestas generadas por la inteligencia artificial y soluciones correctas validadas por expertos. Este tipo de ejercicios no solo permite evaluar la fiabilidad de la herramienta en contextos específicos, sino que también favorece el desarrollo de competencias fundamentales para el futuro ejercicio profesional, tales como la capacidad de análisis crítico, la verificación de la información, la interpretación normativa y la toma de decisiones fundamentadas.
En conclusión, los resultados indican que la experiencia no conduce a un rechazo de la inteligencia artificial, sino a una comprensión más realista de sus capacidades y limitaciones. Los estudiantes mantienen una valoración positiva de estas herramientas como recurso de apoyo, pero desarrollan simultáneamente una actitud más prudente y reflexiva respecto a su utilización. La principal transformación observada consiste en el paso de una confianza basada en la aparente calidad de las respuestas a una confianza condicionada por la necesidad de validación, de supervisión humana y de juicio profesional. Este cambio puede interpretarse como un indicador de madurez tecnológica y constituye uno de los resultados más relevantes de la investigación.
En esta conversación puedes escuchar cómo hemos realizado esta investigación cualitativa.
El vídeo resume bien las ideas más importantes de este tema.
Referencia:
YEPES-BELLVER, L.; MARTÍNEZ-PAGÁN, P.; YEPES, V. (2026). Impacto de la inteligencia artificial en la formación técnica: aprendizaje profundo, metacognición y transferibilidad profesional. En libro de actas: XII Congreso de Innovación Educativa y Docencia en Red. Valencia, 9-10 de julio de 2026.
Os presento un Manual de Referencia sobre la fabricación y la puesta en obra del hormigón. Este libro ofrece una visión integral de la fabricación y la puesta en obra del hormigón, tanto en el ámbito de la edificación como en el de la ingeniería civil. Aborda los equipos y procesos asociados a la preparación del hormigón —incluidas las centrales de hormigonado—, su transporte, vertido, compactación y curado, así como los hormigones especiales, los pavimentos de hormigón para carreteras y el hormigón pretensado. La principal aportación de la obra es su enfoque constructivo, apoyado en abundante material gráfico —fotografías e ilustraciones— que refuerza y clarifica las explicaciones. El texto se completa con una amplia bibliografía, cuestiones de autoevaluación con sus respuestas y problemas resueltos que facilitan la consolidación de los conceptos fundamentales. Concebido como libro de texto para estudiantes de ingeniería y arquitectura, ofrece una orientación práctica clara para la construcción. Al mismo tiempo, está estructurado como un manual de consulta para profesionales vinculados al proyecto y a la ejecución de obras, complementando los contenidos de otros textos de carácter estructural o geotécnico, habitualmente más centrados en el desarrollo teórico y en el cálculo.
El libro está editado a todo color, con 452 páginas, 214 fotografías y dibujos, así como 200 preguntas tipo test (con sus respuestas) y un total de 19 ejercicios totalmente resueltos.
Víctor Yepes Piqueras. Doctor Ingeniero de Caminos, Canales y Puertos. Catedrático de Universidad del Departamento de Ingeniería de la Construcción y Proyectos de Ingeniería Civil de la Universitat Politècnica de València. Consejero del Sector de Docencia e Investigación del Colegio de Ingenieros de Caminos, Canales y Puertos. Número 1 de su promoción, ha desarrollado su vida profesional en empresas constructoras, en el sector público y en el ámbito universitario. Ha recibido el Premio a la Excelencia Docente del Consejo Social, así como el Premio a la Trayectoria Excelente en Investigación y el Premio al Impacto Excelente en Investigación, ambos otorgados por la Universitat Politècnica de València. Es investigador del Instituto de Ciencia y Tecnología del Hormigón (ICITECH) y profesor visitante en la Pontificia Universidad Católica de Chile. Ha sido director académico del Máster Universitario en Ingeniería del Hormigón (acreditado con el sello EUR-ACE). Imparte docencia en asignaturas de grado y posgrado relacionadas con los procedimientos de construcción y gestión de obras, la calidad e innovación, los modelos predictivos y la optimización en la ingeniería. Sus líneas de investigación actuales se centran en la optimización multiobjetivo, la sostenibilidad y el análisis de ciclo de vida de puentes y estructuras de hormigón.
Referencia:
YEPES, V. (2026). Fabricación y puesta en obra del hormigón. Colección Manual de Referencia, serie Ingeniería Civil. Editorial Universitat Politècnica de València, 452 pp. Ref. 441. ISBN: 978-84-1396-418-8
A continuación, os podéis descargar las primeras páginas del libro y su índice:
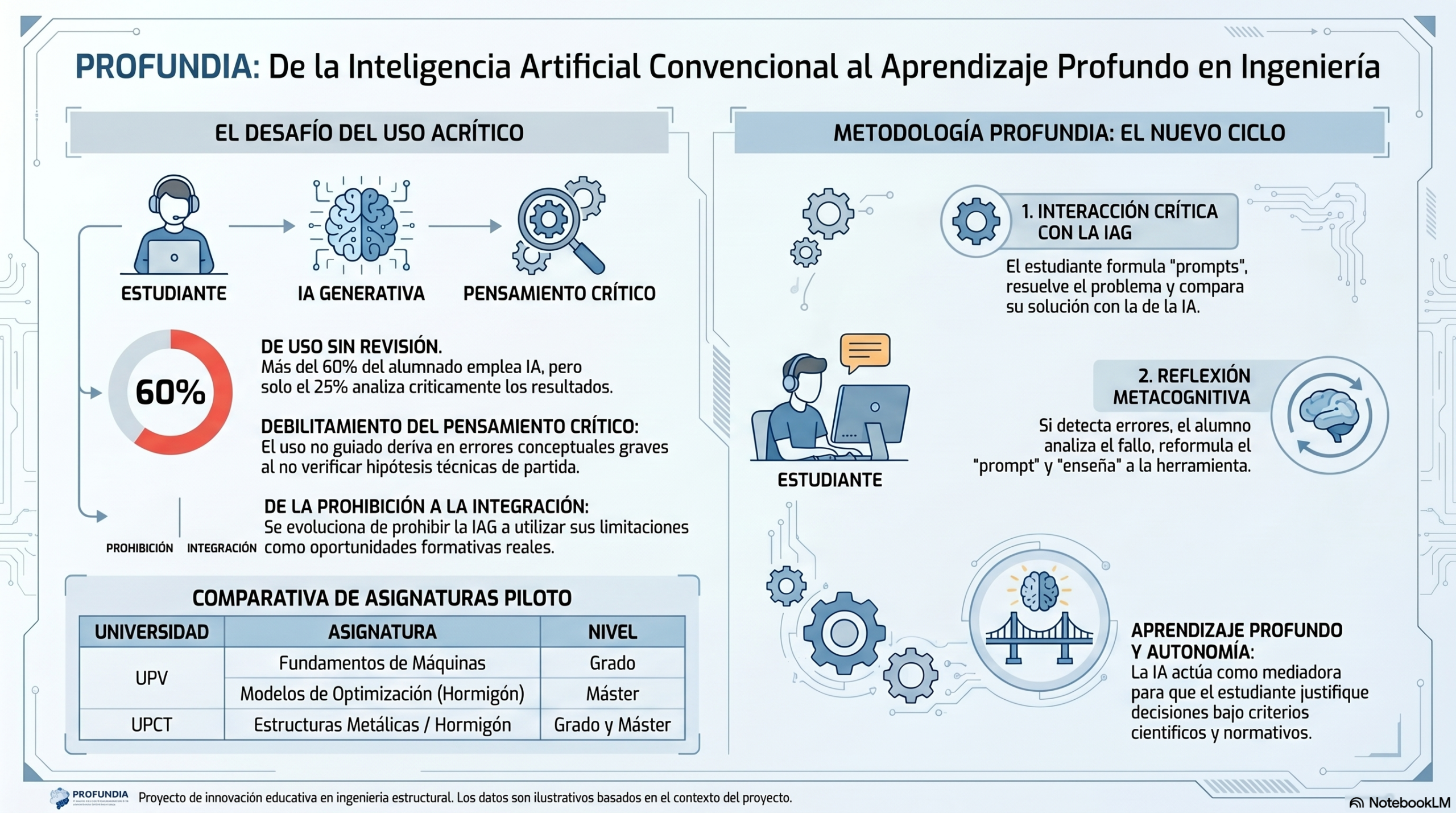
La educación técnica atraviesa una tensión paradójica que amenaza los cimientos del pensamiento crítico. En las asignaturas de modelización y diseño estructural de los grados y másteres en Ingeniería de Caminos y Civil, la inteligencia artificial generativa (IAG) ha pasado de ser una novedad a convertirse en un estándar operativo. Sin embargo, esta adopción generalizada esconde un riesgo sistémico: el «desempleo cognitivo».
Datos recientes de la Universitat Politècnica de València (UPV) y la Universidad Politécnica de Cartagena (UPCT) revelan que, si bien el 60 % del alumnado utiliza estas herramientas, solo el 25 % revisa críticamente los resultados. La solución no consiste en imponer restricciones, sino en diseñar una arquitectura pedagógica que integre la IA como un «socio intelectual» bajo el enfoque de mindtools (Jonassen et al., 1999) para potenciar y no sustituir el pensamiento de orden superior.
Ante este desafío nace el proyecto PROFUNDIA. Nuestra misión es clara: transformar la IA de un «atajo peligroso» en un motor de aprendizaje profundo que refuerce la autonomía del futuro ingeniero.
El éxito no radica en la tecnología, sino en la arquitectura de la auditoría humana.
El hallazgo central de la investigación realizada sobre una muestra de 100 estudiantes subraya que la utilidad percibida de la IA no es una propiedad intrínseca del software, sino del proceso de supervisión. La resolución de problemas de alta responsabilidad física, en los que el error tiene consecuencias estructurales, depende de la capacidad de reformularlos y de una supervisión crítica.
En este nuevo paradigma, el valor profesional se desplaza del «saber hacer» procedimental —que puede automatizarse— al «saber validar». El éxito pedagógico está hoy condicionado por la arquitectura del proceso cognitivo de auditoría, en el que el ingeniero actúa como filtro final de la veracidad técnica.
«Los resultados obtenidos mediante análisis estadísticos multivariantes demuestran que el éxito no reside en el mero uso de la tecnología, sino en el proceso cognitivo de auditoría humana».
Ingeniería de la pregunta: el arte de iterar.
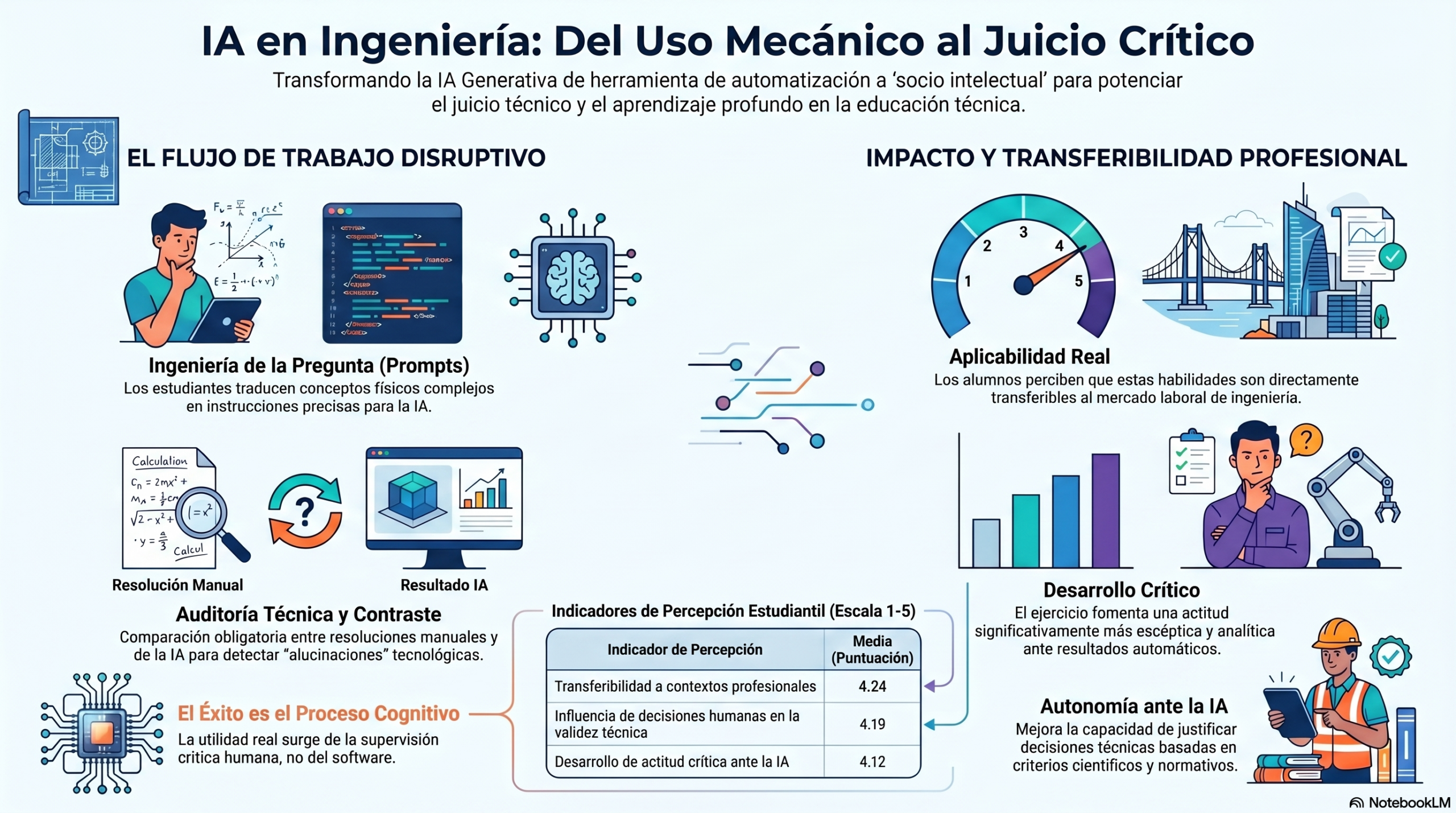
Uno de los pilares de la interacción estratégica es la «ingeniería de la pregunta». No se trata de un simple comando de texto, sino de un ejercicio de abstracción en el que el estudiante debe traducir variables estructurales y conceptos físicos en instrucciones lógicas. El estudio destaca que la clave de esta habilidad transversal no radica en el primer intento, sino en la capacidad de iterar.
El ítem 2 del estudio («Las iteraciones de los mensajes de texto me ayudaron a mejorar progresivamente la calidad») obtuvo una media de 4,11, lo que confirma que la calidad técnica surge de un diálogo dialéctico con la máquina. Este proceso de refinamiento constante combate la «complacencia tecnológica» y garantiza que el usuario mantenga el control sobre el resultado final.
El valor disruptivo de buscar deliberadamente el error.
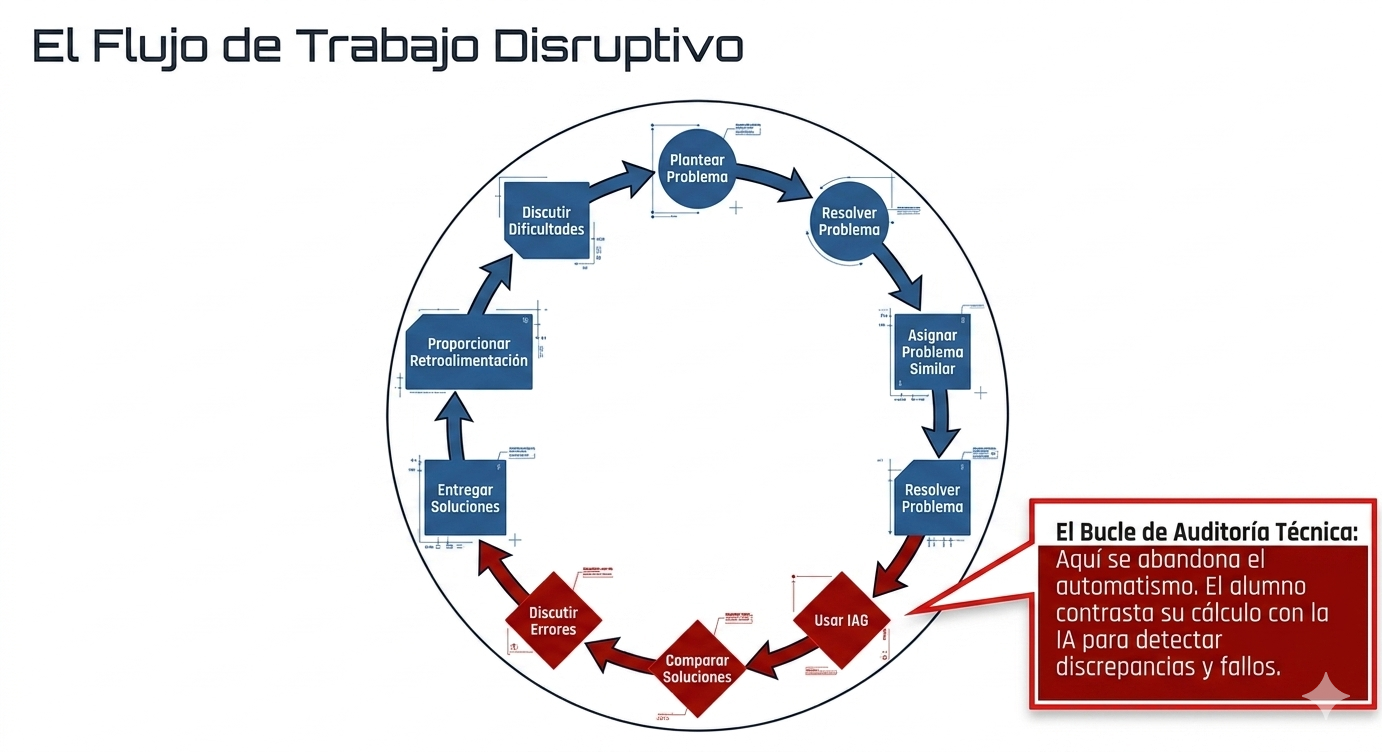
La innovación docente más potente consiste en utilizar la IA con un «sesgo deliberado hacia el error». En lugar de aceptar la respuesta de la IA como una verdad absoluta, el flujo de trabajo propuesto obliga al alumnado a realizar un «contraste crítico»: primero, deben resolver el problema manualmente y, después, interpelar a la IA para buscar activamente la «alucinación» o el fallo técnico.
Este enfoque es crucial desde el punto de vista estadístico. El ítem 4 (comparación entre la resolución manual y la IA) se identificó, mediante modelos de regresión múltiple, como uno de los tres predictores clave del éxito. Al buscar el fallo, el estudiante activa una reflexión metacognitiva, aprende a pensar sobre cómo piensa y fortalece su criterio técnico al corregir el algoritmo.
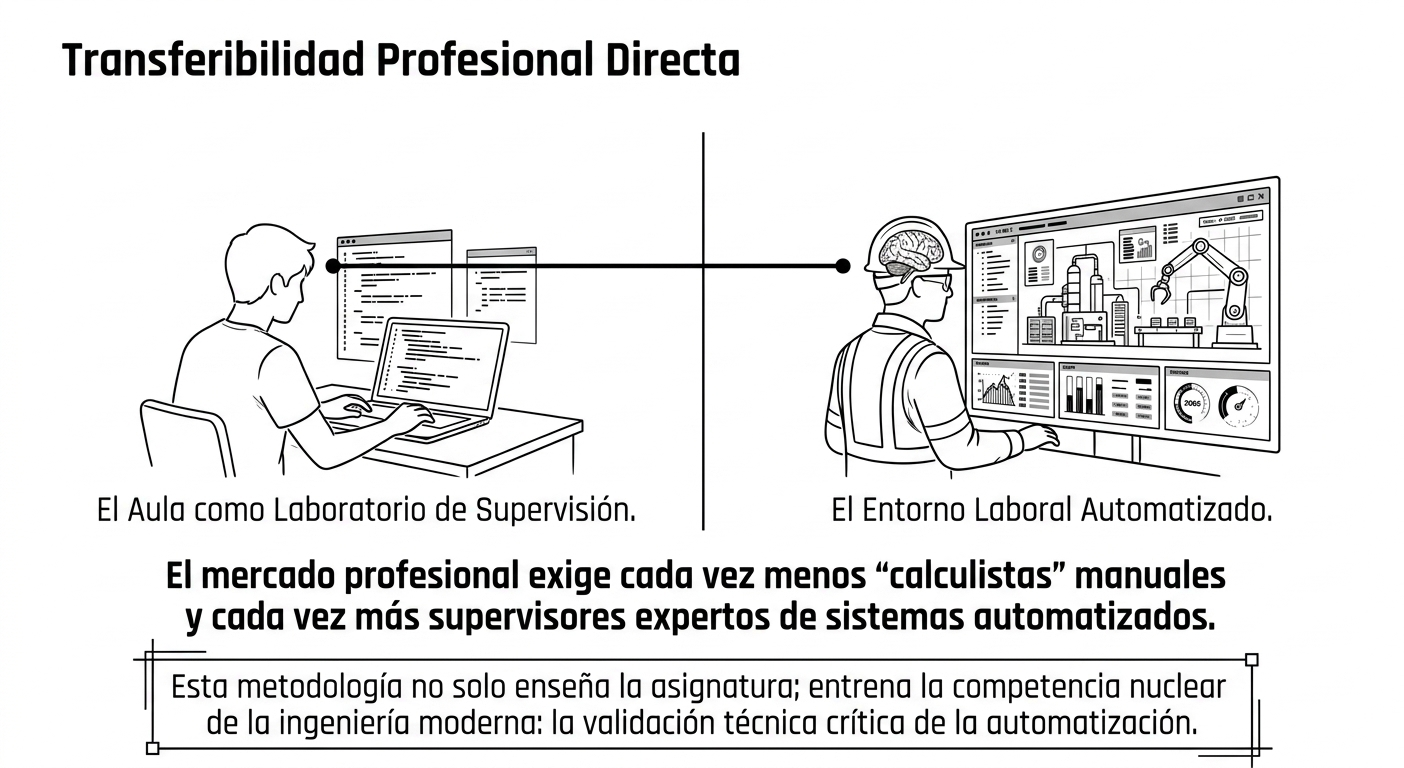
De las aulas al mercado laboral: la transferibilidad de la autorregulación.
La relevancia de esta formación trasciende las calificaciones. Los datos son contundentes: la pregunta 9 («Las habilidades se pueden aplicar en contextos profesionales») obtuvo la puntuación más alta del cuestionario, 4,24. Los futuros ingenieros son conscientes de que la supervisión experta de sistemas automatizados ya es una competencia esencial en la industria moderna.
La solidez de este modelo se demuestra por su capacidad explicativa, ya que la valoración global de la IA (punto 10) se explica en un 37,7 % (R² corregida) por la combinación de tres factores: la capacidad de reformular el problema (punto 1), la detección de errores por contraste (punto 4) y la percepción de la transferibilidad profesional (punto 9).
«Esta metodología favorece la adquisición de competencias esenciales en entornos profesionales donde se requiere la supervisión experta de sistemas automatizados, y prepara al ingeniero para entornos de alta complejidad».
Conclusión: ingenieros de decisiones, no usuarios de software.
La inteligencia artificial, lejos de mermar el rigor científico, puede ser el mayor catalizador del aprendizaje profundo si se gestiona desde la «autorregulación crítica» (componente 1 del análisis factorial). El futuro de la ingeniería no pertenece a quienes saben usar herramientas, sino a quienes son capaces de enseñar, corregir y auditar a la máquina según criterios científicos y normativos.
En última instancia, nos enfrentamos a una pregunta que definirá la resiliencia de la profesión ante la obsolescencia tecnológica: en un contexto de automatización creciente, ¿estamos formando usuarios de software o educando a los ingenieros de las decisiones del mañana? La responsabilidad ética del ingeniero sigue siendo la última instancia de decisión, y esa carga no puede ni debe asumirla ningún algoritmo.
En esta conversación puedes escuchar las ideas más interesantes sobre el tema.
En este vídeo se resumen bien los conceptos vistos.
YEPES-BELLVER, L.; MARTÍNEZ-PAGÁN, P.; YEPES, V. (2026). Impacto de la inteligencia artificial en la formación técnica: aprendizaje profundo, metacognición y transferibilidad profesional. En libro de actas: XII Congreso de Innovación Educativa y Docencia en Red. Valencia, 9-10 de julio de 2026.
En ingeniería civil, un error de cálculo no es solo una errata en un examen, sino una cuestión de seguridad pública y de responsabilidad ética. Por ello, el panorama actual resulta alarmante: mientras que más del 60 % de los estudiantes reconoce utilizar inteligencia artificial generativa (IAG) en sus tareas, apenas un 25 % realiza una revisión crítica de los resultados.
Esta dependencia acrítica amenaza con diluir el rigor técnico necesario para diseñar infraestructuras seguras. Ante este desafío nace el proyecto PROFUNDIA, liderado por el catedrático Víctor Yepes en la Universitat Politècnica de València (UPV), en colaboración con la Universidad Politécnica de Cartagena (UPCT). Nuestra misión es clara: transformar la IA de un «atajo peligroso» en un motor de aprendizaje profundo que refuerce la autonomía del futuro ingeniero.
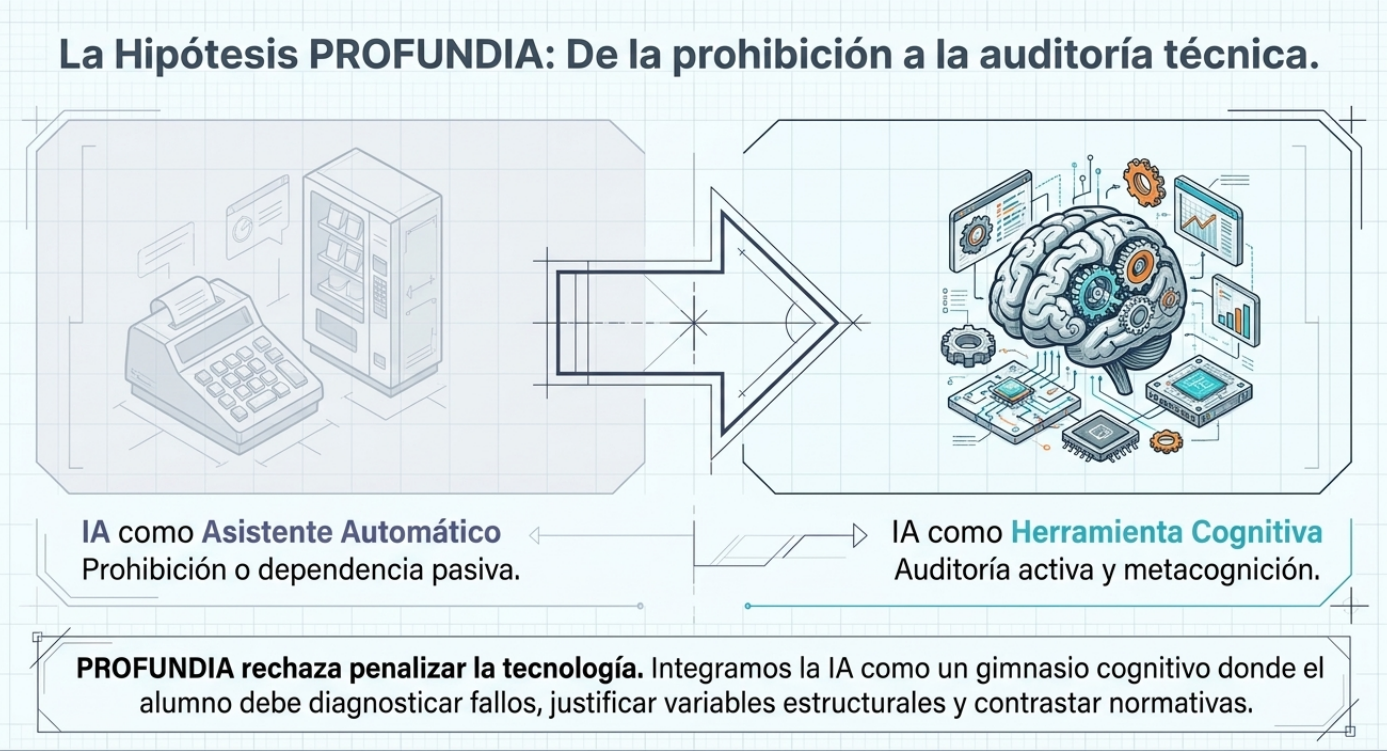
El fin de la era de la prohibición: de «No usar» a «Usar para pensar».
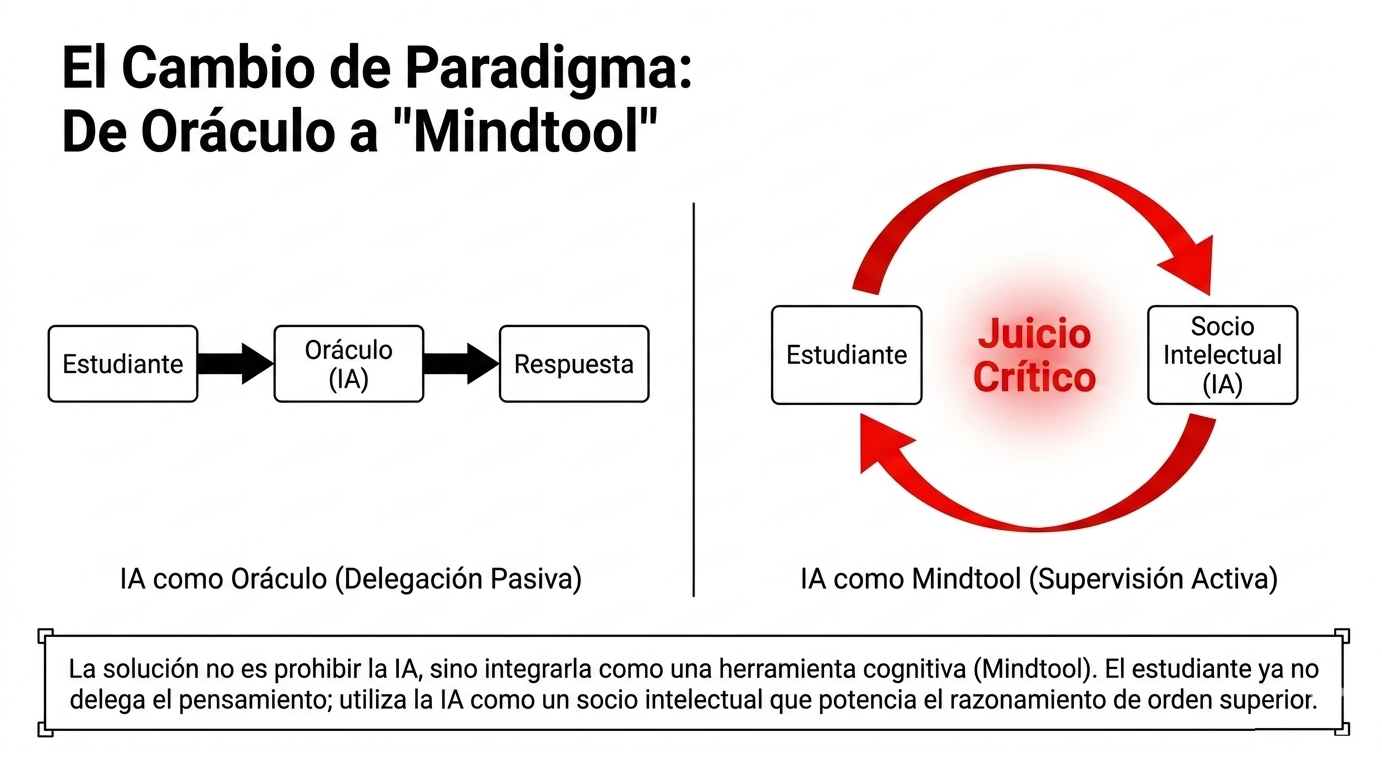
Durante los últimos años, la respuesta académica dominante ha sido la restricción. Sin embargo, en un entorno profesional de alta exigencia, prohibir la tecnología es una batalla perdida que solo agrava la brecha entre el aula y la realidad. PROFUNDIA propone un cambio de paradigma radical: integrar la IA como una «herramienta cognitiva» o «mindtool», bajo la filosofía constructivista de Jonassen.
No buscamos que el estudiante aprenda «de» la tecnología como si esta fuera un oráculo, sino «con» la tecnología. Al utilizar la IA como mediadora, el alumno no se limita a recibir datos, sino que debe «luchar» con la herramienta para construir un modelo mental sólido de los fenómenos físicos. En ingeniería, el objetivo no es obtener el número final, sino comprender el comportamiento estructural que ese número representa.
«Enseñar» a la IA para aprender ingeniería.
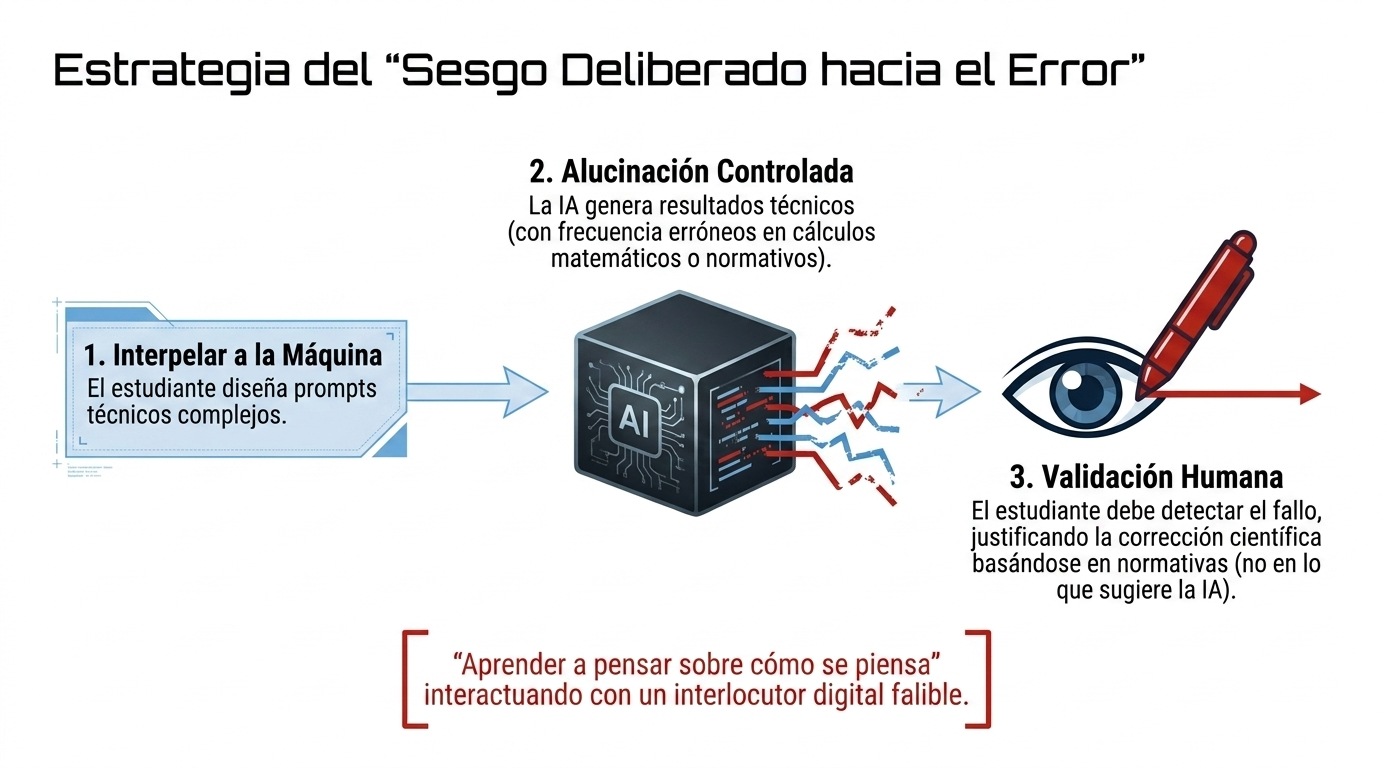
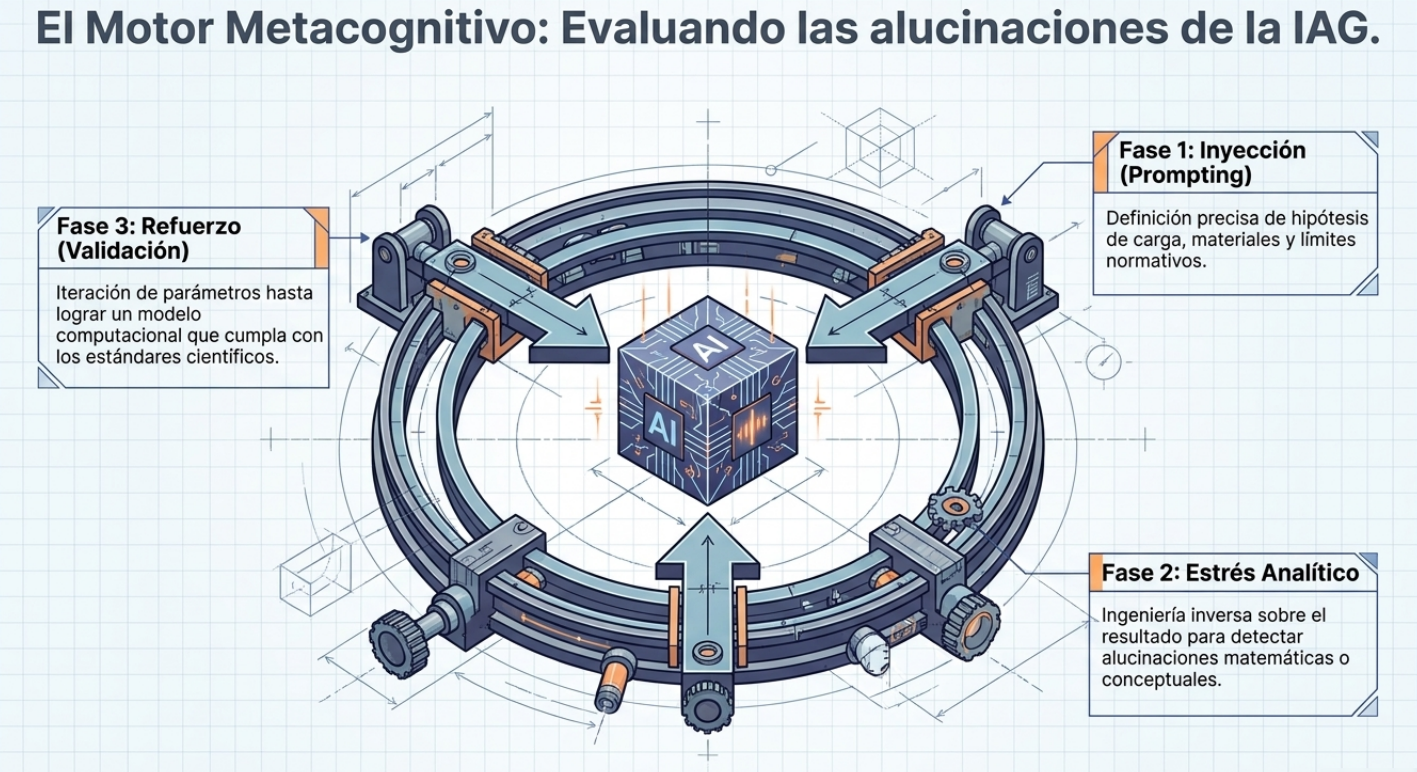
El corazón de nuestra metodología se basa en un concepto disruptivo: el «sesgo deliberado hacia el error». En asignaturas críticas como «Modelos predictivos de estructuras de hormigón» o «Resistencia de materiales», hemos observado que la IA tiende a «alucinar» al proponer hipótesis de partida o al aplicar normativas específicas. En lugar de considerar esto como una limitación, lo convertimos en nuestra principal ventaja pedagógica.
Obligamos al estudiante a enfrentarse a las respuestas de la IA no como verdades absolutas, sino como borradores que deben ser auditados. Para corregir los cálculos de la máquina en una viga o en un pórtico, el alumno primero debe dominar la teoría de forma exhaustiva.
«En PROFUNDIA, el estudiante invierte los roles tradicionales: deja de ser un receptor pasivo para convertirse en el «maestro» de la IA, validando, cuestionando y corrigiendo la tecnología con su propio juicio técnico y rigor científico».
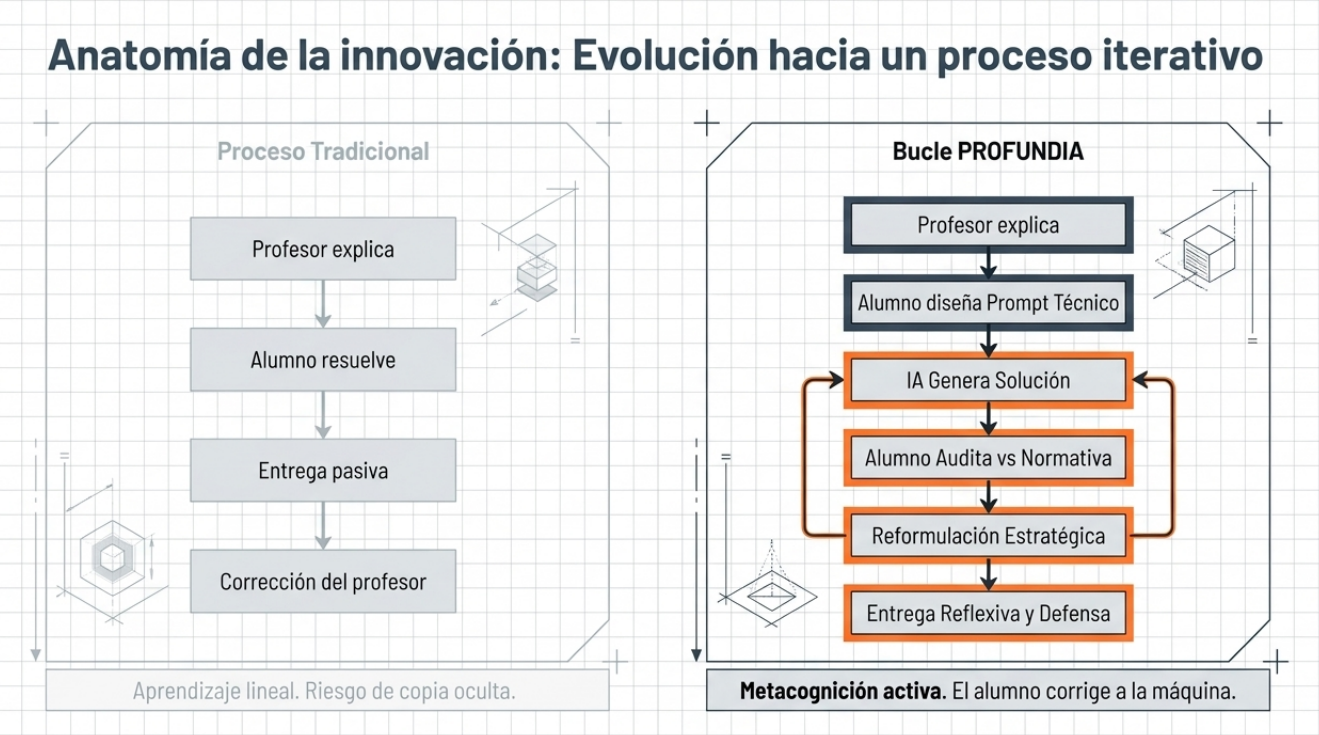
El ciclo del «prompt crítico»: reflexión metacognitiva.
Para estructurar este proceso, hemos diseñado una secuencia metodológica (basada en la Figura 2 del proyecto) que obliga al estudiante a reflexionar metacognitivamente de manera constante.
Formulación del prompt: el alumno debe traducir un problema de estructuras metálicas o de hormigón a un lenguaje técnico preciso, definiendo cargas, luces y condiciones de contorno.
Comparación crítica: se contrasta el resultado de la IA con modelos analíticos propios y con programas informáticos profesionales de cálculo.
Detección de errores y reformulación: aquí es donde ocurre el aprendizaje real. El estudiante debe identificar si el error de la IA se debe a un cálculo matemático incorrecto, a una hipótesis física errónea o a un desconocimiento del Código Estructural. Tras el análisis, debe guiar a la IA, mediante nuevos mensajes, hacia la solución correcta.
Justificación técnica: el paso final consiste en validar la solución según los criterios científicos y normativos vigentes, a fin de garantizar que la respuesta no solo «parezca» correcta, sino que también sea técnicamente viable y segura.
Más allá del aula: preparación para el mundo real.
La colaboración entre la UPV y la UPCT (con los profesores Antonio Tomás y Pedro Martínez-Pagán) permite validar este modelo en diversos contextos, desde los grados hasta los másteres. El objetivo no es simplemente aprobar la asignatura de Estructuras Metálicas, sino desarrollar el criterio técnico experto que hoy demandan las empresas de ingeniería.
En el ejercicio profesional, el ingeniero es el último responsable de la empresa que avala un proyecto. PROFUNDIA prepara a los egresados para que puedan actuar como auditores tecnológicos, capaces de aprovechar la eficiencia de la IA sin comprometer nunca la integridad estructural ni la seguridad de las personas.
Un entorno de aprendizaje enriquecido.
La innovación de este proyecto no radica en el software (ChatGPT es solo una herramienta), sino en la redefinición metodológica del entorno de aprendizaje. Hemos transformado el aula en un laboratorio de interacción social y psicológica en el que la IA actúa como un «agente activo» dentro del equipo de trabajo. Esta dinámica fomenta una mayor implicación del alumnado, que percibe el aprendizaje no como una carga, sino como el desarrollo de la maestría en las herramientas que definirán su futuro.
Conclusión: Hacia una ingeniería de pensamiento profundo.
La visión de PROFUNDIA consiste en formar ingenieros que lideren la tecnología en lugar de depender de ella. La eficiencia de un algoritmo es una herramienta poderosa, pero carece de la comprensión profunda y de la responsabilidad ética que definen nuestra profesión.
Al final, cuando nos enfrentamos al diseño de un puente o una infraestructura de gran envergadura, debemos plantearnos una pregunta provocadora: en un futuro en el que las máquinas pueden realizar cálculos en milisegundos, ¿seremos capaces de formar a ingenieros con la suficiente intuición y criterio técnico como para negarnos a firmar un proyecto que la IA considera «eficiente», pero que el juicio humano reconoce como un riesgo de colapso? El futuro de nuestra seguridad depende de esa capacidad crítica.
En esta conversación puedes escuchar las ideas más interesantes de este proyecto.
Blight, T., Martínez-Pagán, P., Roschier, L., Boulet, D., Yepes-Bellver, L., & Yepes, V. (2025). Innovative approach of nomography application into an engineering educational context. PloS one, 20(2), e0315426.
Castro-Aristizabal, G., Acosta-Ortega, F., & Moreno-Charris, A. V. (2024). Los entornos de aprendizaje y el éxito escolar en Latinoamérica. Lecturas de Economía, (101), 7-46.
Hadgraft, R. G., & Kolmos, A. (2020). Emerging learning environments in engineering education. Australasian Journal of Engineering Education, 25(1), 3-16.
Jiang, N., Zhou, W., Hasanzadeh, S., & Duffy Ph D, V. G. (2025). Application of Generative AI in Civil Engineering Education: A Systematic Review of Current Research and Future Directions. In CIB Conferences (Vol. 1, No. 1, p. 306).
Jonassen, D. H., Peck, K. L., & Wilson, B. G. (1999). Learning with technology: A constructivist perspective. Columbus, OH: Merrill/Prentice-Hall.
Liao, W., Lu, X., Fei, Y., Gu, Y., & Huang, Y. (2024). Generative AI design for building structures. Automation in Construction, 157, 105187.
Navarro, I. J., Marti, J. V., & Yepes, V. (2023). Evaluation of Higher Education Students’ Critical Thinking Skills on Sustainability. International Journal of Engineering Education, 39(3), 592-603.
Onatayo, D., Onososen, A., Oyediran, A. O., Oyediran, H., Arowoiya, V., & Onatayo, E. (2024). Generative AI applications in architecture, engineering, and construction: Trends, implications for practice, education & imperatives for upskilling—a review. Architecture, 4(4), 877-902.
Pellicer, E., Yepes, V., Ortega, A. J., & Carrión, A. (2017). Market demands on construction management: View from graduate students. Journal of Professional Issues in Engineering Education and Practice, 143(4), 04017005.
Perkins, D., & Unger, C. (1999). La enseñanza para la comprensión. Argentina: Paidós.
Torres-Machí, C., Carrión, A., Yepes, V., & Pellicer, E. (2013). Employability of graduate students in construction management. Journal of Professional Issues in Engineering Education and Practice, 139(2), 163-170.
Xu, G., & Guo, T. (2025). Advances in AI-powered civil engineering throughout the entire lifecycle. Advances in Structural Engineering, 13694332241307721.
Zhou, Z., Tian, Q., Alcalá, J., & Yepes, V. (2025). Research on the coupling of talent cultivation and reform practice of higher education in architecture. Computers and Education Open, 100268.
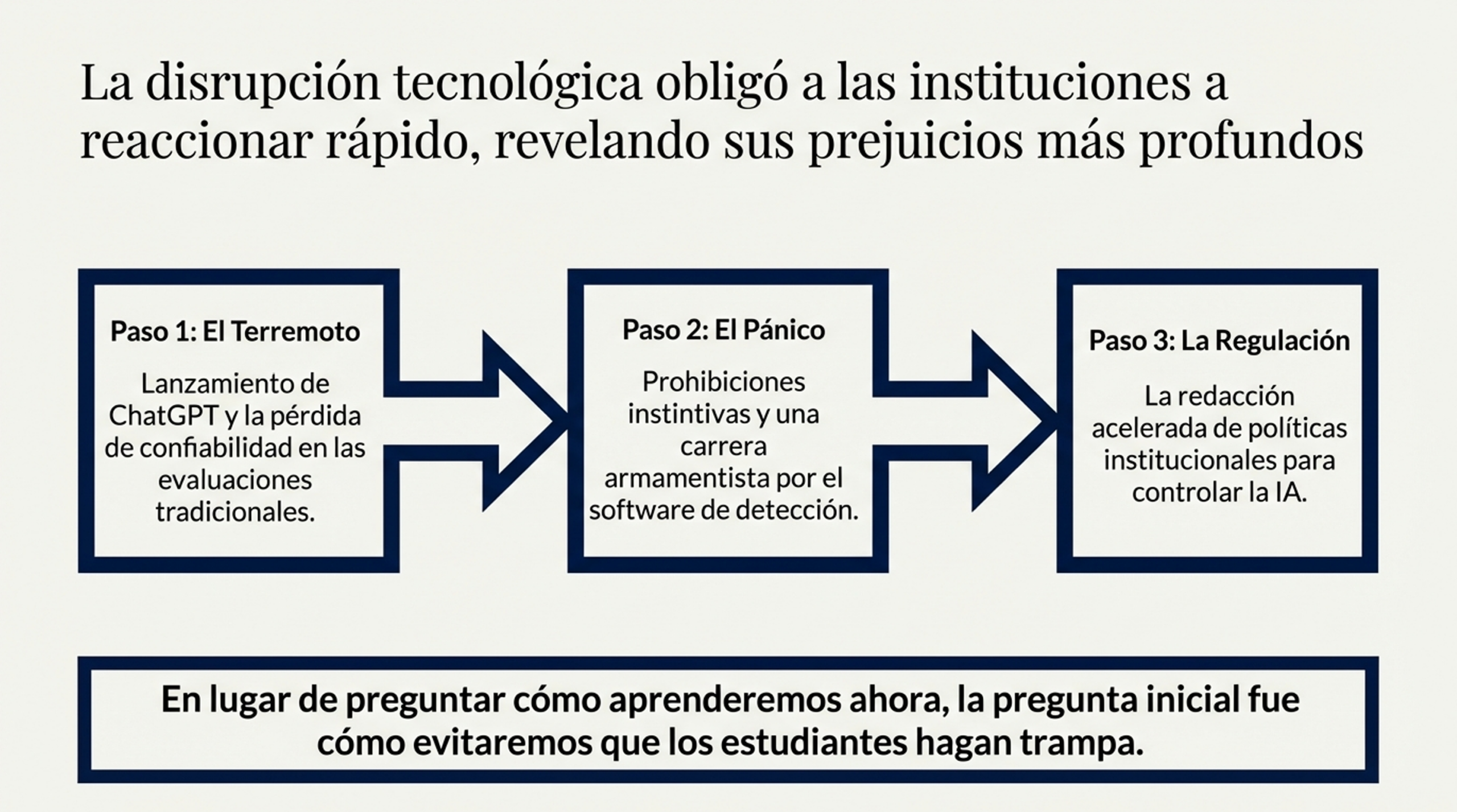
La irrupción de la inteligencia artificial generativa (GenAI) ha hecho saltar por los aires el «contrato de confianza» que sustentaba la evaluación académica. Lo que antes era un acuerdo implícito —que el estudiante era el único autor de cada palabra— hoy se ha transformado en una arquitectura de la sospecha. Pero ¿qué sucede cuando examinamos en profundidad esta crisis?
Un estudio en profundidad de las políticas de las veinte mejores universidades del mundo revela que no se trata solo de ajustar las normas, sino de una lucha desesperada por rescatar una noción de autoría que quizá ya no existe (Luo, 2024).
Como profesor universitario, observo con preocupación cómo la academia no reacciona con pedagogía, sino con una vigilancia que fosiliza el aprendizaje. A continuación, presento cinco revelaciones críticas sobre cómo la universidad está gestionando —o malinterpretando— este cambio de era.
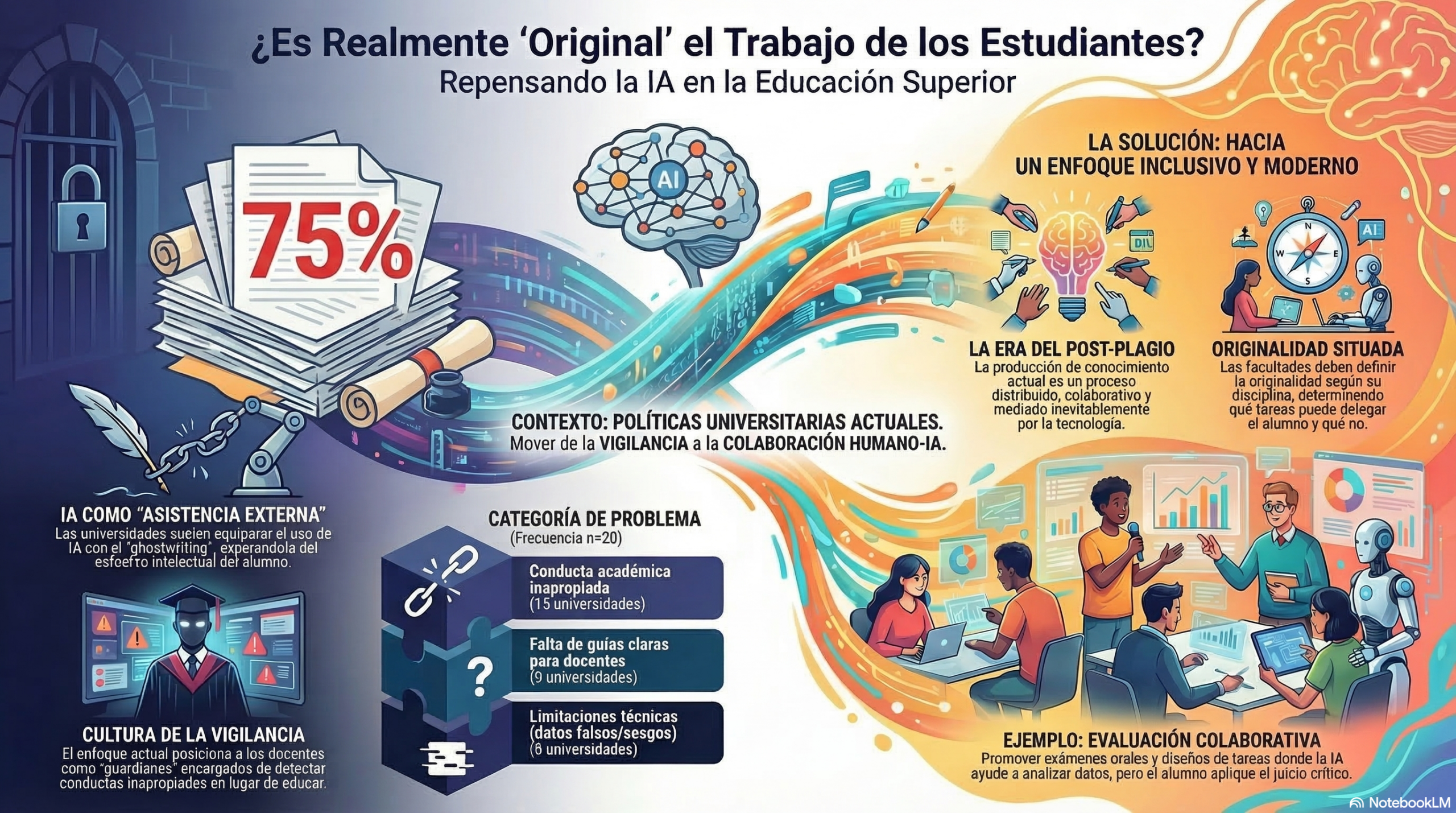
1. La «originalidad» como mecanismo de vigilancia (Marco WPR).
En el marco analítico de Carol Bacchi, What’s the problem represented to be (WPR), descubrimos que las universidades no solo responden a un problema, sino que también lo están creando. Al analizar las políticas de las instituciones de élite, el estudio de Jiahui Luo revela que el «problema» se ha representado casi exclusivamente como la pérdida de la autoría original.
Esta visión se aferra al mito del «genio solitario en el ático» (Johnson-Eilola y Selber), esa idea romántica y obsoleta que sostiene que el trabajo intelectual solo es valioso si se realiza en un vacío social y tecnológico. Al definir la IA como una «ayuda externa» prohibida, las universidades reducen la educación a un ejercicio de detección de fraude. Como señala una de las políticas analizadas:
«Los estudiantes deben ser autores de su propio trabajo. El contenido producido por plataformas de IA, como ChatGPT, no representa el trabajo original del estudiante, por lo que se consideraría una forma de mala conducta académica».
2. El error de la analogía del «escritor fantasma».
Algunas de las universidades analizadas por Luo (2024) han cometido un error fundamental de categoría: equiparan el uso de la IA generativa con el ghostwriting o con la ayuda de un tercero. Esta es una falla de imaginación tecnológica. La IA no es un agente externo, sino una prótesis cognitiva integrada en el flujo de pensamiento contemporáneo.
Tratar a una herramienta como si fuera una persona es ignorar la realidad digital del siglo XXI. El análisis de Luo muestra que las políticas universitarias suelen agrupar los problemas en seis categorías que revelan una mentalidad de «vigilancia primero».
Mala conducta académica: el pánico ante la entrega de trabajos ajenos.
Diseño de evaluación: la urgencia de crear tareas que la IA no pueda «resolver».
Limitaciones tecnológicas: desconfianza en la veracidad de los datos.
Equidad: el riesgo de que se creen brechas entre quienes pueden permitirse una IA avanzada y quienes no.
Políticas y directrices: la falta de claridad por parte de los docentes.
Capacitación y apoyo: la necesidad de una alfabetización urgente.
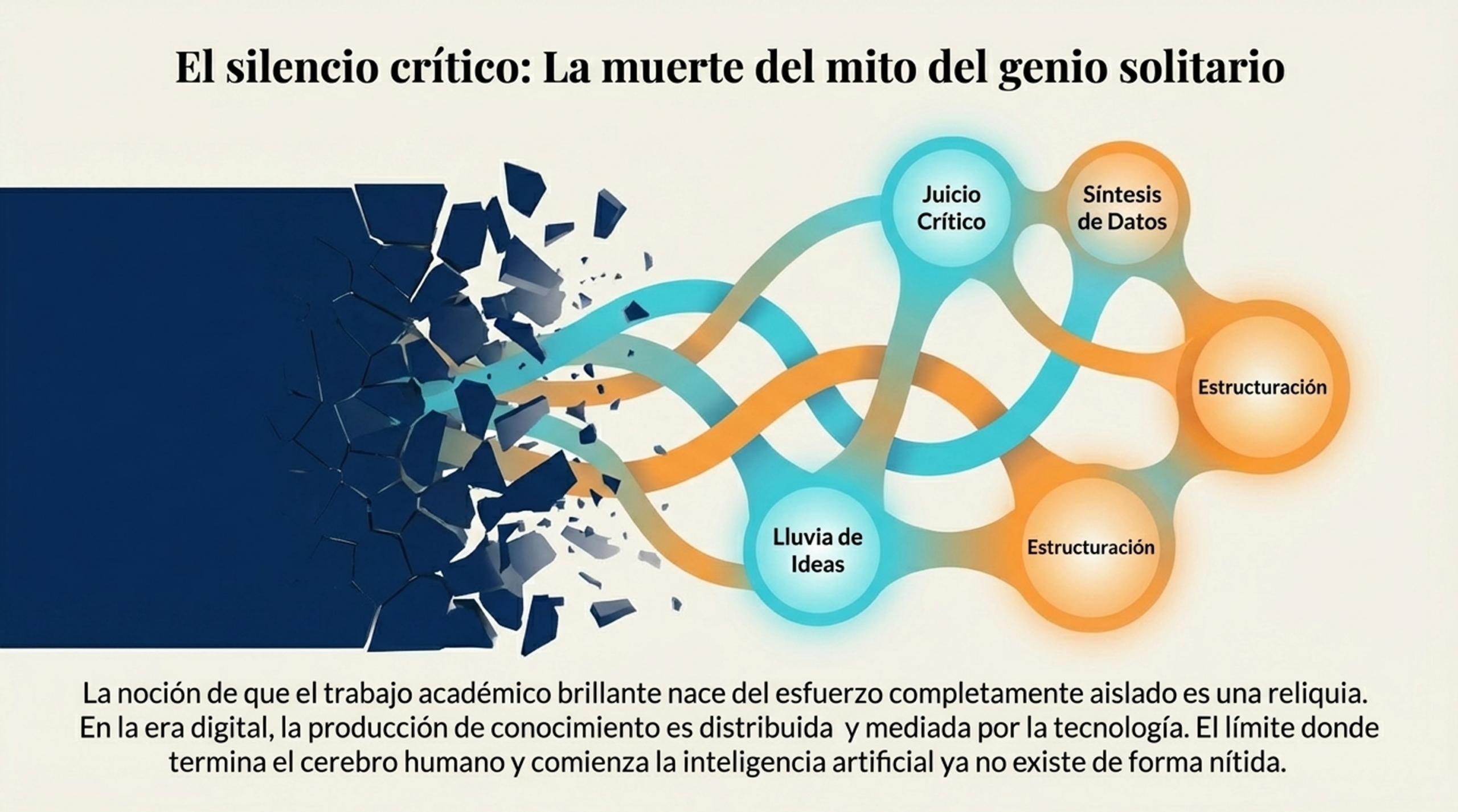
3. El silencio crítico y la «era del posplagio».
Lo más inquietante de estas políticas es lo que callan. Existe un «silencio crítico» sobre el significado de la originalidad en la actualidad. Estamos entrando de lleno en lo que la investigadora Sarah Eaton denomina la era del posplagio. En este nuevo paradigma, la frontera entre lo humano y lo artificial no solo es difusa, sino también irrelevante.
El conocimiento actual es, por naturaleza, distribuido y colaborativo. Al ignorar la evolución del concepto de originalidad, las universidades se desconectan de la realidad. Si el contenido de la IA es «remezclado y reelaborado» por un ser humano, ¿dónde termina la máquina y dónde empieza el autor? Mantener la exigencia de una autoría analógica en un mundo de inteligencia híbrida es una receta para la irrelevancia académica.
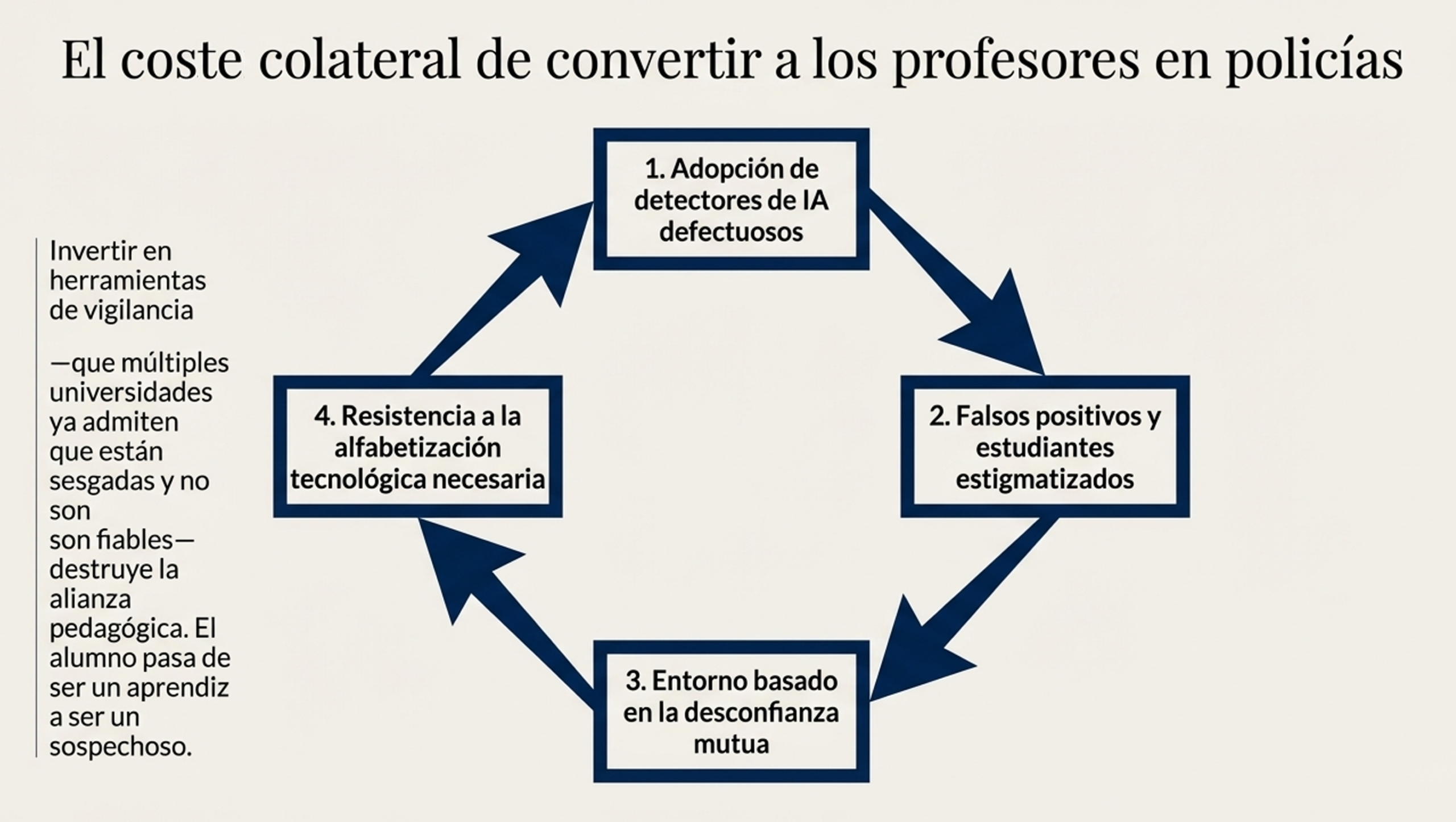
4. El efecto secundario: de docentes a policías.
Siguiendo el análisis de los efectos de las políticas (pregunta 5 del marco WPR), se observa una erosión pedagógica alarmante. Los profesores están siendo desplazados de su papel de mentores para convertirse en «guardianes» o vigilantes de la frontera.
Este enfoque de patrullaje tiene consecuencias reales: los estudiantes son tratados como sospechosos desde el principio. Esto genera una cultura de desconfianza en la que el alumno se vuelve reacio al uso legítimo de las herramientas tecnológicas por miedo a la estigmatización. Si el sistema está diseñado para «atrapar» al infractor en lugar de implicar al alumno, la relación pedagógica muere.
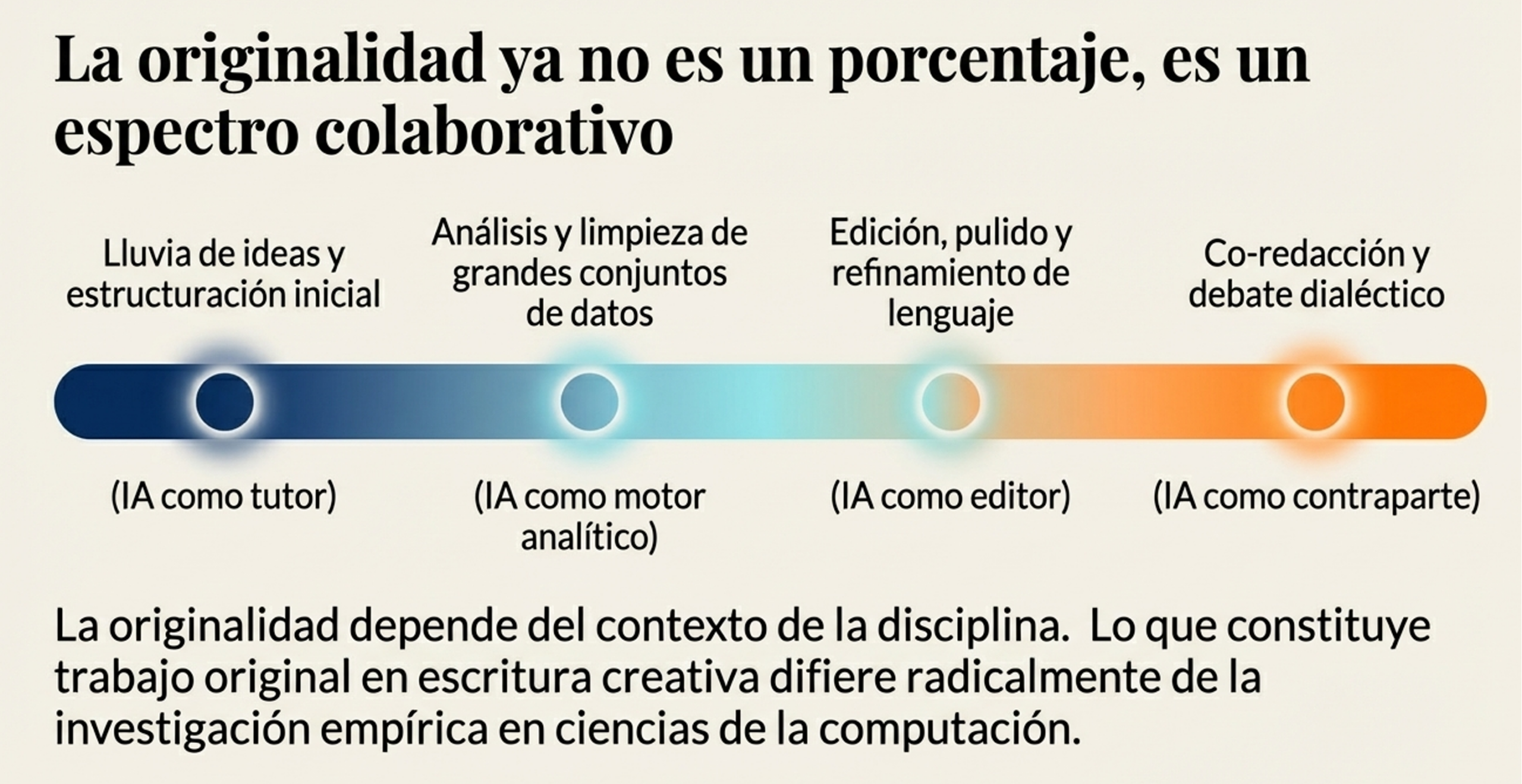
5. Hacia la originalidad como espectro y juicio evaluativo.
Debemos desmantelar la dicotomía «humano vs. IA». La propuesta de vanguardia, respaldada por autores como Luo y Chan (2023), consiste en entender la originalidad como un espectro de colaboración. La clave ya no es la producción solitaria de textos, sino el juicio evaluativo: la capacidad del estudiante para criticar, refinar y dar sentido a la información, ya sea de cualquier origen.
Es hora de aceptar una verdad incómoda que las políticas evitan mencionar:
«Podría decirse que los humanos hacemos lo mismo que la IA cuando generamos un texto original: escribimos basándonos en asociaciones que provienen de lo que hemos oído o leído antes de otros humanos».
Para avanzar, necesitamos evaluaciones auténticas, como defensas orales y la transparencia en los procesos, que valoren el pensamiento crítico por encima del producto final.
Conclusión: una pregunta para el futuro.
La universidad se encuentra en una encrucijada: puede evolucionar y liderar la alfabetización en IA o quedarse anclada en el pasado como un tribunal de autoría obsoleto. No podemos seguir exigiendo una originalidad de «genio solitario» en un mundo donde la inteligencia se comparte con las máquinas.
¿Estamos dispuestos a rediseñar la confianza o seguiremos educando a los estudiantes para que finjan una autoría analógica que ya no existe?
En esta conversación puedes escuchar las ideas más interesantes sobre el tema.
Este vídeo resume bien los contenidos de este artículo.
Bacchi C. Introducing the ‘What’s the Problem Represented to be?’ approach. In: Bletsas A, Beasley C, eds. Engaging with Carol Bacchi: Strategic Interventions and Exchanges. The University of Adelaide Press; 2012:21-24.
Johnson-Eilola, J., & Selber, S. A. (2007). Plagiarism, originality, assemblage. Computers and composition, 24(4), 375-403.
Luo (Jess), J. (2024). A critical review of GenAI policies in higher education assessment: a call to reconsider the “originality” of students’ work. Assessment & Evaluation in Higher Education, 49(5), 651–664. https://doi.org/10.1080/02602938.2024.2309963
De izquierda a derecha: Julián Alcalá, Víctor Yepes y Zhiwu Zhou
El Dr. Zhiwu Zhou , profesor de la Hunan University of Science and Engineering, ha alcanzado la máxima distinción en la educación tecnológica asiática al alzarse con el Primer Premio en la 7.ª edición del Concurso Nacional de Innovación de Habilidades Docentes («Craftsmanship to Build Dreams and Lead the Future«). El concurso fue organizado por el Ministerio de Educación y la Asociación China de Educación Superior. Este galardón, anunciado tras una rigurosa fase nacional en China, reconoce al Dr. Zhou como parte de la vanguardia pedagógica en ingeniería. Su éxito no solo es un hito para su trayectoria personal, sino que también valida la calidad de la formación doctoral recibida en el Instituto de Ciencia y Tecnología del Hormigón (ICITECH) de la Universitat Politècnica de València (UPV), consolidando un puente de excelencia académica entre España y China. Su tesis doctoral, dirigida por los profesores Víctor Yepes y Julián Alcalá, recibió el Premio Extraordinario 2024 de la UPV.
El hito del Dr. Zhiwu Zhou : Élite en la docencia de ingeniería civil
En un contexto global en el que las «Nuevas Ingenierías» (New Engineering) exigen una evolución radical de los métodos de enseñanza, el logro del Dr. Zhou Zhiwu destaca por su singularidad. Adscrito al College of Civil and Environmental Engineering de la Universidad de Hunan, el Dr. Zhou ha superado un proceso altamente competitivo. De los 4.014 profesores inscritos procedentes de 904 universidades de todo el país, solo una fracción selecta ha logrado el Primer Premio.
Es fundamental distinguir este logro dentro del ecosistema académico chino: aunque la competencia otorgó reconocimientos a 2.717 docentes, el Primer Premio representa el estrato superior de la excelencia, situando al Dr. Zhou en la élite absoluta de los premiados. Este éxito tiene implicaciones directas en el rígido sistema de promoción académica chino: ganar esta distinción es un factor determinante para la promoción universitaria y conlleva bonificaciones económicas y un prestigio institucional que eleva el posicionamiento de su facultad en los rankings nacionales. El éxito individual del Dr. Zhou se convierte así en un activo estratégico para la competitividad de su universidad.
Radiografía de la competencia: «Craftsmanship to Build Dreams«
La 7.ª edición de este certamen se ha erigido en la plataforma definitiva para elevar los estándares de la educación superior china. Organizado por la Chinese Society of Higher Education, el Comité Organizador del Concurso Nacional de Innovación de Habilidades Docentes y el Centro de Promoción de la Industria de Educación de Innovación de Zhongguancun, el evento promueve la mejora continua bajo el lema «Corazón de Artesano».
Datos clave de la 7.ª edición (marzo 2026):
Escala de participación: 904 universidades involucradas, con una criba final de 2.717 premiados provenientes de 687 instituciones.
Filosofía del «Artisan Heart»: El concepto de 匠心, aplicado a la ingeniería moderna, busca fusionar la precisión técnica del artesano con la innovación digital (IA y conectividad), orientando la formación hacia la resolución de retos industriales reales.
Impacto Sistémico: La competencia actúa como un laboratorio de metodologías que luego se replican en el sistema masivo de educación superior chino.
Esta robustez en la evaluación pedagógica tiene sus raíces en una formación técnica de rigor internacional, forjada en los laboratorios de España.
El vínculo con España: el rigor del ICITECH y la escuela de la UPV
El éxito del Dr. Zhou en China es, en gran medida, una extensión del prestigio de la escuela de ingeniería estructural española. El Dr. Zhou desarrolló su capacidad analítica y su visión innovadora durante su etapa doctoral en la Universitat Politècnica de València (UPV), bajo la dirección de dos referentes internacionales: los profesores Víctor Yepes y Julián Alcalá.
Su pertenencia al ICITECH, centro de vanguardia mundial en la ciencia y la tecnología del hormigón, fue el crisol donde se fusionó el concepto de «Corazón de Artesano» con el rigor científico europeo. La metodología de optimización y el pensamiento crítico aprendidos bajo la tutela de Yepes y Alcalá han sido la base sobre la que el Dr. Zhou ha construido su propuesta docente premiada. Esta sinergia demuestra que la formación de alto nivel en centros de excelencia españoles dota a los líderes globales de las herramientas necesarias para transformar la educación técnica en mercados tan competitivos como el asiático.
Conclusión: El impacto en el futuro de la ingeniería global
El reconocimiento al Dr. Zhiwu Zhou subraya la importancia de la colaboración internacional en la formación de cuadros docentes de alto impacto. Al integrar el rigor estructural del ICITECH con las necesidades de la educación masiva en China, el Dr. Zhou personifica el perfil del docente del siglo XXI: un investigador de frontera que traduce la complejidad técnica en habilidades prácticas y visionarias para sus alumnos.
Este premio reafirma el papel de la UPV y de sus grupos de investigación como exportadores de talento y de metodologías de éxito global. En última instancia, la excelencia docente premiada en Hunan es una victoria para la ingeniería construida con «Corazón de Artesano», un compromiso inquebrantable con la mejora continua que garantiza que la ingeniería siga liderando el progreso de la sociedad.