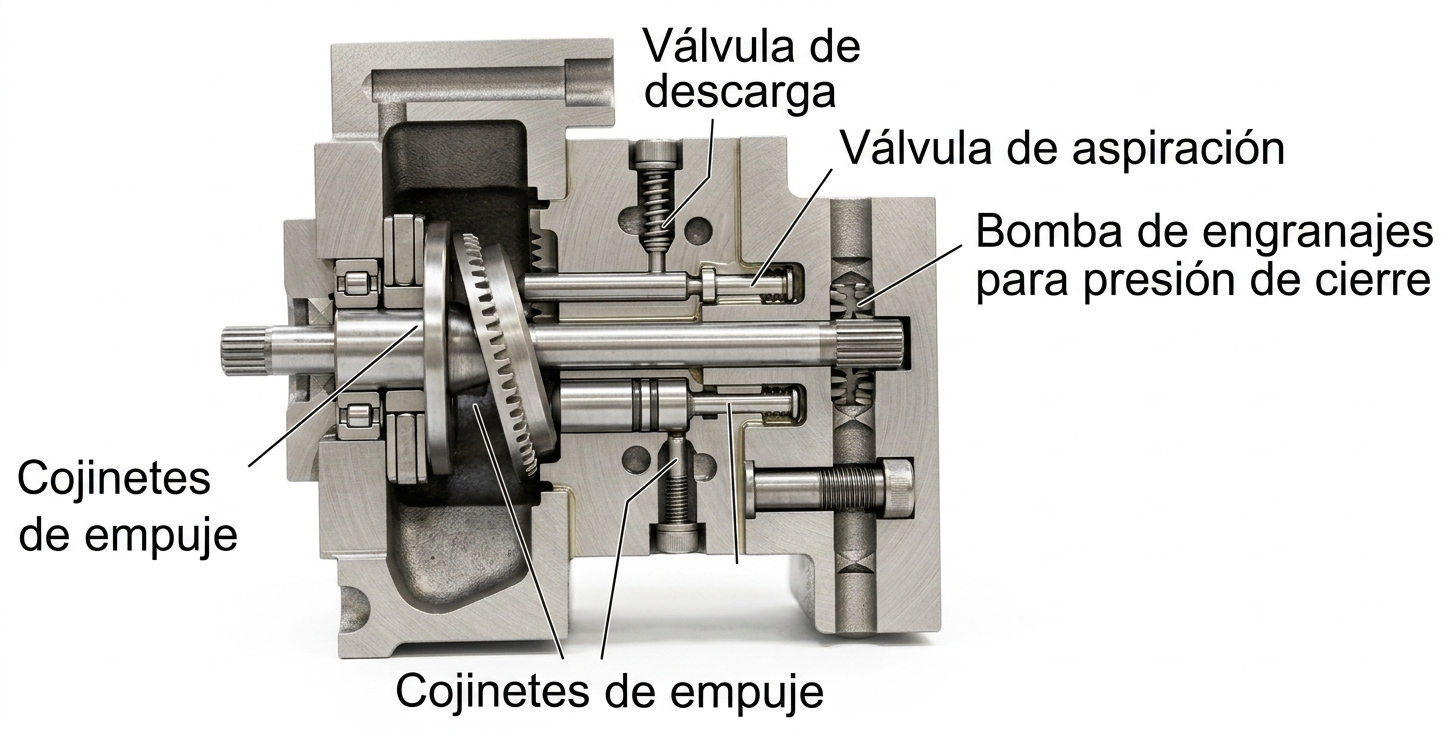
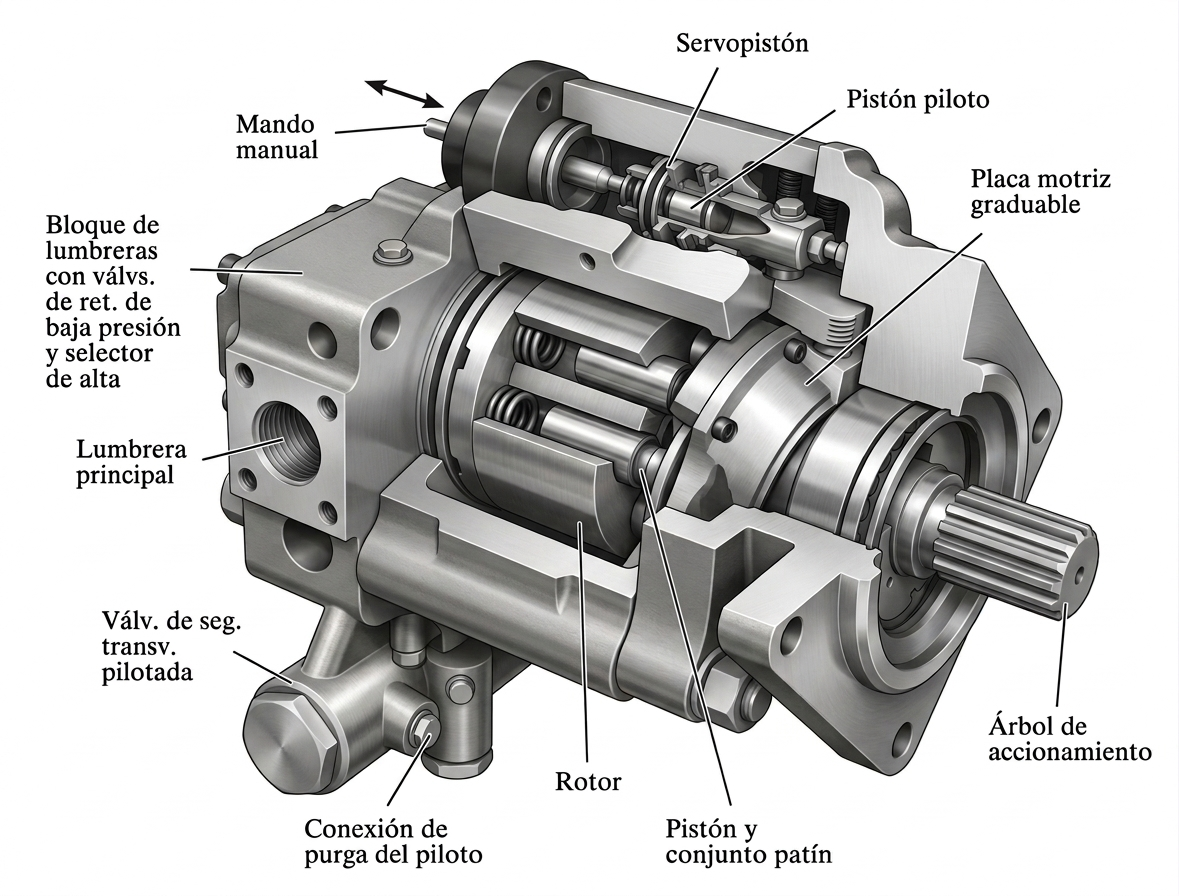
Los motores neumáticos son actuadores que transforman la energía almacenada en el aire comprimido en trabajo mecánico, ya sea rotativo o alternativo. Destacan por su ligereza y compacidad y ofrecen una densidad de potencia comparable o incluso superior a la de motores eléctricos equivalentes. Además, comparten con los sistemas hidráulicos ventajas importantes, como la seguridad en atmósferas explosivas, ya que no generan arcos eléctricos ni chispas, y la capacidad de transmitir un par elevado en relación con su peso.
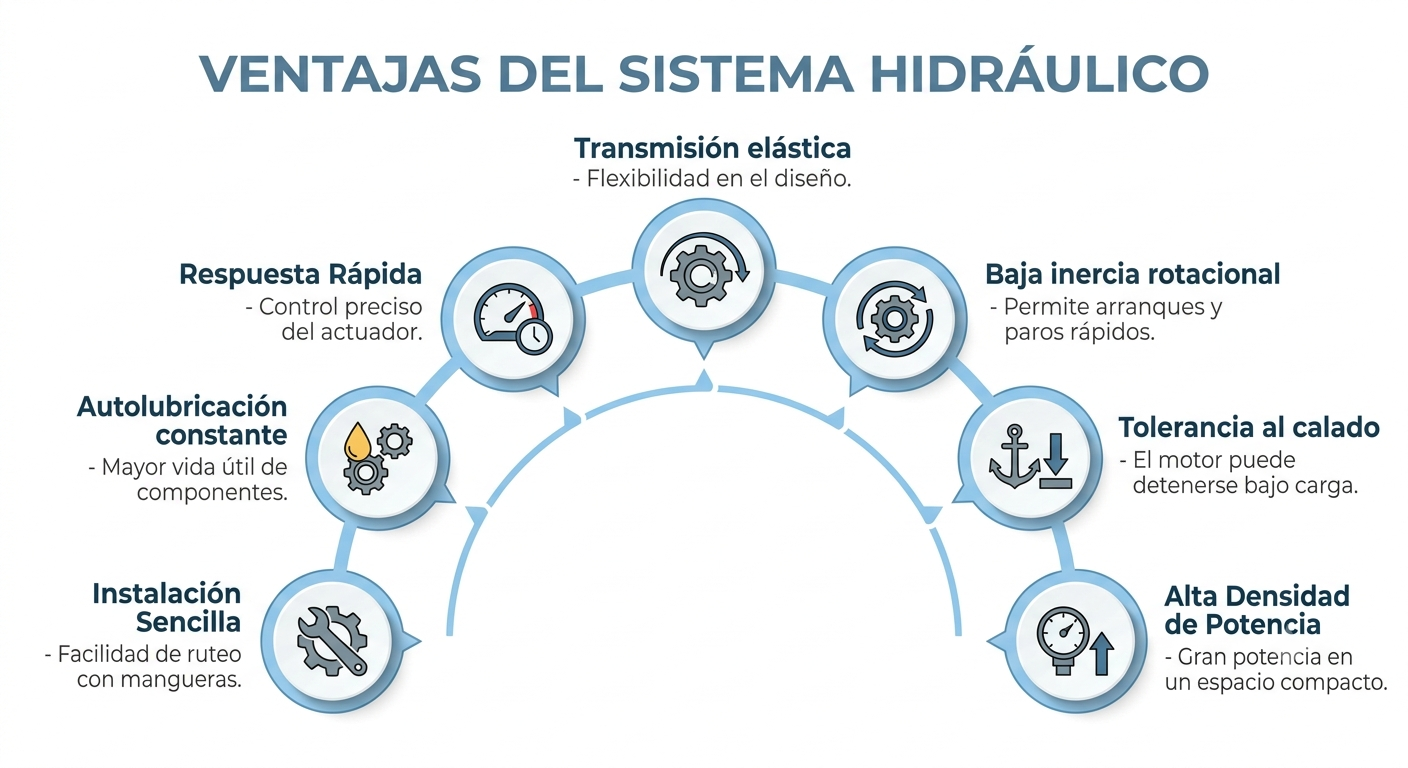
Frente a la tecnología oleohidráulica, también presenta ventajas operativas específicas. En cuanto a la gestión térmica, el aire se enfría al expandirse y al realizar trabajo. Esto proporciona un efecto refrigerante natural que evita la acumulación de calor, incluso durante trabajos prolongados bajo carga, a diferencia de los motores hidráulicos.
En cuanto a la infraestructura, las redes de distribución de aire comprimido son más sencillas y económicas de instalar. Como el aire es un fluido inocuo, no se requieren líneas de retorno. Tras su expansión, puede evacuarse directamente a la atmósfera. Además, en caso de fuga, no existe riesgo de contaminación del suelo ni de incendio. Por ello, estos motores son especialmente adecuados para trabajos en túneles y en explotaciones mineras.
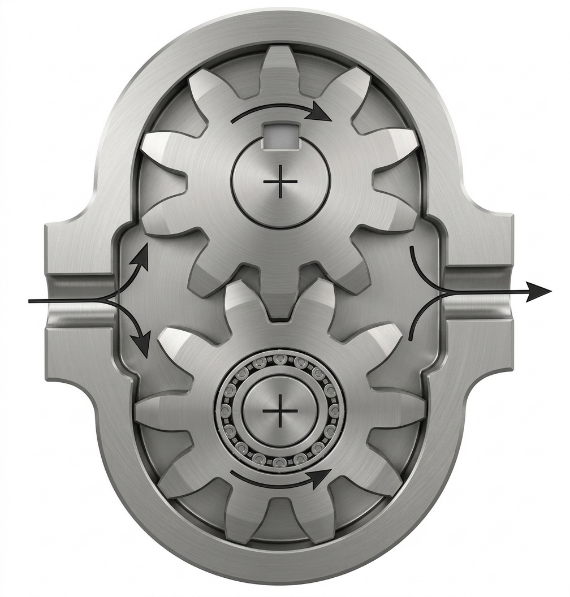
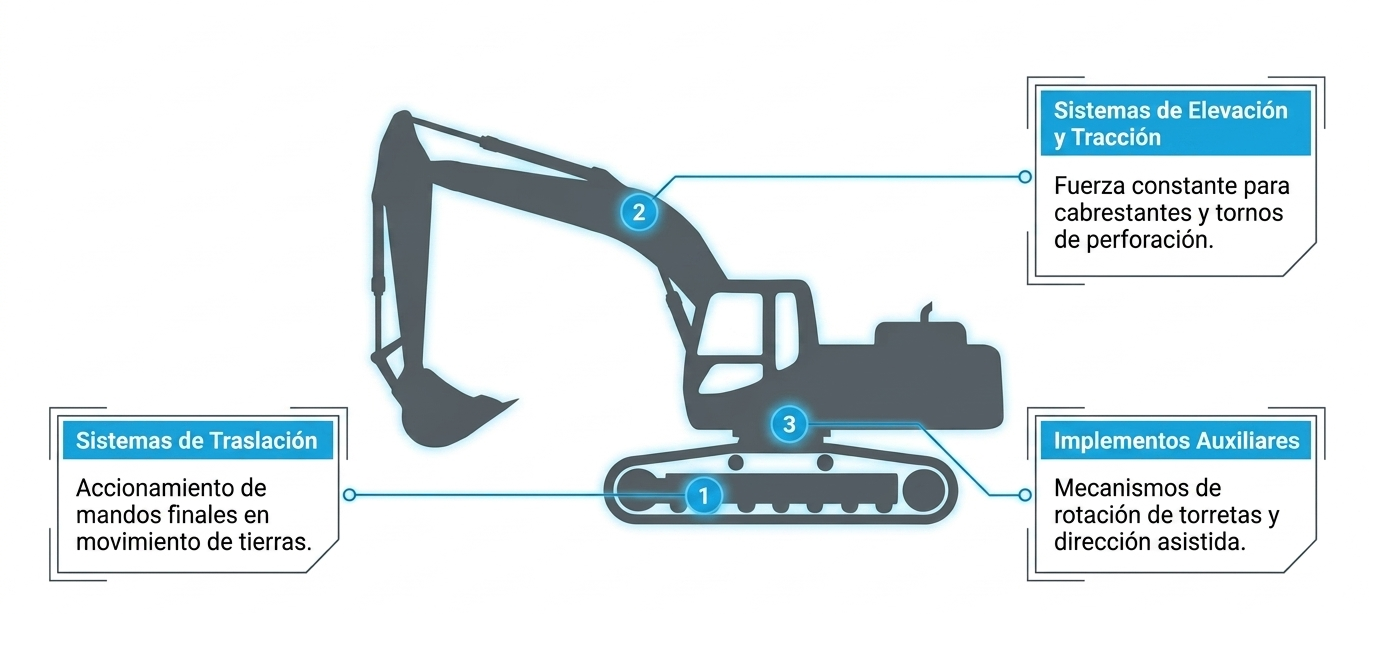
En el ámbito de la edificación y la obra civil, los motores neumáticos constituyen la solución estándar para accionar herramientas portátiles y equipos de elevación. Entre ellos se incluyen amoladoras, llaves de impacto, polipastos y cabrestantes. Su elevada frecuencia de impacto también los hace especialmente adecuados para martillos rompedores, perforadoras y vibradores de hormigón. En estas aplicaciones, la fiabilidad en entornos con polvo y vibraciones intensas es un requisito fundamental.
Desde el punto de vista técnico, los motores neumáticos presentan las siguientes características diferenciales frente a los motores eléctricos e hidráulicos:
- Elevada relación potencia-peso: su diseño simplificado permite fabricar unidades más ligeras y compactas que las de un motor eléctrico de potencia equivalente. Esto facilita su integración en herramientas manuales y en espacios reducidos.
- Seguridad ambiental: al no utilizar electricidad, son intrínsecamente seguros en atmósferas explosivas, húmedas, polvorientas o corrosivas. Además, ofrecen una elevada resistencia a impactos mecánicos y vibraciones.
- Gestión térmica por expansión: la disminución de la temperatura asociada a la expansión del aire evita la acumulación de calor incluso tras largos periodos de funcionamiento a plena carga. De este modo, se elimina el riesgo de quemaduras por contacto y se reduce el riesgo de incendio en el entorno de trabajo.
- Flexibilidad de control y reversibilidad: el par y la velocidad pueden regularse de forma continua mediante válvulas de estrangulamiento. Su baja inercia rotacional permite arrancar, detener e invertir el sentido de giro prácticamente al instante.
- Tolerancia al calado: pueden detenerse a carga máxima sin sufrir daños internos. A diferencia de los motores eléctricos, no existe riesgo de sobreintensidad. Una vez eliminada la sobrecarga, el motor recupera inmediatamente su funcionamiento normal.
- Sencillez y bajo mantenimiento: la ausencia de sistemas eléctricos y la robustez de sus componentes mecánicos reducen las necesidades de mantenimiento. Como resultado, ofrecen una elevada fiabilidad en ciclos continuos de arranque y parada.
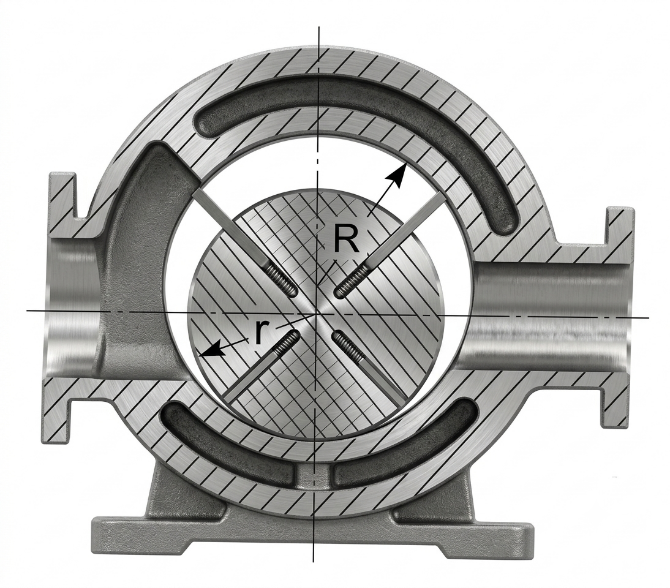
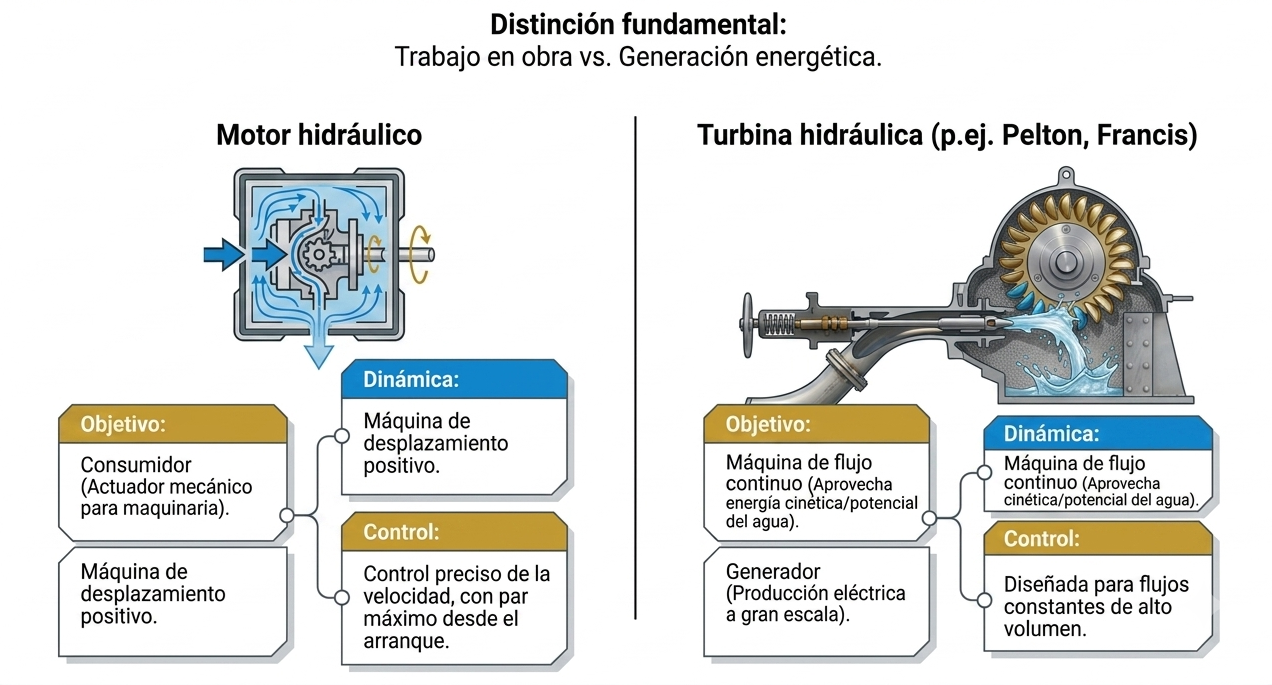
Aunque los tipos y principios de funcionamiento de los motores neumáticos son similares a los de los motores hidráulicos, en ambos casos existen variantes de paletas, pistones y engranajes. Sin embargo, su comportamiento difiere debido a las propiedades del fluido de trabajo. El aceite es prácticamente incompresible, lo que permite movimientos rígidos y precisos. El aire, por el contrario, es altamente compresible. Esta característica proporciona una respuesta más suave ante las variaciones de carga, aunque el control de velocidad resulta menos preciso si no se emplean reguladores específicos.
Os dejo algunos vídeos sobre este tipo de motores.
Referencias:
YEPES, V.; MARTÍ, J.V. (2017). Máquinas, cables y grúas empleados en la construcción. Editorial de la Universitat Politècnica de València. Ref. 814. Valencia, 210 pp.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.