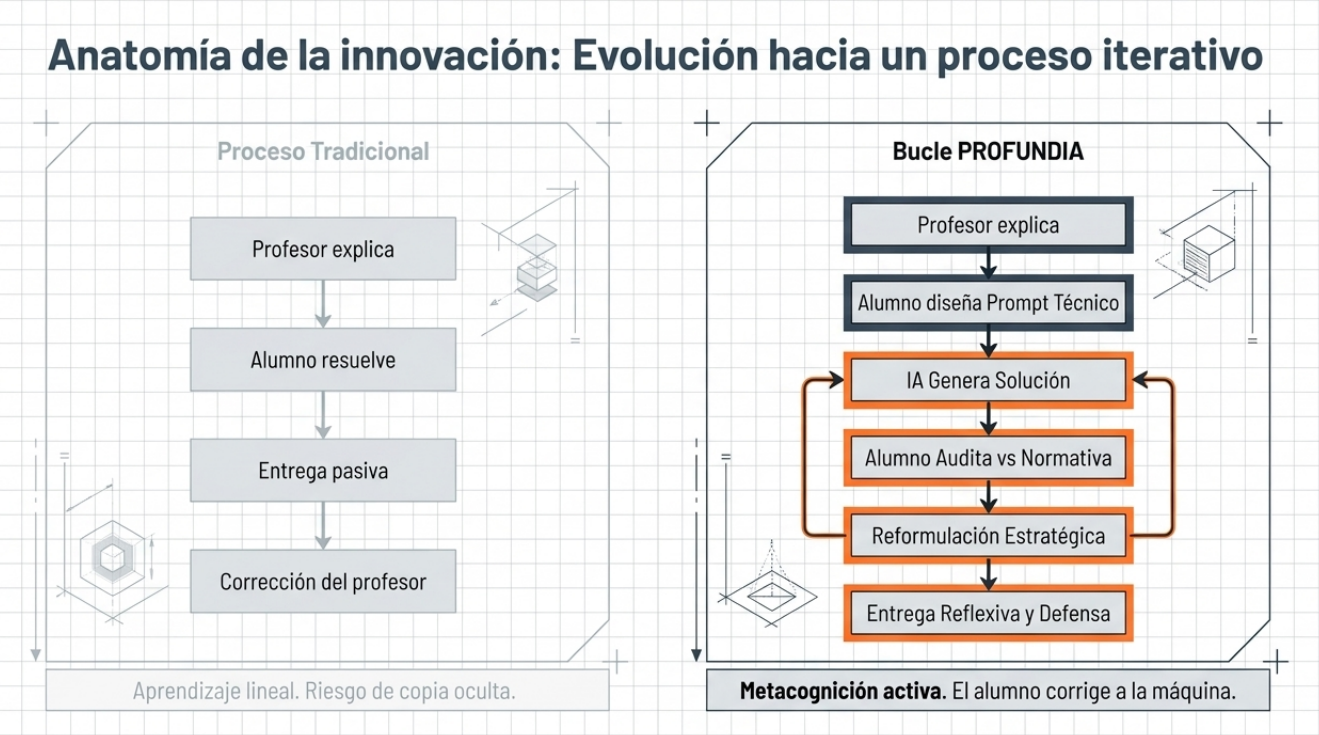
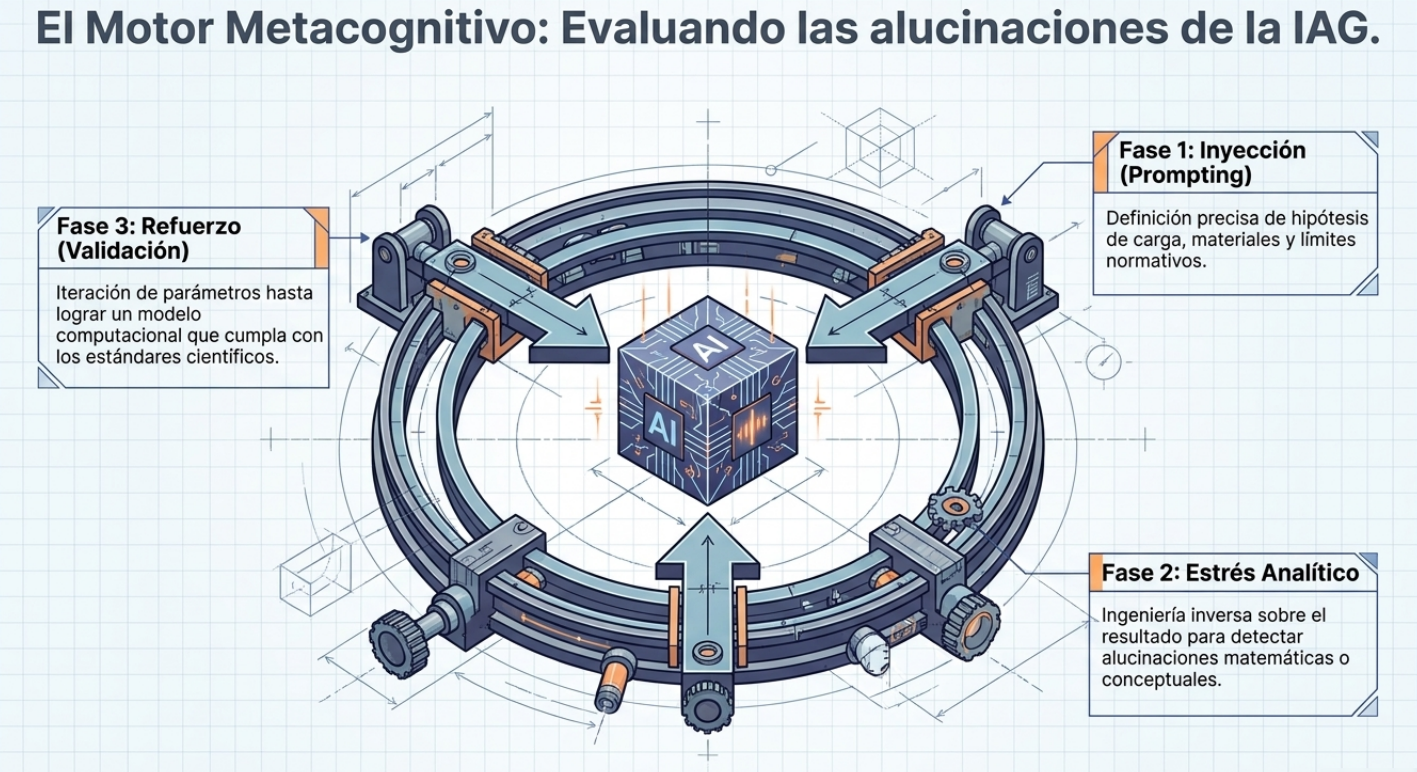
Dentro del proyecto de innovación docente PROFUNDIA, hemos realizado una investigación cualitativa sobre la percepción de los estudiantes respecto de la capacidad de la inteligencia artificial para resolver problemas de ingeniería. Se realizó mediante una variante de la técnica de «focus group» en una clase de 10 alumnos del Máster Universitario en Ingeniería del Hormigón de la Universitat Politècnica de València. A continuación describimos cómo se realizó la investigación y adelantamos algunas de las conclusiones más interesantes.
Dentro del proyecto de innovación docente PROFUNDIA, hemos realizado una investigación cualitativa sobre la percepción de los estudiantes respecto de la capacidad de la inteligencia artificial para resolver problemas de ingeniería. Se realizó mediante una variante de la técnica de «focus group» en una clase de 10 alumnos del Máster Universitario en Ingeniería del Hormigón de la Universitat Politècnica de València. A continuación describimos cómo se realizó la investigación y adelantamos algunas de las conclusiones más interesantes.
La presente investigación tuvo como objetivo analizar cómo perciben los estudiantes universitarios la capacidad de la inteligencia artificial generativa (IAG) para resolver problemas de ingeniería y, en especial, cómo evolucionan dichas percepciones cuando tienen la oportunidad de contrastar las respuestas proporcionadas por la IA con una solución correcta validada por el profesorado.
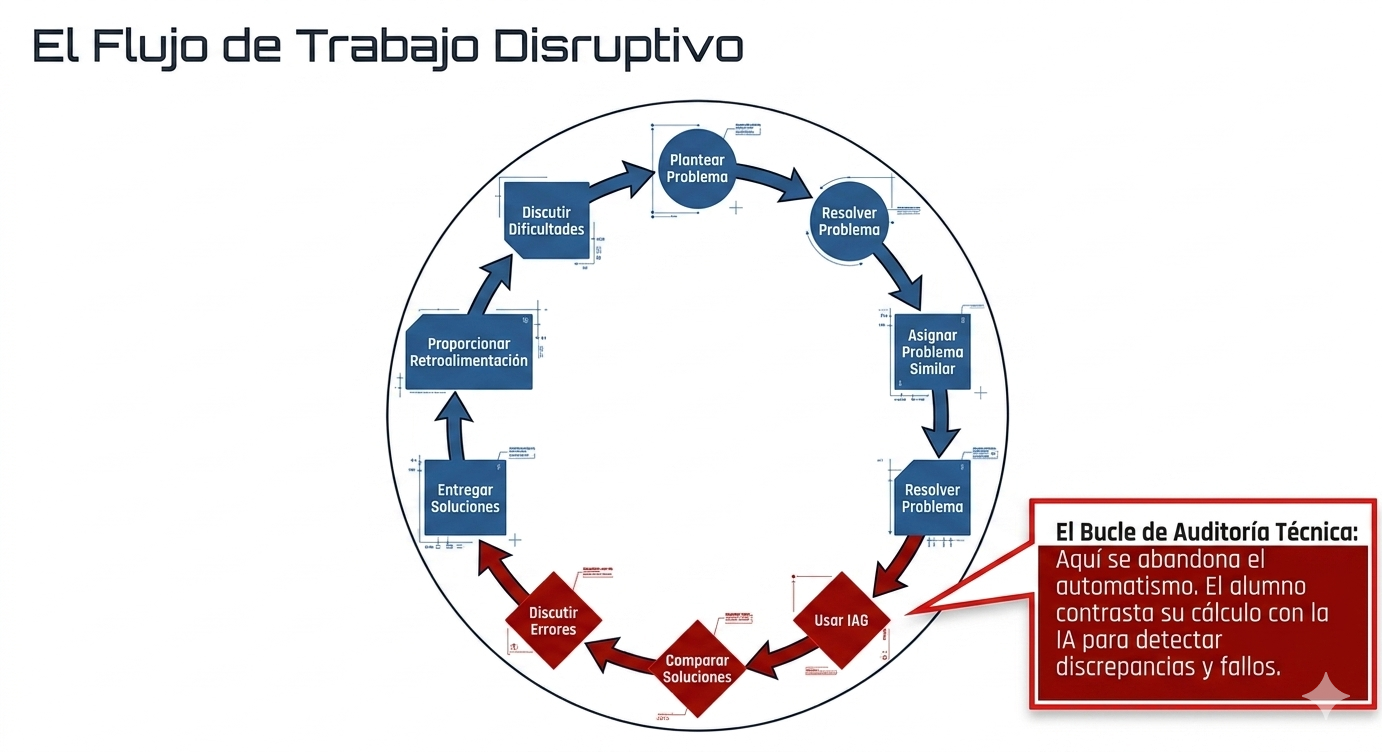
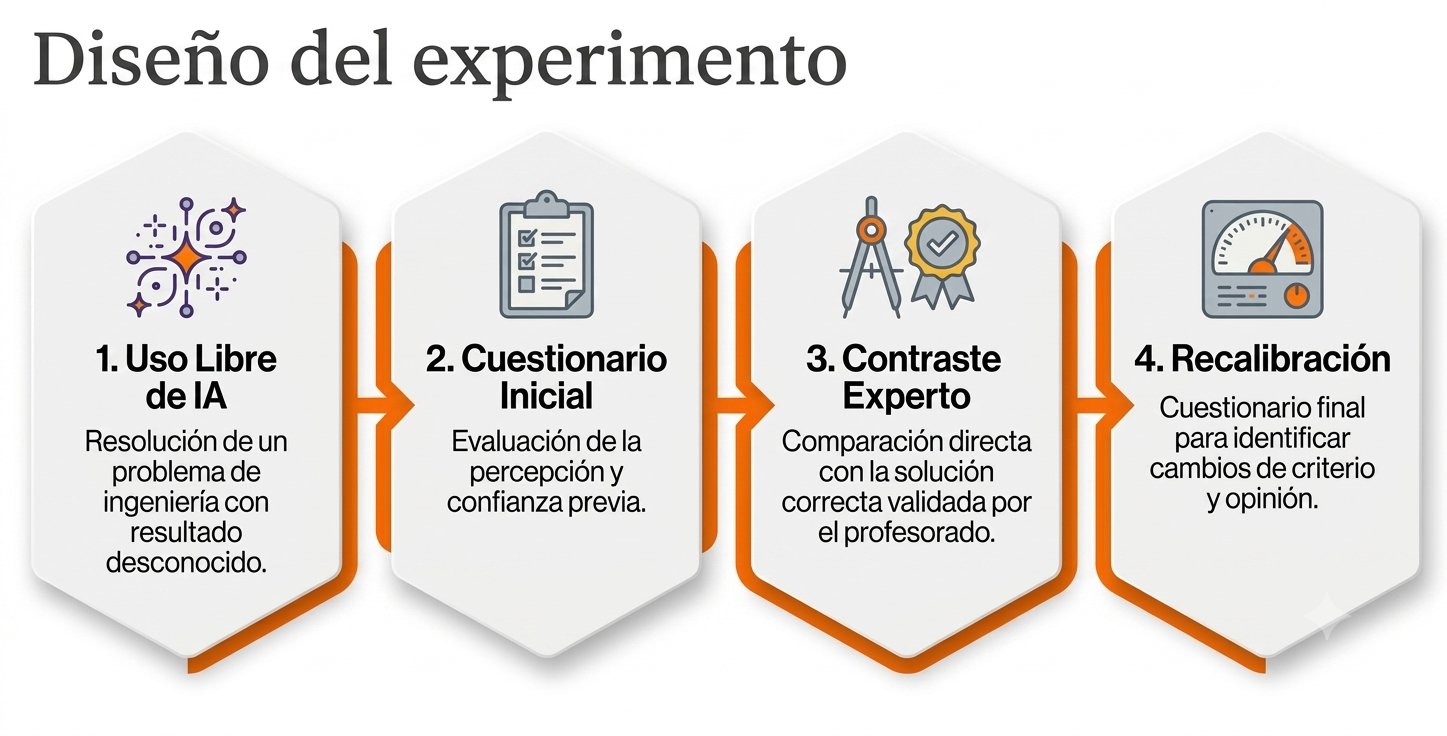
Para ello, se diseñó una experiencia en dos fases. En la primera, los participantes utilizaron libremente herramientas de inteligencia artificial para resolver un problema de ingeniería cuyo resultado desconocían y, posteriormente, respondieron a un cuestionario de preguntas abiertas. En la segunda fase, una vez facilitada la resolución correcta del problema, los estudiantes compararon ambos resultados y completaron un nuevo cuestionario orientado a identificar posibles cambios en sus opiniones, niveles de confianza y criterios de valoración.
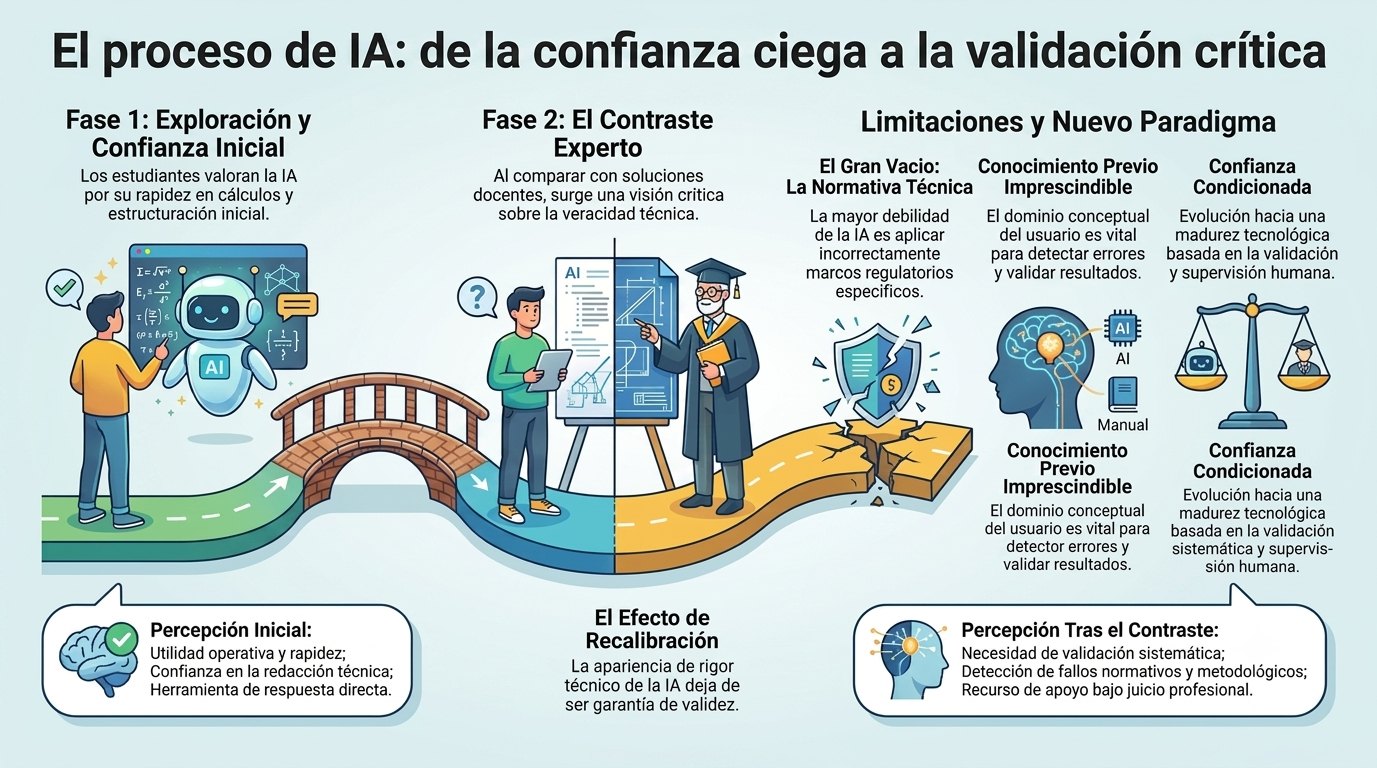
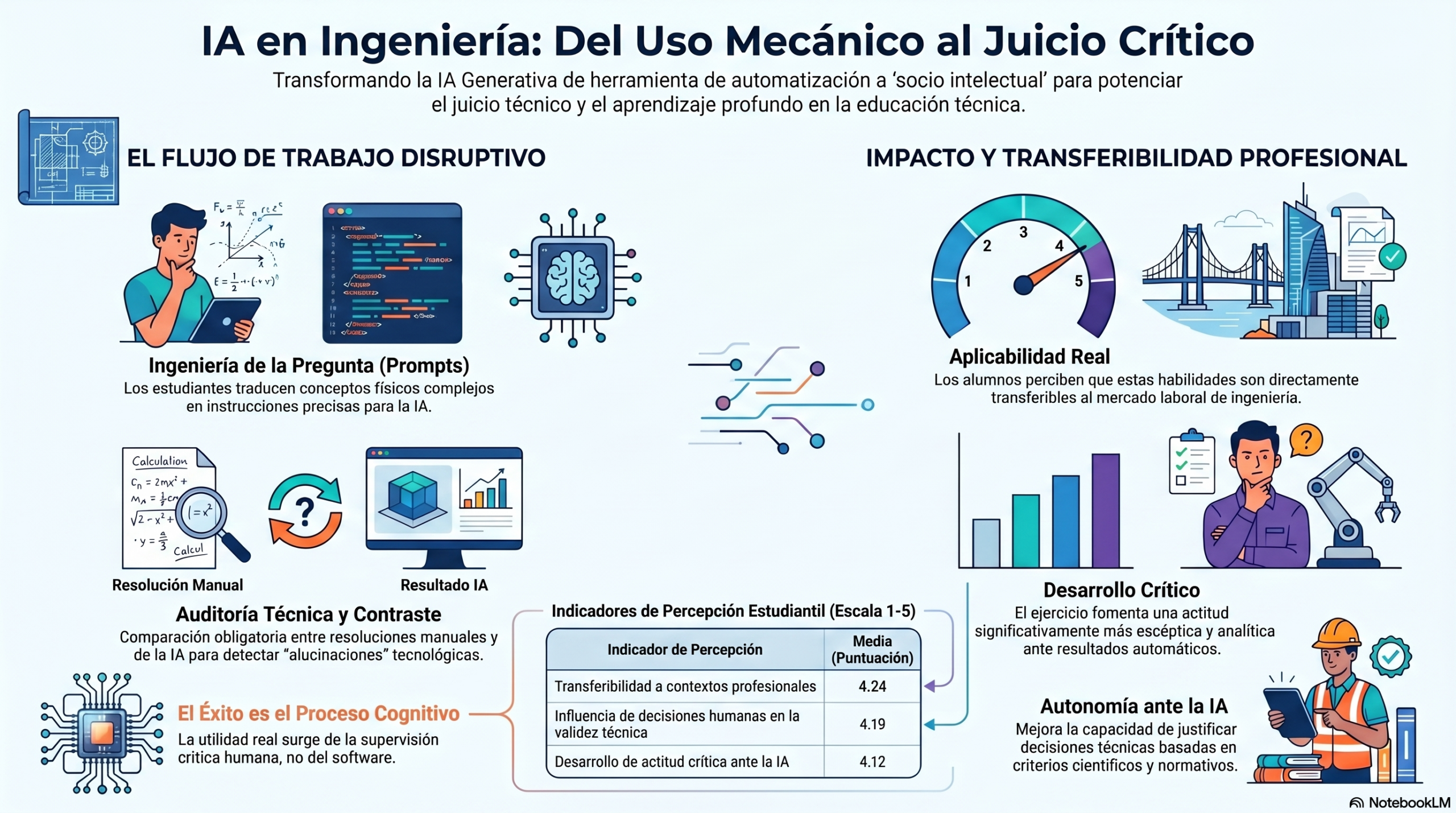
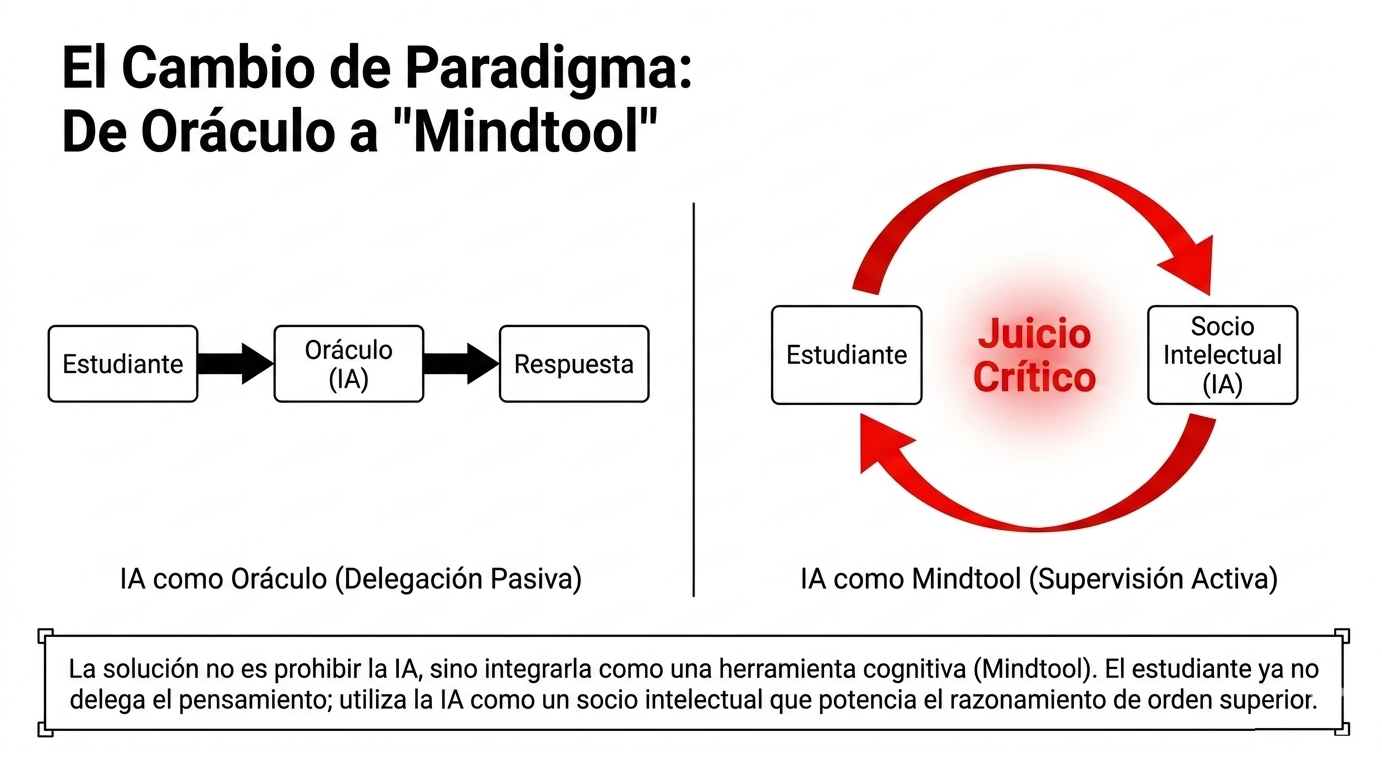
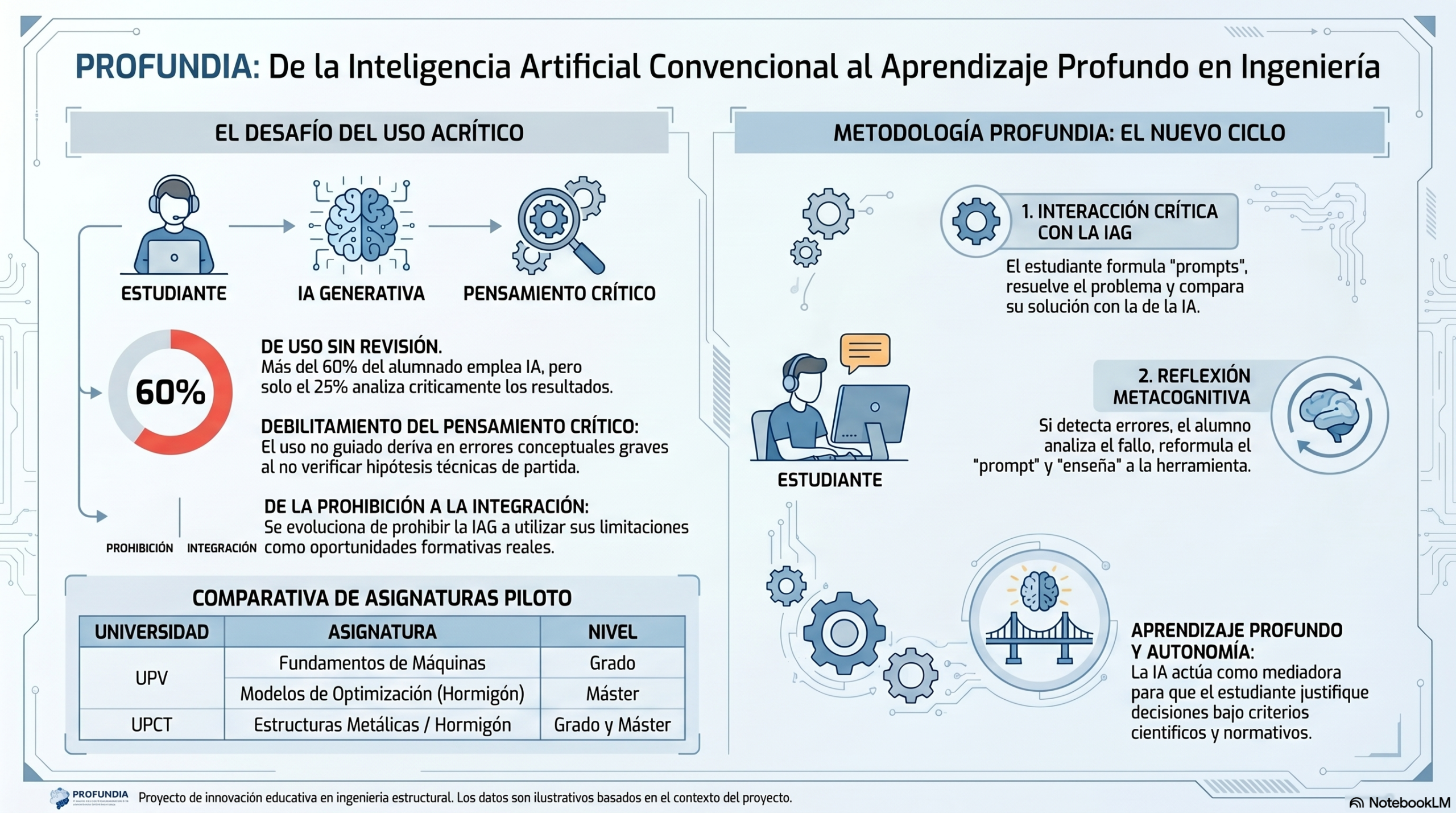
Los resultados muestran que los estudiantes parten de una actitud generalmente favorable hacia la inteligencia artificial. La mayoría considera que estas herramientas son útiles para apoyar el aprendizaje, agilizar los cálculos, estructurar procedimientos o proporcionar orientación inicial en la resolución de problemas técnicos. Sin embargo, incluso antes de conocer la solución correcta, ya se observa una percepción relativamente madura de sus propias limitaciones. Los participantes manifiestan reiteradamente que las respuestas obtenidas deben ser verificadas mediante la normativa técnica, la bibliografía especializada o el propio razonamiento, lo que evidencia una confianza condicionada más que una aceptación acrítica de los resultados generados por la IA.
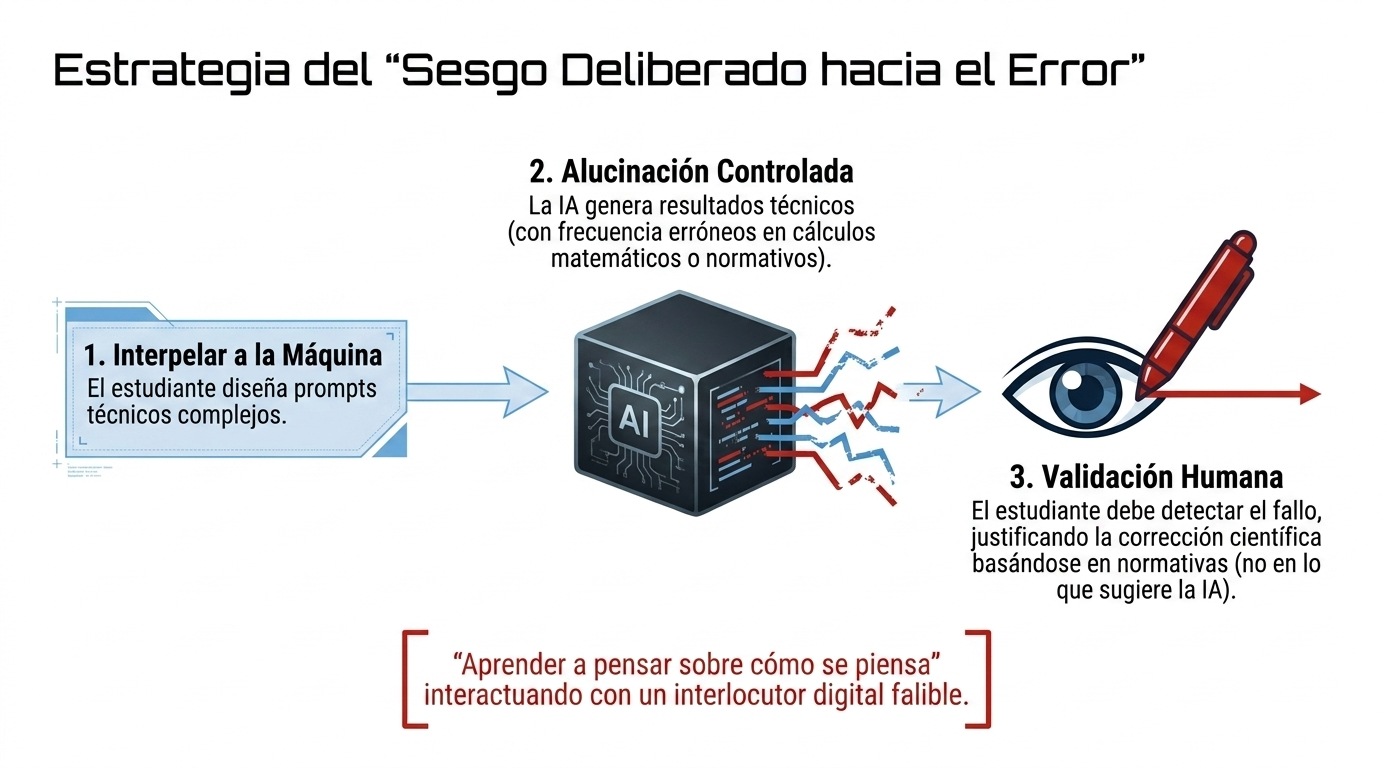
La comparación posterior con la resolución correcta produjo un efecto significativo de recalibración de la confianza. Los estudiantes comprobaron que la inteligencia artificial era capaz de generar respuestas técnicamente plausibles y bien redactadas, pero no necesariamente correctas desde el punto de vista normativo o metodológico. Esta constatación reforzó la percepción de que la apariencia de rigor técnico no constituye una garantía de validez. Tras la experiencia, las opiniones evolucionaron de una valoración centrada en la utilidad operativa de la herramienta a una visión más crítica, basada en la necesidad de validar sistemáticamente cualquier resultado antes de aceptarlo como correcto.
Uno de los hallazgos más relevantes del estudio es la identificación de la normativa técnica como uno de los ámbitos en los que los estudiantes perciben mayores limitaciones al uso de la inteligencia artificial. Numerosos participantes señalaron que las respuestas generadas no incorporaban adecuadamente los criterios establecidos en las normas aplicables, omitían condicionantes relevantes o utilizaban referencias incorrectas. En consecuencia, la principal fuente de error detectada no se relacionó tanto con la capacidad de cálculo de la herramienta como con su dificultad para interpretar y aplicar correctamente los marcos regulatorios específicos. Esta percepción resulta especialmente relevante en el ámbito de la ingeniería, donde la adecuación normativa constituye un requisito esencial para la validez de cualquier solución técnica.
El análisis también revela una comprensión creciente por parte de los estudiantes del funcionamiento y de las limitaciones inherentes de los sistemas de inteligencia artificial. A medida que reflexionaban sobre los errores detectados, los participantes identificaban fenómenos como la generación de respuestas plausibles sin fundamento suficiente, la tendencia a proporcionar una respuesta incluso cuando la información disponible es insuficiente o la dependencia de fuentes cuya calidad no siempre puede verificarse. Esta toma de conciencia constituye un indicio del desarrollo de competencias de alfabetización en inteligencia artificial y de una comprensión más sofisticada de los riesgos asociados a su uso.
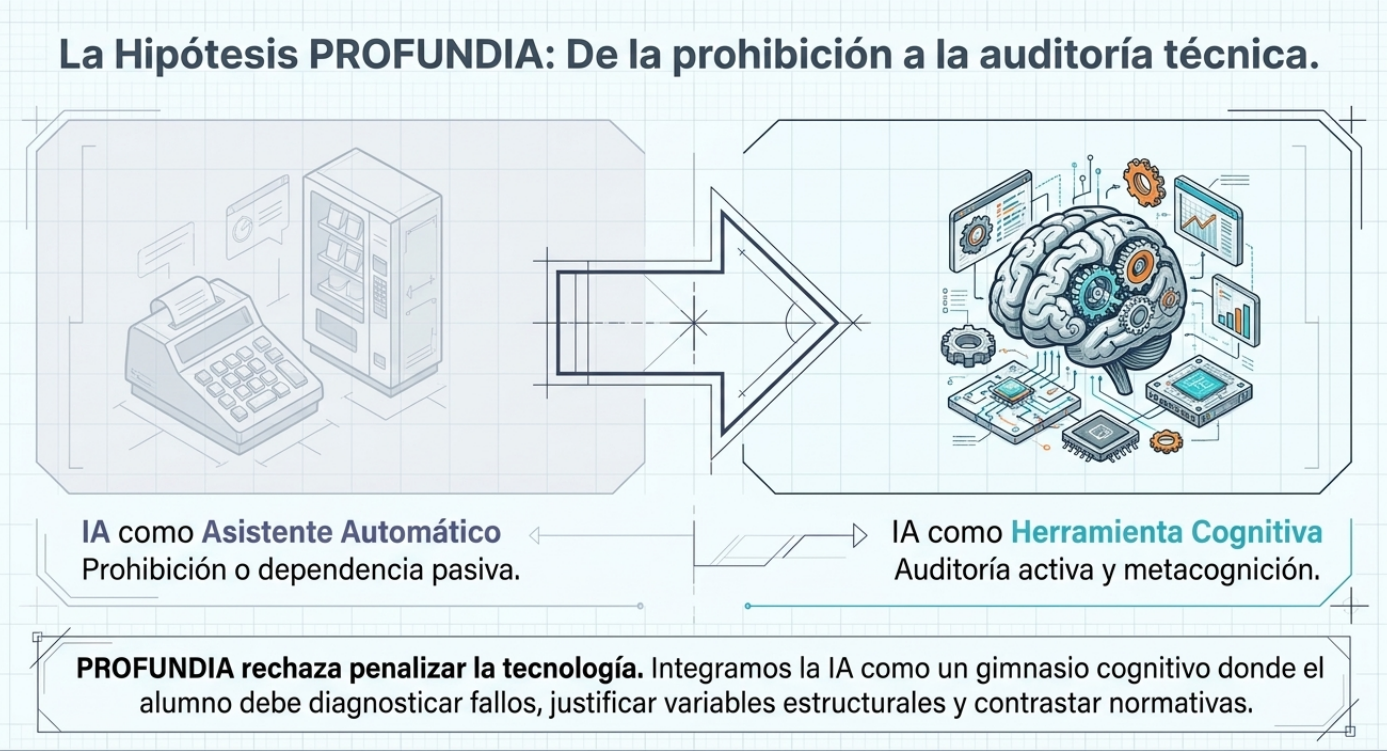
Otro aspecto especialmente significativo es que los estudiantes concluyen prácticamente de manera unánime que el uso eficaz de la inteligencia artificial requiere sólidos conocimientos previos sobre la materia consultada. Lejos de considerar que estas herramientas puedan sustituir el aprendizaje o el criterio profesional, los participantes afirman que la capacidad para detectar errores, formular preguntas adecuadas y validar resultados depende directamente del dominio conceptual del usuario. Desde esta perspectiva, la IA se percibe como una herramienta de apoyo cuyo valor aumenta cuando se utiliza desde una posición de conocimiento y de pensamiento crítico.
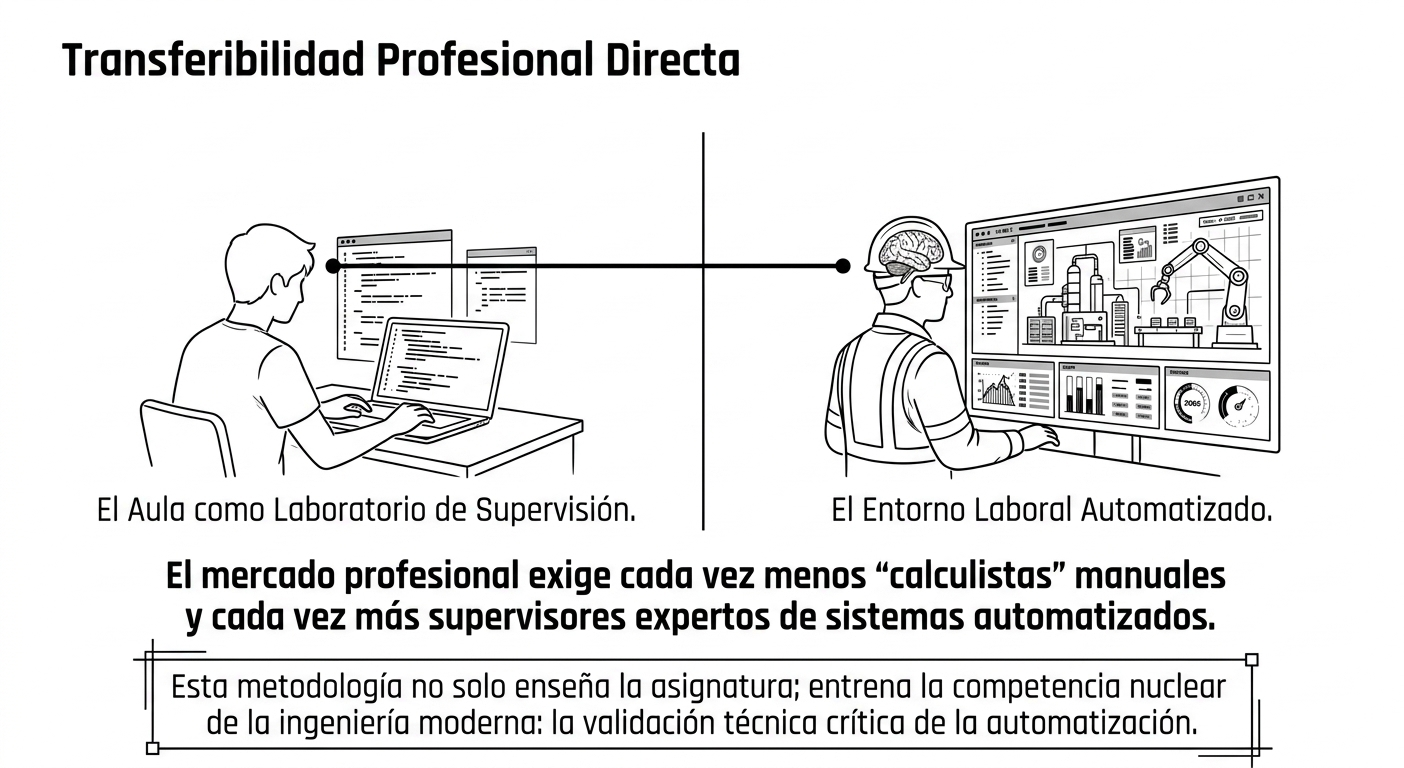
En términos educativos, la experiencia pone de manifiesto el potencial formativo de actividades basadas en la comparación entre respuestas generadas por la inteligencia artificial y soluciones correctas validadas por expertos. Este tipo de ejercicios no solo permite evaluar la fiabilidad de la herramienta en contextos específicos, sino que también favorece el desarrollo de competencias fundamentales para el futuro ejercicio profesional, tales como la capacidad de análisis crítico, la verificación de la información, la interpretación normativa y la toma de decisiones fundamentadas.
En conclusión, los resultados indican que la experiencia no conduce a un rechazo de la inteligencia artificial, sino a una comprensión más realista de sus capacidades y limitaciones. Los estudiantes mantienen una valoración positiva de estas herramientas como recurso de apoyo, pero desarrollan simultáneamente una actitud más prudente y reflexiva respecto a su utilización. La principal transformación observada consiste en el paso de una confianza basada en la aparente calidad de las respuestas a una confianza condicionada por la necesidad de validación, de supervisión humana y de juicio profesional. Este cambio puede interpretarse como un indicador de madurez tecnológica y constituye uno de los resultados más relevantes de la investigación.
En esta conversación puedes escuchar cómo hemos realizado esta investigación cualitativa.
El vídeo resume bien las ideas más importantes de este tema.
Referencia:
YEPES-BELLVER, L.; MARTÍNEZ-PAGÁN, P.; YEPES, V. (2026). Impacto de la inteligencia artificial en la formación técnica: aprendizaje profundo, metacognición y transferibilidad profesional. En libro de actas: XII Congreso de Innovación Educativa y Docencia en Red. Valencia, 9-10 de julio de 2026.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.