Cada día cruzamos puentes y entramos en edificios con una confianza casi absoluta en su solidez. Damos por hecho que el hormigón y el acero que nos rodean son permanentes. Sin embargo, la realidad es que estas estructuras, al igual que cualquier otra cosa, envejecen, se desgastan y están expuestas a amenazas constantes. Esta degradación no es un problema lejano, sino una realidad silenciosa que ya está aquí. Se trata, como ya he comentado algunas veces, de una verdadera «crisis de las infraestructuras». De eso nos estamos ocupando en el proyecto de investigación RESIFIFE, del cual soy investigador principal.
Para comprender la magnitud del desafío, basta con echar un vistazo a las cifras. Según el informe de la Sociedad Americana de Ingenieros Civiles (ASCE) de 2021, casi el 42 % de todos los puentes de Estados Unidos tienen más de 50 años y un preocupante 7,5 % se consideran «estructuralmente deficientes». A nivel mundial, el panorama es igualmente preocupante. El Foro Económico Mundial estima que la brecha de inversión en infraestructuras podría alcanzar los 18 billones de dólares para el año 2040.
Los dos «enemigos» al que se enfrentan nuestras estructuras
La degradación de un edificio o un puente no es un proceso único. Para los ingenieros, el primer paso es siempre realizar un diagnóstico correcto. En este caso, hay dos tipos muy diferentes:
- La degradación progresiva: piense en ella como un desgaste lento y constante. Se trata del «deterioro ambiental», por ejemplo, la corrosión del acero causada por la sal en el aire o la fatiga del material tras soportar cargas durante décadas. Es un enemigo paciente que debilita la estructura poco a poco a lo largo de toda su vida útil.
- La degradación instantánea: son los impactos repentinos y violentos. Se trata de «eventos extremos», como terremotos, inundaciones o incluso desastres provocados por el ser humano. A diferencia de la degradación progresiva, un solo evento de este tipo puede reducir drásticamente el rendimiento de una estructura en cuestión de minutos.
Comprender esta diferencia es crucial, ya que no se puede utilizar la misma estrategia para reparar una grieta por fatiga que para recuperar una estructura después de un terremoto.

La caja de herramientas de los ingenieros: mantenimiento frente a reparación
Frente a estos dos enemigos, la ingeniería no lucha con las manos vacías. Cuenta con una caja de herramientas específica para cada amenaza, con dos categorías principales de soluciones o «mecanismos de intervención».
- Mantenimiento: son acciones planificadas para combatir la degradación progresiva. Piense en ellas como la medicina preventiva. Estas «intervenciones preventivas o esenciales» incluyen tareas como reparar grietas, aplicar una nueva capa de pintura protectora o reemplazar componentes estructurales antes de que fallen. El objetivo es frenar el desgaste natural.
- Reparación: son las acciones que se llevan a cabo en respuesta a la degradación instantánea. Pueden ser «preventivas», como reforzar una estructura (retrofit) para que resista mejor un futuro terremoto, o «correctivas», como las labores de recuperación para devolver la funcionalidad lo antes posible.
Este enfoque de «ciclo de vida» supone un cambio fundamental. En lugar de esperar a que algo se rompa para repararlo, los ingenieros modernos planifican, predicen e intervienen a lo largo de toda la vida útil de la estructura para garantizar su rendimiento a largo plazo.
Más allá de la seguridad: las cuatro formas de medir el «éxito» de una estructura
Es aquí donde el campo se ha vuelto realmente fascinante. La forma de evaluar el «éxito» de una estructura ha evolucionado desde una pregunta sencilla de «¿se ha caído o no?» basta un cuadro de mando sofisticado con cuatro indicadores clave. Para entenderlo mejor, podemos pensar en cómo se evalúa a un atleta profesional:
- Fiabilidad (reliability): esta es la base. ¿Puede el atleta aguantar el esfuerzo de un partido sin lesionarse? Mide la probabilidad de que una estructura no falle en las condiciones para las que fue diseñada.
- Riesgo (risk): este indicador va un paso más allá. Si el atleta se lesiona, ¿qué consecuencias tiene para el equipo? ¿Se pierde un partido clave o la final del campeonato? El riesgo tiene en cuenta las consecuencias de un fallo: sociales, económicas y medioambientales.
- Resiliencia (resilience): este es un concepto más nuevo y crucial. En caso de lesión, ¿cuánto tiempo tardará el atleta en recuperarse y volver a jugar al máximo nivel? Mide la capacidad de una estructura para prepararse, adaptarse y, sobre todo, recuperarse de manera rápida y eficiente tras un evento extremo.
- Sostenibilidad (sustainability): esta es la visión a largo plazo. ¿Está el atleta gestionando su carrera para poder jugar durante muchos años o se quemará en dos temporadas? La sostenibilidad integra los aspectos sociales, económicos y medioambientales para garantizar que las decisiones de hoy no afecten a las generaciones futuras.
Este cambio de enfoque para evaluar las consecuencias supone una revolución en el campo. Los expertos señalan un cambio de mentalidad fundamental: ya no basta con medir el rendimiento en términos técnicos. Ahora se centran en las consecuencias en el mundo real (sociales, económicas y ambientales), ya que estas ofrecen una visión mucho más fiel y significativa de lo que realmente está en juego.

La carrera contra el tiempo: por qué este campo está investigando ahora
El interés por modelar y gestionar el ciclo de vida de las estructuras no es solo una curiosidad académica, sino una respuesta directa a una necesidad global cada vez más acuciante. Un análisis de la investigación científica en este campo revela una clara «tendencia ascendente».
El futuro es inteligente: De la reparación a la predicción
Para gestionar esta complejidad, la ingeniería está recurriendo a herramientas cada vez más avanzadas que van más allá del cálculo tradicional. El objetivo es pasar de un enfoque reactivo a otro predictivo y optimizado. Es como pasar de ir al médico solo cuando tienes un dolor insoportable a llevar un reloj inteligente que monitoriza tu salud las 24 horas del día y te avisa de un problema antes incluso de que lo notes.
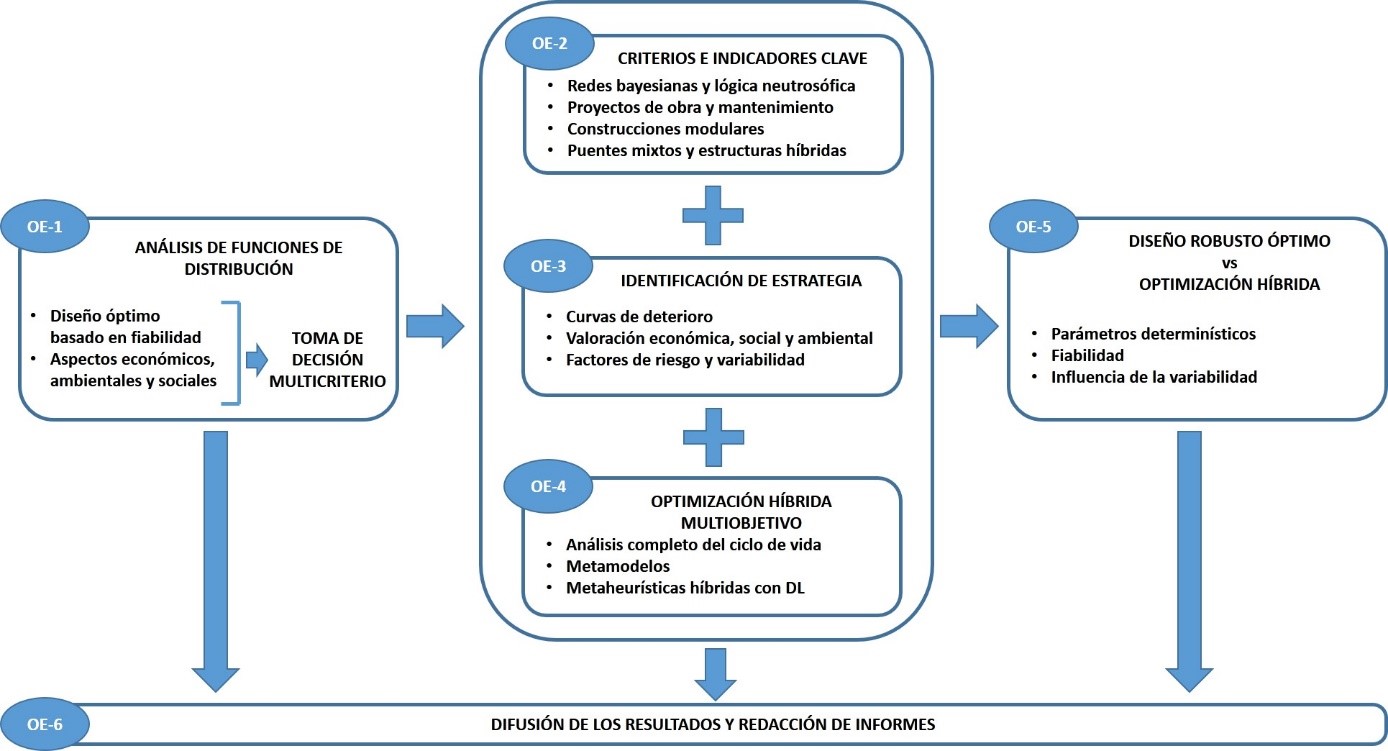
Entre las metodologías más destacadas se encuentran:
- Optimización: algoritmos que ayudan a decidir cuál es la mejor estrategia de mantenimiento (cuándo, dónde y cómo intervenir) para obtener el máximo beneficio con recursos limitados.
- Modelos de Markov: herramientas estadísticas que funcionan como un pronóstico del tiempo para las estructuras, ya que predicen su estado futuro basándose en su condición actual.
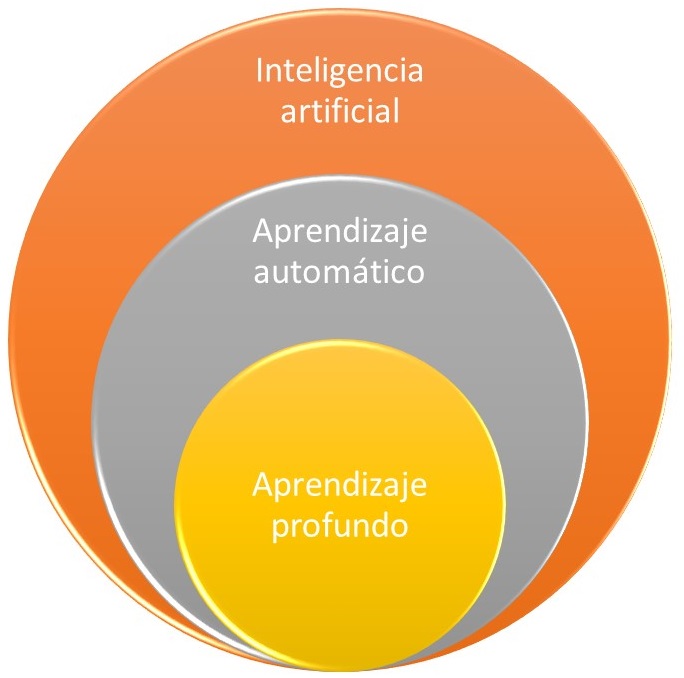
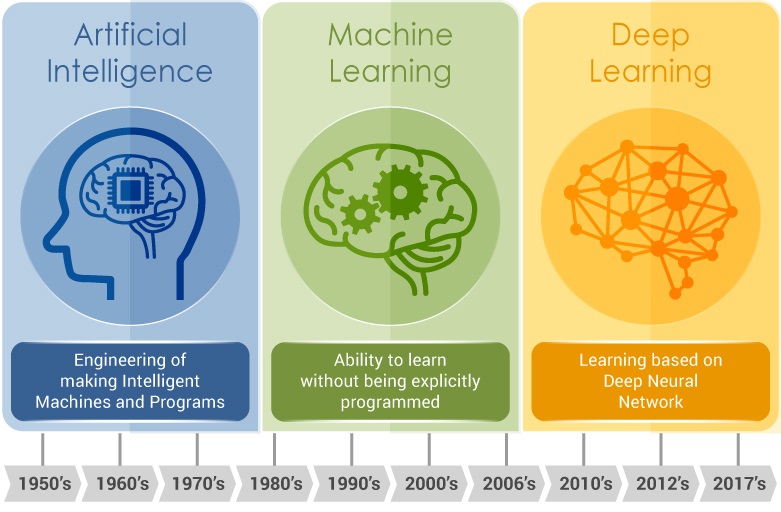
- Inteligencia artificial (IA), aprendizaje automático y aprendizaje profundo: estas tecnologías permiten analizar grandes cantidades de datos (de sensores, inspecciones, etc.) para predecir fallos, identificar patrones invisibles al ojo humano y optimizar la gestión del ciclo de vida a una escala nunca antes vista.
Este cambio de paradigma significa que, en el futuro, las decisiones sobre cuándo reparar un puente o reforzar un edificio se tomarán con la ayuda de datos y algoritmos complejos que pueden prever el futuro de la estructura.
Conclusión: pensar en el mañana, hoy
Gestionar la salud de nuestra infraestructura es un desafío continuo, complejo y vital. Ya no basta con construir estructuras impresionantes; es fundamental adoptar una mentalidad de «ciclo de vida» que nos obligue a evaluar, intervenir y planificar constantemente pensando en el futuro. Solo así podremos garantizar que los edificios y puentes que usamos cada día no solo sean fiables, sino también resilientes ante los imprevistos y sostenibles para las próximas generaciones.
La próxima vez que cruces un puente, no pienses solo en dónde te lleva. Pregúntate cuál es su historia invisible en su lucha contra el paso del tiempo y si, como sociedad, estamos invirtiendo no solo para construir, sino también para perdurar.
Os dejo un vídeo que os puede servir de guía.
Referencias:
- NAVARRO, I.J.; YEPES, V.; MARTÍ, J.V.; GONZÁLEZ-VIDOSA, F. (2018). Life cycle impact assessment of corrosion preventive designs applied to prestressed concrete bridge decks. Journal of Cleaner Production, 196: 698-713. DOI:10.1016/j.jclepro.2018.06.110
- SIERRA, L.A.; YEPES, V.; PELLICER, E. (2018). A review of multi-criteria assessment of the social sustainability of infrastructures. Journal of Cleaner Production, 187:496-513. DOI:10.1016/j.jclepro.2018.03.022
- NAVARRO, I.J.; MARTÍ, J.V.; YEPES, V. (2019). Reliability-based maintenance optimization of corrosion preventive designs under a life cycle perspective. Environmental Impact Assessment Review, 74:23-34. DOI:10.1016/j.eiar.2018.10.001
- SALAS, J.; YEPES, V. (2020). Enhancing sustainability and resilience through multi-level infrastructure planning. International Journal of Environmental Research and Public Health, 17(3): 962. DOI:10.3390/ijerph17030962
- MAKOOND, N.; SETIAWAN, A.; BUITRAGO, M., ADAM, J.M. (2024). Arresting failure propagation in buildings through collapse isolation. Nature 629, 592–596 (2024). DOI:10.1038/s41586-024-07268-5
- VILLALBA, P.; SÁNCHEZ-GARRIDO, A.; YEPES, V. (2024). A review of multi-criteria decision-making methods for building assessment, selection, and retrofit. Journal of Civil Engineering and Management, 30(5):465-480. DOI:10.3846/jcem.2024.21621
- NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2025). Metamodel-assisted design optimization of robust-to-progressive-collapse RC frame buildings considering the impact of floor slabs, infill walls, and SSI implementation. Engineering Structures, 325:119487. DOI:10.1016/j.engstruct.2024.119487
- SÁNCHEZ-GARRIDO, A.J.; NAVARRO, I.J.; YEPES, V. (2026). Optimizing reactive maintenance intervals for the sustainable rehabilitation of chloride-exposed coastal buildings with MMC-based concrete structure. Environmental Impact Assessment Review, 116, 108110. DOI:10.1016/j.eiar.2025.108110

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.