¿Cómo es posible que insectos con capacidades individuales sumamente limitadas resuelvan problemas geométricos y logísticos que a la humanidad le han llevado décadas de estudio formal para dominar?
¿Cómo es posible que insectos con capacidades individuales sumamente limitadas resuelvan problemas geométricos y logísticos que a la humanidad le han llevado décadas de estudio formal para dominar?
En el rincón más sencillo de un jardín tiene lugar un fenómeno asombroso: una comunidad de diminutos seres encuentra, sin mapas, líderes jerárquicos ni tecnología GPS, el camino más corto entre un hormiguero y una fuente de alimento.
Este prodigio de la naturaleza no es solo una curiosidad biológica, sino la piedra angular de la optimización mediante colonias de hormigas (ACO), una potente metaheurística computacional que actúa como puente entre la eficiencia orgánica y los algoritmos más avanzados de la actualidad.
A continuación, exploramos cinco lecciones fundamentales que estos optimizadores naturales nos enseñan sobre la resolución de problemas complejos.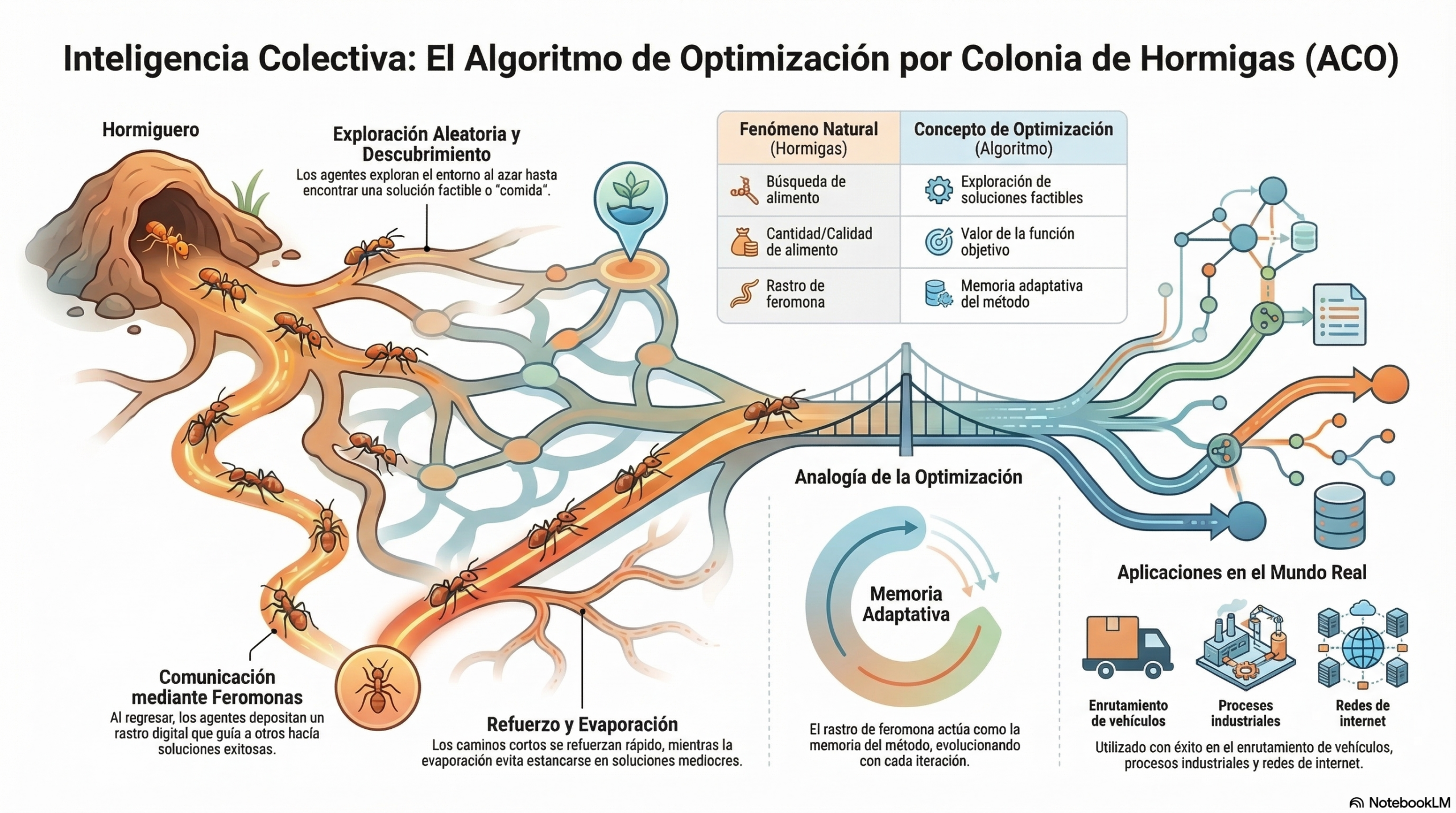
La inteligencia no reside en el individuo, sino en el colectivo.
En el mundo de las hormigas, la genialidad no es una cualidad de un «líder» con una visión superior, sino que surge del grupo. Así, el comportamiento inteligente surge de la masa, lo que desafía nuestras nociones tradicionales de gestión jerárquica. La ciencia ha comprobado que la brillantez del sistema no radica en sus componentes aislados, sino en la red de interacciones entre ellos.
Como se describe en los fundamentos de la inteligencia colectiva:
«En la naturaleza existen ejemplos de colectivos de individuos cuyo comportamiento es aparentemente inteligente, sin que esta característica se manifieste en sus componentes individuales».
Esta realidad nos invita a reflexionar sobre un cambio de paradigma: frente al liderazgo humano centralizado, la naturaleza propone una lógica bottom-up, en la que la suma de acciones simples y coordinadas supera la capacidad de cualquier genio individual.
El «Universo» como herramienta de comunicación dinámica.
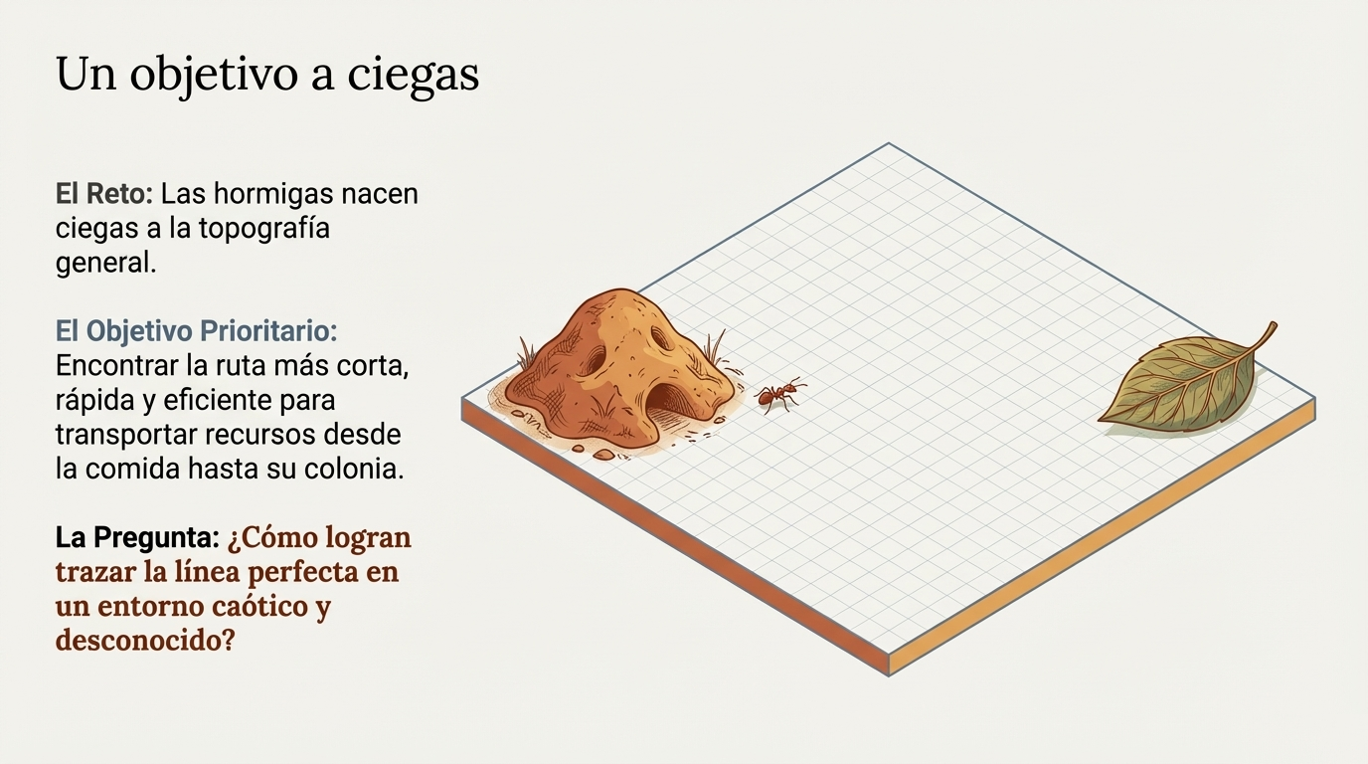
Para que una colonia resuelva un problema, no es necesario que todas las hormigas conozcan el mapa completo del entorno. De hecho, ningún agente posee un conocimiento global. El éxito depende de la interacción con su «universo», que actúa como depositario físico de la información.
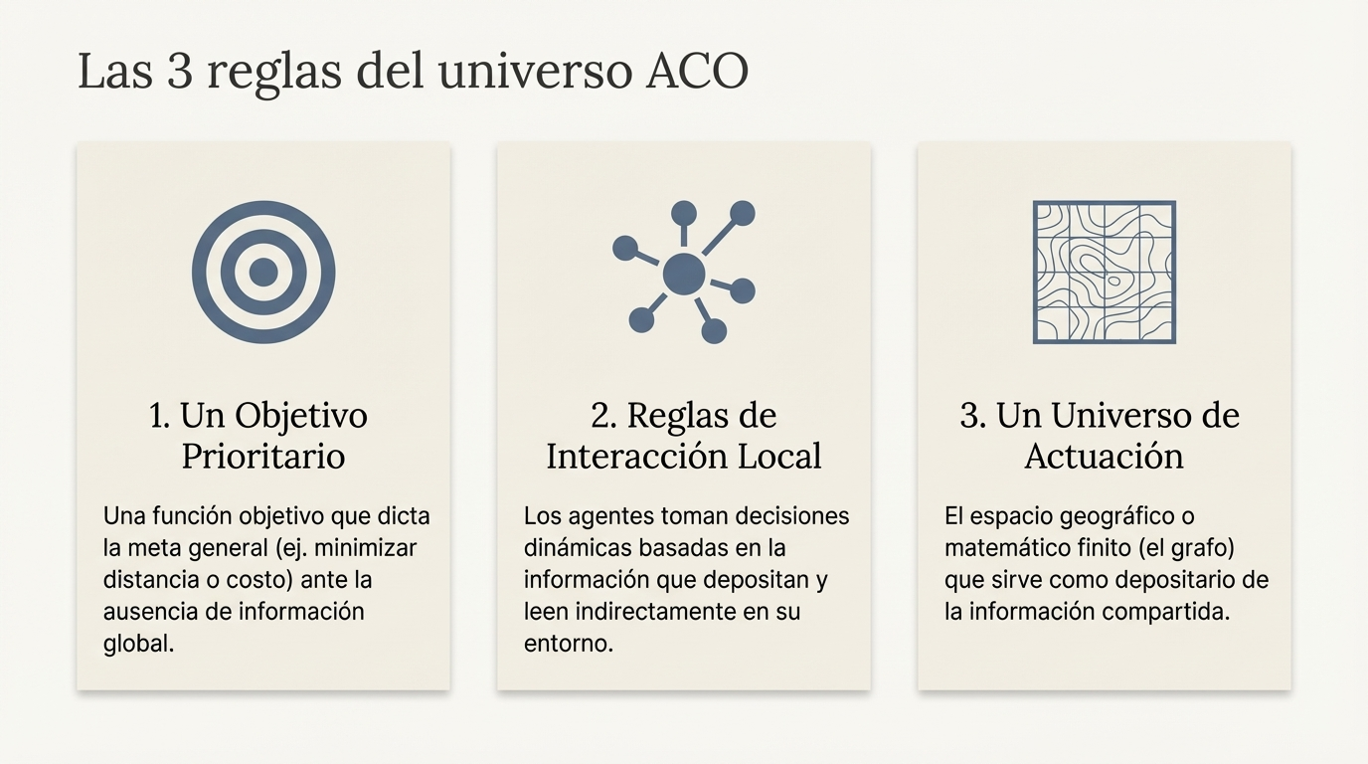
Según el contexto científico, deben cumplirse tres condiciones esenciales para que se produzca este comportamiento:
- Existencia de un objetivo prioritario: una meta clara (como la locomoción o la alimentación) que proporciona un norte y, crucialmente, dicta el comportamiento de los agentes incluso en ausencia de información local.
- Reglas de interacción local: si existe información local, el agente la utiliza para tomar decisiones que le permitan alcanzar el objetivo más rápidamente. Los agentes independientes depositan y modifican datos en el entorno, comunicando indirectamente los resultados de sus esfuerzos.
- Un universo donde actuar: el entorno es la «geografía» por la que transitan. Es el medio que proporciona los datos necesarios y en el que se encuentra la memoria colectiva del sistema.
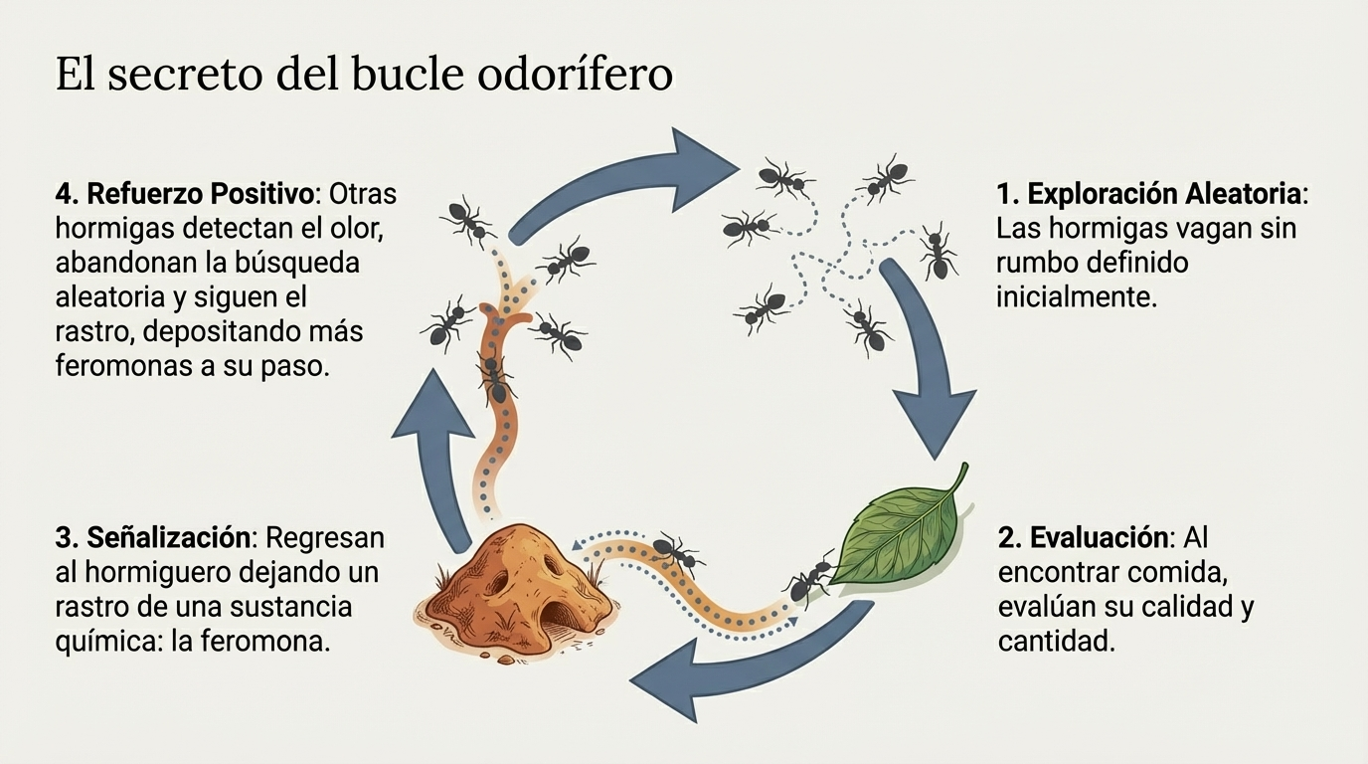
Feromonas: el rastro que se convierte en memoria adaptativa.
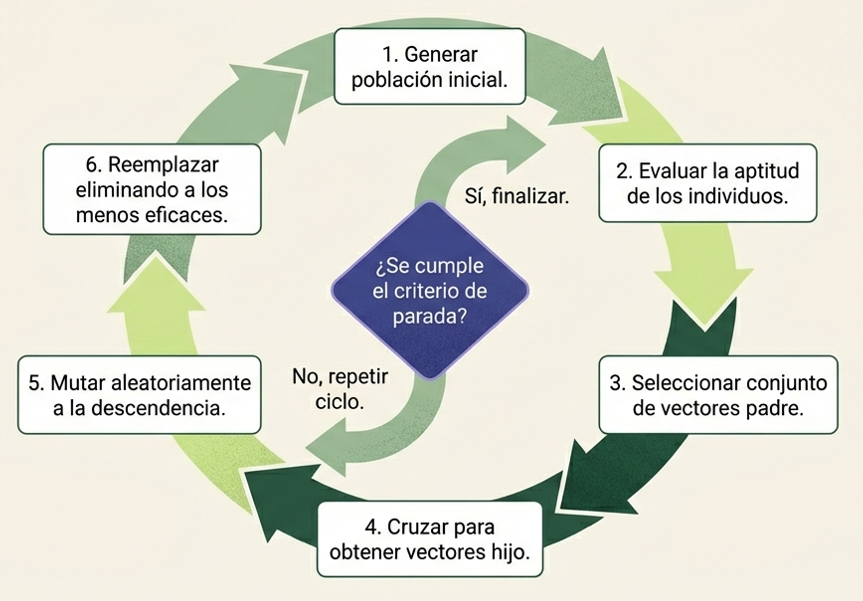
El proceso mediante el cual las hormigas optimizan sus rutas es un fascinante ciclo químico-digital. Todo comienza con una exploración aleatoria del entorno. Tan pronto como un individuo encuentra una fuente de alimento, evalúa su cantidad y calidad. Al regresar al hormiguero, deposita una sustancia química llamada feromona.
Este rastro oloroso sirve de señal para las demás hormigas. El camino más corto acaba ganando por una cuestión de frecuencia: las hormigas que viajan por la ruta más breve regresan antes y con mayor frecuencia, por lo que refuerzan ese rastro más rápido que en las rutas largas.
Sin embargo, la clave del éxito radica en la fragilidad del rastro: la feromona es dinámica y se evapora con el tiempo. Si un camino deja de usarse, la señal desaparece. Esta capacidad de «olvido» o plasticidad es vital, ya que permite que el sistema sea flexible y evita la «estagnación», impidiendo que la colonia se quede atrapada en soluciones locales, ya sean mediocres u óptimas, que ya no resultan eficientes ante un entorno cambiante.
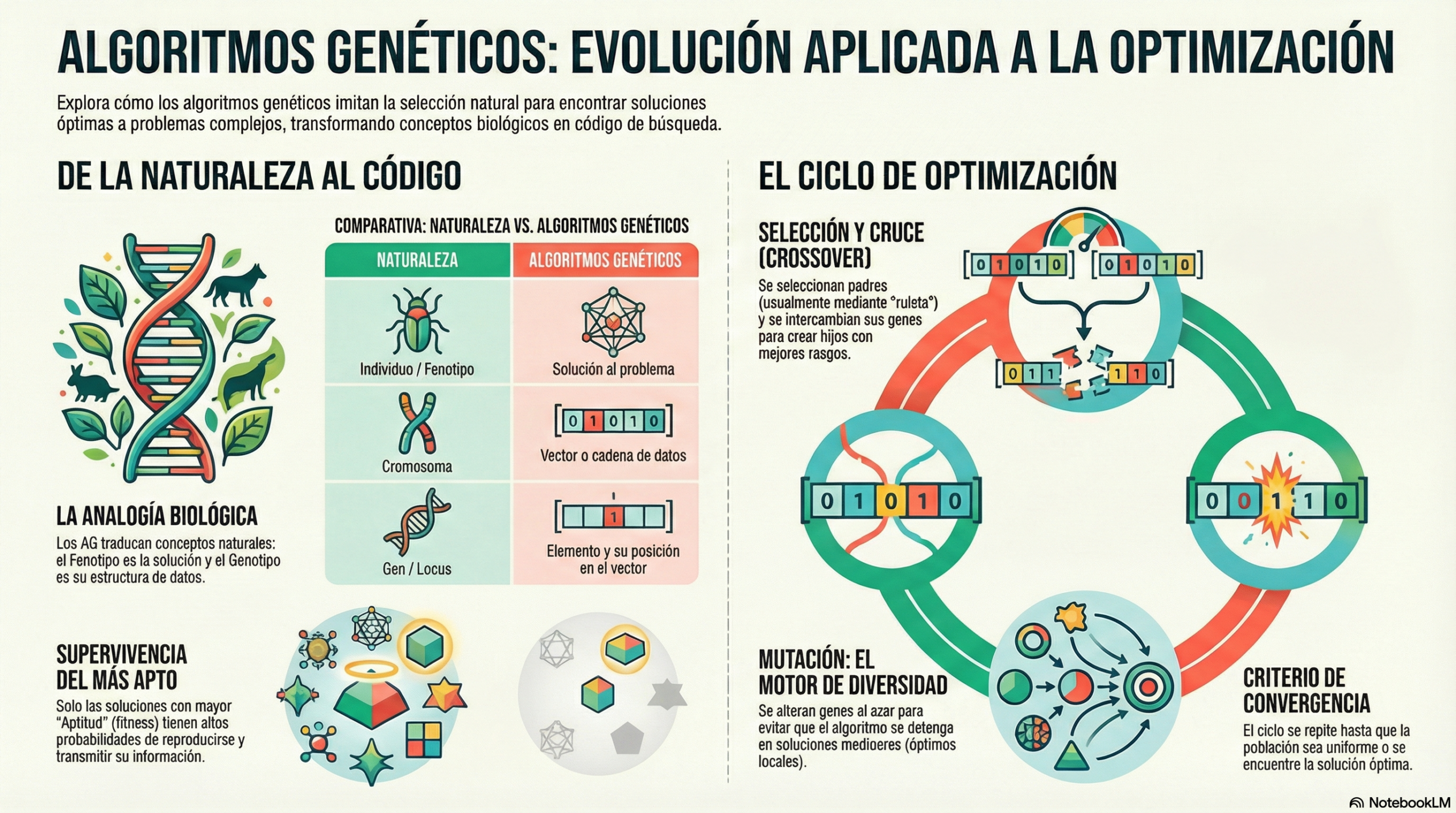
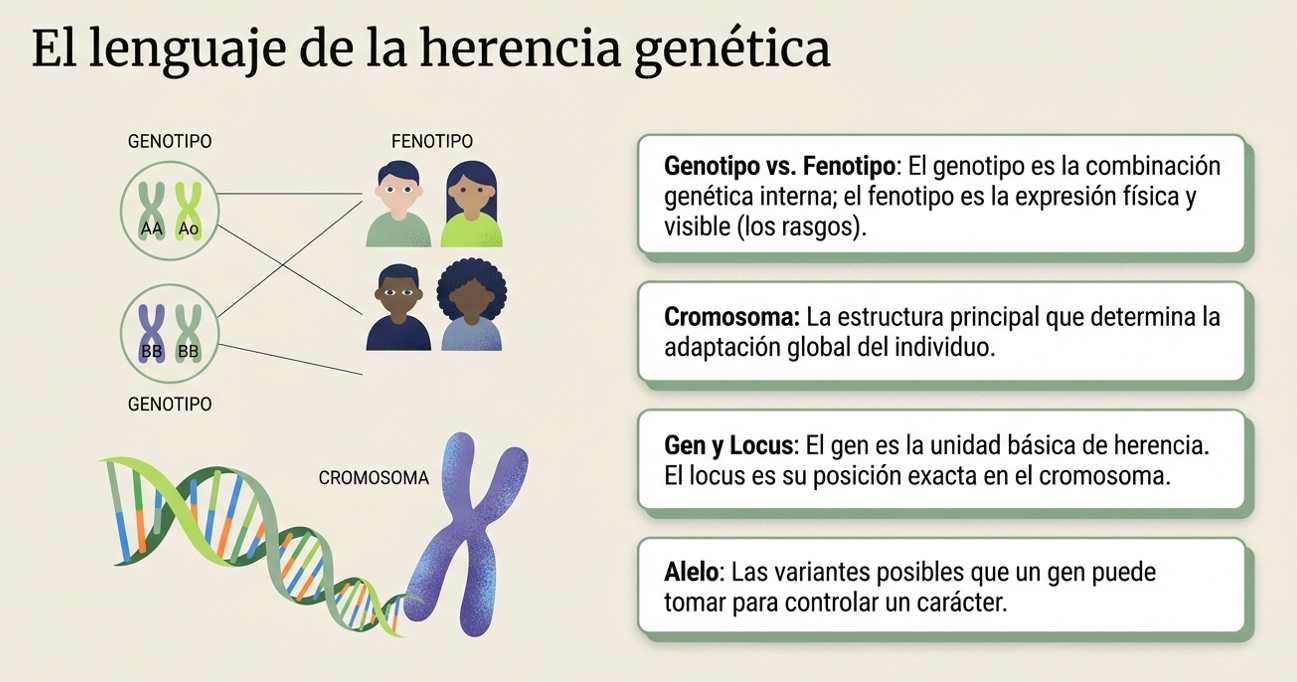
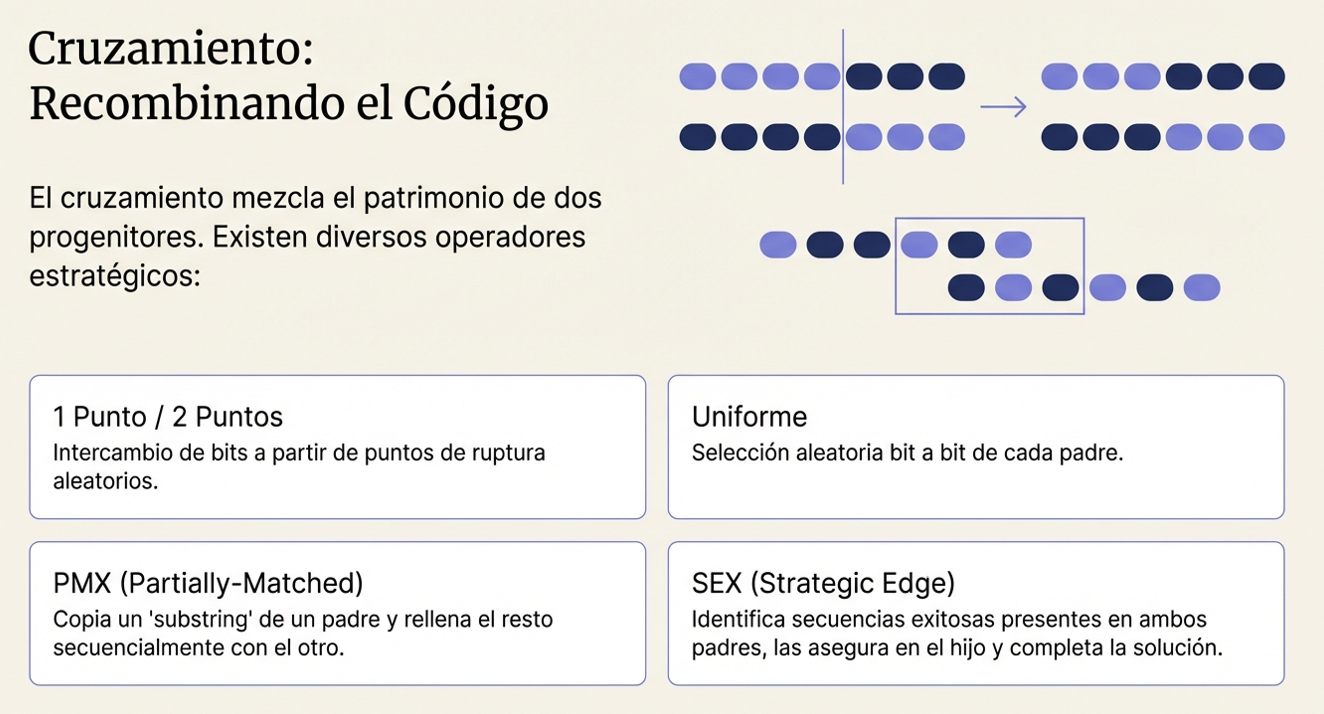
De la biología al código: el espejo de la optimización.
La informática ha logrado traducir estos comportamientos biológicos en algoritmos de búsqueda altamente sofisticados. Para comprender esta transición del mundo natural al ámbito del procesador, es necesario observar cómo cada elemento biológico encuentra su contraparte matemática.

Esta estructura permite a los programadores utilizar la lógica de la colonia para explorar enormes espacios de soluciones, donde encontrar la respuesta perfecta sería inviable con métodos tradicionales.
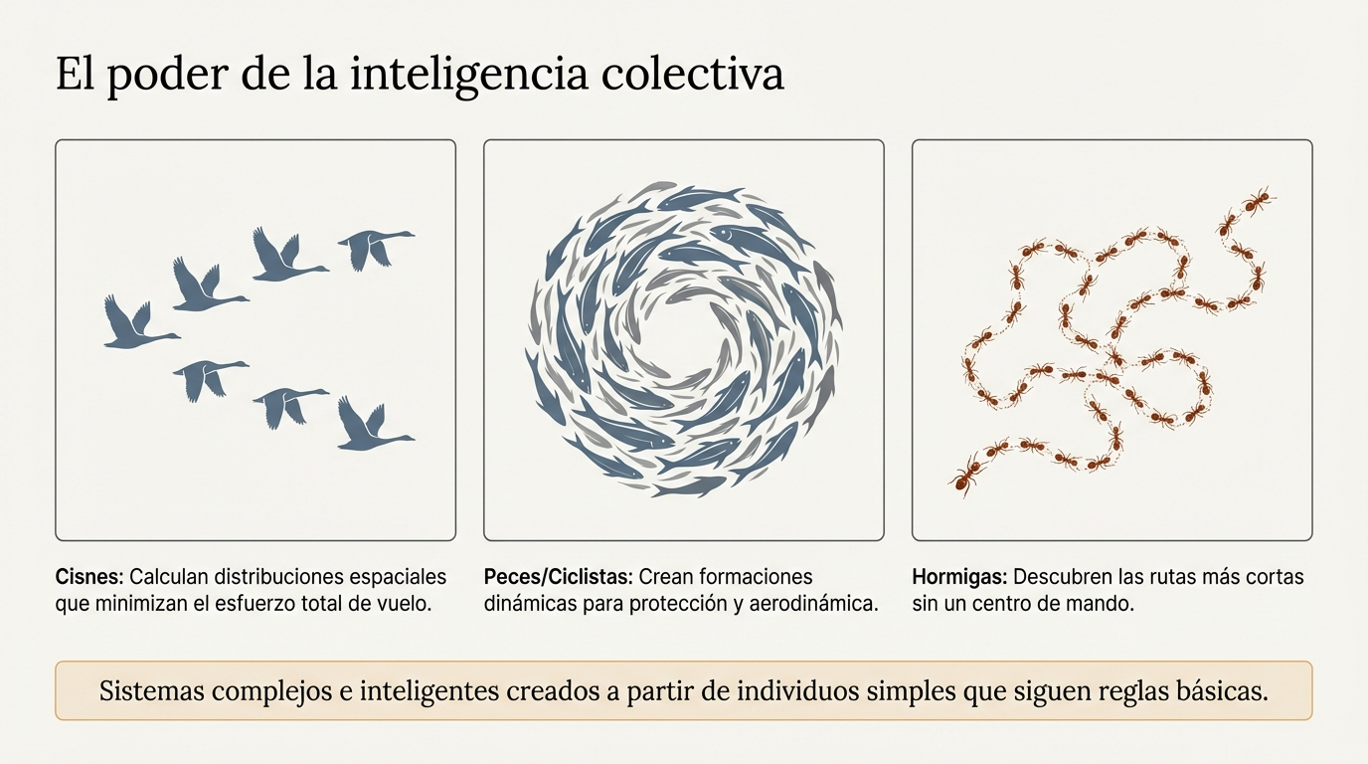
No estamos solos: el club de los optimizadores naturales.
Las hormigas no son las únicas maestras del arte de la economía de recursos. La naturaleza es un club exclusivo de optimizadores en el que la eficiencia es una ley universal de supervivencia, no una invención humana. Otros ejemplos destacados son:
- Los cisnes: al volar en formación de V, calculan una distribución espacial precisa para minimizar el esfuerzo total que debe realizar la bandada para desplazarse de un punto A a otro B.
- Los depredadores y los peces: los patrones de ataque de los primeros y las formaciones de los segundos buscan la máxima efectividad con el mínimo riesgo energético.
- Los ciclistas: apelotonándose instintivamente en una carrera para reducir la resistencia al viento, emulan estos patrones de optimización colectiva.
Conclusión: un futuro inspirado en lo pequeño.
En 1991, los investigadores Corloni, Dorigo y Maniezzo abrieron una puerta trascendental al sugerir que podíamos imitar el comportamiento de los insectos para resolver problemas de optimización combinatoria. Esa semilla científica nos permite hoy en día gestionar redes de tráfico complejas, diseñar ciudades más habitables y optimizar las cadenas logísticas globales que sustentan nuestra economía.
Si aprendiéramos a «escuchar» y a observar con mayor detenimiento los rastros y la información que fluyen en nuestro propio universo, quizá descubriríamos soluciones a problemas que hoy consideramos irresolubles.
En definitiva, nos queda una reflexión provocadora: si una hormiga no sabe que está resolviendo un algoritmo, ¿qué problemas estamos resolviendo colectivamente sin darnos cuenta?
En esta conversación puedes escuchar algunas de las ideas más interesantes sobre el tema.
Este vídeo resume bien los conceptos básicos de la optimización mediante la colonia de hormigas.
Ant_Colony_Optimization Ant_Colony_Optimization
Referencias:
COLORNI, A.; DORIGO, M.; MANIEZZO, V. (1991). Distributed optimization by ant colonies, in VARELA, F.J.; BOURGINE, P. (eds.) Proceedings of the First European Conference on Artificial Life (ECAL-91). The MIT Press: Cambrige, MA, 134-142.
MARTÍNEZ, F.; PEREA, C.; YEPES, V.; HOSPITALER, A.; GONZÁLEZ-VIDOSA, F. (2007). Optimización heurística de pilas rectangulares huecas de hormigón armado. Hormigón y Acero, 244: 67-80. ISBN: 0439-5689. (link)
MARTÍNEZ, F.J.; GONZÁLEZ-VIDOSA, F.; HOSPITALER, A.; YEPES, V. (2010). Heuristic Optimization of RC Bridge Piers with Rectangular Hollow Sections. Computers & Structures, 88: 375-386. ISSN: 0045-7949. (link)
YEPES, V. (2003). Apuntes de optimización heurística en ingeniería. Editorial de la Universidad Politécnica de Valencia. Ref. 2003.249. Valencia, 266 pp. Depósito legal: V-2720-2003.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.