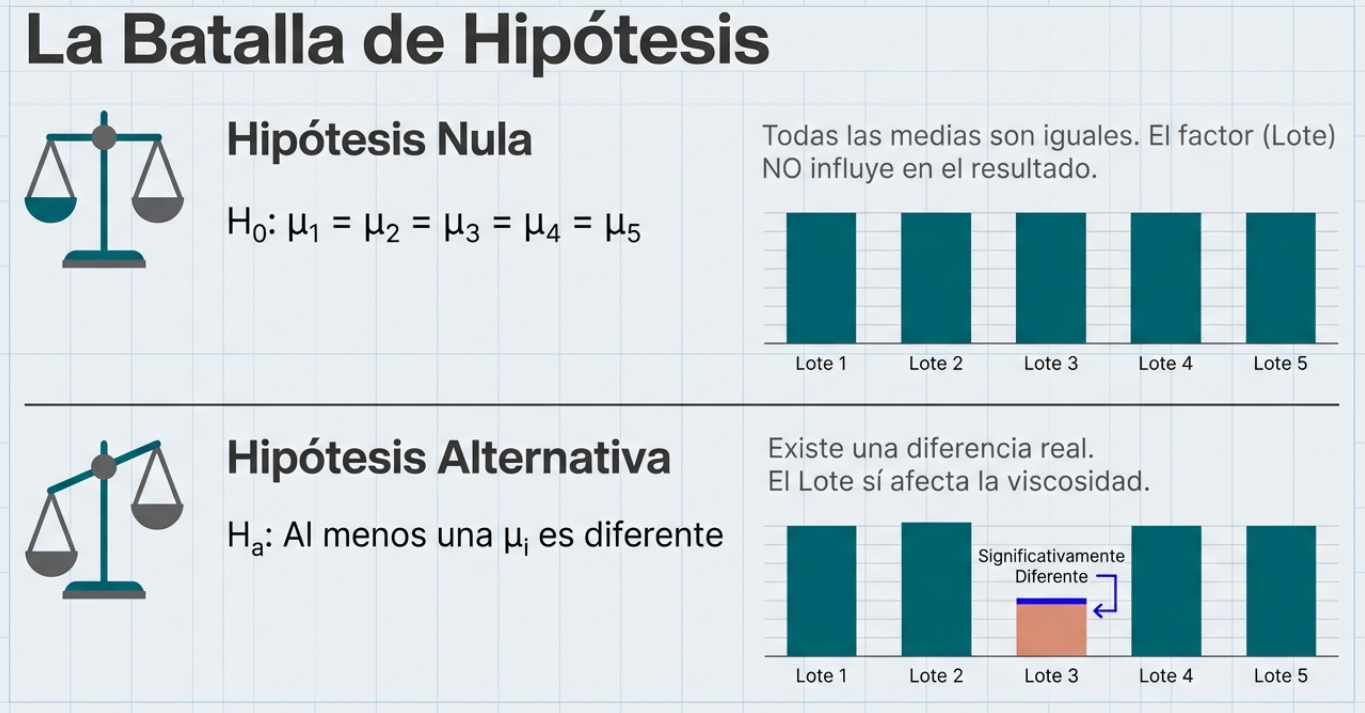
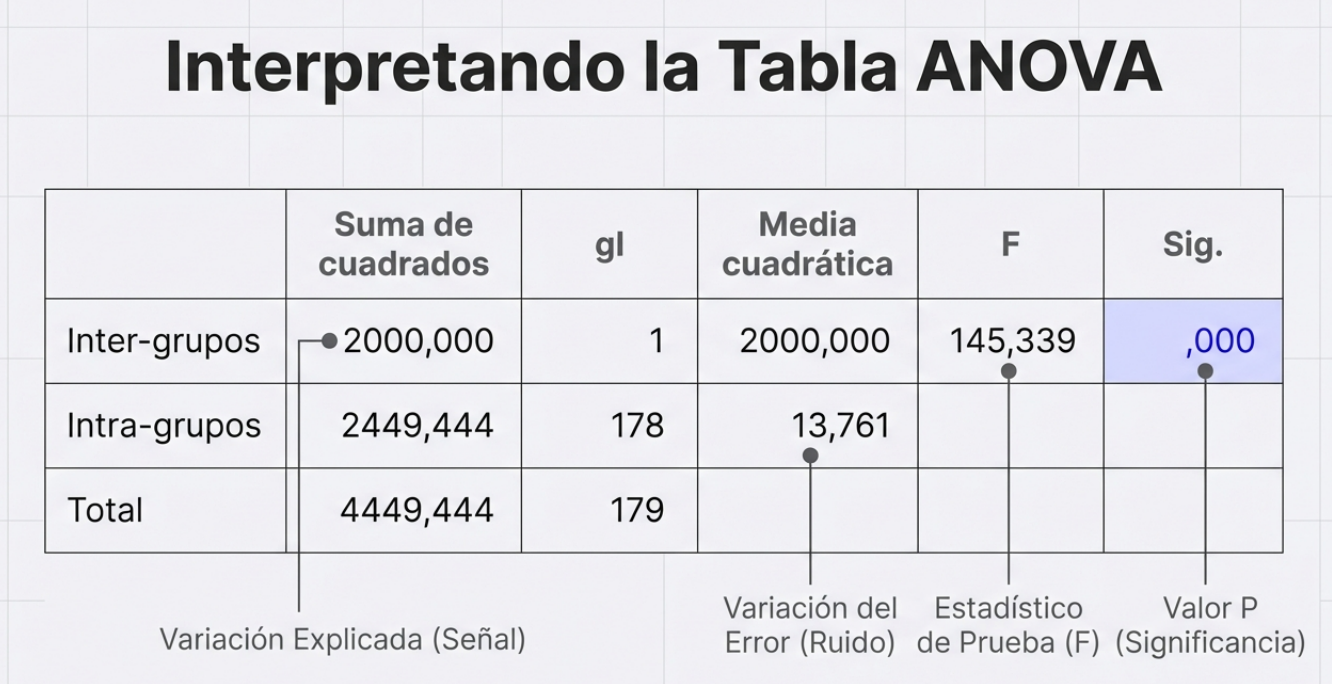
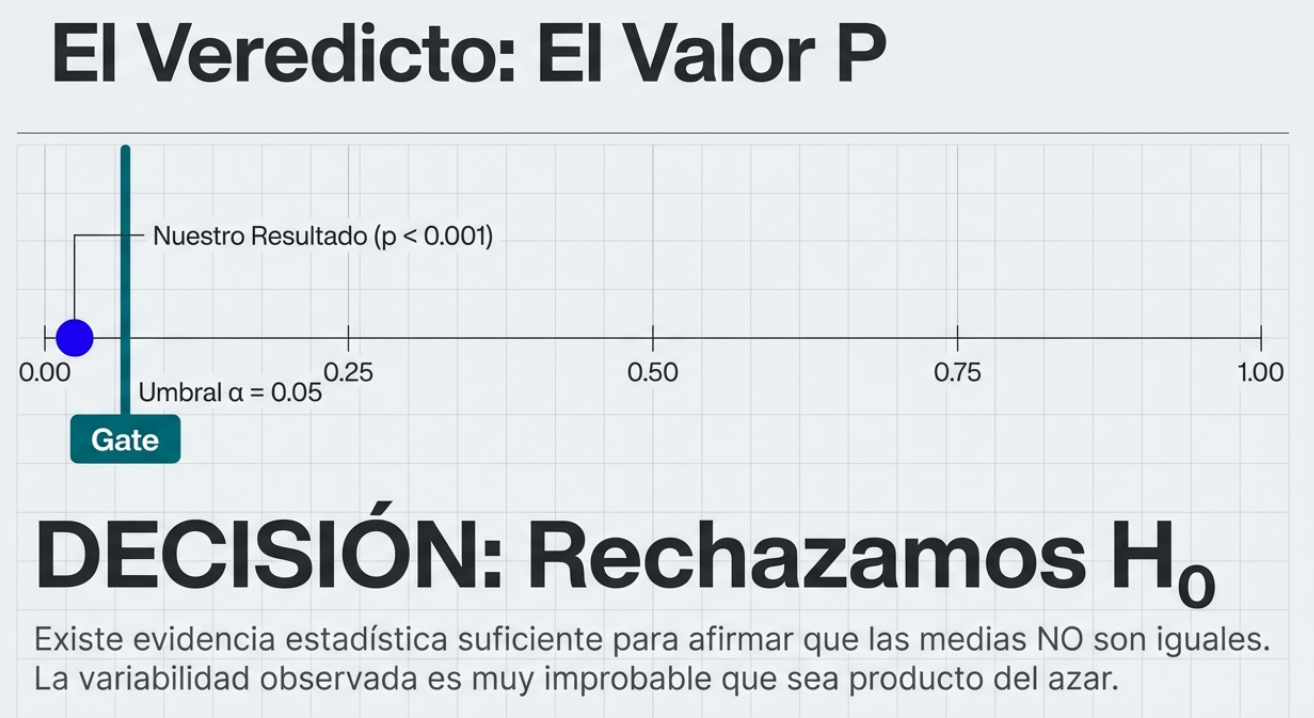
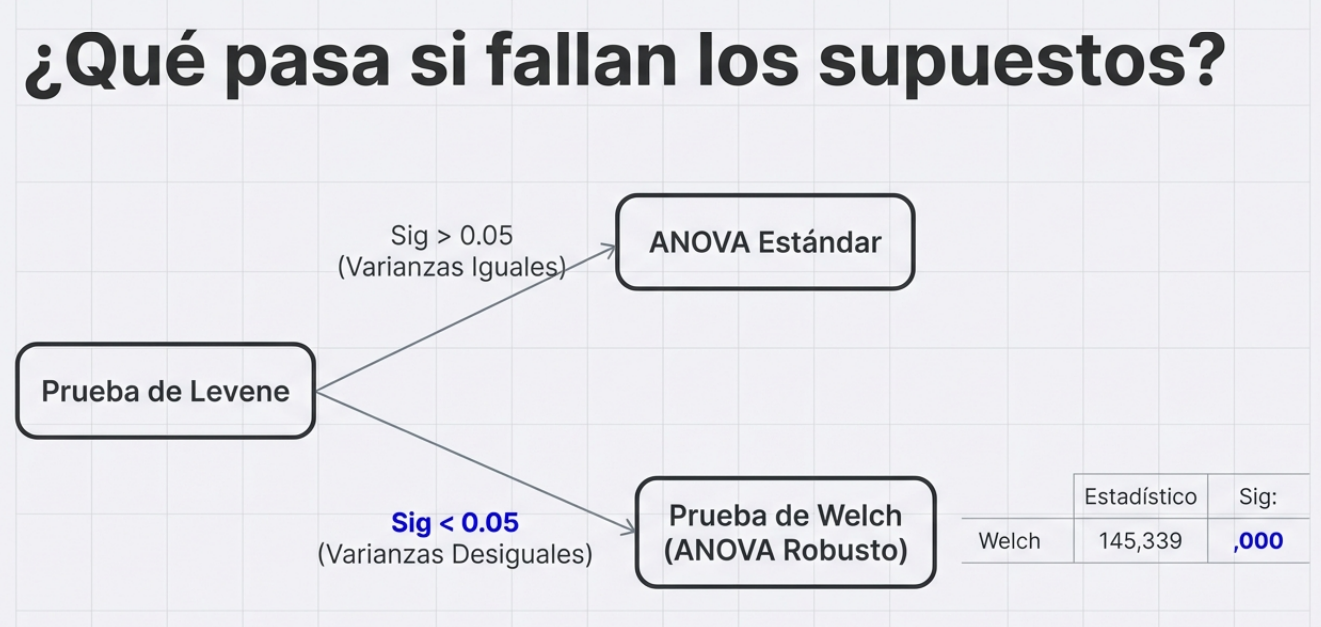
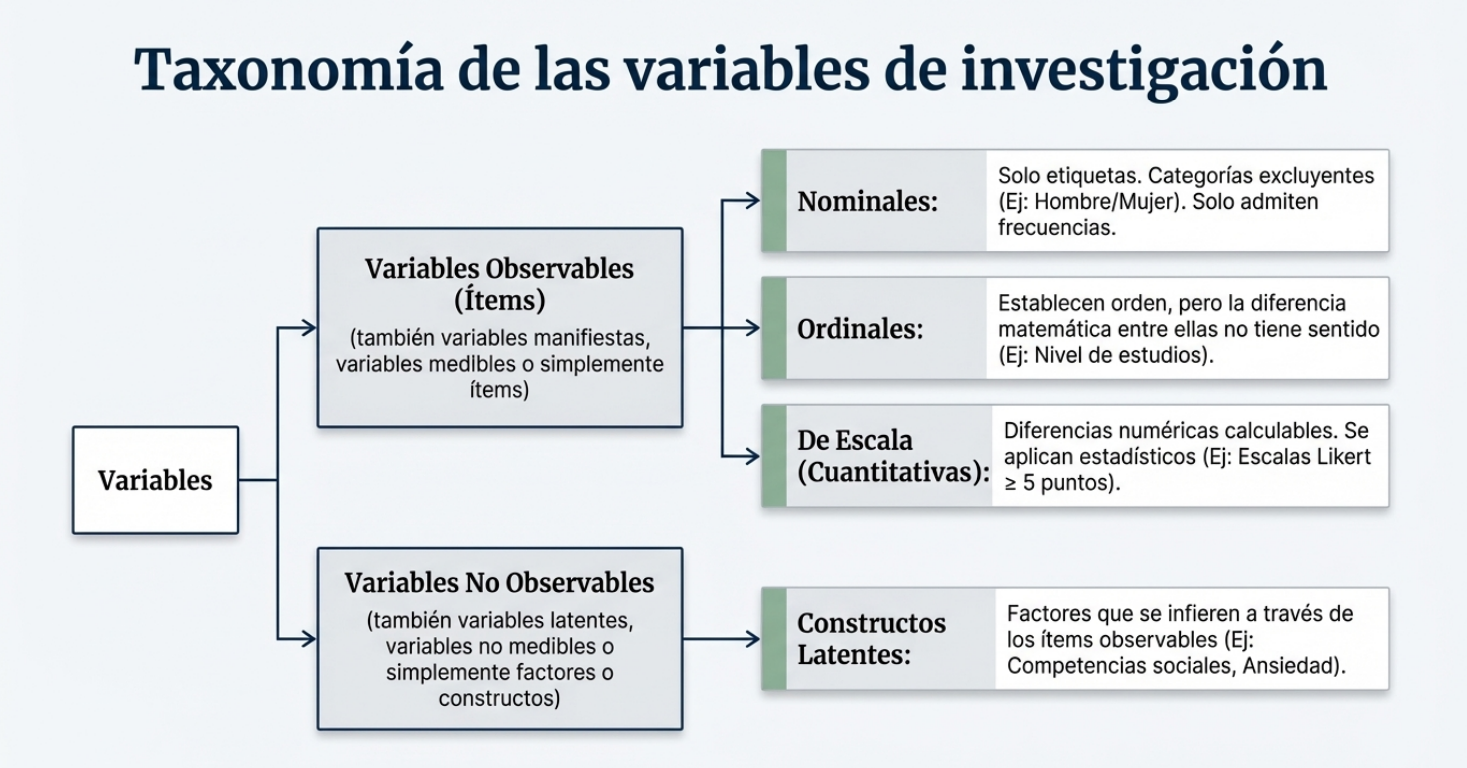
Medir la temperatura de un fluido o la resistencia de un material es una tarea técnica que emplea parámetros físicos tangibles. Sin embargo, cuando el objeto de estudio es la mente humana (opiniones, actitudes o rasgos de personalidad), entramos en el terreno de las variables no observables, también conocidas como constructos latentes.
Medir la temperatura de un fluido o la resistencia de un material es una tarea técnica que emplea parámetros físicos tangibles. Sin embargo, cuando el objeto de estudio es la mente humana (opiniones, actitudes o rasgos de personalidad), entramos en el terreno de las variables no observables, también conocidas como constructos latentes.
Aunque las encuestas son la herramienta universal para capturar esta subjetividad, la mayoría falla no por la tecnología empleada, sino por errores de diseño psicométrico que invalidan el dato desde su origen.
Desde que Rensis Likert introdujo su escala en 1932, esta se ha convertido en el estándar para convertir percepciones en métricas. No obstante, su uso profesional exige una rigurosidad que trasciende la mera formulación de preguntas al azar. Debemos comprender que una escala es un instrumento de precisión diseñado para capturar la esencia de lo inobservable. A continuación, presentamos cinco aspectos fundamentales para garantizar que sus mediciones sean científicamente válidas.
1. Lo subjetivo es el reino, no el dato objetivo.
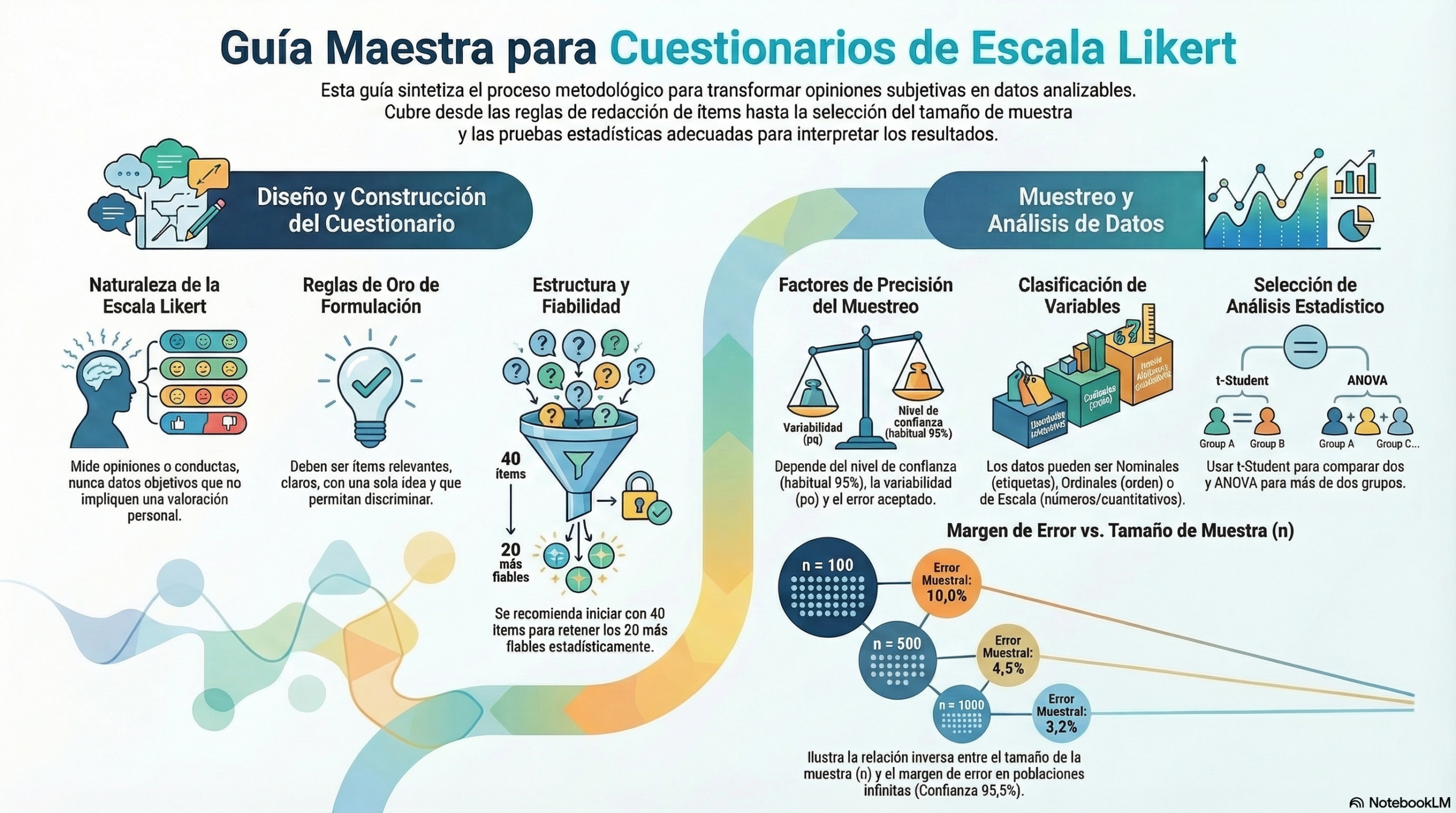
La base de una escala Likert es la medición de una valoración personal, no de una competencia. Un error metodológico frecuente consiste en incluir preguntas que miden conocimientos factuales en lugar de preguntas que miden actitudes. Si un ítem tiene una respuesta técnicamente «correcta», deja de ser una escala de opinión para convertirse en un examen.
Para garantizar la pureza del constructo, la formulación debe seguir tres reglas de oro:
- Enfoque: centrarse exclusivamente en opiniones o conductas.
- Unidimensionalidad: incluir una sola idea por ítem para evitar el ruido en la medición.
- Claridad gramatical: evitar expresiones negativas que puedan confundir al sujeto.
Como bien señala la norma psicométrica:
«Nunca en forma de datos objetivos que impliquen una valoración personal (conocimientos)».
2. La regla del 40-20: supervivencia de ítems y validez de las subescalas.
En el diseño de cuestionarios, la cantidad es el filtro de la calidad. No existe un número óptimo de ítems a priori, pero sí una metodología de «supervivencia»: para obtener un instrumento robusto, se recomienda partir de unos 40 ítems iniciales y retener finalmente entre 20 y 30.
¿Por qué este excedente? El uso de ítems repetitivos (expresar la misma idea de diversas formas) permite aumentar la discriminación y aislar la señal real del error de medida. Durante la fase de pretest, debemos descartar los ítems que no discriminan, es decir, aquellos que son aceptados o rechazados por casi todos los sujetos, para fortalecer la consistencia interna.
Además, hay pruebas que sugieren que el orden y la estructura son importantes: agrupar los ítems por temas o subescalas, en lugar de mezclarlos aleatoriamente, aumenta la validez convergente y divergente y facilita una interpretación más precisa de los factores medidos.

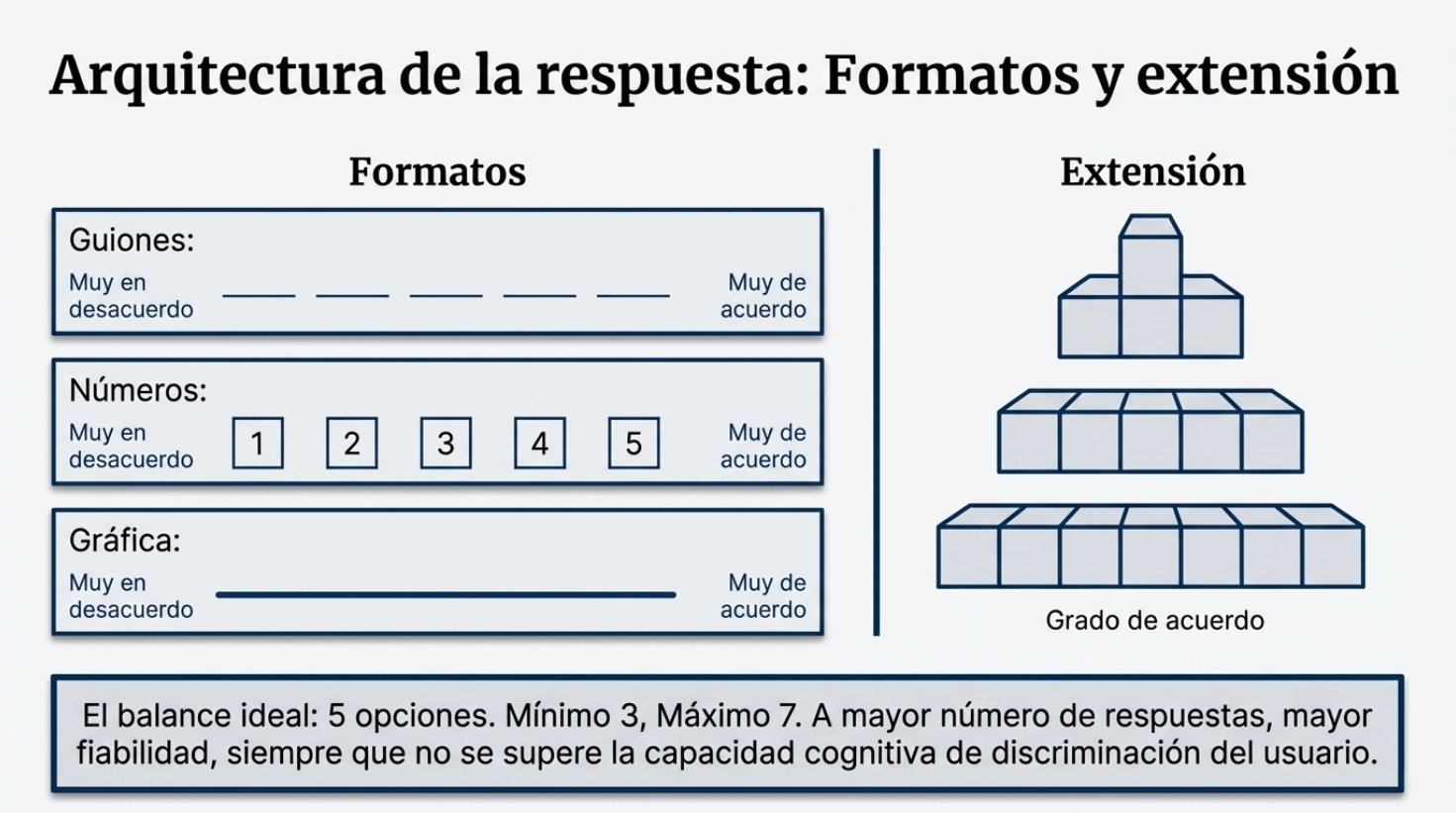
3. El dilema del número impar y la capacidad de discriminación.
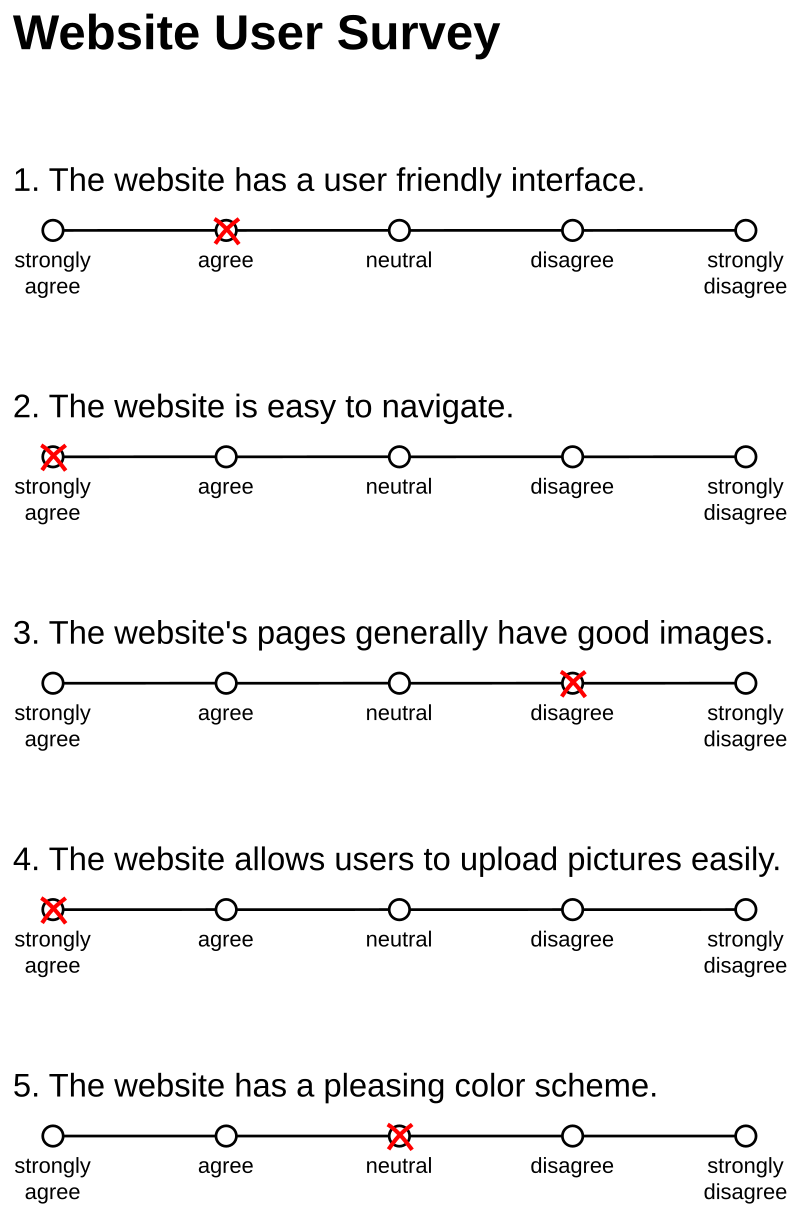
La controversia sobre si se debe ofrecer una «salida neutral» (como la clásica opción «Indiferente») sigue vigente. El estándar oscila entre tres y siete opciones de respuesta, siendo cinco el número más habitual. Un número impar permite la ambivalencia, mientras que uno par obliga a decantarse por una opción.
Desde el punto de vista psicométrico, no existe un consenso definitivo sobre cuál es la mejor opción, lo que otorga libertad al investigador. Sin embargo, existe un límite técnico infranqueable: la capacidad de discriminación del sujeto. Aumentar el número de respuestas puede mejorar la fiabilidad de la escala, pero solo hasta el punto en que el encuestado sea capaz de distinguir entre los matices. Superar ese umbral solo introduce fatiga y errores aleatorios en la matriz de datos.
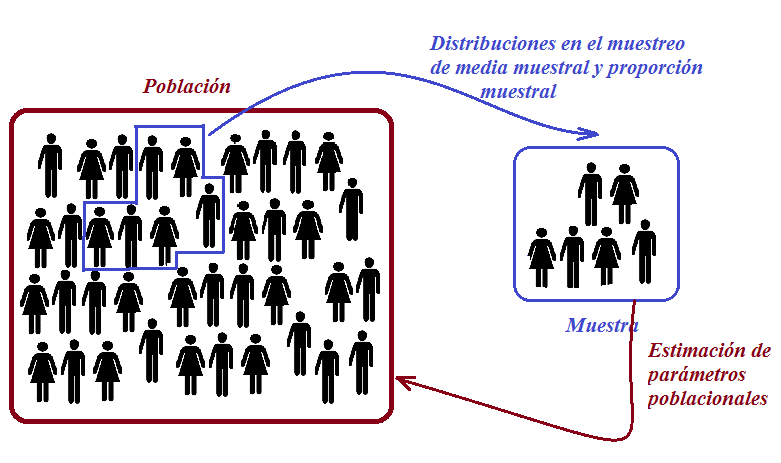
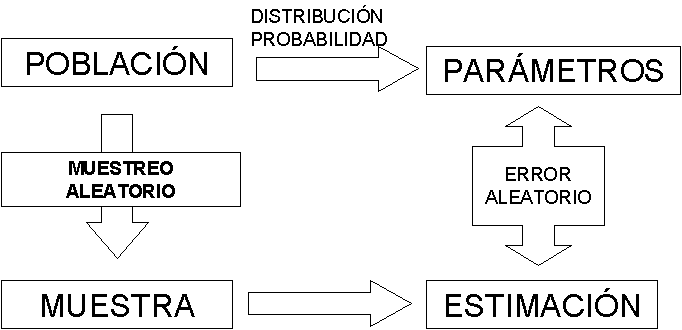
4. El mito del tamaño: por qué una muestra gigantesca no elimina el sesgo.
Es un error común pensar que una muestra muy grande garantiza precisión. En psicometría, el nivel de confianza o riesgo de primera especie (z) gestiona el riesgo de equivocarnos al generalizar, pero no elimina el sesgo de selección. Una muestra de 10 000 personas puede ser menos precisa que una de 500 si la primera está sesgada.
Para poblaciones extensas, la estrategia más adecuada es la estratificación. Al segmentar la población en estratos, garantizamos la representatividad de los grupos críticos y obtenemos una interpretación más precisa de los resultados. Debemos recordar siempre que:
«Una muestra de gran tamaño no garantiza que el margen de error sea pequeño, pues puede estar sesgada hacia segmentos de la población que están representados en exceso o poco representados».

5. La barrera de 5 puntos: ¿es un dato cuantitativo o una etiqueta ordinal?
Esta es, quizá, la distinción técnica más trascendental en el análisis de datos. La naturaleza de su escala determina qué operaciones matemáticas pueden realizarse legalmente.
- Variable de escala (cuantitativa): solo si la escala tiene 5 o más puntos de respuesta. En este caso, es estadísticamente lícito calcular la media y la desviación típica, considerando la opinión como un continuo numérico.
- Variable ordinal: si la escala tiene menos de cinco puntos. En este caso, no tiene sentido calcular diferencias entre categorías; el análisis se limita estrictamente a tablas de frecuencias (absolutas y relativas).
Ignorar esta distinción es un error grave en la comunicación de resultados: intentar presentar como promedio el resultado de una escala de tres puntos es una aberración estadística que distorsiona la realidad del constructo.
Reflexión final.
El cuestionario no es una simple lista de preguntas, sino un conjunto articulado y coherente de ítems diseñado para traducir la complejidad humana en datos operables. El éxito de su investigación depende de la arquitectura psicométrica subyacente, no del software que procese las respuestas.
Cuando finalice su próximo diseño, tómese un momento para evaluar si sus resultados serán estadísticamente operativos o meramente decorativos. La diferencia radica en el respeto a las leyes fundamentales de la medición.
En esta conversación puedes escuchar algunas de las ideas más interesantes sobre este tipo de encuestas.
El vídeo resume bien las ideas más importantes.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.