A veces me toca dirigir algún trabajo de investigación de mis estudiantes que trata de conocer la opinión sobre algún aspecto concreto. Normalmente se trata de temas relacionados con el sector de la construcción, aunque también suelo investigar si ha tenido éxito algún tipo de innovación educativa en mis clases. Para ello suelo aconsejar el uso de cuestionarios basados en escalas Likert, pues de esta forma facilito el análisis estadístico multivariante de los resultados.
A veces me toca dirigir algún trabajo de investigación de mis estudiantes que trata de conocer la opinión sobre algún aspecto concreto. Normalmente se trata de temas relacionados con el sector de la construcción, aunque también suelo investigar si ha tenido éxito algún tipo de innovación educativa en mis clases. Para ello suelo aconsejar el uso de cuestionarios basados en escalas Likert, pues de esta forma facilito el análisis estadístico multivariante de los resultados.
El problema siempre es el mismo: ¿Profesor, tengo suficientes encuestas o tengo que enviar más encuestas? Y la respuesta siempre es la misma: depende del objeto de la encuesta. Vamos a analizar esto por partes.
Si se trata de describir los resultados obtenidos de un grupo de estudio, la muestra representa a la totalidad de la población, y por tanto no es necesario alcanzar un número de respuestas mínimo. Por ejemplo, si en una asociación de empresarios de la construcción el número de socios es de 30 y todos responden el cuestionario, es evidente que los resultados del estudio representan de forma exacta lo que opinan los 30 socios.
Sin embargo, lo habitual es encontrarse con un número de respuestas que forman una muestra de una población. Aquí se trata de saber si podemos extrapolar los resultados a la población que representa la muestra. Para ello nos debemos hacer dos preguntas: ¿Es la muestra representativa? ¿Cuál es el margen de error que cometemos?
Las técnicas de muestreo permiten extraer muestras representativas. Estos muestreos pueden ser probabilísticos o no probabilísticos. Entre los primeros podemos resaltar el muestreo aleatorio sistemático, el estratificado o el muestreo por conglomerados. Entre los no probabilísticos, el muestreo por cuotas, por bola de nieve o el muestreo subjetivo por decisión razonada. Remito a los interesados a bibliografía específica, pues se escapa al objetivo de este artículo.
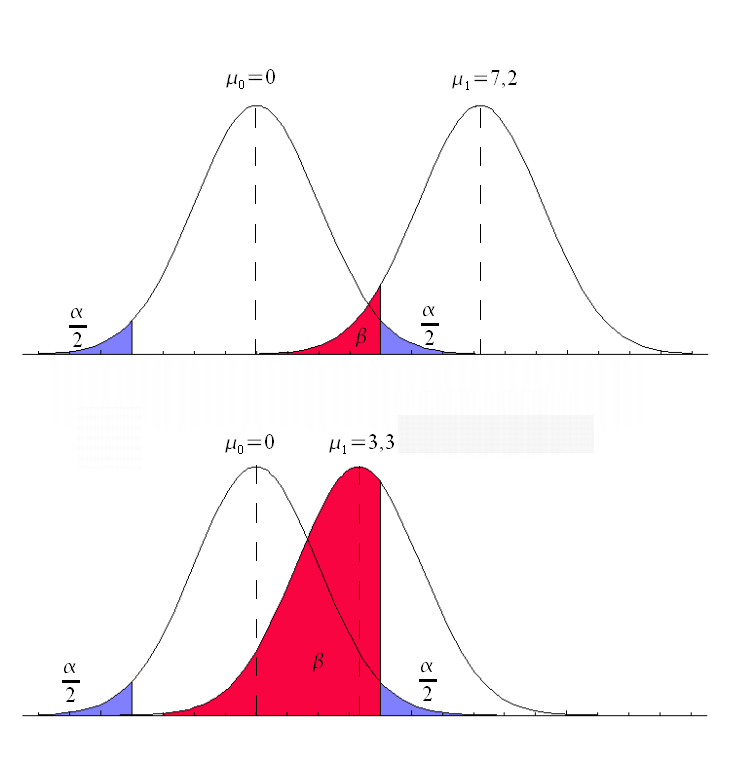
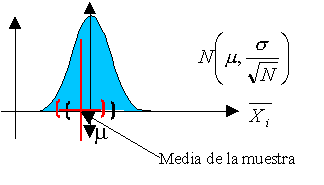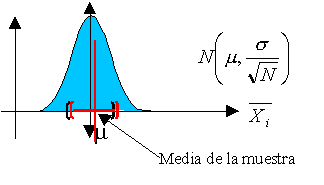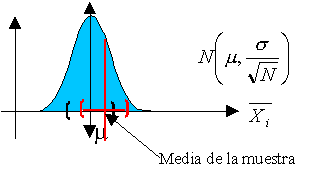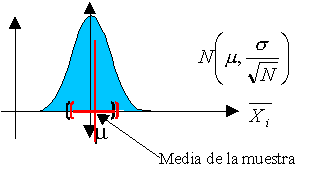
Aquí vamos a comentar brevemente lo relativo al error muestral. El error muestral se corresponde con el margen de error que estamos dispuestos a aceptar. Por ejemplo, si decimos que el 15% de la población está de acuerdo con algo y el error muestral es del 4%, realmente dicha opinión se encuentra entre el 11% y el 19% para un nivel de confianza determinado. Por eso, lo primero, será definir el nivel de confianza o riesgo de primera especie «z», que sería el riesgo que aceptamos de equivocarnos al presentar nuestros resultados. El nivel de confianza habitual es 1 – α = 95% o α = 5%. Se utiliza como «z», que es un valor de la distribución normal asociado a una determinada probabilidad de ocurrencia. Así, z=1,96 si 1 – α = 95%, z=2,00 si 1 – α = 95,5% y z=2,57 si 1 – α = 99%.
Otro factor a tener en cuenta es la variabilidad de las respuestas estimada en la población. Si sabemos que todos los sujetos piensan lo mismo, nos bastará preguntar a uno solo o a muy pocos. Pero si sabemos que habrá una gran diversidad de respuestas, hará falta una mayor número de sujetos en la muestra. Como lo normal es desconocer la variabilidad de las respuestas en la población, elegimos la mayor varianza posible p=q=50% (sería que el 50% respondiera que «sí» y el otro 50% lo contrario).
Las fórmulas que nos dan el error muestral, por tanto, dependen de los factores anteriores y también de conocer si la población es finita o infinita (más de 30.000 individuos ya se considera como infinita). En la figura se indican ambas fórmulas.
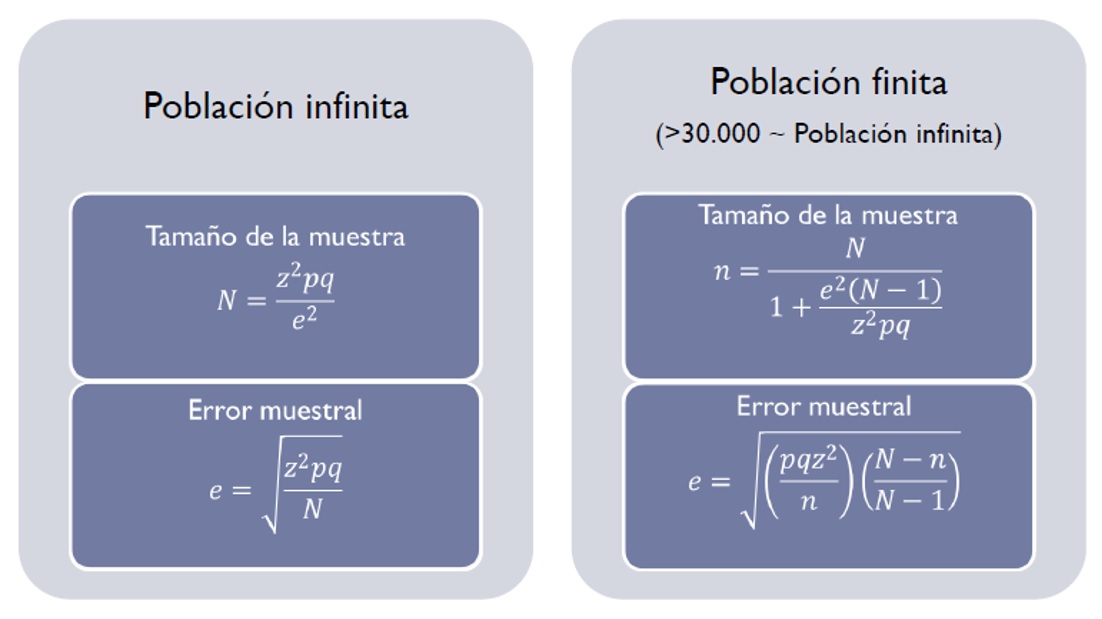
Si jugamos un poco con estas fórmulas, veremos que para un nivel de confianza del 95%, serían necesarias 96 respuestas en una población infinita y 95 respuestas en una población de un tamaño de 10.000 (casi coinciden) para un error muestral del 10%. Pero si queremos bajar el error al 5%, se eleva el número de respuestas a 384 en el caso de la población infinita y a 370 en el caso de una población finita de 10.000. Como vemos, se dispara el número de respuestas necesarias para reducir el error.
Por tanto, mi respuesta a mis estudiantes suele ser siempre la misma: vamos a intentar llegar a 100 respuestas para empezar a tener un error razonable.
En apretada síntesis, os quiero dar las siguientes consideraciones sobre el muestreo:
- No solo es necesario que el tamaño de la muestra sea suficiente, sino también que la muestra sea representativa de la población que tratamos de describir
- Una muestra de gran tamaño no garantiza que el margen de error sea pequeño, pues puede estar sesgada hacia segmentos de la población representados en exceso o poco representados
- Si la población a estudiar es demasiado grande es recomendable segmentarla en estratos y valorar en cuáles de ellos pueden obtenerse muestras representativas, facilitando así una interpretación de los resultados más precisa
- En general, el margen de error en cada estrato suele ser superior al margen de error de toda la muestra en conjunto. Es recomendable ser consciente de esta diferencia de precisión en la interpretación de resultados
Pues ahora una reflexión final: ¿Qué error tienen las encuestas que contestan los alumnos en relación con la calidad del profesor? ¿Es razonable tomar decisiones respecto a la continuidad o no de un profesor teniendo en cuenta estas encuestas? Tenéis las claves releyendo el artículo.
Aquí tenéis un vídeo sobre las técnicas de muestreo.
Os dejo a continuación un pequeño vídeo sobre el error de muestreo.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.