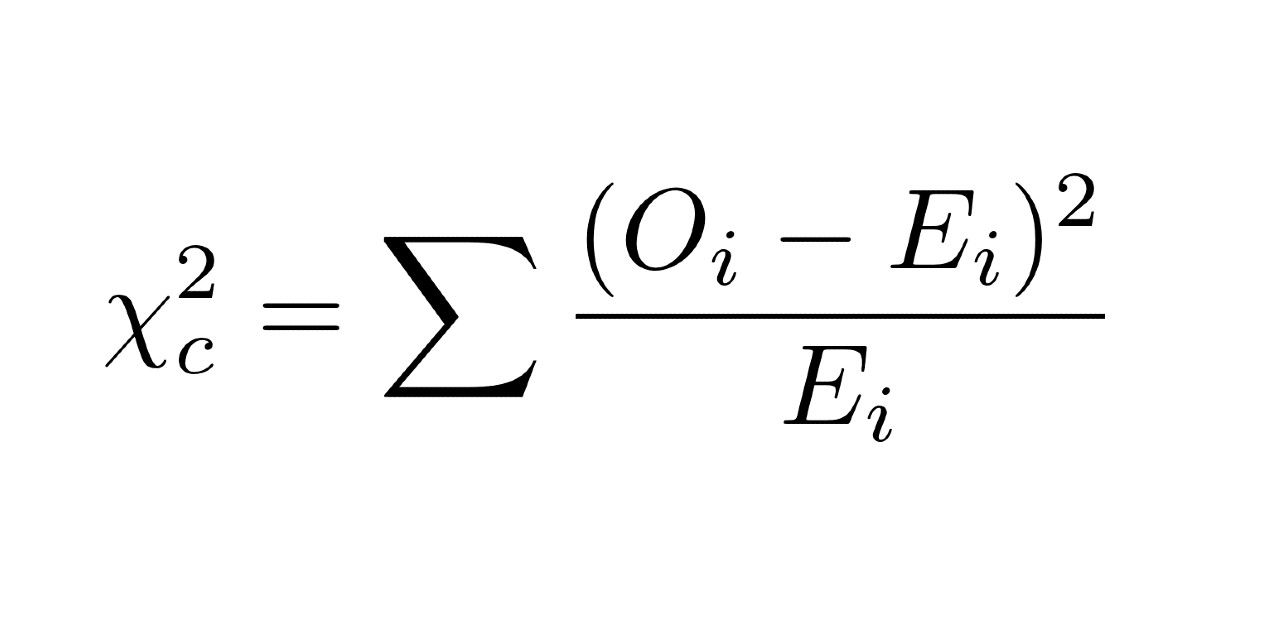Laboratorio de materiales de ICITECH. https://icitech.blogs.upv.es/index.php/home/laboratorio-de-materiales/
En la asignatura de “Modelos predictivos y de optimización de estructuras de hormigón”, del Máster en Ingeniería del Hormigón, se desarrollan laboratorios informáticos. En este caso, os traigo un ejemplo de aplicación de un diseño de experimentos. En este caso, un diseño de experimentos por bloques aleatorizados resuelto con SPSS y MINITAB.
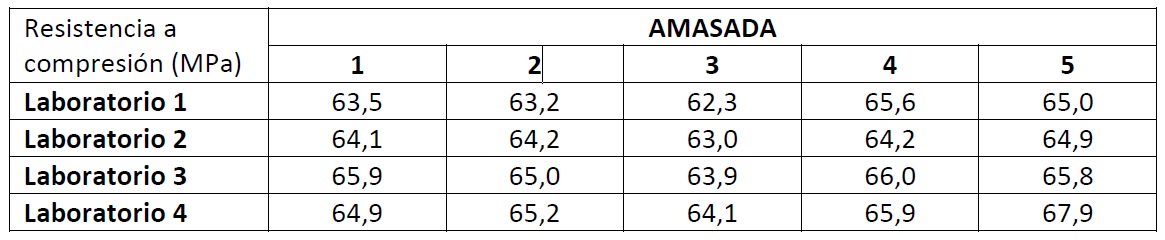
Se pretende comparar la resistencia a compresión simple a 28 días obtenidos por cuatro laboratorios diferentes. Para ello se realizan cinco amasadas diferentes y se obtienen las resistencias medias para cada amasada por cada uno de los laboratorios. Los resultados se encuentran en la tabla que sigue.
Os paso la resolución de este laboratorio informático. Espero que os sea de interés.
En la asignatura de «Modelos predictivos y de optimización de estructuras de hormigón», del Máster en Ingeniería del Hormigón, se desarrollan laboratorios informáticos. En este caso, os traigo un ejemplo de aplicación de un diseño de experimentos. En este caso, un diseño factorial fraccionado resuelto con MINITAB.
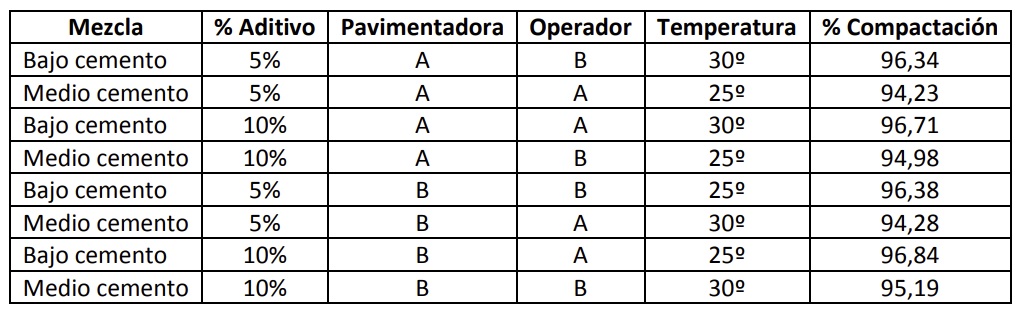
Se quiere determinar la mejor forma de elaborar hormigón compactado con una pavimentadora. La variable de respuesta es el porcentaje de compactación, medido con un densímetro nuclear. Tras una tormenta de ideas con expertos, se ha realizado un diseño de experimentos con 5 factores: el porcentaje de aditivo, la pavimentadora (A antigua, B moderna), el operador de la pavimentadora (A con poca experiencia, y B con mucha), el tipo de mezcla de hormigón y la temperatura del hormigón. Se ha tenido que realizar un diseño fraccionado puesto que el presupuesto limita el número de experimentos a un máximo de 12. Se pide que se analicen los resultados, que fueron los de la tabla siguiente:
Los datos de este caso provienen de la siguiente publicación: Arias, C.; Adanaqué, I.; Buestán, M. Optimización del proceso de elaboración de hormigón compactado con pavimentadora. Escuela Superior Politécnica del Litoral, Ecuador. http://www.dspace.espol.edu.ec/handle/123456789/4754
Os paso la resolución de este laboratorio informático. Espero que os sea de interés.
Figura 1. Paso superior sobre la N-II. https://ingedis.es/puentes.htm
Como ya habréis observado, en muchos de mis artículos os doy pistas sobre cómo utilizar determinadas herramientas que nos permiten, si sabemos utilizarlas, obtener información relevante y muchas veces no evidente de nuestras bases de datos. En esta ocasión os voy a hablar de los métodos jerárquicos de análisis cluster, y en particular, de los dendrogramas. En el contexto de la minería de datos, se consideran los algoritmos de agrupamiento (clustering), como una técnica de aprendizaje no supervisado.
Los llamados métodos jerárquicos buscan formar agrupaciones de elementos de forma sucesiva, de modo que se minimice alguna distancia o maximice alguna medida de similitud. Estos métodos se dividen, a su vez, en métodos aglomerativos -también llamados ascendentes- que comienzan con tantos grupos como individuos haya, formándose grupos de forma ascendente, de forma que al final todos los casos se engloban en un mismo aglomerado. Por contra, los métodos disociativos -descendentes- hacen lo contrario, comienzan con un conglomerado que engloba todos los casos y, con sucesivas divisiones, se forman grupos cada vez más pequeños hasta llegar a tantas agrupaciones como casos.
Un dendrograma es una representación gráfica de los datos en forma de árbol que los organiza en subcategorías que se van dividiendo hasta llegar al nivel de detalle deseado. Para formar este diagrama se forman conglomerados de observaciones en cada paso y sus niveles de similitud. El nivel de similitud se mide en el eje vertical (aunque también se puede mostrar el nivel de distancia), y las diferentes observaciones se especifican en el eje horizontal.
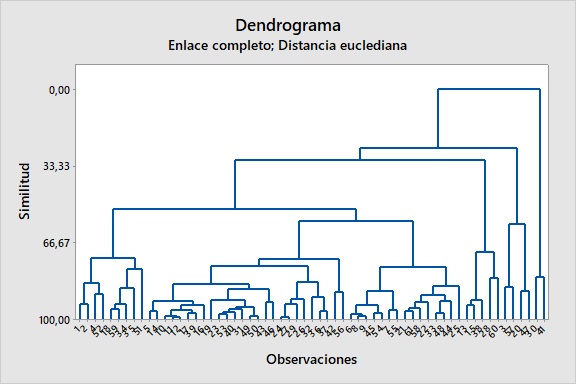
Veamos cómo se puede utilizar dicha herramienta. Para eso vamos a utilizar los datos recopilados de 61 puentes losa postesados aligerados (Yepes et al., 2009). Utilizamos el software Minitab para este análisis. En la Figura 2 se ha realizado un análisis para las 61 observaciones. Aunque permite determinar qué puentes son más parecidos entre sí, la verdad es que la información que nos deja es difícil de manejar.
Figura 2. Dendrograma obtenido por conglomerado de las 61 observaciones de puentes losa (Yepes et al., 2009)
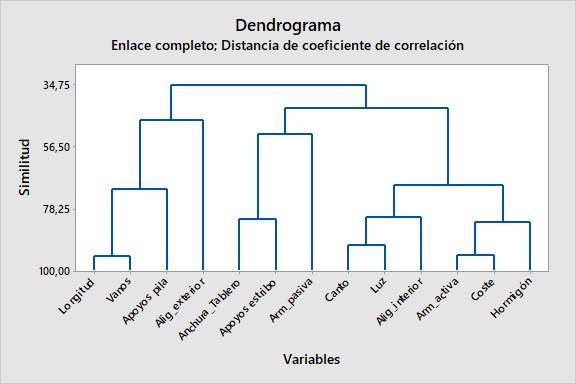
En cambio, si realizamos el mismo análisis respecto a las variables que definen el puente y a su coste, obtenemos información relevante, tal y como se puede observar en la Figura 3. El conglomerado de variables a sí obtenido comienza con todas las variables separadas, cada una formando su propio conglomerado. En el primer paso, las dos variables más cercanas entre sí se unen. En el siguiente paso, una tercera variable se une a las primeras dos u otras dos variables se unen para formar un conglomerado diferente. Este proceso continuará hasta que todos los conglomerados se unan en un solo conglomerado. En el caso estudiado, se ha utilizado como medición de la distancia la correlación y el método de vinculación completo. De esta forma conseguimos que un conglomerado se encuentre dentro de una distancia máxima, tendiéndose a producir conglomerados con diámetros similares.
Figura 3. Dendrograma realizado con las variables que definen los 61 puentes losa postesados (Yepes et al., 2009)
La Figura 3 ya nos permite interpretar cómo se relacionan las variables de un puente losa postesado, siendo un análisis que es coherente con los resultados obtenidos en Yepes et al. (2009). Se observa que el coste está muy relacionado con la cuantía de armadura activa, y también, con la cuantía de hormigón empleado. También se observa la estrecha relación entre el canto y la luz del puente, que junto con la cuantía del aligeramiento interior, se aglomeran a otro nivel para configurar el coste. Otras relaciones son evidentes, como que la longitud total del puente y el número de vanos son magnitudes muy relacionadas, o cómo la anchura del tablero se relaciona con el número de apoyos existentes en el estribo.
Figura 1. ¿Depende la calidad del hormigón de un proveedor determinado?
En ocasiones nos encontramos con un par de variables cualitativas que, a priori, no sabemos si están relacionadas entre sí o si pertenecen a una misma población estadística. Recordemos que las variables cualitativas son aquellas cuyo resultado es un valor o categoría de entre un conjunto finito de respuestas (tipo de defecto, nombre del proveedor, color, etc.).
En el ámbito del hormigón, por ejemplo, podríamos tener varios proveedores de hormigón preparado en central y un control del número de cubas-hormigonera aceptadas, aceptadas con defectos menores o rechazadas. Otro ejemplo sería contabilizar el tipo de incumplimiento de una tolerancia por parte de un equipo que está encofrando un muro de contención. En estos casos, se trata de determinar si existe dependencia entre los proveedores o los equipos de encofradores respecto de los defectos detectados. Esto sería interesante en el ámbito del control de la calidad para tomar medidas, como pudiese ser descartar a determinados proveedores o mejorar la formación de un equipo de encofradores.
Así, podríamos tener un problema como el siguiente: Teniendo en cuenta el punto 5.6 del Anejo 11 de la EHE, donde se definen las tolerancias de muros de contención y de sótano, se quiere comprobar si tres equipos de encofradores producen de forma homogénea en la ejecución de muros vistos, o, por el contrario, si unos equipos producen más defectos de un tipo que otro. Todos los equipos emplean el mismo tipo de encofrado. Las tolerancias que deben cumplirse son:
1. Desviación respecto a la vertical
2. Espesor del alzado
3. Desviación relativa de las superficies planas de intradós o de trasdós
4. Desviación de nivel de la arista superior del intradós, en muros vistos
5. Tolerancia de acabado de la cara superior del alzado, en muros vistos
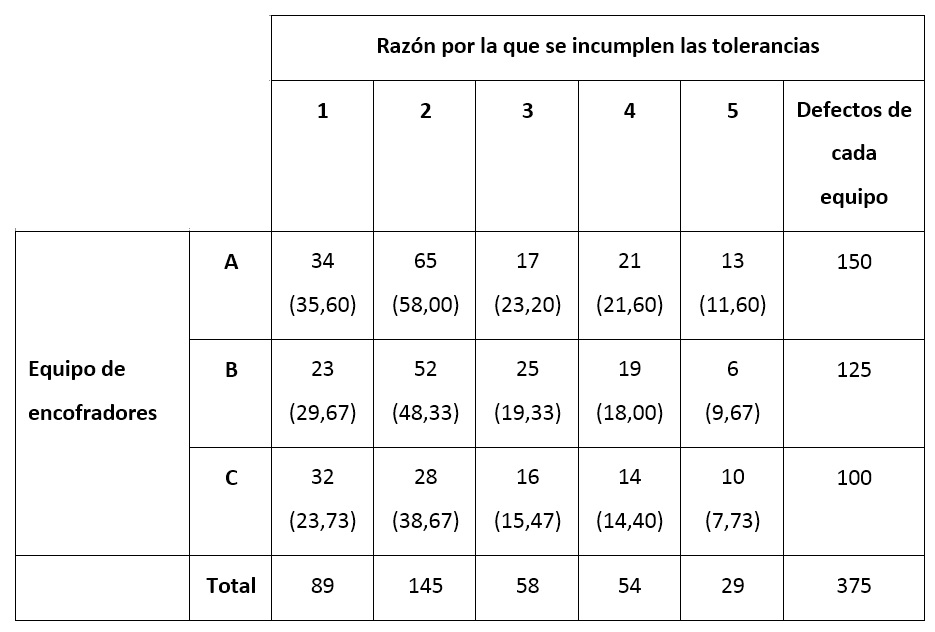
Los equipos han estado trabajando durante un año ejecutando este tipo de unidad de obra. Durante este tiempo el número de defectos en relación con la tolerancia dimensional ha sido pequeño, pero se han contabilizado 375 defectos. El control de calidad ha dado como resultado el conteo de la tabla de la Figura 2.
Figura 2. Conteo de incumplimientos según el equipo de encofradores. En paréntesis figura el valor esperado.
En la Figura 2 se ha representado también la frecuencia esperada para cada uno de los casos. Por ejemplo, la fracción esperada del incumplimiento «1» es de 89/375, mientras que la fracción esperada de defectos del equipo A es de 150/375. Ello implica que el valor esperado de incumplimientos del tipo «1» para el equipo de encofradores «A» sería: (89/375)·(150/375)·375=89·150/375=35,60.
La pregunta que nos podríamos hacer es la siguiente: ¿Influye el tipo de proveedor en la calidad de la recepción del hormigón? Para ello plantearíamos la hipótesis nula: el tipo de proveedor no influye en la calidad de la recepción del hormigón. La hipótesis alternativa sería que sí existe dicha influencia o dependencia entre las variables cualitativas.
Para ello, necesitamos una prueba estadística; en este caso, la prueba χ². El fundamento de la prueba χ² es comparar la tabla de las frecuencias observadas respecto a la de las frecuencias esperadas (que sería la que esperaríamos encontrar si las variables fueran estadísticamente independientes o no estuvieran relacionadas). Esta prueba permite obtener un p-valor (probabilidad de equivocarnos si rechazamos la hipótesis nula) que podremos contrastar con el nivel de confianza que determinemos. Normalmente el umbral utilizado es de 0,05. De esta forma, si p < 0,05, se rechaza la hipótesis nula y, por tanto, diremos que las variables son dependientes. Dicho con mayor precisión, en este caso no existe un nivel de significación suficiente que respalde la independencia de las variables.
Las conclusiones que se obtienen de la prueba son sencillas de interpretar. Si no existe mucha diferencia entre los valores observados y los esperados, no hay razones para dudar de que las variables sean independientes.
No obstante, hay algunos problemas con la prueba χ², entre ellos el relacionado con el tamaño muestral. A mayor número de casos analizados, el valor de la χ² tiende a aumentar. Es decir, si la muestra es excesivamente grande, será más fácil que rechacemos la hipótesis nula de independencia, cuando a lo mejor podrían ser las variables independientes.
Por otra parte, cada una de las celdas de la tabla de contingencia debería contar con un mínimo de 5 observaciones esperadas. Si no fuera así, podríamos agrupar filas o columnas (excepto en tablas 2×2). También se podría eliminar la fila que muestra una frecuencia esperada menor que 5.
Por último, no hay que abusar de la prueba χ². Por ejemplo, podríamos tener una variable numérica, como la resistencia característica del hormigón, y agruparla en una variable categórica en grupos como 25, 30, 35, 40, 45 y 50 MPa. Lo correcto cuando tenemos una escala numérica es aplicar la prueba t de Student; es incorrecto convertirla en una escala ordinal o incluso binaria.
A continuación os dejo el problema anterior resuelto, tanto con el programa SPSS como con MINITAB.