El aprendizaje no supervisado es una rama del aprendizaje automático (Machine Learning) que se centra en analizar y estructurar datos sin etiquetas ni categorías predefinidas. A diferencia del aprendizaje supervisado, en el que los modelos se entrenan con datos etiquetados, en el aprendizaje no supervisado los algoritmos deben identificar de manera autónoma patrones, relaciones o estructuras ocultas dentro de los datos. Se trata de una herramienta poderosa para explorar y entender datos complejos sin la necesidad de etiquetas predefinidas, descubriendo patrones y estructuras ocultas que pueden ser de gran valor en diversas aplicaciones prácticas.
El aprendizaje no supervisado es una rama del aprendizaje automático (Machine Learning) que se centra en analizar y estructurar datos sin etiquetas ni categorías predefinidas. A diferencia del aprendizaje supervisado, en el que los modelos se entrenan con datos etiquetados, en el aprendizaje no supervisado los algoritmos deben identificar de manera autónoma patrones, relaciones o estructuras ocultas dentro de los datos. Se trata de una herramienta poderosa para explorar y entender datos complejos sin la necesidad de etiquetas predefinidas, descubriendo patrones y estructuras ocultas que pueden ser de gran valor en diversas aplicaciones prácticas.
El aprendizaje no supervisado permite analizar datos sin un objetivo definido o sin conocimiento previo de su estructura. Este enfoque es ideal para explorar patrones latentes y reducir la dimensionalidad de grandes conjuntos de datos, lo que facilita una mejor comprensión de su estructura. Además, al no depender de etiquetas previamente asignadas, permite adaptarse de manera flexible a diversos tipos de datos, incluidos aquellos cuya estructura subyacente no es evidente. Esta característica lo hace especialmente valioso en ámbitos como la exploración científica y el análisis de datos de mercado, donde los datos pueden ser abundantes, pero carecer de categorías predefinidas.
A pesar de sus ventajas, el aprendizaje no supervisado plantea desafíos como la interpretación de los resultados, ya que sin etiquetas predefinidas puede ser difícil evaluar la precisión de los modelos. Además, la elección del número óptimo de grupos o la validación de las reglas de asociación descubiertas puede requerir la intervención de expertos y métodos adicionales de validación.
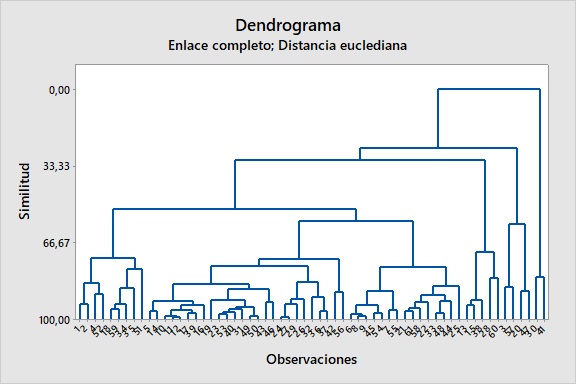
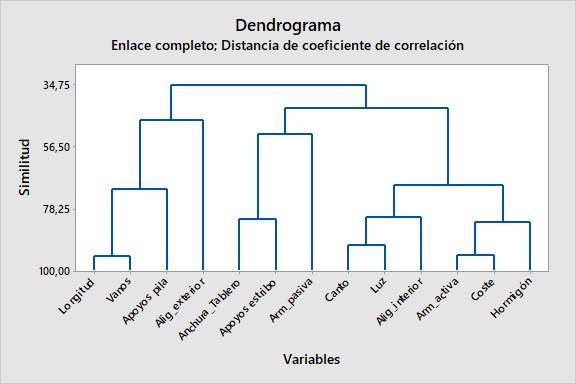
El aprendizaje no supervisado incluye diversas técnicas que permiten analizar y extraer patrones de grandes conjuntos de datos sin necesidad de etiquetas. Una de las principales técnicas es el agrupamiento (clustering), que busca dividir los datos en grupos basados en similitudes inherentes. Existen dos tipos de algoritmos de agrupamiento: el agrupamiento duro, que asigna un dato a un único grupo, y el agrupamiento suave, que permite que un dato pertenezca a varios grupos con diferentes grados de pertenencia. Técnicas como k-means y k-medoids se utilizan mucho en este contexto. Mientras que k-means busca minimizar la distancia entre los datos y los centros de los grupos, k-medoids es más robusto frente a valores atípicos y adecuado para datos categóricos. Por otro lado, el agrupamiento jerárquico genera un dendrograma que permite explorar relaciones jerárquicas en los datos. Los mapas autoorganizados, que emplean redes neuronales, se utilizan para reducir la dimensionalidad de los datos sin perder su estructura y facilitar su interpretación en campos como la bioinformática y la economía.
En situaciones donde los datos tienen relaciones difusas, el agrupamiento suave, como el fuzzy c-means, asigna grados de pertenencia a cada dato, lo que resulta útil en áreas como la biomedicina. Los modelos de mezcla gaussiana, que utilizan distribuciones normales multivariadas, también se aplican a problemas complejos como la segmentación de mercado o la detección de anomalías. Además, el aprendizaje no supervisado incluye técnicas de asociación que buscan descubrir relaciones entre variables en grandes bases de datos, como el análisis de la cesta de la compra, donde se identifican productos que suelen comprarse juntos. También se utilizan técnicas de reducción de la dimensionalidad, que simplifican los datos de alta dimensionalidad sin perder mucha variabilidad. El análisis de componentes principales (PCA) es una técnica común en este ámbito, ya que transforma los datos en combinaciones lineales que facilitan su visualización y análisis, especialmente en casos de datos ruidosos, como los procedentes de sensores industriales o dispositivos médicos. Otras técnicas, como el análisis factorial y la factorización matricial no negativa, también se utilizan para reducir la complejidad de los datos y hacerlos más manejables, y son útiles en áreas como la bioinformática, el procesamiento de imágenes y el análisis de textos.

El aprendizaje no supervisado tiene diversas aplicaciones, como el análisis de clientes, que permite identificar segmentos con características o comportamientos similares, lo que optimiza las estrategias de marketing y la personalización de los servicios. También se utiliza en la detección de anomalías, ya que ayuda a identificar datos atípicos que pueden indicar fraudes, fallos en los sistemas o comportamientos inusuales en áreas industriales y financieras; en este campo, el análisis factorial revela dinámicas compartidas entre sectores económicos, lo que mejora la predicción de tendencias de mercado. En el procesamiento de imágenes, facilita tareas como la segmentación, que consiste en agrupar píxeles con características similares para identificar objetos o regiones dentro de una imagen. Además, en el análisis de textos, técnicas como la factorización matricial no negativa permiten descubrir temas latentes en grandes colecciones de documentos, mejorando los sistemas de recomendación y el análisis de sentimientos. En la investigación genómica, el clustering suave ha permitido identificar genes implicados en el desarrollo de enfermedades, lo que ha contribuido a avanzar en la medicina personalizada. Esta capacidad para analizar patrones complejos en datos biológicos ha acelerado el descubrimiento de biomarcadores y posibles dianas terapéuticas. Este enfoque también permite identificar correlaciones entre variables macroeconómicas que de otra manera podrían pasar desapercibidas. Por otro lado, el PCA se ha aplicado con éxito en la monitorización de sistemas industriales, ya que permite predecir fallos y reducir costes operativos mediante el análisis de variaciones en múltiples sensores. En el ámbito de la minería de textos, la factorización no negativa permite descubrir temas latentes, lo que mejora los sistemas de recomendación y análisis de sentimiento. Esto resulta particularmente valioso en aplicaciones de marketing digital, donde la segmentación precisa del contenido puede aumentar la eficacia de las campañas.

El aprendizaje no supervisado ha encontrado diversas aplicaciones en el ámbito de la ingeniería civil, ya que permite optimizar procesos y mejorar la toma de decisiones. A continuación, se destacan algunas de ellas:
- Clasificación de suelos y materiales de construcción: Mediante técnicas de agrupación (clustering), es posible agrupar muestras de suelo o materiales de construcción según sus propiedades físicas y mecánicas. Esto facilita la selección adecuada de materiales para proyectos específicos y optimiza el diseño de cimentaciones y estructuras.
- Análisis de patrones de tráfico: El aprendizaje automático permite identificar patrones en los flujos de tráfico, detectando comportamientos anómalos o recurrentes. Esta información es esencial para diseñar infraestructuras viales más eficientes y aplicar medidas de control de tráfico.
- Monitorización de estructuras: Mediante la reducción dimensional y el análisis de datos procedentes de sensores instalados en puentes, edificios y otras infraestructuras, se pueden detectar anomalías o cambios en el comportamiento estructural. Esto contribuye a la prevención de fallos y al mantenimiento predictivo.
- Optimización de rutas para maquinaria pesada: En proyectos de construcción a gran escala, el aprendizaje no supervisado ayuda a determinar las rutas más eficientes para la maquinaria, considerando factores como el terreno, el consumo de combustible y la seguridad, lo que se traduce en una mayor productividad y reducción de costes.
- Segmentación de imágenes por satélite y aéreas: Las técnicas de aprendizaje no supervisado permiten clasificar y segmentar imágenes obtenidas de satélites o drones, identificando áreas urbanas, vegetación, cuerpos de agua y otros elementos. Esto es útil para la planificación urbana y la gestión de recursos naturales.
- Análisis de datos de sensores en tiempo real: En la construcción de túneles y excavaciones, el análisis en tiempo real de datos de sensores puede realizarse mediante algoritmos no supervisados para detectar condiciones peligrosas, como deslizamientos de tierra o acumulación de gases, lo que mejora la seguridad en las obras.

En conclusión, el aprendizaje no supervisado es una herramienta versátil y potente para abordar problemas complejos y descubrir patrones ocultos en datos sin etiquetar. Su aplicación trasciende sectores, ya que ofrece soluciones prácticas para la investigación, la industria y el análisis de datos. En un mundo impulsado por el crecimiento exponencial de la información, el dominio de estas técnicas se presenta como una ventaja competitiva fundamental. La capacidad para analizar grandes volúmenes de datos y extraer información útil sigue siendo un motor clave de innovación y progreso.
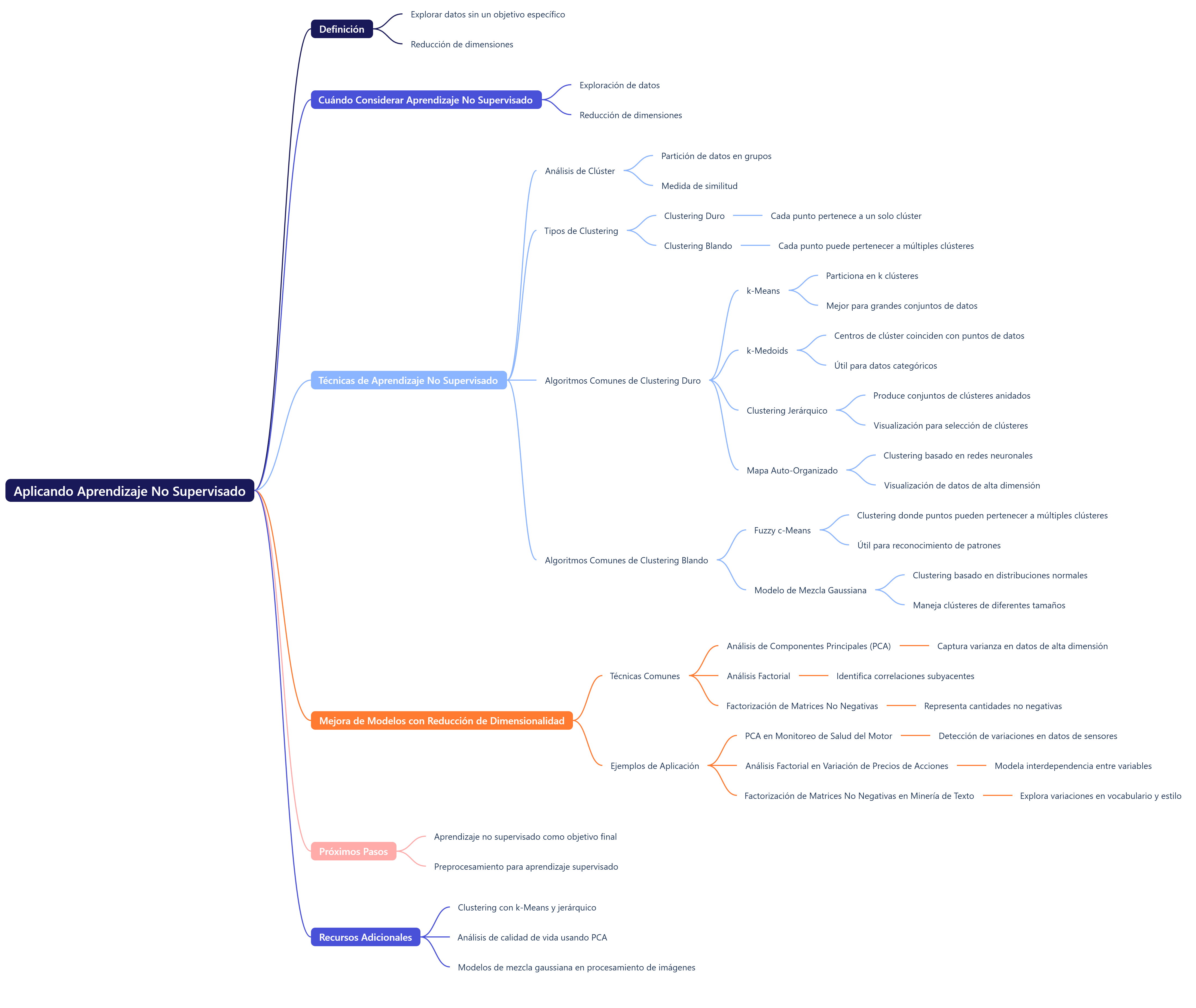
Os dejo un mapa mental acerca del aprendizaje no supervisado.
Para profundizar en este tema, puedes consultar la siguiente conferencia:
Referencia:
GARCÍA, J.; VILLAVICENCIO, G.; ALTIMIRAS, F.; CRAWFORD, B.; SOTO, R.; MINTATOGAWA, V.; FRANCO, M.; MARTÍNEZ-MUÑOZ, D.; YEPES, V. (2022). Machine learning techniques applied to construction: A hybrid bibliometric analysis of advances and future directions. Automation in Construction, 142:104532. DOI:10.1016/j.autcon.2022.104532

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.