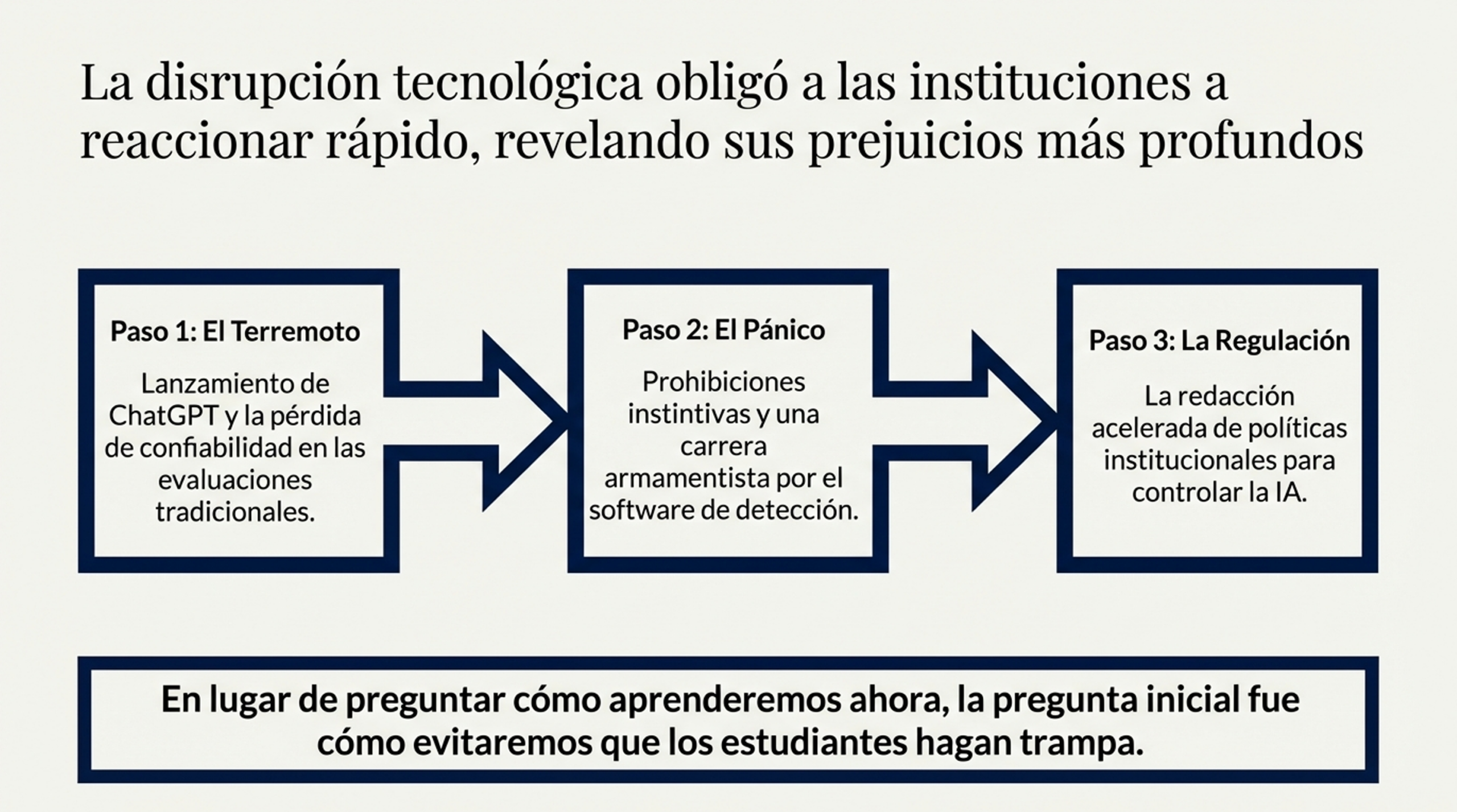
La irrupción de la inteligencia artificial generativa (GenAI) ha hecho saltar por los aires el «contrato de confianza» que sustentaba la evaluación académica. Lo que antes era un acuerdo implícito —que el estudiante era el único autor de cada palabra— hoy se ha transformado en una arquitectura de la sospecha. Pero ¿qué sucede cuando examinamos en profundidad esta crisis?
La irrupción de la inteligencia artificial generativa (GenAI) ha hecho saltar por los aires el «contrato de confianza» que sustentaba la evaluación académica. Lo que antes era un acuerdo implícito —que el estudiante era el único autor de cada palabra— hoy se ha transformado en una arquitectura de la sospecha. Pero ¿qué sucede cuando examinamos en profundidad esta crisis?
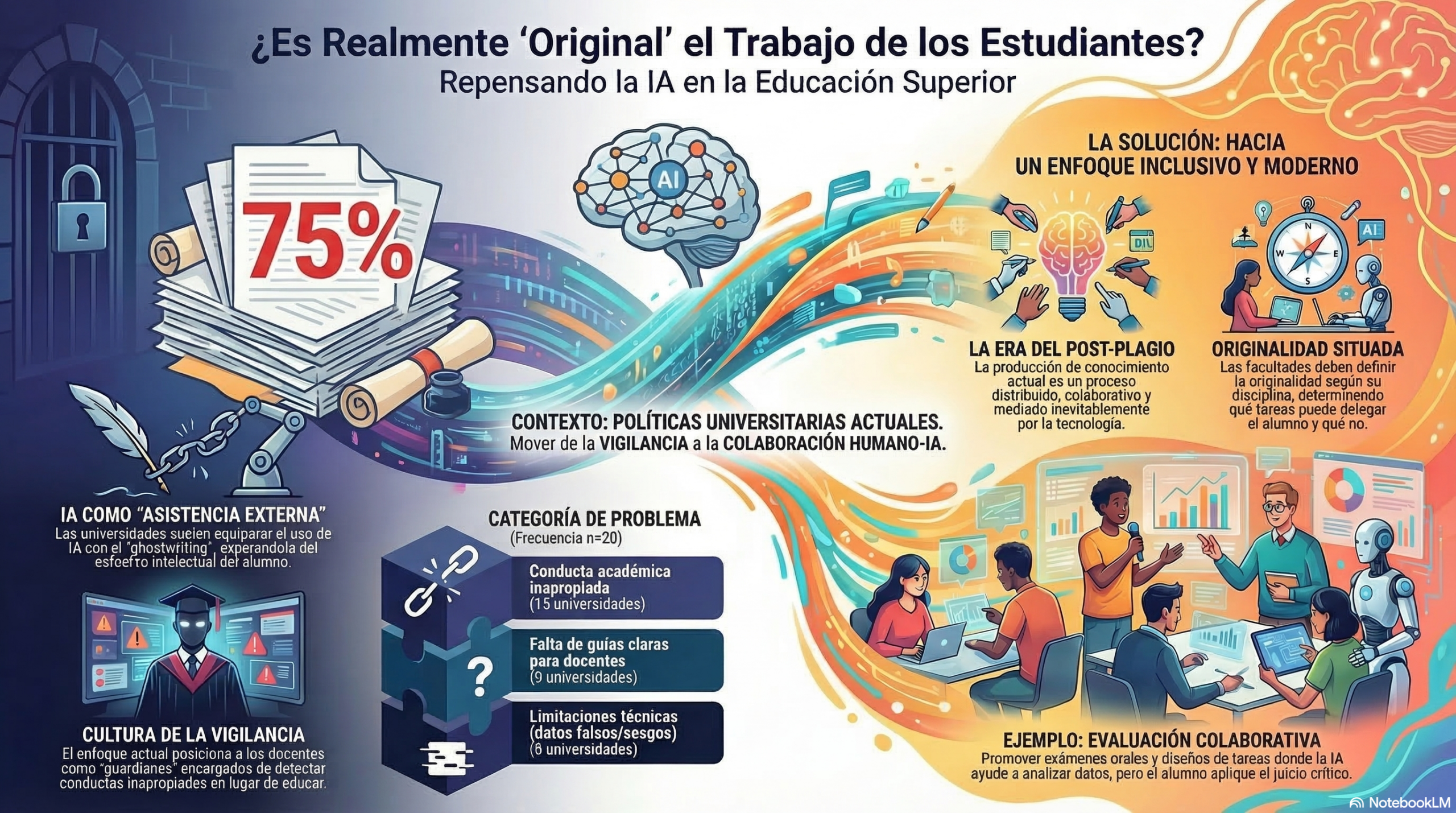
Un estudio en profundidad de las políticas de las veinte mejores universidades del mundo revela que no se trata solo de ajustar las normas, sino de una lucha desesperada por rescatar una noción de autoría que quizá ya no existe (Luo, 2024).
Como profesor universitario, observo con preocupación cómo la academia no reacciona con pedagogía, sino con una vigilancia que fosiliza el aprendizaje. A continuación, presento cinco revelaciones críticas sobre cómo la universidad está gestionando —o malinterpretando— este cambio de era.
1. La «originalidad» como mecanismo de vigilancia (Marco WPR).
En el marco analítico de Carol Bacchi, What’s the problem represented to be (WPR), descubrimos que las universidades no solo responden a un problema, sino que también lo están creando. Al analizar las políticas de las instituciones de élite, el estudio de Jiahui Luo revela que el «problema» se ha representado casi exclusivamente como la pérdida de la autoría original.
Esta visión se aferra al mito del «genio solitario en el ático» (Johnson-Eilola y Selber), esa idea romántica y obsoleta que sostiene que el trabajo intelectual solo es valioso si se realiza en un vacío social y tecnológico. Al definir la IA como una «ayuda externa» prohibida, las universidades reducen la educación a un ejercicio de detección de fraude. Como señala una de las políticas analizadas:
«Los estudiantes deben ser autores de su propio trabajo. El contenido producido por plataformas de IA, como ChatGPT, no representa el trabajo original del estudiante, por lo que se consideraría una forma de mala conducta académica».
2. El error de la analogía del «escritor fantasma».
Algunas de las universidades analizadas por Luo (2024) han cometido un error fundamental de categoría: equiparan el uso de la IA generativa con el ghostwriting o con la ayuda de un tercero. Esta es una falla de imaginación tecnológica. La IA no es un agente externo, sino una prótesis cognitiva integrada en el flujo de pensamiento contemporáneo.
Tratar a una herramienta como si fuera una persona es ignorar la realidad digital del siglo XXI. El análisis de Luo muestra que las políticas universitarias suelen agrupar los problemas en seis categorías que revelan una mentalidad de «vigilancia primero».
- Mala conducta académica: el pánico ante la entrega de trabajos ajenos.
- Diseño de evaluación: la urgencia de crear tareas que la IA no pueda «resolver».
- Limitaciones tecnológicas: desconfianza en la veracidad de los datos.
- Equidad: el riesgo de que se creen brechas entre quienes pueden permitirse una IA avanzada y quienes no.
- Políticas y directrices: la falta de claridad por parte de los docentes.
- Capacitación y apoyo: la necesidad de una alfabetización urgente.

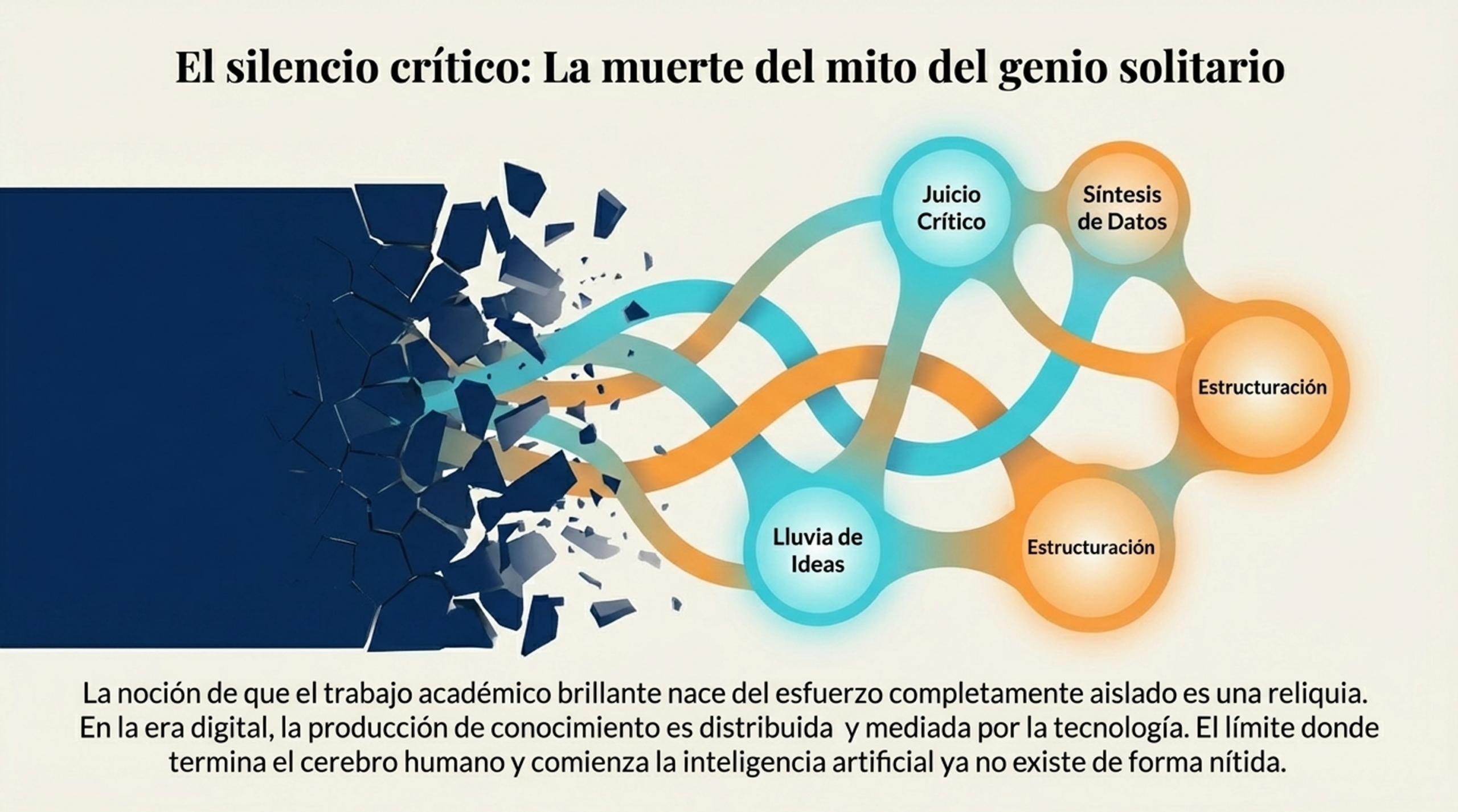
3. El silencio crítico y la «era del posplagio».
Lo más inquietante de estas políticas es lo que callan. Existe un «silencio crítico» sobre el significado de la originalidad en la actualidad. Estamos entrando de lleno en lo que la investigadora Sarah Eaton denomina la era del posplagio. En este nuevo paradigma, la frontera entre lo humano y lo artificial no solo es difusa, sino también irrelevante.
El conocimiento actual es, por naturaleza, distribuido y colaborativo. Al ignorar la evolución del concepto de originalidad, las universidades se desconectan de la realidad. Si el contenido de la IA es «remezclado y reelaborado» por un ser humano, ¿dónde termina la máquina y dónde empieza el autor? Mantener la exigencia de una autoría analógica en un mundo de inteligencia híbrida es una receta para la irrelevancia académica.
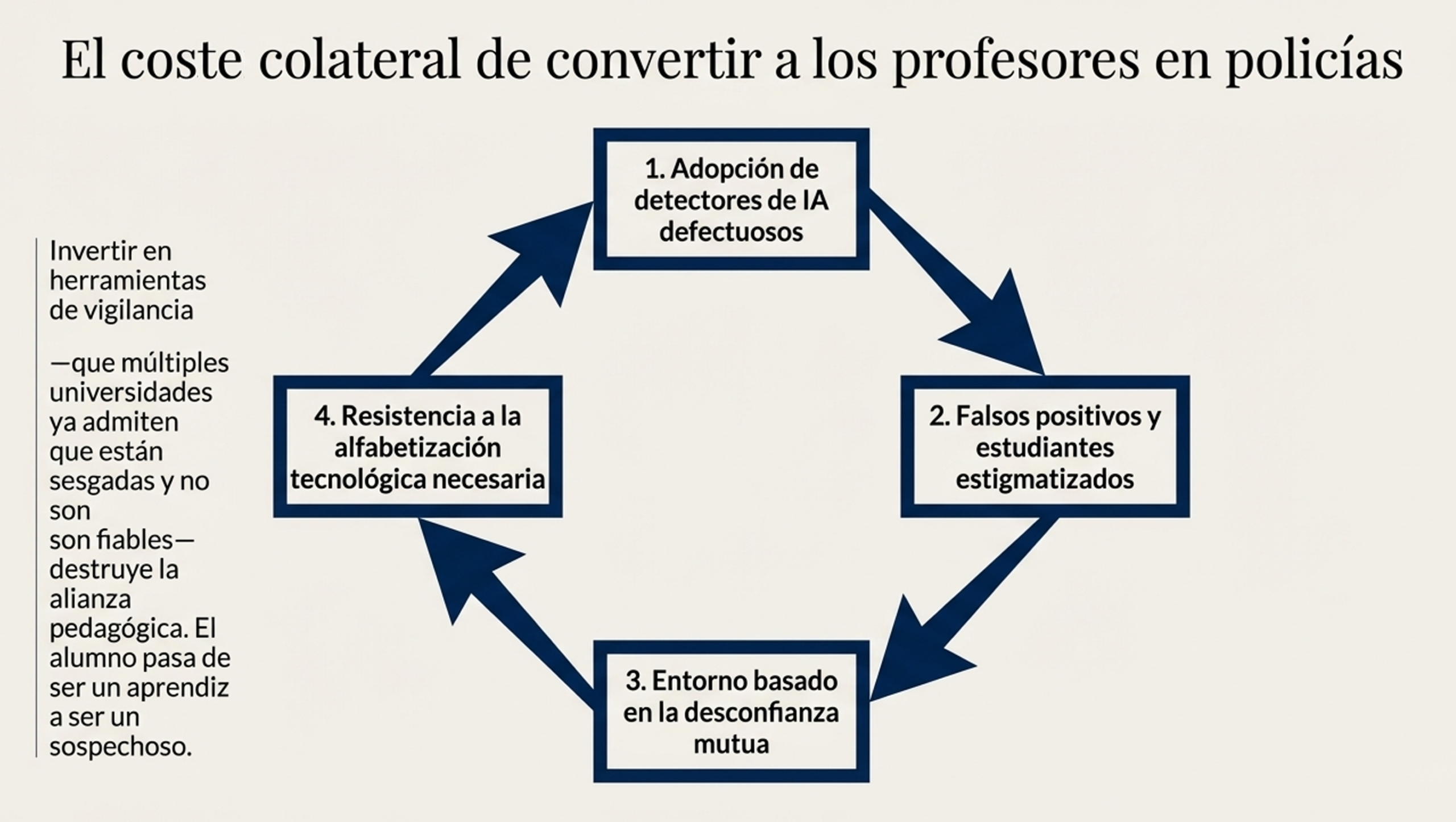
4. El efecto secundario: de docentes a policías.
Siguiendo el análisis de los efectos de las políticas (pregunta 5 del marco WPR), se observa una erosión pedagógica alarmante. Los profesores están siendo desplazados de su papel de mentores para convertirse en «guardianes» o vigilantes de la frontera.
Este enfoque de patrullaje tiene consecuencias reales: los estudiantes son tratados como sospechosos desde el principio. Esto genera una cultura de desconfianza en la que el alumno se vuelve reacio al uso legítimo de las herramientas tecnológicas por miedo a la estigmatización. Si el sistema está diseñado para «atrapar» al infractor en lugar de implicar al alumno, la relación pedagógica muere.
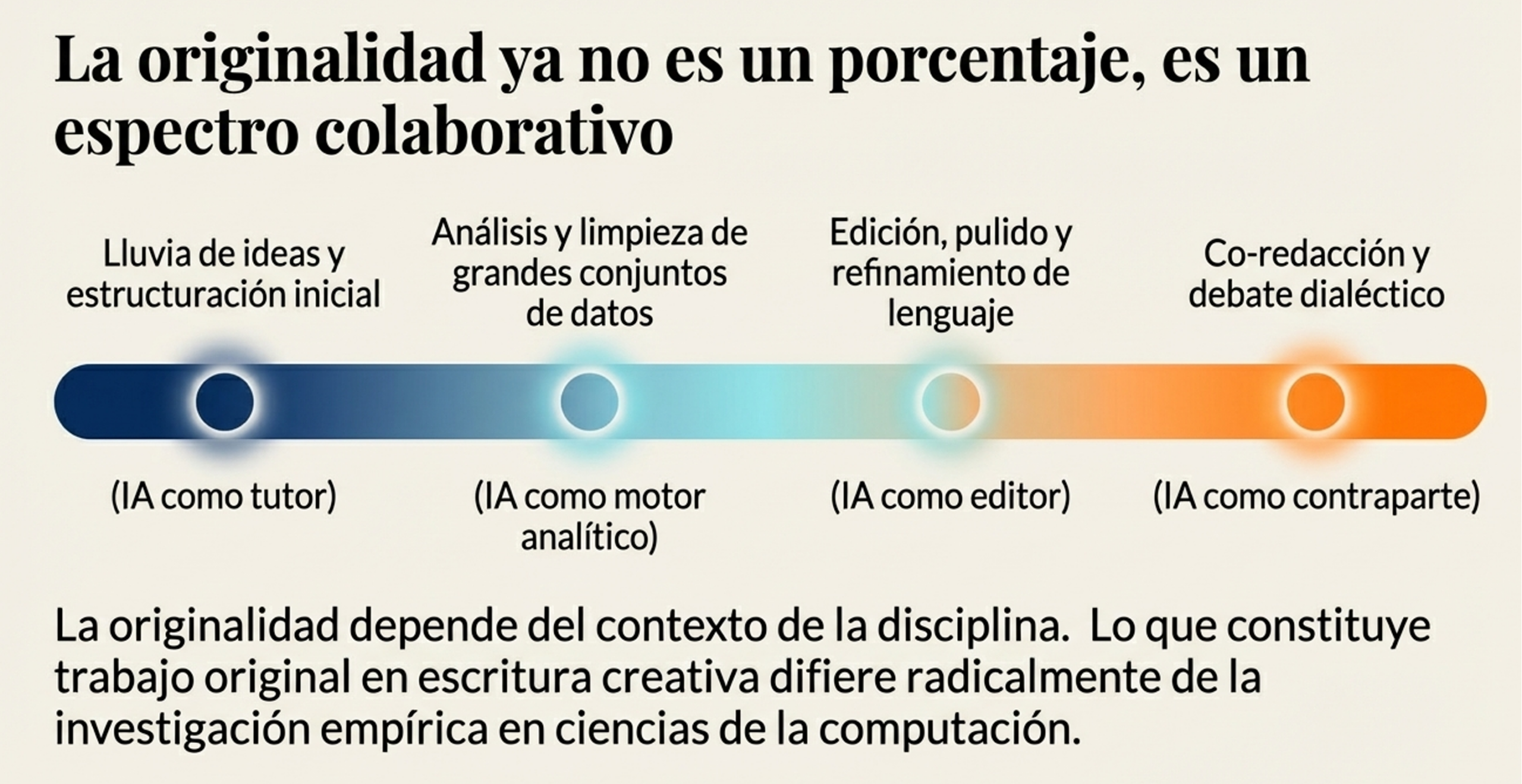
5. Hacia la originalidad como espectro y juicio evaluativo.
Debemos desmantelar la dicotomía «humano vs. IA». La propuesta de vanguardia, respaldada por autores como Luo y Chan (2023), consiste en entender la originalidad como un espectro de colaboración. La clave ya no es la producción solitaria de textos, sino el juicio evaluativo: la capacidad del estudiante para criticar, refinar y dar sentido a la información, ya sea de cualquier origen.
Es hora de aceptar una verdad incómoda que las políticas evitan mencionar:
«Podría decirse que los humanos hacemos lo mismo que la IA cuando generamos un texto original: escribimos basándonos en asociaciones que provienen de lo que hemos oído o leído antes de otros humanos».
Para avanzar, necesitamos evaluaciones auténticas, como defensas orales y la transparencia en los procesos, que valoren el pensamiento crítico por encima del producto final.
Conclusión: una pregunta para el futuro.
La universidad se encuentra en una encrucijada: puede evolucionar y liderar la alfabetización en IA o quedarse anclada en el pasado como un tribunal de autoría obsoleto. No podemos seguir exigiendo una originalidad de «genio solitario» en un mundo donde la inteligencia se comparte con las máquinas.
¿Estamos dispuestos a rediseñar la confianza o seguiremos educando a los estudiantes para que finjan una autoría analógica que ya no existe?

En esta conversación puedes escuchar las ideas más interesantes sobre el tema.
Este vídeo resume bien los contenidos de este artículo.
Redefining_Academic_Originality
Referencias:
Bacchi C. Introducing the ‘What’s the Problem Represented to be?’ approach. In: Bletsas A, Beasley C, eds. Engaging with Carol Bacchi: Strategic Interventions and Exchanges. The University of Adelaide Press; 2012:21-24.
Johnson-Eilola, J., & Selber, S. A. (2007). Plagiarism, originality, assemblage. Computers and composition, 24(4), 375-403.
Luo (Jess), J. (2024). A critical review of GenAI policies in higher education assessment: a call to reconsider the “originality” of students’ work. Assessment & Evaluation in Higher Education, 49(5), 651–664. https://doi.org/10.1080/02602938.2024.2309963

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.