La Universitat Politècnica de València (UPV) ha obtenido un reconocimiento destacado europeo al ganar el premio al mejor proyecto en la categoría «AI for Sustainable Development» de la European Universities Competition on Artificial Intelligence, organizada por la HAW Hamburg.
La Universitat Politècnica de València (UPV) ha obtenido un reconocimiento destacado europeo al ganar el premio al mejor proyecto en la categoría «AI for Sustainable Development» de la European Universities Competition on Artificial Intelligence, organizada por la HAW Hamburg.
El trabajo galardonado, desarrollado en el ICITECH por el doctorando Iván Negrín, demuestra cómo la inteligencia artificial puede transformar el diseño estructural para hacerlo más sostenible y resiliente, con reducciones de hasta un 32 % en la huella de carbono respecto a los sistemas convencionales. Este logro posiciona a la UPV como un referente europeo en innovación ética e impacto y reafirma su compromiso con la búsqueda de soluciones frente al cambio climático y al desarrollo insostenible.
El trabajo se enmarca en el proyecto de investigación RESILIFE, que dirijo como investigador principal en la Universitat Politècnica de València. La tesis doctoral de Iván la dirigen los profesores Víctor Yepes y Moacir Kripka.

Introducción: El dilema de la construcción moderna.
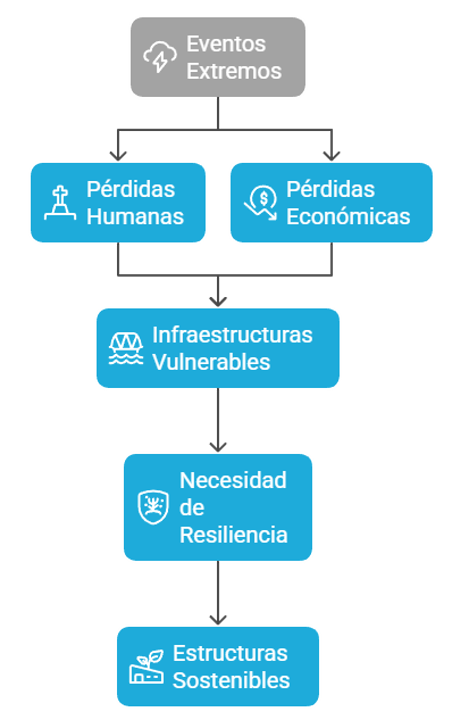
La industria de la construcción se enfrenta a un reto monumental: edificar las ciudades del futuro sin agotar los recursos del presente. El enorme impacto medioambiental de los materiales y procesos tradicionales, especialmente las emisiones de CO₂, es uno de los problemas más acuciantes de nuestra era.
¿Y si la solución a este problema no radicara en un nuevo material milagroso, sino en una nueva forma de pensar? ¿Y si la inteligencia artificial (IA) pudiera enseñarnos a construir de manera mucho más eficiente y segura?
Esa es precisamente la hazaña que ha logrado un innovador proyecto de la Universitat Politècnica de València (UPV). Su enfoque es tan revolucionario que acaba de ganar un prestigioso premio europeo, lo que demuestra que la IA ya no es una promesa, sino una herramienta tangible para la ingeniería sostenible.

Clave 1: una innovación europea premiada al más alto nivel.
Este no es un proyecto académico cualquiera. La investigación, dirigida por el doctorando Iván Negrín del Instituto de Ciencia y Tecnología del Hormigón (ICITECH) de la UPV, ha recibido el máximo reconocimiento continental.
Inicialmente seleccionado como uno de los diez finalistas, el proyecto tuvo que defenderse en una presentación final ante un jurado de expertos. Tras la deliberación del jurado, el proyecto fue galardonado como el mejor en la categoría «AI for Sustainable Development Projects» de la competición «European Universities Competition on Artificial Intelligence to Promote Sustainable Development and Address Climate Change», organizada por la Universidad de Ciencias Aplicadas de Hamburgo (HAW Hamburg). Este reconocimiento consolida la reputación del proyecto en el ámbito de la innovación europea.
Clave 2: adiós al CO₂: reduce la huella de carbono en más del 30 %.
El resultado más impactante de esta investigación es su capacidad para abordar el principal problema medioambiental del sector de la construcción: las emisiones de carbono. La plataforma de diseño asistido por IA puede reducir la huella de carbono de los edificios de manera significativa.
En concreto, consigue una reducción del 32 % de la huella de carbono en comparación con los sistemas convencionales de hormigón armado, que ya habían sido optimizados. Esta reducción abarca todo el ciclo de vida del edificio, desde la extracción de materiales y la construcción hasta su mantenimiento y su eventual demolición.
En un sector tan difícil de descarbonizar, un avance de esta magnitud, impulsado por un diseño inteligente y no por un nuevo material, supone un cambio de paradigma fundamental para la ingeniería sostenible.
Clave 3: Rompe el mito: más sostenible no significa menos resistente.
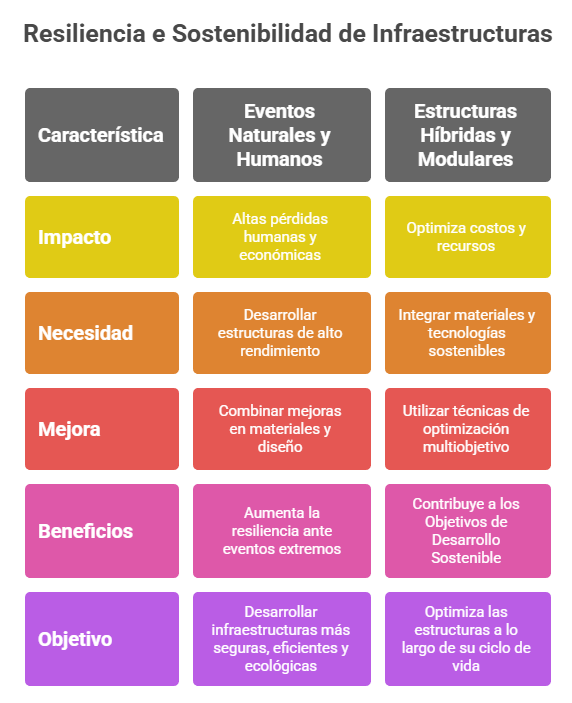
Uno de los aspectos más revolucionarios del proyecto es la forma en que resuelve un conflicto histórico en ingeniería: la sostenibilidad frente a la resiliencia. La IA ha superado la barrera que obligaba a elegir entre usar menos material para ser sostenible o más material para ser resistente.
En una primera fase, el modelo optimizó estructuras mixtas de acero y hormigón (denominadas técnicamente RC-THVS) para que fueran altamente sostenibles, aunque con una resiliencia baja. Lejos de detenerse, la IA iteró sobre su propio diseño y, en una evolución posterior (RC-THVS-R), logró una solución altamente sostenible y resiliente frente a eventos extremos.
La metodología desarrollada permite compatibilizar la sostenibilidad y la resiliencia, superando el tradicional conflicto entre ambos objetivos.
Clave 4: Ahorro desde los cimientos. Menos costes, energía y materiales.
Los beneficios de esta IA no solo benefician al planeta, sino también al bolsillo y a la eficiencia del proyecto. La optimización inteligente de las estructuras se traduce en ahorros tangibles y medibles desde las primeras fases de la construcción.
Los datos demuestran un ahorro significativo en múltiples frentes:
- -16 % de energía incorporada.
- -6 % de coste económico.
- – Reducción del 17 % de las cargas transmitidas a columnas y cimentaciones.
Este último punto es clave. Una menor carga en los cimientos no solo supone un ahorro directo de materiales, sino que tiene un efecto cascada en materia de sostenibilidad: al usar menos hormigón, se reduce la cantidad de cemento empleado, uno de los principales generadores de CO₂ a nivel mundial.
Clave 5: un enfoque versátil para las ciudades del futuro (y del presente).
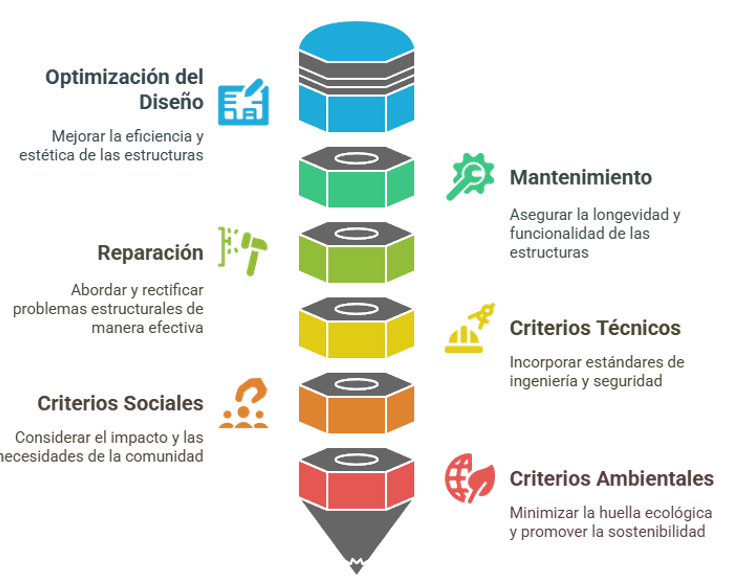
La aplicación de esta metodología no se limita a los grandes edificios de nueva construcción. Su versatilidad la convierte en una herramienta estratégica para el desarrollo urbano integral.
Puede aplicarse a infraestructuras de transporte, como puentes y pasarelas, para minimizar su impacto ambiental. También es fundamental para la rehabilitación de estructuras existentes, ya que permite optimizar su seguridad y reducir las emisiones asociadas a los refuerzos.
Este enfoque se alinea con los Objetivos de Desarrollo Sostenible (ODS) de la ONU, concretamente con los ODS 9 (Industria, innovación e infraestructura), 11 (Ciudades y comunidades sostenibles) y 13 (Acción por el clima).
Conclusión: construyendo un futuro inteligente.
Este proyecto de la UPV demuestra que la inteligencia artificial ha dejado de ser una tecnología futurista para convertirse en una herramienta imprescindible en la ingeniería civil. Ya no se trata de promesas, sino de soluciones prácticas que resuelven problemas reales, medibles y urgentes.
La capacidad de diseñar estructuras más baratas, ecológicas, seguras y resistentes abre un nuevo capítulo en la construcción.
¿Estamos a las puertas de una nueva era en la ingeniería en la que la sostenibilidad y la máxima seguridad ya no son objetivos contrapuestos, sino aliados inseparables gracias a la inteligencia artificial?
En futuros artículos, explicaremos con más detalle el contenido de este proyecto ganador. De momento, os dejo una conversación que lo explica muy bien y un vídeo que resume lo más importante. Espero que os resulte interesante.
Os dejo un documento resumen, por si queréis ampliar la información.
Referencias:
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2025). Environmental Life-Cycle Design Optimization of a RC-THVS composite frame for modern building construction. Engineering Structures, 345, 121461. DOI:10.1016/j.engstruct.2025.121461
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2025). Manufacturing cost optimization of welded steel plate I-girders integrating hybrid construction and tapered geometry. International Journal of Advanced Manufacturing Technology, 140, 1601-1624. DOI:10.1007/s00170-025-16365-2
NEGRÍN, I.; CHAGOYÉN, E.; KRIPKA, M.; YEPES, V. (2025). An integrated framework for Optimization-based Robust Design to Progressive Collapse of RC skeleton buildings incorporating Soil-Structure Interaction effects. Innovative Infrastructure Solutions, 10:446. DOI:10.1007/s41062-025-02243-z
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2025). Design optimization of a composite typology based on RC columns and THVS girders to reduce economic cost, emissions, and embodied energy of frame building construction. Energy and Buildings, 336:115607. DOI:10.1016/j.enbuild.2025.115607
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2025). Metamodel-assisted design optimization of robust-to-progressive-collapse RC frame buildings considering the impact of floor slabs, infill walls, and SSI implementation. Engineering Structures, 325:119487. DOI:10.1016/j.engstruct.2024.119487
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2024). Optimized Transverse-Longitudinal Hybrid Construction for Sustainable Design of Welded Steel Plate Girders. Advances in Civil Engineering, 2024:5561712. DOI:10.1155/2024/5561712.
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2023). Multi-criteria optimization for sustainability-based design of reinforced concrete frame buildings. Journal of Cleaner Production, 425:139115. DOI:10.1016/j.jclepro.2023.139115
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2023). Metamodel-assisted meta-heuristic design optimization of reinforced concrete frame structures considering soil-structure interaction. Engineering Structures, 293:116657. DOI:10.1016/j.engstruct.2023.116657
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2023). Design optimization of welded steel plate girders configured as a hybrid structure. Journal of Constructional Steel Research, 211:108131. DOI:10.1016/j.jcsr.2023.108131
TERREROS-BEDOYA, A.; NEGRÍN, I.; PAYÁ-ZAFORTEZA, I.; YEPES, V. (2023). Hybrid steel girders: review, advantages and new horizons in research and applications. Journal of Constructional Steel Research, 207:107976. DOI:10.1016/j.jcsr.2023.107976.
NEGRÍN, I.; KRIPKA, M.; YEPES, V. (2023). Metamodel-assisted design optimization in the field of structural engineering: a literature review. Structures, 52:609-631. DOI:10.1016/j.istruc.2023.04.006

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.