La unidad experimental (UE) es el elemento central en el diseño y el análisis de experimentos comparativos. Se define como la entidad a la que se le puede asignar un tratamiento de forma independiente y sobre la cual se realizan las mediciones. La identificación correcta de la UE es fundamental, ya que la estimación de la variabilidad natural, conocida como error experimental, depende exclusivamente de la comparación entre unidades experimentales idénticas que reciben el mismo tratamiento.
Una unidad experimental puede contener múltiples unidades muestrales, subelementos que reciben obligatoriamente el mismo tratamiento que la UE a la que pertenecen. Por esta razón, la variabilidad entre estas unidades muestrales internas no resulta útil para estimar el efecto del tratamiento. Un diseño experimental sólido se basa en la capacidad de distinguir los efectos reales de los tratamientos del «ruido» natural del sistema, una distinción que solo es posible mediante la correcta cuantificación de la variabilidad entre las unidades experimentales completas.
Definiciones fundamentales
El marco de un experimento se define a través de sus componentes básicos, en los que la unidad experimental y la unidad muestral desempeñan funciones distintas, aunque interconectadas.
1. La unidad experimental (UE)
La unidad experimental es el pilar de cualquier ensayo comparativo. Su definición formal es la siguiente:
«El elemento sobre el que se realizan las mediciones y al que se puede asignar un tratamiento de forma independiente».
El conjunto de todas las unidades experimentales disponibles para un estudio se denomina material experimental. La definición de una UE es flexible y se adapta a los objetivos de la investigación.
Ejemplos prácticos:
Ensayo de resistencia del hormigón: la unidad experimental puede ser un bloque o un cilindro de hormigón elaborado con una mezcla específica. Las unidades muestrales serían las probetas o las muestras extraídas del mismo bloque para realizar ensayos de compresión o de flexión.
Prueba de rendimiento de pavimentos: la unidad experimental puede ser un tramo de vía construido con un diseño o material específico (por ejemplo, un segmento de 50 metros). Las unidades muestrales serían los puntos de medición dentro del tramo, por ejemplo, las deflexiones o la rugosidad.
Ensayo de estructuras a escala en laboratorio: la unidad experimental puede ser una viga o una columna, construida según un diseño específico. Las unidades muestrales serían los puntos de medición (deformaciones, desplazamientos o tensiones) registrados por sensores a lo largo de la estructura.
El criterio esencial para definir una UE es que sea capaz de recibir diferentes tratamientos de manera independiente de las demás unidades.
2. La unidad muestral.
Dentro de una unidad experimental pueden existir subelementos en los que se aplican las condiciones experimentales. A estos se les conoce como unidades muestrales.
La regla fundamental que las rige es que todas las unidades muestrales de una misma unidad experimental deben recibir el mismo tratamiento. Como consecuencia directa, la asignación del tratamiento a estas subunidades no es independiente entre sí, lo que tiene implicaciones críticas para el análisis estadístico.
El papel de la estimación en la variabilidad.
La distinción entre unidades experimentales y muestrales es crucial para inferir correctamente los efectos de un tratamiento, ya que incide directamente en la medición de la variabilidad del sistema.
a. El error experimental
Para evaluar si un tratamiento tiene un efecto real, es necesario conocer la variabilidad natural del material experimental. Esta variabilidad inherente se conoce como error experimental. Es la base contra la que se comparan las diferencias observadas entre los tratamientos.
b. Metodología de estimación
La estimación correcta del error experimental solo se logra a partir de las diferencias observadas entre unidades experimentales que, en principio, son idénticas y han recibido el mismo tratamiento.
Fuente de estimación válida: la variación entre unidades experimentales es la única que permite estimar correctamente el error experimental.
Fuente de estimación no válida: la variación entre las unidades muestrales dentro de una misma unidad experimental es, por lo general, muy pequeña y no proporciona información útil para estimar el efecto del tratamiento ni el error experimental.
La observación clave es que «solo la unidad experimental completa permite estimar correctamente el error experimental».
Tipología de variables en un experimento.
Los datos recopilados en un experimento se organizan en dos categorías principales de variables:
Tipo de variable
Descripción
Variables de respuesta
Son las mediciones obtenidas de las unidades experimentales. Sus valores reflejan tanto los efectos de los tratamientos como la variabilidad natural del sistema.
Variables explicativas (factores)
Son las variables que se manipulan o controlan porque se cree que influyen en las variables de respuesta. Incluyen los factores de clasificación, que definen los niveles o categorías sobre los cuales se realizan las inferencias estadísticas.
Conclusión: el fundamento de un diseño sólido.
La estructura de un diseño experimental robusto se basa en comparar unidades experimentales similares. Este enfoque permite a los investigadores distinguir de manera fiable el efecto real de los tratamientos aplicados del «ruido» o de la variabilidad natural inherente al sistema experimental. Por tanto, la identificación precisa y la gestión adecuada de la unidad experimental no son meros detalles técnicos, sino requisitos indispensables para que las conclusiones científicas derivadas del experimento sean válidas y fiables.
En este documento tenéis un resumen de las ideas más importantes.
Base del Citigroup Center junto a la Iglesia de San Pedro, lo que obligó a una disposición inusual de las columnas. https://es.wikipedia.org/wiki/Citigroup_Center
Introducción: El gigante con pies de barro.
Los rascacielos son monumentos a la permanencia. Se elevan sobre nuestras ciudades como símbolos de ingenio, poder y estabilidad estructural. Sin embargo, en 1978, el Citigroup Center, uno de los edificios más innovadores y reconocibles de Nueva York, ocultaba un secreto aterrador. Inaugurado con gran fanfarria en 1977, este hito de la ingeniería estaba, de hecho, peligrosamente cerca del colapso.
La ironía central de esta historia es casi cinematográfica: el fallo catastrófico se descubrió gracias a la pregunta de una estudiante universitaria, y la persona que cometió el error de cálculo que puso en peligro a miles de personas fue la misma que se convirtió en el héroe que los salvó. Esta es la historia de cómo una combinación de error humano, ética profesional y una suerte increíble evitó uno de los mayores desastres arquitectónicos de la historia moderna.
1. No bastó con un solo error; se necesitaron dos para poner en jaque al gigante.
El fallo que puso en jaque al Citigroup Center no fue un simple descuido, sino la combinación de dos errores críticos que se multiplicaron entre sí.
El primero fue un error de cálculo cometido por William LeMessurier, el ingeniero jefe. Siguiendo el código de construcción de la época, calculó las cargas de viento que incidían perpendicularmente en las caras del edificio. Sin embargo, debido al diseño único de la torre, que estaba apoyada sobre cuatro enormes pilares situados en el centro de cada lado en lugar de en las esquinas, pasó por alto que los vientos diagonales (conocidos como quartering winds) ejercían una tensión mucho mayor. Este descuido incrementó la carga en las uniones estructurales clave en un 40 %.
El segundo error agravó fatalmente el primero. Durante la construcción, la empresa constructora Bethlehem Steel propuso sustituir las uniones soldadas, que eran más resistentes pero también más costosas, por uniones atornilladas, más económicas. Basándose en los cálculos originales de vientos perpendiculares, este cambio parecía una modificación rutinaria y segura, por lo que la oficina de LeMessurier lo aprobó sin que él revisara personalmente las implicaciones. En aquel momento, fue una decisión técnicamente sólida, pero con el paso del tiempo se consideró fatal.
La combinación de un error oculto y una decisión que parecía segura resultó devastadora. La carga adicional del 40 % de los vientos diagonales aplicada a las uniones atornilladas más débiles provocó un aumento catastrófico del 160 % en la tensión de las conexiones. Esto significaba que una tormenta que ocurre cada 55 años podría ser desastrosa. Sin embargo, el peligro real era aún mayor: si el amortiguador de masa sintonizado del edificio, que dependía de la electricidad, fallaba durante un apagón —algo muy probable durante un huracán—, una tormenta mucho más común, de las que golpean Nueva York cada dieciséis años, podría derribarlo.
2. El «héroe» de la historia fue el ingeniero que cometió el error.
Tras descubrir el fallo, William LeMessurier se enfrentó a un dilema ético devastador. Años después, relataría que consideró todas las opciones, desde guardar silencio y arriesgar miles de vidas hasta el suicidio para escapar de la desgracia profesional.
Sin embargo, LeMessurier tomó la decisión más honorable: asumir toda la responsabilidad. Consciente de que esto podría significar el fin de su carrera, la bancarrota y la humillación pública, se puso en contacto con los directivos de Citicorp para informarles de que su flamante rascacielos de 175 millones de dólares era fundamentalmente inseguro. En ese momento, su mentalidad no se limitaba al deber, sino que también reflejaba un profundo sentido de su posición única, como él mismo describió:
«Tenía información que nadie más en el mundo poseía. Tenía en mis manos el poder de influir en eventos extraordinarios que solo yo podía iniciar».
Para su sorpresa, la reacción de los ejecutivos de Citicorp, liderados por el presidente Walter Wriston, no fue de ira, sino de una calma pragmática. En lugar de buscar culpables, Wriston se centró de inmediato en la solución. Pidió un bloc de notas amarillo, empezó a redactar un comunicado de prensa y bromeó: «Todas las guerras se ganan con generales que escriben en blocs amarillos». Este gesto de liderazgo, enfocado y sereno, sentó las bases para la increíble operación de rescate que estaba a punto de comenzar.
El Citigoup Center. https://es.wikipedia.org/wiki/Citigroup_Center
3. Una llamada casual de una estudiante lo desencadenó todo.
Toda esta crisis existencial y de ingeniería se desencadenó en junio de 1978 por un hecho tan improbable como una simple llamada telefónica. Al otro lado de la línea estaba Diane Hartley, una estudiante de ingeniería de la Universidad de Princeton que analizaba la estructura del Citigroup Center para su tesis.
Hartley llamó a LeMessurier con preguntas sobre la estabilidad del edificio frente a vientos diagonales. Confiado en su diseño, LeMessurier le explicó pacientemente por qué la estructura era sólida. Sin embargo, la llamada de Hartley sembró una semilla. No porque tuviera una preocupación inmediata, sino porque la conversación lo inspiró, LeMessurier decidió que el tema sería un excelente ejercicio académico para la conferencia que preparaba para sus propios estudiantes de Harvard.
Fue durante este recálculo, realizado por pura curiosidad intelectual, cuando descubrió con horror su error original. La llamada casual de Hartley no le dio la respuesta, pero le hizo la pregunta correcta en el momento adecuado, lo que supuso el golpe de suerte que reveló una vulnerabilidad mortal y activó la carrera contrarreloj para evitar una catástrofe inimaginable.
4. Una operación secreta, un huracán y una huelga de prensa lo mantuvieron en secreto.
La reparación del Citigroup Center fue una operación clandestina de alta tensión. Bajo el nombre en clave «Proyecto SERENE», los equipos trabajaban con una precisión coreografiada. Cada noche, los carpinteros llegaban a las 17:00 h para construir recintos de madera contrachapada alrededor de las juntas que había que reparar. Entre las 20:00 y las 04:00, con el sistema de alarma contra incendios desactivado, los soldadores trabajaban para reforzar más de doscientas uniones atornilladas con placas de acero de dos pulgadas de espesor. Finalmente, un equipo de limpieza eliminaba todo rastro del trabajo antes de la llegada de los primeros empleados a las 8 a. m., ajenos al peligro que se cernía sobre ellos.
El drama alcanzó su punto álgido a principios de septiembre de 1978, cuando el huracán Ella, una tormenta muy intensa, se dirigía directamente hacia la ciudad de Nueva York. Con las reparaciones a medio terminar, el edificio seguía siendo vulnerable. En secreto, las autoridades elaboraron planes para evacuar la torre y una zona de diez manzanas a su alrededor.
Entonces, la suerte intervino de nuevo. A pocas horas de la posible catástrofe, el huracán Ella viró inesperadamente hacia el Atlántico, salvando a la ciudad. El suspiro de alivio fue inmenso. Y, como si esto no fuera suficiente, un último golpe de fortuna mantuvo todo en secreto: justo cuando la historia estaba a punto de filtrarse, comenzó una huelga de periódicos en toda la ciudad que duró varios meses. La huelga enterró la noticia por completo y el casi desastre permaneció oculto al público durante casi veinte años, hasta que fue revelado en un artículo de The New Yorker en 1995.
Conclusión: la delgada línea entre el desastre y la ética.
La historia del Citigroup Center es un poderoso recordatorio de la fragilidad que puede esconderse tras una apariencia de fortaleza. Una combinación de error humano, profunda ética profesional, liderazgo decisivo y una buena dosis de suerte evitó lo que podría haber sido uno de los peores desastres arquitectónicos de la historia. El ingeniero que cometió el error lo afrontó con una valentía que salvó incontables vidas y, paradójicamente, reforzó su reputación.
La historia del Citigroup Center nos recuerda que incluso los símbolos de la permanencia pueden ser frágiles. Nos deja con una pregunta: ¿cuántos otros secretos se esconden en las estructuras que nos rodean, esperando a que una simple pregunta los saque a la luz?
En esta conversación puedes escuchar las ideas más interesantes sobre este asunto.
Aquí puedes ver un vídeo que resume bien el contenido del artículo.
Cuando pensamos en un experimento, solemos imaginar una prueba simple para ver qué opción es “mejor”. Sin embargo, esta visión apenas roza la superficie de una disciplina profunda y estratégica. Existen principios sorprendentes que rigen el diseño experimental y son cruciales no solo para la ciencia, sino también para cualquier toma de decisiones informada. A continuación, se describen brevemente los tipos de experimentos que pueden utilizarse en la investigación científica.
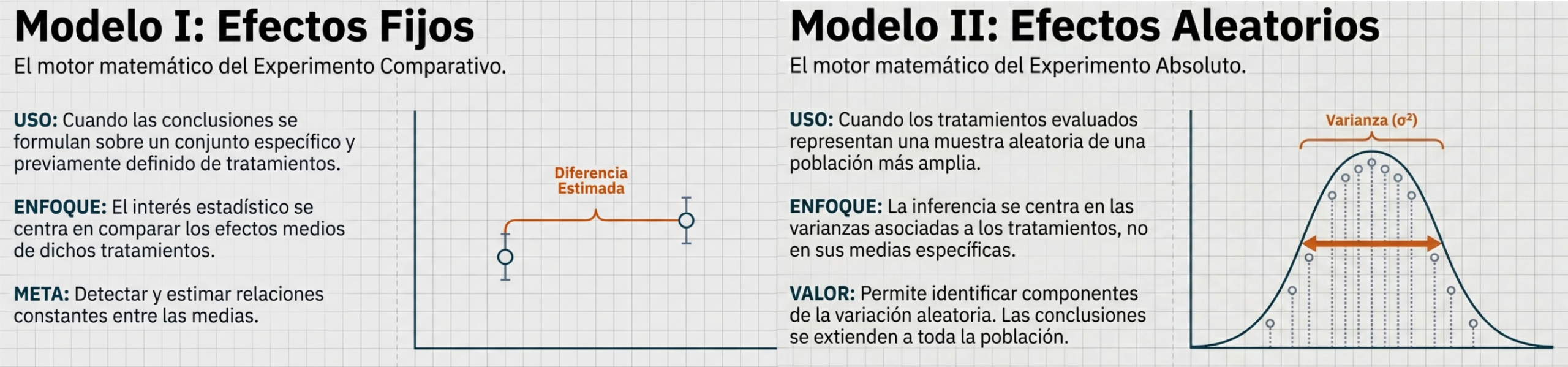
El diseño experimental se clasifica en dos categorías principales, según la propuesta de Anscombe (1947): el experimento absoluto y el experimento comparativo. El experimento absoluto se enfoca en la medición de propiedades físicas constantes para ampliar el conocimiento científico, utilizando un modelo estadístico de efectos aleatorios (Modelo II de Eisenhart), ya que los tratamientos se seleccionan al azar de una población más amplia. Por el contrario, el experimento comparativo está orientado a la toma de decisiones en ciencias aplicadas, con el fin de determinar cuál de varios tratamientos predefinidos es “mejor”. Este enfoque utiliza un modelo de efectos fijos (Modelo I de Eisenhart) y exige una definición precisa del problema para garantizar su validez.
El éxito de un experimento, especialmente el comparativo, depende del cumplimiento de cinco principios fundamentales: simplicidad, nivel de precisión adecuado, ausencia de error sistemático, amplio rango de validez de las conclusiones y una correcta cuantificación de la incertidumbre. La elección del diseño y el modelo estadístico asociado (fijo, aleatorio o mixto) determinan directamente el alcance y la naturaleza de las inferencias que pueden extraerse, vinculando de manera inseparable la planificación experimental con las conclusiones científicas y las decisiones de gestión.
La clasificación propuesta por Anscombe distingue los experimentos en dos grandes tipos según su objetivo fundamental: la adquisición de conocimiento puro o la fundamentación de decisiones prácticas.
Uno de ellos es el llamado experimento absoluto. En este tipo de experimento, el interés principal es medir y conocer las propiedades físicas de una población. Se asume que dichas propiedades permanecen constantes, lo que justifica el uso del término absoluto. El objetivo no es comparar alternativas concretas, sino ampliar el conocimiento científico sobre el fenómeno estudiado.
Los experimentos absolutos suelen centrarse en un solo factor y consideran un número limitado de tratamientos o niveles de ese factor. Estos tratamientos suelen elegirse de forma aleatoria. Por esta razón, si el experimento se repite, no es obligatorio utilizar exactamente los mismos tratamientos en cada ocasión.
Debido a esta forma de selección, los tratamientos se consideran variables aleatorias. En consecuencia, el análisis se basa en un modelo de efectos aleatorios, también conocido como el Modelo II de Eisenhart (1947). Este tipo de modelo permite identificar y estimar los distintos componentes de la variación aleatoria presentes en una población compuesta, lo que constituye un enfoque especialmente útil para muchos problemas de ingeniería.
El experimento comparativo es el segundo tipo de experimento descrito por Anscombe. Este enfoque se utiliza cuando se analizan varios tratamientos y se observa que, aunque los valores absolutos de los resultados pueden fluctuar de forma irregular, las comparaciones relativas entre tratamientos suelen mantenerse estables. En este contexto, es posible concluir que, bajo condiciones similares, algunos tratamientos ofrecen resultados claramente mejores que otros.
Brownlee (1957) sitúa este tipo de experimentos en el ámbito de las ciencias aplicadas, y no es casualidad: la teoría estadística del diseño de experimentos se desarrolló originalmente para responder a las necesidades de este tipo de estudios.
En un experimento comparativo, los tratamientos se evalúan según su efecto promedio sobre una variable de respuesta, con el objetivo principal de determinar cuál es “mejor” según un criterio definido. A diferencia de los experimentos orientados al conocimiento fundamental, aquí el propósito central es apoyar la toma de decisiones prácticas, especialmente las administrativas o de gestión.
Una característica fundamental de los experimentos comparativos es que todos los tratamientos de interés están incluidos explícitamente en el estudio. Por esta razón, el análisis se basa en un modelo de efectos fijos, también conocido como el Modelo I de Eisenhart (1947). Si el experimento se repite, se utilizan exactamente los mismos tratamientos, ya que no se considera una muestra aleatoria. El interés principal radica en detectar y estimar relaciones constantes entre las medias de los tratamientos, lo que conduce naturalmente a la evaluación de hipótesis estadísticas sobre dichas medias.
Para que un experimento comparativo sea válido, debe comenzar con una definición clara y precisa del problema. No basta con plantear de manera general la idea de “comparar tratamientos”. Es imprescindible especificar con detalle los objetivos del estudio y formular con precisión las hipótesis que se probarán. Esta definición inicial determina la población a la que se aplicarán las conclusiones, identifica los factores, los tratamientos y sus niveles, establece las variables de respuesta que se medirán y define qué diferencias entre tratamientos se consideran relevantes. Sin estas especificaciones, no es posible diseñar un experimento adecuado.
Finalmente, una consecuencia natural de los experimentos comparativos es que casi siempre conducen a decisiones concretas. Dado un nivel suficiente de recursos, la hipótesis nula de igualdad entre tratamientos puede rechazarse, lo que obliga a actuar: mantener la situación actual o cambiar a un nuevo tratamiento. Este proceso de decisión consta de dos etapas bien definidas:
Análisis estadístico de los datos, en el que se evalúan las probabilidades asociadas a los resultados y se extraen conclusiones técnicas.
Decisión de gestión en la que, con base en esas conclusiones, se define la acción a realizar.
Esta conexión directa entre el análisis estadístico y la toma de decisiones explica por qué los experimentos comparativos son una herramienta central en la divulgación y la práctica de la ingeniería y de las ciencias aplicadas.
El estadístico cumple un rol clave en el proceso experimental: su responsabilidad es presentar, con la mayor precisión posible, las probabilidades obtenidas en la etapa de análisis, de manera que se reduzca al mínimo la posibilidad de tomar decisiones equivocadas cuando llegue el momento de actuar.
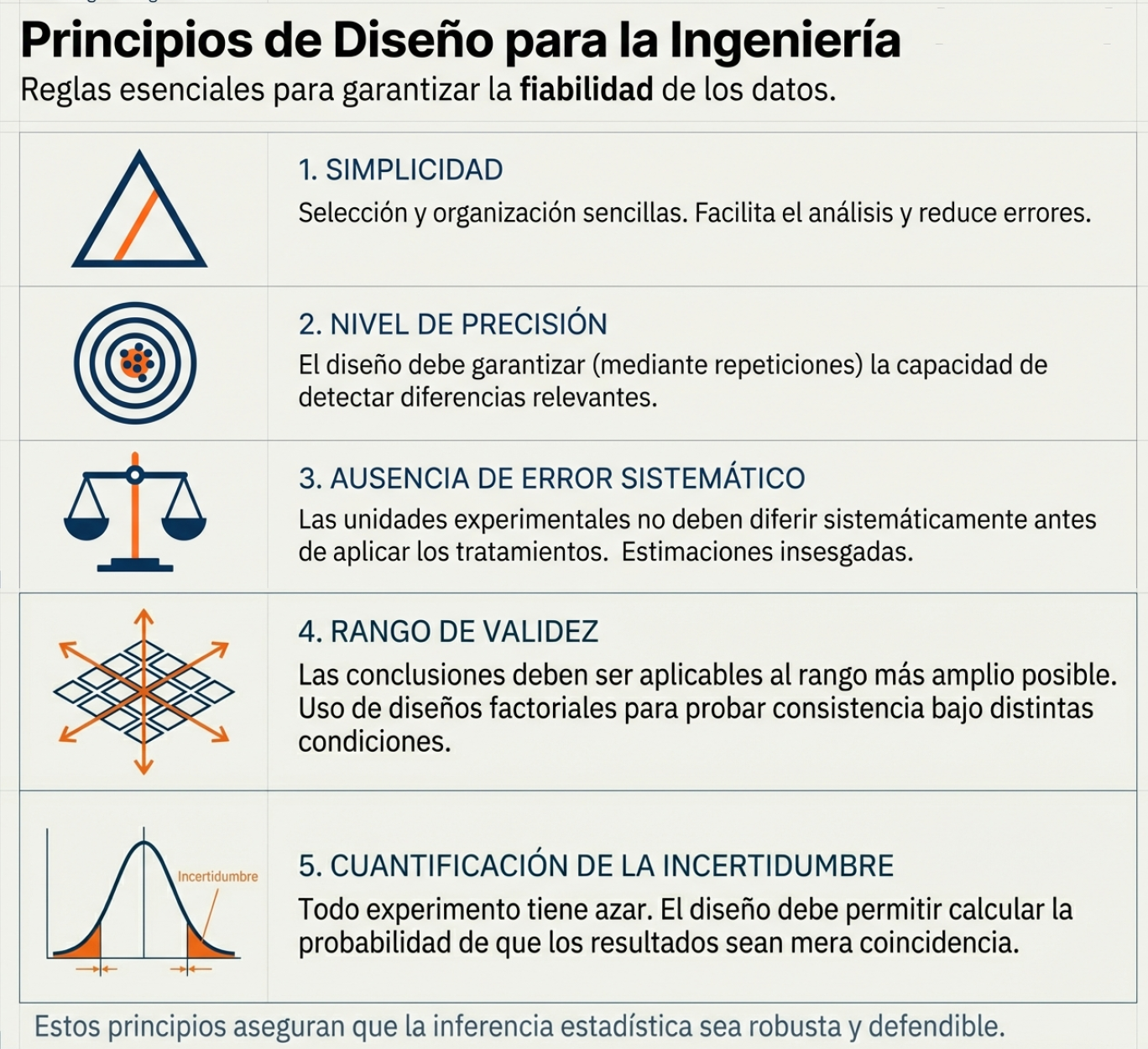
Dado que las decisiones sobre las hipótesis dependen directamente de experimentos cuidadosamente planificados, es esencial que dichos ensayos cumplan con una serie de principios básicos. A continuación se resumen los más importantes, con un enfoque práctico para la ingeniería:
Simplicidad: Tanto la selección de los tratamientos como la organización del experimento deben ser lo más simples posible. Un diseño sencillo facilita el análisis estadístico y la interpretación de los resultados y reduce el riesgo de errores innecesarios.
Nivel de precisión: El experimento debe permitir detectar diferencias entre tratamientos con el grado de precisión que el investigador considere relevante. Para lograrlo, se requiere un diseño experimental adecuado y un número suficiente de repeticiones que garanticen mediciones confiables.
Ausencia de error sistemático: El experimento debe planearse de modo que las unidades experimentales que reciben distintos tratamientos no difieran sistemáticamente entre sí antes de aplicarlos. Este cuidado es fundamental para obtener estimaciones insesgadas del efecto real de cada tratamiento, evitando que factores externos distorsionen los resultados.
Rango de validez de las conclusiones: Las conclusiones del experimento deben ser aplicables a un rango de situaciones lo más amplio posible. Los experimentos replicados y los diseños factoriales ayudan a ampliar este rango de validez, ya que permiten evaluar la consistencia de los resultados bajo diferentes condiciones.
Cuantificación de la incertidumbre: Todo experimento conlleva cierto grado de incertidumbre. Por ello, el diseño debe permitir calcular la probabilidad de que los resultados observados se deban únicamente al azar. Esta cuantificación es esencial para evaluar la solidez de las conclusiones.
Estos principios conducen a una clasificación clásica de los modelos estadísticos, propuesta por Eisenhart (1947), que conecta el diseño del experimento con el tipo de inferencia que se desea realizar:
Modelo de efectos fijos: se utiliza cuando las conclusiones se formulan sobre un conjunto específico y previamente definido de tratamientos. En este caso, el interés estadístico se centra en comparar los efectos medios de dichos tratamientos.
Modelo de efectos aleatorios: se aplica cuando los tratamientos evaluados representan una muestra aleatoria de una población más amplia de tratamientos. Aquí, las conclusiones se extienden más allá de los tratamientos observados y la inferencia se centra en las varianzas asociadas a dichos tratamientos.
Modelo de efectos mixtos: surge cuando el experimento combina tratamientos de efectos fijos y aleatorios en un mismo estudio.
Esta clasificación permite comprender cómo las decisiones sobre el diseño experimental influyen directamente en el tipo de conclusiones que pueden extraerse, un aspecto fundamental tanto en la práctica como en la divulgación de la ingeniería.
En este archivo de audio puedes escuchar una conversación sobre los tipos de experimentos.
En este vídeo se resumen las ideas más importantes sobre este tema.
Referencias:
Anscombe, F. J. (1947). The validity of comparative experiments. Journal of the Royal Statistical Society, 61, 181–211.
Brownlee, K. A. (1957). The principles of experimental design. Industrial Quality Control, 13, 1–9.
Eisenhart, C. (1947). The assumptions underlying the analysis of variance. Biometrics, 3, 1–21.
Melo, O. O., López, L. A., & Melo, S. E. (2007). Diseño de experimentos: métodos y aplicaciones. Universidad Nacional de Colombia. Facultad de Ciencias.
Puente de Quebec, Canadá. Por Murielle Leclerc, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=20033047
Introducción: El puente que tuvo que caer para enseñar a construir.
Las grandes obras de la humanidad a menudo esconden historias de sacrificio y fracaso. Las estructuras que hoy admiramos por su grandeza fueron, en su momento, escenarios de tragedias que nos obligaron a aprender de la peor manera posible. Pocos ejemplos son tan crudos y reveladores como el del puente de Quebec, en Canadá. Su historia no solo es la de un colapso, sino también la de una catástrofe que sacudió los cimientos de la ingeniería y redefinió para siempre el significado de construir con responsabilidad.
La catástrofe del puente de Quebec no solo fue una tragedia de acero retorcido y vidas perdidas, sino también el catalizador que forjó una nueva conciencia ética en toda una profesión. Su legado no se mide en toneladas de acero, sino en los principios que hoy rigen la profesión de la ingeniería en Canadá y en todo el mundo.
A continuación, desvelamos cinco datos impactantes y poco conocidos sobre su catastrófica construcción que transformaron la ingeniería moderna.
1. El desastre ocurrió dos veces, no una.
La memoria colectiva recuerda el estruendoso colapso de 1907, pero la trágica historia del puente de Quebec no terminó ahí. La estructura falló catastróficamente en dos ocasiones distintas, con nueve años de diferencia entre ellas.
El primer colapso, ocurrido el 29 de agosto de 1907, se produjo durante la fase final de la construcción del brazo sur. Sin previo aviso, casi 19 000 toneladas de acero se precipitaron al río San Lorenzo en menos de 15 segundos. El estruendo fue tan violento que los habitantes de la ciudad de Quebec, situada a diez kilómetros de distancia, creyeron que se trataba de un terremoto. Murieron 75 trabajadores (otras fuentes hablan de 76). La investigación posterior determinó que la causa inmediata había sido el fallo por pandeo del cordón de compresión A9L, una viga masiva situada cerca del pilar principal, debido a un diseño deficiente de su entramado interno.
Desastre del puente de Quebec. Restos tras el colapso del tramo sur en 1907, que causó la muerte de 75 personas. Courtesy of Dominion Bridge Company Ltd./Library and Archives Canada/PA-109498
El segundo colapso (11 de septiembre de 1916) ocurrió durante el rediseño y la reconstrucción del puente. Mientras se izaba la sección central de 5000 toneladas para conectar los dos brazos del puente, se fracturó una pieza de fundición del equipo de elevación. La enorme pieza de acero se desplomó al río ante la mirada de miles de espectadores, llevándose la vida a otros trece trabajadores.
Como sombrío monumento a la tragedia, esa sección central, caída en 1916, todavía descansa en el lecho del río San Lorenzo. Este doble desastre subrayó la inmensa dificultad del proyecto y la necesidad de revisar por completo las prácticas y la ética de la ingeniería.
2. La «arrogancia» de un solo ingeniero fue la causa raíz.
El colapso de 1907 no fue un simple error de cálculo, sino que, en gran medida, fue el resultado de la soberbia profesional. La Comisión Real de Investigación, creada para analizar el desastre, señaló a un responsable principal: Theodore Cooper, uno de los ingenieros de puentes más prestigiosos de Estados Unidos de su época.
La arrogancia de Cooper se puso de manifiesto en una serie de decisiones fatales. La más grave fue ordenar, para ahorrar costes, alargar el vano principal del puente de 490 a 550 metros. Como concluyó la Comisión, se cometió «un grave error al asumir el peso muerto en los cálculos con un valor demasiado bajo y al no revisar posteriormente esta suposición». El peso real de la estructura era entre un 10 % y un 30 % mayor que el calculado, lo que constituyó un fallo directo de su supervisión. Su mala salud le impidió visitar la obra, por lo que la dirigió desde su oficina en Nueva York.
Esta negligencia se convirtió en una tragedia cuando Norman McLure, un joven ingeniero contratado por Cooper para inspeccionar la zona, empezó a enviar informes alarmantes. Las vigas de compresión inferiores, los cordones masivos que soportaban el peso, mostraban un pandeo visible, es decir, se estaban doblando. Cuando McLure se lo comunicó, la primera reacción de Cooper fue mostrarse incrédulo: «¿Cómo ha podido suceder eso?». Cooper desarrolló su propia teoría a distancia: las vigas debían haber sido golpeadas por equipos de elevación. McLure investigó y no encontró ninguna prueba. Las vigas continuaban doblándose bajo el peso mal calculado.
La arrogancia de Cooper alcanzó su punto álgido cuando Robert Douglas, un ingeniero del Gobierno canadiense, criticó las tensiones inusualmente altas de su diseño. Cooper respondió de forma tajante:
“This puts me in the position of a subordinate, which I cannot accept.”
La tragedia fue el resultado de un fallo de comunicación. El 29 de agosto, tras la insistencia de McLure, Cooper envió por fin un telegrama a la oficina de la constructora en Pensilvania en el que escribió: «No añadan más carga al puente». Sin embargo, asumió que el mensaje se transmitiría y que se detendrían los trabajos. No fue así. La gerencia del lugar ignoró la orden y decidió esperar hasta el día siguiente para actuar. A las 17:30 h de esa misma tarde, el puente se derrumbó.
3. La tragedia transformó para siempre a la comunidad Mohawk.
La catástrofe de 1907 no solo fue una tragedia de ingeniería, sino también un profundo trauma cultural para la comunidad Mohawk de Kahnawake, cuyos hombres eran reconocidos por su extraordinaria habilidad y valentía para trabajar en las alturas.
El coste humano fue devastador. De los 75 trabajadores que murieron en el primer derrumbe, 33 eran hombres Mohawk de la pequeña comunidad de Kahnawake. La pérdida fue tan grande que cuatro apellidos de la comunidad desaparecieron por completo tras la tragedia.
Lo que sucedió después fue un acto de resiliencia social sin precedentes. Las mujeres Mohawk, en un acto de «decisión matriarcal histórica», se reunieron y dictaminaron una nueva ley para proteger a su pueblo: nunca más se permitiría que los hombres de Kahnawake trabajaran todos juntos en un mismo proyecto de construcción. A partir de ese momento, debían dispersarse en pequeños grupos por toda Norteamérica.
Esta decisión tuvo una consecuencia inesperada y extraordinaria. Los herreros Mohawk se extendieron por Canadá y Estados Unidos, convirtiéndose en una fuerza laboral de élite en la construcción de los rascacielos más icónicos de Nueva York, como el Empire State Building, el Chrysler Building, el puente George Washington y, décadas después, el World Trade Center.
Anillo de hierro usado por los ingenieros canadienses – Imagen: WikiMedia.
4. El famoso anillo de hierro de los ingenieros no proviene del puente (pero la razón es más profunda).
En Canadá, los ingenieros recién graduados participan en una ceremonia solemne llamada «El Ritual de la Vocación de un Ingeniero», en la que reciben un anillo de hierro que llevan en el dedo meñique de la mano con la que escriben. Durante décadas ha circulado la poderosa leyenda de que los primeros anillos se fabricaron con el acero del puente de Quebec que se derrumbó.
Aunque es una historia bonita, es falsa. Fuentes oficiales, como «The Corporation of the Seven Wardens», que administra el ritual, confirman que se trata de un mito simbólico. Sin embargo, su verdadero origen está directamente ligado a una tragedia. El profesor H.E.T. Haultain, al sentir que la profesión necesitaba un «nexo de unión» moral, impulsó la creación de un juramento. Para ello, contó con la ayuda de una de las figuras literarias más importantes de la época: el autor y premio Nobel Rudyard Kipling.
Kipling escribió el texto del juramento (la «Obligación») y ayudó a diseñar el anillo. La primera ceremonia tuvo lugar el 25 de abril de 1925. La razón por la que se refuta activamente el mito es profunda: los anillos se fabrican con acero inoxidable estándar para garantizar que el mensaje sea la responsabilidad, no la superstición. Su superficie áspera sirve de recordatorio constante de las consecuencias de un trabajo mal hecho y del deber de servir a la humanidad por encima de todo.
Conclusión: un monumento de acero y una lección eterna.
Hoy en día, el puente de Quebec sigue en pie. Ostenta el récord del puente tipo ménsula más largo del mundo y es un eslabón vital del transporte en Canadá. Sin embargo, su verdadera grandeza no radica en sus miles de toneladas de acero, sino en las lecciones indelebles que se aprendieron de sus escombros. Es un monumento a las 88 personas que perdieron la vida en sus dos derrumbes y un recordatorio perpetuo de las consecuencias del error y de la arrogancia humana.
Su legado más duradero es invisible: los estándares éticos y la cultura de la responsabilidad que obligó a crear. El Ritual de la Vocación de un Ingeniero, nacido de su fracaso, ha sido adoptado por más de medio millón de ingenieros y se ha convertido en un poderoso símbolo de la profesión. La tragedia nos dejó una pregunta que sigue resonando hoy con más fuerza que nunca: ¿qué «puentes» estamos construyendo hoy con las nuevas tecnologías y prestando suficiente atención a las lecciones de humildad y responsabilidad que nos dejó esta tragedia de hace más de un siglo?
En este audio se recoge una conversación en la que se analizan los aspectos más relevantes de los desastres sufridos por este puente y por el Anillo de Hierro.
Este vídeo constituye una buena síntesis de las ideas fundamentales del artículo.
En este documento se sintetiza la información anterior.
La tesis doctoral leída recientemente por Lorena Yepes Bellver se centra en la optimización del diseño de puentes de losa de hormigón pretensado para pasos elevados con el fin de mejorar la sostenibilidad económica y ambiental mediante la minimización de costes, energía incorporada y emisiones de CO₂. Con el fin de reducir la elevada carga computacional del análisis estructural, la metodología emplea un marco de optimización de dos fases asistido por modelos sustitutos, en el que se destaca el uso de Kriging y redes neuronales artificiales (RNA).
En concreto, la optimización basada en Kriging condujo a una reducción de costes del 6,54 % al disminuir significativamente el consumo de hormigón y acero activo sin comprometer la integridad estructural. Si bien las redes neuronales demostraron una mayor precisión predictiva global, el modelo Kriging resultó más eficaz para identificar los óptimos locales durante el proceso de búsqueda. El estudio concluye que las configuraciones de diseño óptimas priorizan el uso de altos coeficientes de esbeltez y suponen una reducción del hormigón y del acero activo en favor del acero pasivo, con el fin de mejorar la eficiencia energética. Finalmente, la investigación integra la toma de decisiones multicriterio (MCDM, por sus siglas en inglés) para evaluar de manera integral los diseños en función de sus objetivos económicos, estructurales y ambientales.
Cuando pensamos en la construcción de grandes infraestructuras, como los puentes, suele venirnos a la mente la imagen de proyectos masivos, increíblemente caros y con un gran impacto ambiental. Son gigantes de hormigón y acero que, aunque necesarios, parecen irrenunciablemente vinculados a un alto coste económico y ecológico.
Sin embargo, ¿y si la inteligencia artificial nos estuviera mostrando un camino para que estos gigantes de hormigón fueran más ligeros, económicos y respetuosos con el planeta? Una reciente tesis doctoral sobre la optimización de puentes está desvelando hallazgos impactantes y, en muchos casos, sorprendentes. Este artículo resume esa compleja investigación en cinco lecciones clave y a menudo sorprendentes que no solo se aplican a los puentes, sino que anuncian una nueva era en el diseño de infraestructuras.
1. La sostenibilidad cuesta mucho menos de lo que crees.
Uno de los descubrimientos más importantes de la investigación es que la idea de que la sostenibilidad siempre implica un alto sobrecoste es, en gran medida, un mito. La optimización computacional demuestra que la viabilidad económica y la reducción del impacto ambiental no son objetivos opuestos.
La tesis doctoral lo cuantifica con precisión: un modesto aumento de los costes de construcción (inferior al 1 %) puede reducir sustancialmente las emisiones de CO₂ (en más de un 2 %). Este dato es muy relevante, ya que demuestra que con un diseño inteligente asistido por modelos predictivos se puede conseguir un beneficio medioambiental significativo con una inversión mínima. La sostenibilidad y la rentabilidad pueden y deben coexistir en el diseño de las infraestructuras del futuro.
2. El secreto está en la esbeltez: cuanto más fino, más eficiente.
En el diseño de un puente, la «relación de esbeltez» es un concepto clave que define la proporción entre la altura del tablero (su grosor) y la longitud del vano principal. Tradicionalmente, podríamos pensar que «más robusto es más seguro», pero la investigación demuestra lo contrario.
El estudio identificó una relación de esbeltez óptima para minimizar el impacto ambiental. Concretamente, el estudio halló una relación de esbeltez de aproximadamente 1/30 para optimizar las emisiones de CO₂ y de aproximadamente 1/28 para optimizar la energía incorporada. Esto significa que, en lugar de construir puentes masivos por defecto, los modelos de IA demuestran que un diseño más esbelto y afinado no solo es estructuralmente sólido, sino también mucho más eficiente en el uso de materiales. Este diseño más esbelto se logra no solo usando menos material en general, sino también mediante un sorprendente reequilibrio entre los componentes clave de la estructura, como veremos a continuación.
3. El equilibrio de materiales: menos hormigón, más acero (pasivo).
Quizás uno de los descubrimientos más sorprendentes es que el diseño más sostenible no consiste simplemente en utilizar menos cantidad de todos los materiales. La solución óptima es más un reequilibrio inteligente que una simple reducción general.
La investigación revela que los diseños optimizados lograron reducir el uso de hormigón en un 14,8 % y de acero activo (el acero de pretensado que tensa la estructura) en un 11,25 %. Sin embargo, este descenso se compensa con un aumento de la armadura pasiva (el acero convencional que refuerza el hormigón). Esto resulta contraintuitivo, ya que la intuición ingenieril a menudo favorece una reducción uniforme de los materiales. Sin embargo, los modelos computacionales identifican un complejo intercambio —sacrificar un material más barato (hormigón) por otro más caro (acero pasivo)— para alcanzar un diseño globalmente óptimo en términos de coste y emisiones de CO₂, un equilibrio que sería extremadamente difícil de lograr con métodos de diseño tradicionales.
4. Precisión frente a dirección: El verdadero poder de los modelos predictivos.
Al comparar diferentes modelos de IA, como las redes neuronales artificiales y los modelos Kriging, la tesis doctoral reveló una lección fundamental sobre su verdadero propósito en ingeniería.
El estudio reveló que, si bien las redes neuronales ofrecían predicciones absolutas más precisas, el modelo Kriging era más eficaz para identificar las regiones de diseño óptimas. Esto pone de manifiesto un aspecto crucial sobre el uso de la IA en el diseño: su mayor potencial no radica en predecir un valor exacto, como si fuera una bola de cristal, sino en guiar al ingeniero hacia la «región» del diseño donde se encuentran las mejores soluciones posibles. La IA es una herramienta de exploración y dirección que permite navegar por un universo de posibilidades para encontrar de forma eficiente los diseños más prometedores.
5. La optimización va directo al bolsillo: reducción de costes superior al 6 %.
Más allá de los objetivos medioambientales, la investigación demuestra que estos modelos de IA son herramientas muy potentes para la optimización económica directa. Este descubrimiento no se refiere al equilibrio entre coste y sostenibilidad, sino a la reducción pura y dura de los costes del proyecto.
La tesis doctoral muestra que el método de optimización basado en Kriging consigue una reducción de costes del 6,54 %. Esta importante reducción se consigue principalmente minimizando el uso de materiales: un 14,8 % menos de hormigón y un 11,25 % menos de acero activo, el acero de pretensado más especializado y costoso. Esto demuestra de forma contundente que los modelos sustitutivos no solo sirven para alcanzar metas ecológicas, sino que también son una herramienta de gran impacto para la optimización económica en proyectos a gran escala.
Conclusión: Diseñando el futuro, un puente a la vez.
La inteligencia artificial y los modelos de optimización han dejado de ser conceptos abstractos para convertirse en herramientas prácticas que permiten descubrir formas novedosas y eficientes de construir la infraestructura del futuro. Los resultados de esta investigación demuestran que es posible diseñar y construir puentes que sean más económicos y sostenibles al mismo tiempo.
Estos descubrimientos no solo se aplican a los puentes, sino que abren la puerta a una nueva forma de entender la ingeniería. Si la IA puede rediseñar algo tan grande como un puente para hacerlo más sostenible, ¿qué otras grandes industrias están a punto de transformarse con un enfoque similar?
En este audio podéis escuchar una conversación sobre este tema.
Este vídeo resume las ideas principales.
Aquí tenéis un documento resumen de las ideas básicas.
Todos hemos pasado por ello: cuestionarios interminables, preguntas que parecen sacadas de un manual de psicología y, sobre todo, esa sensación de responder a la misma pregunta una y otra vez. Es una experiencia tan común como, a menudo, frustrante. ¿Por qué algunas preguntas parecen extrañas o repetitivas? ¿Realmente merece la pena todo este esfuerzo?
La respuesta es un rotundo sí. Detrás de cada cuestionario bien diseñado se esconde la rigurosa ciencia de la psicometría, el campo dedicado al arte de la medición precisa. Conceptos como la fiabilidad y la validez son los pilares de cualquier instrumento de medición serio, ya sea una encuesta de satisfacción del cliente o un test de personalidad.
Este artículo desvela algunos de los secretos más sorprendentes y fascinantes sobre cómo se construyen estas escalas de medida. Descubrirás por qué la repetición puede ser una virtud, por qué la perfección a veces es sospechosa y por qué es posible equivocarse de manera confiable.
Primer secreto: la fiabilidad no es la validez (y se puede estar fiablemente equivocado).
En el mundo de la medición, la fiabilidad y la validez son dos conceptos cruciales que a menudo se confunden. Sin embargo, comprender su diferencia es fundamental para entender por qué algunas encuestas funcionan y otras no.
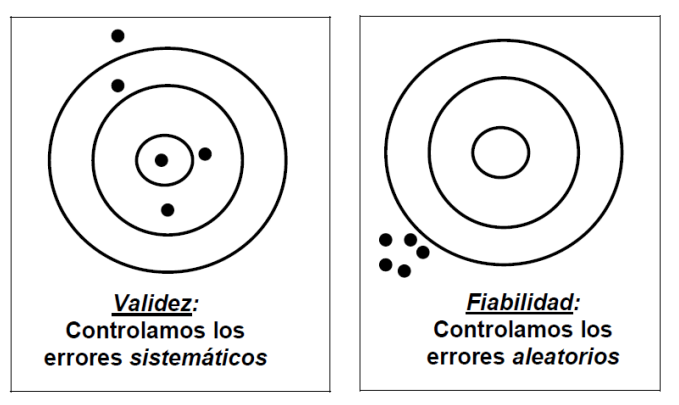
La fiabilidad se refiere a la precisión o consistencia de una medida. Un instrumento fiable produce resultados muy similares cada vez que se utiliza en las mismas condiciones.
La validez es la exactitud de la medida. Un instrumento válido mide exactamente lo que se pretende medir. La validez va más allá de la simple exactitud, ya que se asegura de que las conclusiones que extraemos de los resultados de la encuesta estén justificadas y sean significativas.
La mejor manera de entenderlo es mediante la analogía de un tirador que apunta a una diana.
Fiabilidad sin validez: imagina a un tirador. Escuchas el sonido seco y repetitivo de los disparos impactando en la madera, agrupados en un área no mayor que una moneda, pero peligrosamente cerca del borde de la diana. El patrón es muy consistente (alta fiabilidad), pero erróneo de forma sistemática, ya que no alcanza el blanco (baja validez). Esto representa un error sistemático que se debe a un defecto fundamental en el diseño del cuestionario, como preguntas mal redactadas o una escala de respuesta poco clara.
Validez con baja fiabilidad: ahora imagina a un tirador cuyos disparos están dispersos por toda la diana, pero cuya media se sitúa justo en el centro. No hay precisión en cada tiro (baja fiabilidad), pero, en conjunto, apuntan en la dirección correcta (alta validez). Esto representa errores aleatorios que pueden deberse a factores incontrolables, como distracciones, ruido ambiental o incluso al estado de ánimo temporal del encuestado.
Validez y fiabilidad (Morales, 2008)
La conclusión clave es que la validez es más importante que la fiabilidad. Como subrayan los expertos en la materia: «Un instrumento puede ser muy fiable (medir muy bien), pero no medir bien lo que se quería medir». De nada sirve medir algo con una precisión milimétrica si no es lo que realmente nos interesa.
Segundo secreto: ¿por qué las encuestas a veces parecen repetitivas?
Una de las quejas más comunes sobre los cuestionarios es que incluyen preguntas que parecen decir lo mismo de distintas maneras. Lejos de ser un descuido, el uso de lo que los expertos denominan «ítems repetitivos» —expresar la misma idea de diversas formas— es una técnica deliberada y muy útil para garantizar la calidad de los datos. Esta «forma bidireccional de redactar los ítems» tiene dos ventajas principales:
Requiere mayor atención del sujeto: al presentar la misma idea con formulaciones distintas (a veces en positivo y otras en negativo), se evita que la persona responda de forma automática o sin pensar y se le obliga a procesar el significado de cada pregunta.
Permite comprobar la coherencia de las respuestas: sirve como control de calidad para detectar y mitigar dos de los sesgos más frecuentes al responder encuestas: la aquiescencia y el sesgo de confirmación.
Aquiescencia: tendencia a estar de acuerdo con todas las afirmaciones. Imagina a alguien que responde con prisas, marcando «Totalmente de acuerdo» a todo («Sí, el servicio fue excelente», «Sí, el producto es terrible»), con el único fin de terminar cuanto antes.
Deseabilidad social: tendencia a responder para proyectar una buena imagen. Este sesgo lo muestra la persona que, al ser preguntada por sus hábitos de reciclaje, se presenta como un ecologista modelo, aunque el contenido de su cubo de basura cuente una historia muy diferente.
Por lo tanto, la próxima vez que te encuentres con preguntas que te resulten familiares en un mismo cuestionario, recuerda que no se trata de un error. Se trata de una herramienta diseñada para garantizar que tus respuestas sean más atentas, coherentes y, en última instancia, sinceras.
Tercer secreto: una fiabilidad «perfecta» puede ser una señal de alarma.
Intuitivamente, podríamos pensar que el objetivo de cualquier escala de medida es lograr la mayor fiabilidad posible. Sin embargo, en psicometría, una fiabilidad extremadamente alta puede ser una señal de alarma que indica un problema subyacente.
El coeficiente de fiabilidad más utilizado, el alfa de Cronbach, presenta una particularidad: su valor tiende a aumentar al añadir más ítems a la escala. Esto crea la tentación de inflar artificialmente la fiabilidad simplemente alargando el cuestionario. Como advierte la literatura especializada: «No se debe buscar una alta fiabilidad aumentando sin más el número de ítems, sin pensar si realmente son válidos».
Un ejemplo hipotético ilustra perfectamente este peligro. Imaginemos que aplicamos un test a un grupo mixto compuesto por niñas de 10 años que hacen ballet y niños de 14 años que juegan al fútbol. Les preguntamos por su edad, su sexo y el deporte que practican. La fiabilidad estadística se dispara porque las preguntas son perfectamente consistentes al separar a los dos grupos. Si se pregunta sobre ballet, todas las niñas responden de una manera y todos los niños de otra. Si se pregunta por el fútbol, ocurre lo mismo. El algoritmo estadístico detecta esta consistencia impecable y reporta una fiabilidad altísima, sin comprender que el «rasgo» subyacente que se está midiendo es simplemente una mezcla de datos demográficos, no una característica psicológica coherente. A pesar de esa elevada fiabilidad, en realidad no estaríamos midiendo «nada interpretable».
Este ejemplo nos deja una lección fundamental que el texto fuente resume de manera brillante:
«En ningún caso la estadística sustituye al sentido común y al análisis lógico de nuestras acciones».
Conclusión: la próxima vez que rellenes una encuesta…
Desde el dilema fundamental entre mediciones consistentes, pero erróneas (fiabilidad frente a validez), pasando por el uso deliberado de la repetición para burlar nuestros propios sesgos, hasta la idea contraintuitiva de que una puntuación «perfecta» puede indicar un resultado sin sentido, queda claro que elaborar una buena encuesta es un trabajo científico.
La próxima vez que te enfrentes a un cuestionario, en lugar de frustrarte por sus preguntas, ¿te detendrás a pensar qué rasgo intentan medir y si realmente lo están logrando?
En este audio os dejo una conversación sobre estas ideas.
Os dejo un vídeo que resume el contenido de este artículo.
Referencias:
Campbell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait–multimethod matrix. Psychological Bulletin, 56(2), 81–105. https://doi.org/10.1037/h0046016
Dunn, T. J., Baguley, T., & Brunsden, V. (2014). From alpha to omega: A practical solution to the pervasive problem of internal consistency estimation. British Journal of Psychology, 105, 399–412. https://doi.org/10.1111/bjop.12046
Farrell, A. M. (2010). Insufficient discriminant validity: A comment on Bove, Pervan, Beatty and Shiu (2009). Journal of Business Research, 63, 324–327. https://ssrn.com/abstract=3466257
Fornell, C., & Larcker, D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 18(1), 39–50. https://doi.org/10.1177/002224378101800104
Frías-Navarro, D. (2019). Apuntes de consistencia interna de las puntuaciones de un instrumento de medida. Universidad de Valencia. https://www.uv.es/friasnav/AlfaCronbach.pdf
Grande, I., & Abascal, E. (2009). Fundamentos y técnicas de investigación comercial. Madrid: ESIC.
Hernández, B. (2001). Técnicas estadísticas de investigación social. Madrid: Díaz de Santos.
Hair, J. F., Anderson, R. E., Tatham, R. L., & Black, W. C. (1995). Multivariate data analysis (Eds.). New York: Prentice Hall International, Inc.
Morales, P. (2006). Medición de actitudes en psicología y educación. Madrid: Universidad Pontificia de Comillas.
Morales, P. (2008). Estadística aplicada a las ciencias sociales. Madrid: Universidad Pontificia Comillas.
Nadler, J., Weston, R., & Voyles, E. (2015). Stuck in the middle: The use and interpretation of mid-points in items on questionnaires. The Journal of General Psychology, 142(2), 71–89. https://doi.org/10.1080/00221309.2014.994590
Nunnally, J. C. (1978). Psychometric theory. New York: McGraw-Hill.
Cuando pensamos en la construcción de grandes infraestructuras, como los puentes, a menudo nos viene a la mente una imagen de fuerza bruta: toneladas de hormigón y acero ensambladas con una precisión monumental. Se trata de una proeza de la ingeniería física, un testimonio de la capacidad humana para dominar los materiales y la geografía.
Sin embargo, detrás de esta fachada de poderío industrial se está produciendo una revolución silenciosa. La inteligencia artificial y los modelos computacionales avanzados, que pueden ejecutar el equivalente a décadas de diseño y pruebas de ingeniería en cuestión de horas, están redefiniendo las reglas del juego. Lejos de ser un mero ejercicio teórico, estas herramientas permiten a los ingenieros diseñar puentes que son no solo más resistentes, sino también sorprendentemente más económicos y respetuosos con el medio ambiente.
Las lecciones que siguen se basan en los hallazgos de una tesis doctoral, defendida por la profesora Lorena Yepes Bellver, innovadora en la optimización de puentes. La tesis obtuvo la máxima calificación de sobresaliente «cum laude». Las lecciones demuestran que el futuro de la construcción no radica únicamente en nuevos materiales milagrosos, sino en la aplicación de una inteligencia que permita aprovechar los ya existentes de forma mucho más eficiente.
De izquierda a derecha: Julián Alcalá, Salvador Ivorra, Lorena Yepes, Tatiana García y Antonio Tomás.
1. El pequeño coste de un gran impacto ecológico: pagar un 1 % más para emitir un 2 % menos de CO₂.
Uno de los principales obstáculos para la adopción de prácticas sostenibles ha sido siempre la creencia de que «ser verde» es significativamente más caro. Sin embargo, la investigación en optimización de puentes revela una realidad mucho más alentadora. Gracias a los diseños perfeccionados mediante metamodelos, es posible lograr reducciones significativas de la huella de carbono con un impacto económico mínimo.
El dato clave del estudio es contundente: «Un modesto aumento de los costes de construcción (menos del 1 %) puede reducir sustancialmente las emisiones de CO₂ (más del 2 %)». Este hallazgo demuestra que la sostenibilidad no tiene por qué ser un lujo, sino el resultado de una ingeniería más inteligente.
«Esto demuestra que el diseño de puentes sostenibles puede ser económicamente viable».
Esta lección es fundamental, ya que pone fin a una falsa dicotomía entre la economía y la ecología. Demuestra que no es necesario elegir entre un puente asequible y otro respetuoso con el medio ambiente. Gracias a las decisiones de diseño inteligentes, guiadas por la optimización avanzada, es posible alcanzar ambos objetivos simultáneamente, de modo que la sostenibilidad se convierte en una ventaja competitiva y no en una carga.
2. La paradoja de los materiales: añadir más componentes para reducir el consumo global.
La lógica convencional nos diría que, para construir de forma más sostenible, el objetivo debería ser reducir la cantidad total de materiales utilizados. Menos hormigón, menos acero, menos de todo. Sin embargo, uno de los hallazgos más sorprendentes de la tesis es una paradoja que desafía esta idea tan simple.
El diseño óptimo y más sostenible aumenta, de hecho, la cantidad de uno de sus componentes: la armadura pasiva (el acero de refuerzo convencional). A primera vista, esto parece contradictorio: ¿cómo puede ser más ecológico añadir más material?
La explicación se debe a un enfoque sistémico. Este aumento estratégico y calculado del refuerzo pasivo permite reducir considerablemente el consumo de otros dos materiales clave: el hormigón y la armadura activa (el acero de pretensado). La producción de estos materiales, especialmente la del cemento y del acero de alta resistencia, es intensiva en energía y, por tanto, genera numerosas emisiones de CO₂. En esencia, se sacrifica una pequeña cantidad de un material de menor impacto para ahorrar una cantidad mucho mayor de materiales de alto impacto.
Este enfoque, que podría describirse como «sacrificar una pieza para ganar el juego», es un ejemplo perfecto de cómo la optimización avanzada supera las reglas simplistas de reducción. En lugar de aplicar un recorte general, se analiza el sistema en su conjunto y se determina el equilibrio más eficiente. Este equilibrio inteligente de materiales solo es posible si se afina otro factor clave: la geometría de la estructura.
Retos en la optimización de puentes con metamodelos
3. Más esbelto es mejor: el secreto de la «delgadez» estructural para la sostenibilidad.
En el ámbito de la ingeniería de puentes, el concepto de «esbeltez» es fundamental. En términos sencillos, se refiere a la relación entre el canto de la losa y la luz que debe cubrir. Una mayor esbeltez implica un diseño estructural, en palabras comunes, más «delgado» o «fino».
La investigación revela un hallazgo crucial: los diseños que son óptimos tanto en términos de emisiones de CO₂ como de energía incorporada se logran con relaciones de esbeltez altas, concretamente de entre 1/30 y 1/28. En otras palabras, los puentes más sostenibles son también los más delgados y se complementan con hormigones óptimos situados entre 35 y 40 MPa de resistencia característica.
¿Por qué es esto tan beneficioso? Un diseño más esbelto requiere, inherentemente, una menor cantidad de materiales, principalmente de hormigón. Lo realmente notable es cómo se consigue. Los métodos tradicionales suelen basarse en reglas generales y márgenes de seguridad amplios, mientras que la optimización computacional permite a los ingenieros explorar miles, e incluso millones, de variaciones para acercarse al límite físico de la eficiencia sin sacrificar la seguridad. El resultado es una elegancia estructural casi contraintuitiva: puentes que alcanzan su fuerza no a través de la masa bruta, sino mediante una delgadez inteligentemente calculada, donde la sostenibilidad es una consecuencia natural de la eficiencia.
4. La optimización inteligente genera ahorros reales: una reducción de costes de hasta un 6,5 %.
Más allá de los beneficios medioambientales, la aplicación de estas técnicas de optimización tiene un impacto económico directo y medible. El diseño de infraestructuras deja de ser un arte basado únicamente en la experiencia para convertirse en una ciencia precisa que busca la máxima eficiencia económica.
El resultado principal del estudio sobre la optimización de costes es claro: el uso de modelos sustitutos (metamodelos Kriging) guiados por algoritmos heurísticos, como el recocido simulado, logró una reducción de costes del 6,54 % en comparación con un diseño de referencia.
Estos ahorros no son teóricos, sino que provienen directamente de la reducción de materiales. En concreto, se consiguió una disminución del 14,8 % en el uso de hormigón y del 11,25 % en el acero activo (pretensado). Es crucial destacar que estas reducciones se consiguieron sin afectar a la integridad estructural ni a la capacidad de servicio del puente. No se trata de sacrificar la calidad por el precio, sino de diseñar de manera más inteligente. Esta metodología convierte la optimización del diseño en una tarea académica en una herramienta práctica y altamente eficaz para la gestión económica de grandes proyectos de ingeniería civil.
5. No todos los cerebros artificiales piensan igual; la clave está en elegir el modelo computacional adecuado.
Una de las lecciones más importantes de esta investigación es que no basta con aplicar «inteligencia artificial» de forma genérica. El éxito de la optimización depende de elegir la herramienta computacional adecuada para cada tarea específica.
La tesis comparó dos potentes metamodelos: las redes neuronales artificiales (RNA) y los modelos de Kriging. Se descubrió una diferencia crucial en su rendimiento: si bien las RNA ofrecían predicciones absolutas más precisas sobre el comportamiento de un diseño concreto, el modelo de Kriging demostró ser mucho más eficaz para identificar los «óptimos locales», es decir, las zonas del mapa de diseño donde se encontraban las mejores soluciones.
Esto revela una capa más profunda de la optimización inteligente. Un modelo puede ser excelente para predecir un resultado (RNA), mientras que otro es más eficaz para guiar la búsqueda del mejor resultado posible (Kriging). No se trata solo de utilizar IA, sino de comprender qué «tipo de pensamiento» artificial es el más adecuado para cada fase del problema: predecir frente a optimizar. La verdadera maestría de la ingeniería moderna consiste en saber elegir las herramientas adecuadas para cada fase del problema.
Conclusión: la nueva frontera del diseño de infraestructuras.
La construcción de nuestras infraestructuras entra en una nueva era. La combinación de la ingeniería estructural clásica con el poder de los modelos computacionales avanzados, como el metamodelado Kriging y las redes neuronales artificiales, está abriendo una nueva frontera en la que la eficiencia y la sostenibilidad no son objetivos opcionales, sino resultados intrínsecos de un buen diseño.
Como hemos visto, los grandes avances no siempre provienen de materiales revolucionarios. A menudo, los «secretos» mejor guardados residen en la optimización inteligente de los diseños y materiales que ya conocemos. Obtener un mayor beneficio ecológico pagando menos, utilizar estratégicamente más de un material para reducir el consumo global o diseñar estructuras más esbeltas y elegantes son lecciones que van más allá de la construcción de puentes.
Nos dejan con una pregunta final que invita a la reflexión: si podemos lograr esto con los puentes, ¿qué otras áreas de la construcción y la industria están esperando a ser reinventadas por el poder de la optimización inteligente?
Os dejo un audio en el que se discuten las ideas de la tesis doctoral. Espero que os guste.
Y en este vídeo, tenemos resumidas las ideas principales de esta tesis.
Ayer, cuando se cumplían 11 meses de la catástrofe de la DANA de 2024, volvimos a estar en alerta roja en Valencia. No se trató de un evento tan catastrófico como el que vivimos hace menos de un año. Pero volvieron los fantasmas y se volvió a poner a prueba todo el esfuerzo, con mayor o menor acierto, que se está realizando para evitar este tipo de catástrofes.
Queda mucho por hacer: necesitamos consenso en la gobernanza de los proyectos de futuro, desarrollo sostenible de los territorios, un mejor conocimiento para actuar de manera más eficaz por parte de las autoridades y los ciudadanos, y finalmente, aprender a convivir con las inundaciones.
A continuación, os resumo algunos pensamientos sobre este tema que he ido publicando en este blog. Espero que sirvan para reflexionar sobre este tema.
Introducción: cuando la «naturaleza» no es la única culpable.
Tras la devastadora DANA que asoló la provincia de Valencia en octubre de 2024, dejando una estela de dolor y destrucción, es natural buscar explicaciones. La tendencia humana nos lleva a señalar a la «furia de la naturaleza», a la «mala suerte» o a un evento tan extraordinario que era imposible de prever. Nos sentimos víctimas de una fuerza incontrolable.
Sin embargo, un análisis técnico y sereno nos obliga a mirar más allá del barro y el agua. Como se argumenta en foros de expertos, los desastres no son naturales, sino que son siempre el resultado de acciones y decisiones humanas que, acumuladas con el paso del tiempo, crean las condiciones perfectas para la tragedia. Esta idea no es nueva. Ya en 1755, tras el terremoto de Lisboa, Jean-Jacques Rousseau le escribía a Voltaire: «Convenga usted que la naturaleza no construyó las 20.000 casas de seis y siete pisos, y que, si los habitantes de esta gran ciudad hubieran vivido menos hacinados, con mayor igualdad y modestia, los estragos del terremoto hubieran sido menores, o quizá inexistentes».
Este artículo explora cuatro de las ideas menos obvias y más impactantes que surgen del análisis técnico del desastre. Cuatro revelaciones que nos invitan a dejar de buscar un único culpable para empezar a entender las verdaderas raíces del riesgo, repensar cómo nos preparamos para él y, sobre todo, cómo lo reconstruimos de forma más inteligente.
Primera revelación: un desastre no es azar, es la coincidencia de errores en cadena (el modelo del queso suizo).
La primera revelación consiste en abandonar la búsqueda de un único culpable. Un desastre no es un rayo que cae, sino una tormenta perfecta de debilidades sistémicas.
1. Las catástrofes no se producen por un único fallo, sino por una tormenta perfecta de pequeñas debilidades.
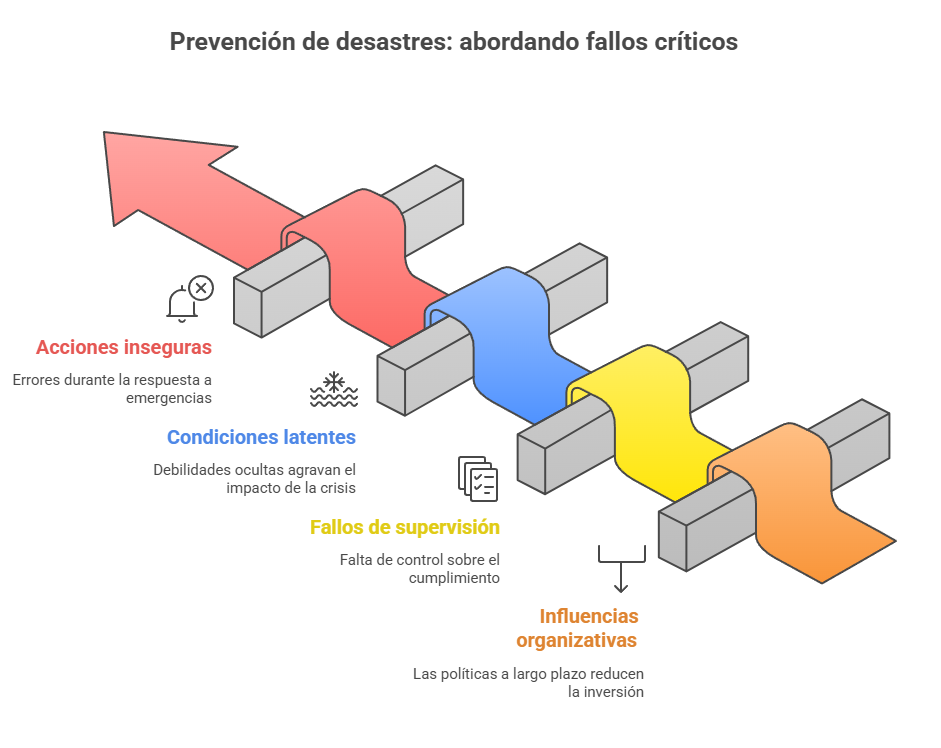
Para entender por qué un fenómeno meteorológico extremo se convierte en una catástrofe, los analistas de riesgos utilizan el «modelo del queso suizo» de James T. Reason. La idea es sencilla: nuestro sistema de protección es como una pila de lonchas de queso. Cada loncha representa una capa de defensa (infraestructuras, planes de emergencia, normativas urbanísticas) y los agujeros en cada una de ellas simbolizan fallos o debilidades. Ocurre un desastre cuando los agujeros de varias capas se alinean, creando una «trayectoria de oportunidad de accidente» que permite al peligro atravesar todas las barreras.
Aplicado a la gestión de inundaciones, este modelo identifica cuatro áreas principales donde se producen estos fallos:
Influencias organizativas: decisiones políticas a largo plazo, como «un contexto de austeridad» en el que las instituciones «reducen la inversión en infraestructuras de protección». Esto crea agujeros latentes en nuestras defensas.
Fallos de supervisión: falta de control efectivo sobre el cumplimiento de normativas, como la construcción en zonas inundables o el mantenimiento de infraestructuras de contención.
Condiciones latentes: Debilidades preexistentes que permanecen ocultas hasta que se produce la crisis. Un sistema de drenaje obsoleto, planes de evacuación anticuados o la «falta de concienciación y preparación en la comunidad» son ejemplos de condiciones latentes.
Acciones inseguras: errores activos cometidos durante la emergencia, como retrasos en la emisión de alertas o una comunicación deficiente con el público.
Esta perspectiva nos saca del juego de la culpa lineal —una presa que falló, una alerta que no llegó— y nos obliga a entender el desastre como un fallo sistémico acumulado, resultado de años de pequeñas decisiones, omisiones y debilidades que finalmente se alinearon en el peor momento posible.
2. Volver a construir lo mismo que se destruyó es programar la siguiente catástrofe.
Tras la conmoción, la presión política y social exige una respuesta inmediata: limpiar, reparar y reconstruir. Sin embargo, este impulso esconde una de las trampas más peligrosas. Si la reconstrucción se limita a la reposición de lo perdido, ignoramos la lección más importante y perpetuamos las mismas vulnerabilidades.
La forma en que se afronta la reconstrucción tras un desastre no puede limitarse a la reposición de lo perdido.
Aquí surge un conflicto fundamental. Por un lado, está el «enfoque táctico» de los políticos, que necesitan acciones rápidas y visibles. Como explican los análisis de ingeniería, «la rapidez en la ejecución de ciertas obras genera la percepción de una gestión eficaz, pero este proceder puede ocultar la ausencia de una estrategia que optimice las actuaciones a largo plazo». Por otro lado, está la necesidad técnica de llevar a cabo una reflexión estratégica que requiere tiempo para analizar qué ha fallado y diseñar soluciones resilientes que no repitan los errores del pasado.
Para evitar que la urgencia impida esta reflexión, es esencial contar con un equipo de análisis, una especie de «ministerio del pensamiento», que establezca directrices fundamentadas. Esta «trampa de la reconstrucción» es común porque la reflexión es lenta y políticamente menos rentable que una foto posando en la inauguración de un puente reparado. Evitarla tras la DANA de Valencia es crucial. No se trata solo de levantar muros, sino de aprovechar esta dolorosa oportunidad para reordenar el territorio, rediseñar las infraestructuras y construir una sociedad más segura.
Tercera revelación: El clima ha roto las reglas del juego.
3. Ya no podemos utilizar el pasado como guía infalible para diseñar el futuro de nuestras infraestructuras.
Durante un siglo, la ingeniería se ha basado en una premisa fundamental que hoy es una peligrosa falsedad: que el clima del pasado era una guía fiable para el futuro. Este principio, conocido como «estacionariedad climática», ha dejado de ser válido. Esta hipótesis partía de la base de que, aunque el clima es variable, sus patrones a largo plazo se mantenían estables, lo que permitía utilizar registros históricos para calcular estadísticamente los «periodos de retorno» y diseñar infraestructuras capaces de soportar, por ejemplo, la «tormenta de los 100 años», un evento que no ocurre cada 100 años, sino que tiene un 1 % de probabilidad de suceder en cualquier año.
El cambio climático ha invalidado esta hipótesis. El clima ya no es estacionario. La frecuencia e intensidad de los fenómenos meteorológicos extremos están aumentando a un ritmo que hace que los datos históricos dejen de ser una referencia fiable. Esta no estacionariedad aumenta los «agujeros» en nuestro queso suizo de defensas, haciendo que las vulnerabilidades sistémicas sean aún más críticas.
La consecuencia es alarmante: muchas de nuestras infraestructuras (puentes, sistemas de drenaje, presas) pueden haber sido diseñadas para unas condiciones que ya no existen, lo que aumenta drásticamente el riesgo estructural. La adaptación al cambio climático no es una opción ideológica, sino una necesidad inaplazable. Esto exige una revisión completa de los códigos de diseño y los planes de ordenación del territorio. Debemos dejar de mirar exclusivamente por el retrovisor para empezar a diseñar con la vista puesta en el futuro.
Cuarta revelación: Los argumentos técnicos no ganan batallas culturales.
4. El obstáculo más grande no es técnico ni económico, sino nuestra propia mente.
Ingenieros y científicos llevan años advirtiendo sobre los riesgos. Sin embargo, estas advertencias a menudo no se traducen en la voluntad política y social necesaria para actuar. La respuesta se halla en la psicología humana. El fenómeno de la «disonancia cognitiva» explica nuestra tendencia a rechazar información que contradiga nuestras creencias más profundas. A esto se suma la «asimetría cognitiva»: la brecha de comunicación existente entre los distintos «estratos» de la sociedad (científicos, técnicos, políticos y la opinión pública). Cada grupo opera con su propia percepción de la realidad, su lenguaje y sus prioridades, lo que crea mundos paralelos que rara vez se tocan.
Esto nos lleva a una de las ideas más frustrantes para los técnicos: la creencia de que es posible convencer a alguien solo con datos es, en muchos casos, una falacia.
«Cuando intentas convencer a alguien con argumentos respecto a un prejuicio que tiene, es imposible. Es un tema mental, es la disonancia cognitiva».
Cuando un dato choca con un interés o una creencia, lo más habitual no es cambiar de opinión, sino rechazar el dato. Esto explica por qué, a pesar de la evidencia sobre ciertos riesgos, se posponen las decisiones o se toman decisiones que van en direcciones contrarias. El problema no es la falta de conocimiento técnico, sino la enorme dificultad para comunicarlo de manera que sea aceptado eficazmente por quienes toman las decisiones y por la sociedad en su conjunto. Superar esta barrera mental es, quizás, el mayor desafío de todos.
Conclusión: reconstruir algo más que edificios y puentes.
Las lecciones de la DANA de 2024 nos obligan a conectar los puntos: los desastres son fallos sistémicos (como el queso suizo), cuyas debilidades se multiplican porque el clima ha cambiado las reglas del juego (no estacionariedad); la reconstrucción debe suponer una reinvención estratégica, no una copia; y las barreras humanas, alimentadas por la disonancia cognitiva, a menudo son más difíciles de superar que cualquier obstáculo técnico.
La verdadera lección, por tanto, no se limita a la hidráulica o al urbanismo. Se trata de cómo tomamos decisiones como sociedad frente a riesgos complejos y sistémicos. Se trata de nuestra capacidad para aprender, adaptarnos y actuar con valentía y visión de futuro.
Ahora que conocemos mejor las causas profundas del desastre, ¿estamos dispuestos como sociedad a adoptar las decisiones valientes que exige una reconstrucción inteligente o la urgencia nos hará tropezar de nuevo con la misma piedra?
En este audio hay ideas que os pueden servir para entender el problema.
Os dejo un vídeo que os puede ayudar a entender las ideas principales de este artículo.
Y por último, os dejo una intervención que tuve sobre este tema en el Colegio de Ingenieros de Caminos. Espero que os interese.
En el ámbito de la ingeniería y la gestión de la calidad, el diagrama de Pareto se ha consolidado como una herramienta esencial para la toma de decisiones y la mejora continua. Permite identificar los problemas más importantes, priorizar acciones y optimizar el uso de recursos.
La idea central se basa en la observación de que unos pocos factores tienen un impacto desproporcionado en los resultados, lo que se conoce como el principio 80/20. Por ejemplo, en una obra de construcción, unos pocos materiales concentran la mayor parte del coste, mientras que, en logística, unos pocos clientes generan la mayoría de las ventas.
Figura 2. Vilfredo Pareto (1848-1923). https://es.wikipedia.org/
2. Origen histórico
El concepto fue acuñado por el economista italiano Vilfredo Pareto (1848-1923), quien observó que aproximadamente el 80 % de la riqueza en Europa estaba en manos del 20 % de la población.
Décadas más tarde, el ingeniero y consultor de calidad Joseph M. Juran reconoció la aplicabilidad universal de esta distribución y acuñó la expresión «los pocos vitales y los muchos triviales (o útiles)», extendiendo su uso a la gestión empresarial y de calidad.
3. ¿Qué es un diagrama de Pareto?
Es un gráfico de barras en el que los datos se clasifican de mayor a menor importancia, de izquierda a derecha. Cada barra representa una categoría (por ejemplo, defectos, causas de fallo o tipos de no conformidades).
A menudo, se añade una línea de porcentaje acumulado que muestra qué porcentaje del problema total explican las categorías principales.
La diferencia con respecto a un histograma es clara: en el diagrama de Pareto, el eje horizontal representa categorías, mientras que en el histograma representa intervalos numéricos.
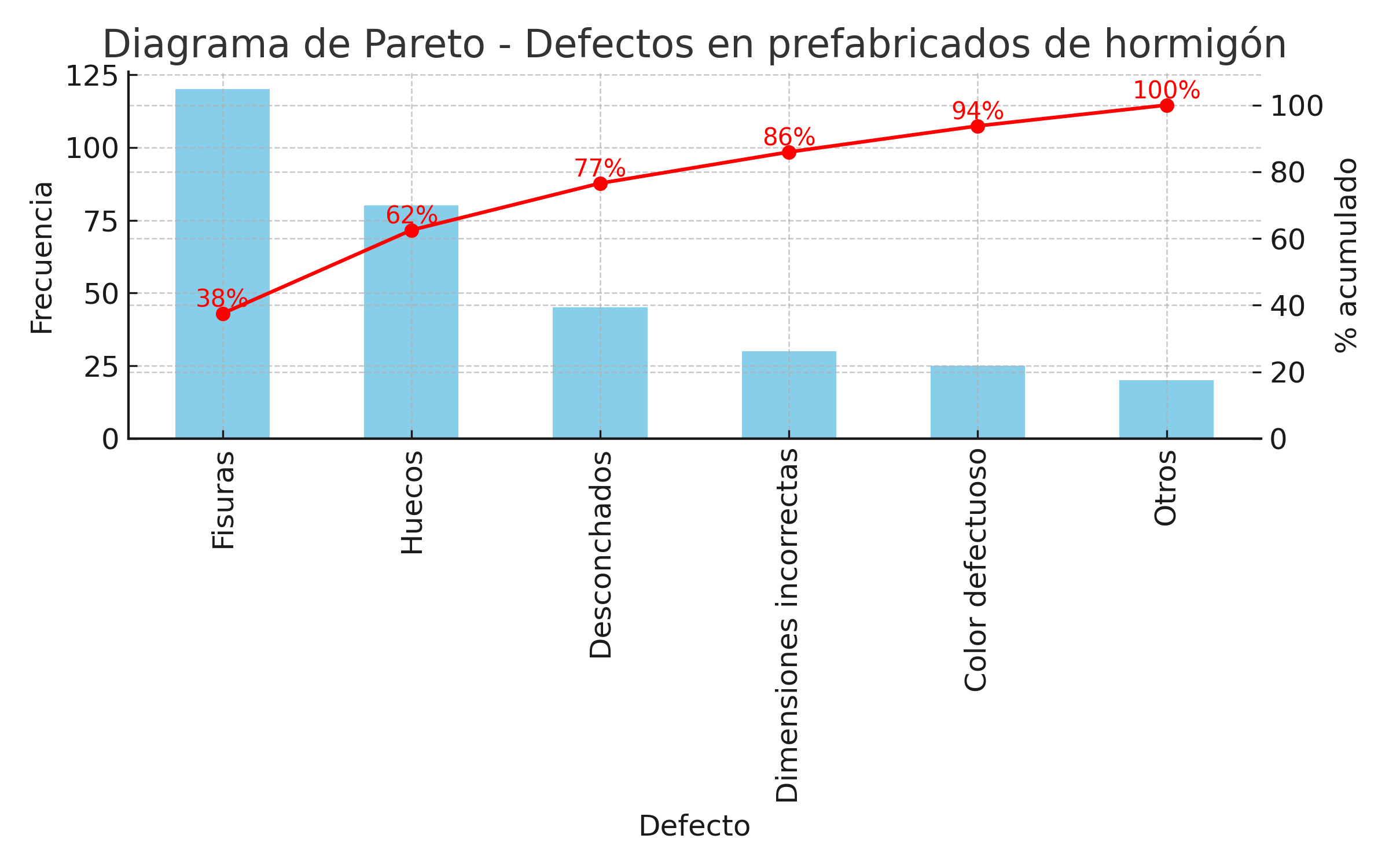
Figura 3. Diagrama de Pareto – Defectos en prefabricados de hormigón
4. Construcción paso a paso.
El procedimiento clásico consta de seis pasos:
Determinar cómo clasificar los datos (problemas, causas, defectos, costes, etc.).
Definir la métrica (frecuencia, valor monetario o frecuencia ponderada).
Recolectar datos en un periodo adecuado.
Agrupar y ordenar las categorías en orden descendente.
Calcular el porcentaje acumulado.
Dibujar el diagrama y distinguir cuáles son los pocos vitales.
Cuando se emplea el porcentaje acumulado, este debe coincidir con la escala principal para que el 100 % se sitúe a la misma altura que la suma de frecuencias o valores.
5. Importancia en la mejora continua.
El diagrama de Pareto no es un análisis estático, sino un proceso cíclico.
En la primera iteración, se identifican las categorías más críticas.
Tras actuar sobre ellas, un nuevo análisis muestra otras prioridades.
El ciclo se repite hasta que los problemas se vuelven residuales o insignificantes.
Este enfoque garantiza que los recursos se destinen a lo que realmente afecta a la calidad, la productividad o los costes.
6. Aplicaciones prácticas
Ingeniería civil: defectos en prefabricados de hormigón.
En una planta de prefabricados, se recopilaron datos sobre los defectos.
Fisuras: 120
Huecos: 80
Desconchados: 45
Dimensiones incorrectas: 30
Color defectuoso: 25
Otros: 20
El análisis de la Figura 3 muestra que las fisuras y los huecos representan más del 65 % de los defectos totales, por lo que constituyen los «puntos vitales» en los que hay que centrarse para mejorar.
Logística: gestión de inventarios en obra (análisis ABC).
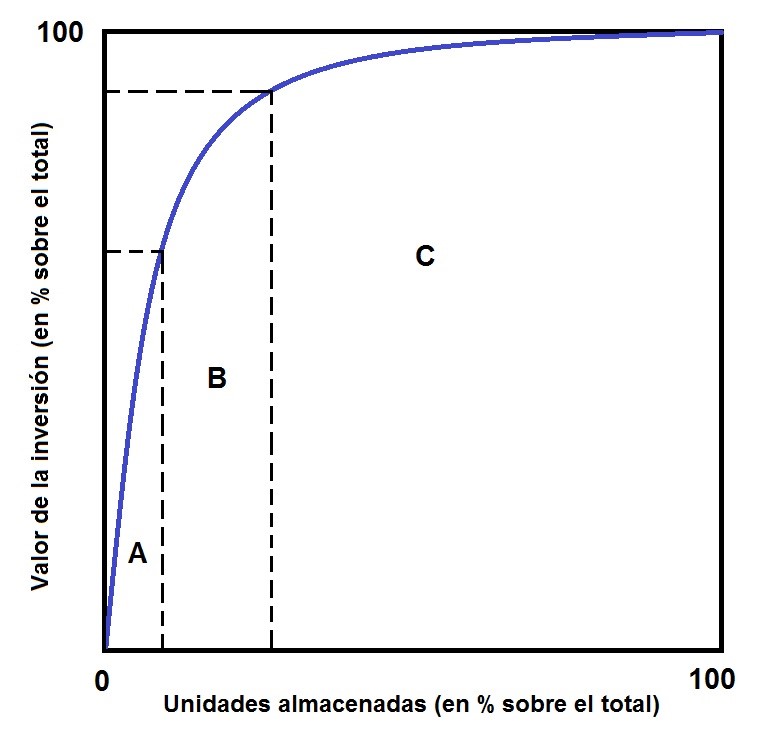
En el suministro de materiales de construcción, el análisis Pareto se traduce en el método ABC (Figura 4).
Para ello se clasifican según su valor de uso anual (podría ser cualquier otro periodo), agrupándolos de acuerdo con el coste de su gasto anual: cantidad utilizada (consumida, vendida, empleada, etc.) coste unitario (o precio unitario). Para ello se dividen los elementos en tres grupos:
Grupo A: Suponen un porcentaje alto de la inversión total, de forma que, controlando este grupo, se tiene controlado casi todo el almacén. Representa generalmente el 10 % de los artículos, estando su valor de uso entre el 60 % y el 80 % del total.
Grupo C: Son aquellos cuyo control es poco interesante, pues siendo muy numeroso, su valor es pequeño. Suele ser el 50-70 % del total de artículos, significando solo entre el 5-10 % del valor total de uso
Grupo B: Tienen una importancia en relación con el número de unidades del almacén parecida a la que tienen con referencia al valor total de la inversión del inventario. Abarca generalmente al 25 % de los artículos, y representa entre el 15-30 % del valor total de uso.
Figura 4. Método ABC para gestionar los inventarios
Por ejemplo:
Acero estructural: 40 000 €
Cemento: 30 000 €
Tuberías PVC: 12 000 €
Pintura: 6 000 €
Clavos y tornillería: 2 000 €
Otros: 1 000 €
La Figura 5 muestra que el acero y el cemento (el 20 % de los artículos) representan el 70 % del valor total. Estos materiales requieren un control de inventario estricto, mientras que los de bajo impacto se gestionan de manera más flexible.
Figura 5. Diagrama de Pareto – Inventario en obra
6.3 Otras aplicaciones destacadas.
Quejas de clientes: un pequeño grupo de problemas genera la mayoría de las reclamaciones.
Procesos productivos: unos pocos defectos causan la mayor parte de los reprocesos.
Mantenimiento: unas pocas averías originan la mayor parte del tiempo de inactividad.
Ventas: unos pocos clientes concentran la mayor parte de los ingresos.
7. Conclusión
El diagrama de Pareto es sencillo de apariencia, pero potente en resultados.
Facilita la visualización de las prioridades.
Permite concentrar los recursos en lo más importante.
Puede aplicarse en ingeniería civil, logística, producción, calidad, marketing y gestión empresarial.
La clave está en identificar los aspectos vitales y no dispersar esfuerzos en los triviales.
De izquierda a derecha: Julián Alcalá, Salvador Ivorra, Lorena Yepes, Tatiana García y Antonio Tomás.
Hoy, 6 de junio de 2025, ha tenido lugar la defensa de la tesis doctoral de Dª. Lorena Yepes Bellver, titulada “Multi-criteria optimization for sustainable design of post-tensioned concrete slab bridges using metamodels”, dirigida por el profesor Julián Alcalá González. La tesis ha obtenido la máxima calificación de sobresaliente «cum laude». A continuación, presentamos un pequeño resumen de la misma.
Esta tesis utiliza técnicas de modelización sustitutiva para optimizar los costes económicos y medioambientales en puentes losa de hormigón postesado hormigonado in situ. El objetivo principal de esta investigación es desarrollar una metodología sistemática que permita optimizar el diseño de puentes, reduciendo los costes, las emisiones de CO₂ y la energía necesaria para construir este tipo de puentes sin comprometer la viabilidad estructural o económica. El marco de optimización propuesto consta de dos fases secuenciales: la primera se centra en ampliar el espacio de búsqueda y la segunda intensifica la búsqueda de soluciones óptimas. El metamodelo basado en Kriging realiza una optimización heurística que da como resultado un diseño con emisiones de CO₂ significativamente menores que los diseños convencionales. El estudio revela que una relación de esbeltez de aproximadamente 1/30 arroja resultados óptimos, ya que se reduce el consumo de material y se mantiene la integridad estructural. Además, el aumento de la armadura pasiva compensa la reducción de hormigón y armadura activa, lo que da como resultado un diseño más sostenible. Por otra parte, se identifica una compensación entre costes y emisiones que muestra que un modesto aumento de los costes de construcción (menos del 1 %) puede reducir sustancialmente las emisiones de CO₂ (más del 2 %), lo que demuestra que el diseño de puentes sostenibles puede ser económicamente viable.
La investigación explora más a fondo la optimización de la energía incorporada en la construcción de pasos elevados de carreteras anuladas mediante el uso de muestreo por hipercubo latino y optimización basada en Kriging. La metodología permite identificar los parámetros críticos de diseño, como los altos coeficientes de esbeltez (en torno a 1/28), el uso mínimo de hormigón y armadura activa, y el aumento de la armadura pasiva para mejorar la eficiencia energética. Aunque en el estudio se emplearon Kriging y redes neuronales artificiales (RNA), Kriging demostró ser más eficaz a la hora de identificar óptimos locales, a pesar de que las redes neuronales ofrecen predicciones absolutas más precisas. Esto pone de manifiesto la eficacia de los modelos sustitutos a la hora de orientar las decisiones de diseño sostenible, incluso cuando los modelos no ofrecen predicciones absolutas perfectamente exactas.
En el contexto de la optimización de costes para puentes de losa postesada, el estudio demuestra el potencial del modelado sustitutivo combinado con la simulación del recocido. Los resultados muestran que el método de optimización basado en Kriging conduce a una reducción de costes del 6,54 %, principalmente mediante la minimización del uso de materiales, concretamente de hormigón en un 14,8 % y de acero activo en un 11,25 %. Estas reducciones en el consumo de material se consiguen manteniendo la integridad estructural y la capacidad de servicio del puente, lo que convierte al modelado sustitutivo en una herramienta práctica y eficaz para la optimización económica en el diseño de puentes.
El estudio también evalúa la forma de optimizar las emisiones de CO₂ en pasos elevados de carreteras pretensadas. Se identifican los parámetros óptimos de diseño, como grados de hormigón entre C-35 y C-40 MPa, profundidades del tablero entre 1,10 y 1,30 m, y anchuras de base entre 3,20 y 3,80 m. La red neuronal mostró las predicciones más precisas entre los modelos predictivos analizados, con los errores medios absolutos (MAE) y cuadrados medios (RMSE) más bajos. Estos resultados subrayan la importancia de seleccionar el modelo predictivo adecuado para optimizar las emisiones de CO₂ en el diseño de puentes y destacan el valor de utilizar modelos sustitutivos para mejorar la sostenibilidad en los proyectos de ingeniería civil.
Por último, la investigación integra la toma de decisiones multicriterio (MCDM) con la optimización basada en Kriging para evaluar y optimizar los diseños de puentes en relación con objetivos económicos, medioambientales y estructurales. El enfoque MCDM permite evaluar de manera más exhaustiva las alternativas de diseño al tener en cuenta las compensaciones entre coste, impacto ambiental y rendimiento estructural. Esta integración contribuye al desarrollo sostenible de las infraestructuras, ya que facilita la selección de diseños óptimos que se ajusten a los objetivos de sostenibilidad.
En conclusión, esta tesis demuestra que el modelado sustitutivo, que utiliza explícitamente el Kriging y redes neuronales artificiales, es un enfoque práctico para optimizar las dimensiones medioambiental y económica del diseño de puentes. El marco de optimización en dos fases que aquí se presenta proporciona una metodología eficiente desde el punto de vista computacional que permite identificar soluciones de diseño óptimas y sostenibles que cumplen las restricciones estructurales y económicas. Los resultados sugieren que la metodología es aplicable a proyectos de infraestructuras a gran escala y sentarán las bases para futuras investigaciones. Futuros estudios podrían investigar el uso de algoritmos y modelos de optimización adicionales para perfeccionar aún más el proceso de optimización y mejorar la aplicabilidad de estas metodologías en proyectos reales.
 La unidad experimental (UE) es el elemento central en el diseño y el análisis de experimentos comparativos. Se define como la entidad a la que se le puede asignar un tratamiento de forma independiente y sobre la cual se realizan las mediciones. La identificación correcta de la UE es fundamental, ya que la estimación de la variabilidad natural, conocida como error experimental, depende exclusivamente de la comparación entre unidades experimentales idénticas que reciben el mismo tratamiento.
La unidad experimental (UE) es el elemento central en el diseño y el análisis de experimentos comparativos. Se define como la entidad a la que se le puede asignar un tratamiento de forma independiente y sobre la cual se realizan las mediciones. La identificación correcta de la UE es fundamental, ya que la estimación de la variabilidad natural, conocida como error experimental, depende exclusivamente de la comparación entre unidades experimentales idénticas que reciben el mismo tratamiento.