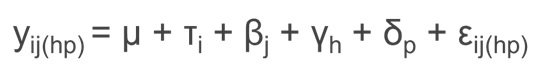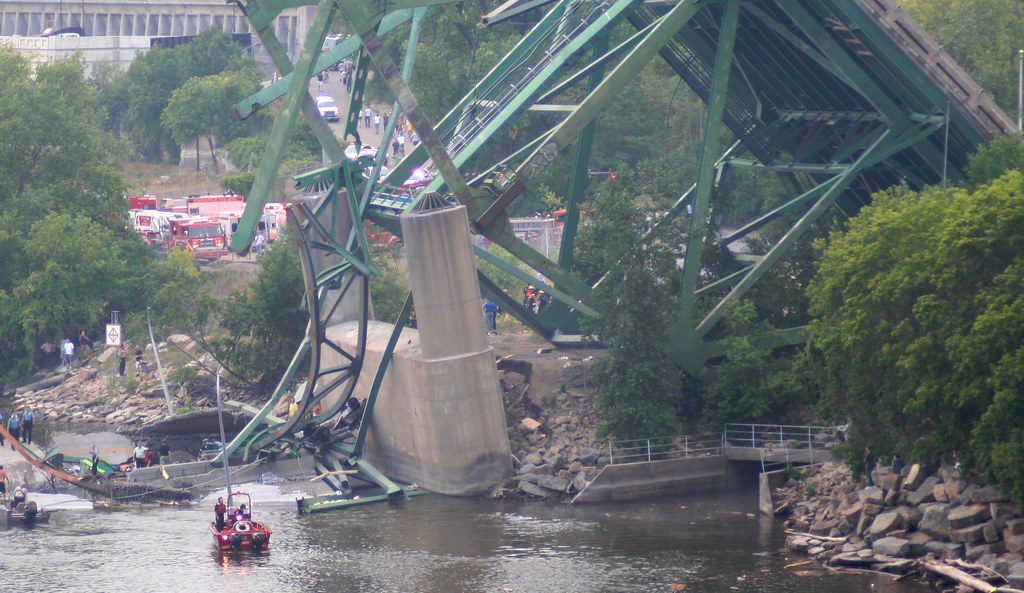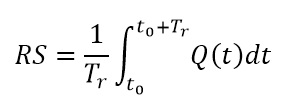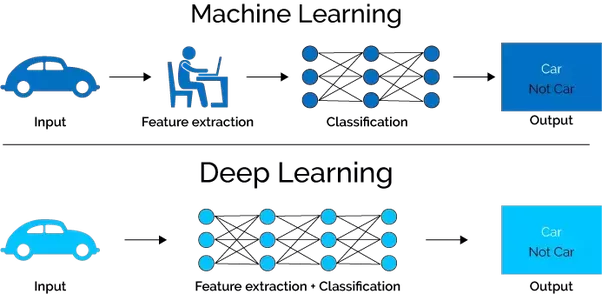Tengo el placer de anunciar mi participación el la IV Bienal Internacional de Ingeniería BIING20. En este caso, impartiré una conferencia sobre «Optimización aplicada a la gestión sostenible del mantenimiento de carreteras».
La Bienal Internacional de Ingeniería es un espacio académico dedicado a la difusión, integración y generación de nuevo conocimiento a partir de los resultados de investigación y de las actividades de consultoría desarrolladas por la comunidad académica y profesionales, además de conocer las nuevas tendencias en la Ingeniería y tecnología y los retos que tenemos para la innovación y la sustentabilidad.
Este evento, que organiza la facultad de Ingenierías (programa de ingeniería civil e ingeniería de sistemas) de la Universidad Cooperativa de Colombia Campus Ibagué – Espinal, fomenta el intercambio de saberes entre investigadores, profesores, estudiantes y actores del sector de la infraestructura física y la infraestructura tecnológica, a través de la presentación de los últimos avances investigativos y de innovación, tanto a nivel nacional como internacional, conducentes a la apropiación social del conocimiento científico y su transferencia a la sociedad.
La edición 2020 de la Bienal Internacional de Ingenierías contará con la participación de expertos reconocidos a nivel local, nacional e internacional, complementados con investigadores de la Universidad Cooperativa de Colombia de los diferentes campus.
A continuación os dejo el panel de conferenciantes y el programa completo por si os interesa.
Figura 1. Cuadrado grecolatino de orden cuatro. Wikipedia
Un cuadrado greco-latino, cuadrado de Euler o cuadrados latinos ortogonales de orden n se denomina, en matemáticas, a la disposición en una cuadrícula cuadrada n×n de los elementos de dos conjuntos S y T, ambos con n elementos, cada celda conteniendo un par ordenado (s, t), siendo s elemento de S y t de T, de forma que cada elemento de S y cada elemento de T aparezca exactamente una vez en cada fila y en cada columna y que no haya dos celdas conteniendo el mismo par ordenado. Si bien los cuadrados grecolatinos eran una curiosidad matemática, a mediados del siglo XX Fisher demostró su utilidad para el control de experimentos estadísticos.
El diseño de experimentos en cuadrado grecolatino constituye una extensión del cuadrado latino. En este caso se eliminan tres fuentes extrañas de variabilidad, es decir, se controlan tres factores de bloques y un factor de tratamiento. Se trata de un diseño basado en una matriz de «n» letras latinas y «n» letras griegas, de forma que cada letra latina aparece solo una vez al lado de cada letra griega. Lo interesante de este diseño es que se permite la investigación de cuatro factores (filas, columnas, letras latinas y letras griegas), cada una con «n» niveles en solo «n2» corridas. Se llama cuadrado grecolatino porque los cuatro factores involucrados se prueban en la misma cantidad de niveles, de aquí que se pueda escribir como un cuadro. En la Figura 1 se presenta el aspecto de los datos del diseño de orden cuatro. El inconveniente de este modelo es que su utilización es muy restrictiva. El análisis de la varianza permite comprobar las hipótesis de igualdad de letras latinas (tratamientos), de las filas, de las columnas y de las letras griegas.
Si a un cuadrado latino p x p se le superpone un segundo cuadrado latino n x n en el que los tratamientos se denotan con letras griegas, entonces los dos cuadrados tienen la propiedad de que cada letra griega aparece una y sólo una vez con cada letra latina. Este diseño permite controlar sistemáticamente tres fuentes de variabilidad extraña. Ello permite la investigación de cuatro factores (filas, columnas, letras latinas y letras griegas), cada una con p niveles en sólo n2 ensayos.
Por tanto, el diseño de experimentos en cuadrado grecolatino se caracteriza por lo siguiente:
Es un diseño con cuatro factores a n niveles
Se asume que no hay interacciones entre los factores
Requiere de n2 observaciones
Cada nivel de un factor aparece una vez con cada nivel de los otros factores
Se trata de la superposición de dos cuadrados latinos (ver Figura 2)
Figura 2. Superposición de dos cuadrados latinos
En un diseño en cuadrado greco-latino la variable respuesta yij(hp) viene descrita por la siguiente ecuación:
A continuación os presento un caso para aclarar la aplicabilidad de este diseño de experimentos. Se trata de averiguar si la resistencia característica del hormigón a flexocompresión (MPa) varía con cuatro dosificaciones diferentes. Para ello se han preparado amasadas en cuatro amasadoras diferentes, se han utilizado cuatro operarios de amasadora y los ensayos se han realizado en cuatro laboratorios diferentes. Los resultados se encuentran en la tabla que sigue. Se quiere analizar el diseño de experimentos en cuadrado grecolatino realizado.
En el caso que nos ocupa, la variable de respuesta de la resistencia característica del hormigón a flexocompresión (MPa). El factor que se quiere estudiar es la dosificación a cuatro niveles (A, B, C y D). El bloque I es el tipo de amasadora, con cuatro niveles (α, β, γ y δ). El bloque II es el operario de la amasadora, con cuatro niveles (1, 2, 3 y 4). El bloque III es el laboratorio, con cuatro niveles (las filas). Se supone que no hay interacción entre el factor y los bloques entre sí.
Lo que se quiere averiguar es si hay diferencias significativas entre las dosificaciones (el factor a estudiar). De paso, se desea saber si hay diferencias entre los laboratorios, los operarios y las amasadoras (los bloques).
Os paso un pequeño vídeo donde se explica, de forma muy resumida, este caso, tanto para SPSS como para MINITAB.
Os dejo otro vídeo donde también se explica este tipo de diseño de experimentos.
Referencias:
Gutiérrez, H.; de la Vara, R. (2004). Análisis y Diseño de Experimentos. McGraw Hill, México.
Vicente, MªL.; Girón, P.; Nieto, C.; Pérez, T. (2005). Diseño de Experimentos. Soluciones con SAS y SPSS. Pearson, Prentice Hall, Madrid.
Pérez, C. (2013). Diseño de Experimentos. Técnicas y Herramientas. Garceta Grupo Editorial, Madrid.
Figura 1. Desgraciadamente, no existe comida gratis. https://medium.com/@LeonFedden/the-no-free-lunch-theorem-62ae2c3ed10c
Después de años impartiendo docencia en asignaturas relacionadas con la optimización heurística de estructuras de hormigón, y tras muchos artículos científicos publicados y más aún en los que he sido revisor de artículos de otros grupos de investigación, siempre se plantea la misma pregunta: De todos los algoritmos que utilizamos para optimizar, ¿cuál es el mejor? ¿Por qué dice en su artículo que su algoritmo es el mejor para este problema? ¿Por qué no nos ponemos de acuerdo?
Para resolver esta cuestión, dos investigadores norteamericanos, David Wolpert y William Macready, publicaron en 1997 un artículo en el que establecieron un teorema denominado «No free lunch«, que, traducido, sería algo así como «no hay comida gratis». Dicho teorema establece que, por cada par de algoritmos de búsqueda, hay tantos problemas en los que el primer algoritmo es mejor que el segundo como problemas en los que el segundo algoritmo es mejor que el primero.
Este teorema revolucionó la forma de entender el rendimiento de los algoritmos. Incluso una búsqueda aleatoria en el espacio de soluciones podría dar mejores resultados que cualquier algoritmo de búsqueda. La conclusión es que no existe un algoritmo que sea universalmente mejor que los demás, pues siempre habrá casos en los que funcione peor que otros, lo que significa que todos ellos se comportarán igual de bien (o de mal) en promedio.
De hecho, podría decirse que un experto en algoritmos genéticos podría diseñar un algoritmo genético más eficiente que, por ejemplo, un recocido simulado, y viceversa. Aquí el arte y la experiencia en un problema y en una familia de algoritmos determinados suelen ser decisivos. En la Figura 2 se puede ver cómo un algoritmo muy especializado, que conoce bien el problema, puede mejorar su rendimiento, pero pierde la generalidad para usarse en cualquier tipo de problema de optimización distinto del que se diseñó.
Figura 2. El uso del conocimiento del problema puede mejorar el rendimiento, pero a costa de la generalidad. https://medium.com/@LeonFedden/the-no-free-lunch-theorem-62ae2c3ed10c
¿Qué consecuencias obtenemos de este teorema? Lo primero, una gran decepción, pues hay que abandonar la idea del algoritmo inteligente capaz de optimizar cualquier problema. Lo segundo, que es necesario incorporar en el algoritmo cierto conocimiento específico del problema, lo cual equivale a una «carrera armamentística» para cada problema de optimización. Se escriben y escribirán miles de artículos científicos en los que un investigador demuestre que su algoritmo es mejor que otro para un determinado problema.
Una forma de resolver este asunto de incorporar conocimiento específico del problema es el uso de la inteligencia artificial en apoyo de las metaheurísticas. Nuestro grupo de investigación está abriendo puertas en este sentido, incorporando «deep learning» en el diseño de algoritmos (Yepes et al., 2020; García et al., 2020a; 2020b) o bien redes neuronales (García-Segura et al., 2017). Incluso, en este momento, me encuentro como editor de un número especial de la revista Mathematics (primer decil del JCR) denominado: “Deep Learning and Hybrid-Metaheuristics: Novel Engineering Applications”, al cual os invito a enviar vuestros trabajos de investigación.
Si nos centramos en un tipo de problema determinado, por ejemplo, la optimización de estructuras (puentes, pórticos de edificación, muros, etc.), el teorema nos indica que necesitamos gente formada y creativa para optimizar el problema concreto al que nos enfrentamos. Es por ello que no existen programas comerciales eficientes capaces de adaptarse a cualquier estructura para optimizarla. Tampoco son eficientes las herramientas generales, «tools», que ofrecen algunos programas, como Matlab, para su uso inmediato e indiscriminado.
Por tanto, no se podrá elegir entre dos algoritmos solo basándose en el buen desempeño que obtuvieron anteriormente en un problema determinado, pues en el siguiente problema pueden optimizar de forma deficiente. Por tanto, se exige conocimiento intrínseco de cada problema para optimizarlo. Es por ello que, por ejemplo, un experto matemático o informático no puede, sin más, dedicarse a optimizar puentes atirantados.
Tengo el placer de compartir con todos vosotros, de forma totalmente abierta, un libro que he editado junto con el profesor de la Universidad de Zaragoza, José María Moreno Jiménez. La labor de editar libros científicos es una oportunidad para seleccionar a los autores y temas que destacan en un ámbito determinado. En este caso, la optimización de la toma de decisiones.
Además, resulta gratificante ver que el libro se encuentra editado en abierto, por lo que cualquiera de vosotros os lo podéis descargar sin ningún tipo de problema en esta entrada del blog. También os lo podéis descargar, o incluso pedirlo en papel, en la página web de la editorial MPDI: https://www.mdpi.com/books/pdfview/book/2958
Decision-making is one of the distinctive activities of the human being; it is an indication of the degree of evolution, cognition, and freedom of the species. Until the end of the 20th century, scientific decision-making was based on the paradigms of substantive rationality (normative approach) and procedural rationality (descriptive approach). Since the beginning of the 21st century and the advent of the Knowledge Society, decision-making has been enriched with new constructivist, evolutionary, and cognitive paradigms that aim to respond to new challenges and needs; especially the integration into formal models of the intangible, subjective, and emotional aspects associated with the human factor, and the participation in decision-making processes of spatially distributed multiple actors that intervene in a synchronous or asynchronous manner. To help address and resolve these types of questions, this book comprises 13 chapters that present a series of decision models, methods, and techniques, along with their practical applications in economics, engineering, and the social sciences. The chapters collect the papers included in the “Optimization for Decision Making” Special Issue of the Mathematics journal (2019, 7(3)), ranked in the first decile of the JCR 2019 in the Mathematics category. We would like to thank both the MDPI publishing editorial team for their excellent work and the 47 authors who have collaborated in its preparation. The papers cover a wide spectrum of issues related to the scientific resolution of problems, in particular decision-making, optimization, metaheuristics, simulation, and multi-criteria decision-making. We hope that the papers, with their undoubted mathematical content, can be of use to academics and professionals from the many branches of knowledge (philosophy, psychology, economics, mathematics, decision science, computer science, artificial intelligence, neuroscience, and more) that have, from such diverse perspectives, approached the study of decision-making, an essential aspect of human life and development.
Víctor Yepes, José María Moreno-Jiménez
Editors
About the Editors
Víctor Yepes, Full Professor of Construction Engineering, holds a Ph.D. degree in civil engineering. He serves at the Department of Construction Engineering, Universitat Politecnica de Valencia, Valencia, Spain. He has been the Academic Director of the M.S. studies in concrete materials and structures since 2007 and a Member of the Concrete Science and Technology Institute (ICITECH). He is currently involved in several projects related to the optimization and life-cycle assessment
of concrete structures as well as optimization models for infrastructure asset management. He is currently teaching courses in construction methods, innovation, and quality management. He authored more than 250 journal and conference papers, including more than 100 published in a journal listed in JCR. He acted as an Expert in the evaluation of project proposals for the Spanish Ministry of Technology and Science, and he is the Main Researcher on many projects. He currently serves as the Editor-in-Chief of the International Journal of Construction Engineering and Management and a member of the editorial board of 12 international journals (Structure & Infrastructure Engineering, Structural Engineering and Mechanics, Mathematics, Sustainability, Revista de la Construcción, Advances in Civil Engineering, and Advances in Concrete Construction, among others).
José María Moreno-Jiménez, Full Professor of Operations Research and Multicriteria Decision Making, received degrees in mathematics and economics, as well as a Ph.D. in applied mathematics, from the University of Zaragoza, Spain, where he has been teaching since 1980–1981. He has been the Head of the Quantitative Methods Area in the Faculty of Economics and Business of the University of Zaragoza from 1997, the Chair of the Zaragoza Multicriteria Decision Making Group from 1996, a member of the Advisory Board of the Euro Working Group on Decision Support Systems from 2017, and an Honorary Member of the International Society on Applied Economics ASEPELT from 2019. He has also been the President of this international scientific society (2014–2018) and the Coordinator of the Spanish Multicriteria Decision Making Group (2012–2015). His research interests are in the general area of Operations Research theory and practice, with an emphasis on multicriteria decision making, electronic democracy/cognocracy, performance analysis, and industrial and technological diversification. He has published more than 250 papers in leading scientific journals and books, and is a member of the Editorial Board of several national and international journals.
Figura 1. Colapso del puente I-35W en Minneapolis. https://thestartupgrowth.com/2019/02/21/structural-health-monitoring-market-driven-by-rapid-expansion-in-the-infrastructure-sector-till-2024/
Una noticia publicada el 9 de diciembre de 2018 en El País, con el siguiente titular: “Fomento admite que hay 66 puentes con graves problemas de seguridad”, suscitó cierta inquietud en la opinión pública sobre la seguridad de nuestros puentes. Esta inquietud irrumpió en agosto de ese mismo año con el derrumbe de un puente en Génova (Italia). Pero los ejemplos no quedan aquí. Podríamos hablar de la sustitución de los cables del Puente Fernando Reig, en Alcoy, o del Puente del Centenario, en Sevilla. O del derribo del puente Joaquín Costa, en Madrid. Ejemplos los tenemos en todo el mundo. En cualquier caso, estamos hablando de cifras millonarias, de cortes de tráfico, de pérdidas humanas, por poner algunas consecuencias sobre la mesa.
Los puentes son componentes críticos de la infraestructura, pues su correcto funcionamiento es básico para la resiliencia de nuestros entornos urbanos. Sin embargo, un gran número de infraestructuras están llegando al final de su vida útil al mismo tiempo. De hecho, se espera que la vida útil de muchos puentes sea menor que la proyectada debido al deterioro continuo provocado por el incremento del tráfico y de los impactos ambientales.Esto constituye una auténtica bomba de relojería (Thurlby, 2013), que, junto al reto de la reducción de los impactos ambientales, es razón más que suficiente para preocuparnos de mejorar el mantenimiento de nuestros puentes. De hecho, ya hemos comentado en un artículo anterior un concepto estrechamente relacionado con este: la «crisis de las infraestructuras«. Yo me atrevería a afirmar algo que puede parecer muy duro: el derrumbe de nuestra civilización será paralelo al de las infraestructuras que le dan soporte.
Hoy día los gestores de las infraestructuras tienen ante sí un reto importante consistente en mantenerlas en un estado aceptable con presupuestos muy limitados. De hecho, la inspección de los puentes, su mantenimiento y reparación constituyen tareas rutinarias necesarias para mantener dichas infraestructuras en buenas condiciones (Tong et al., 2019). Sin embargo, el problema se vuelve grave cuando una parte significativa del parque de infraestructuras está próxima al final de su vida útil. Y lo que aún es peor, cuando existen riesgos de alto impacto y de baja probabilidad que pueden afectar gravemente a las infraestructuras. Resolver este problema es complicado, pues no se presta fácilmente a la exploración con los instrumentos analíticos y de previsión tradicionales.
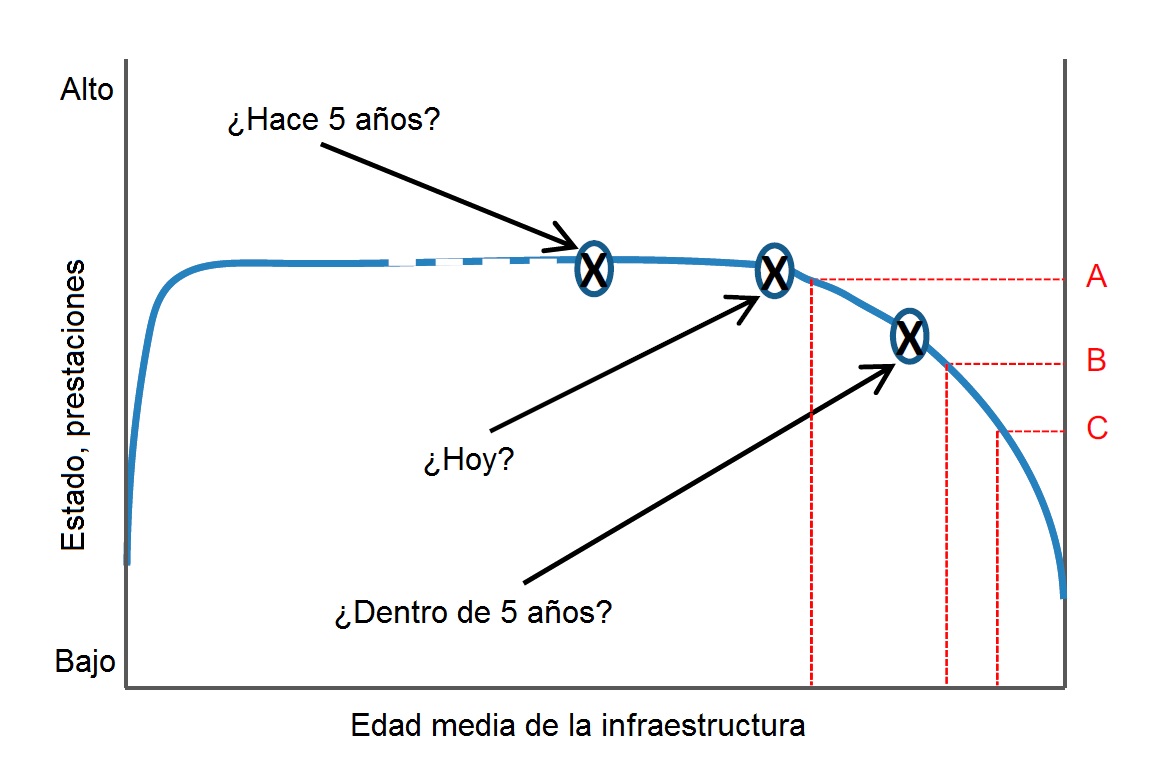
El estado o deterioro de una infraestructura sigue un comportamiento similar, pero invertido, al de la llamada «curva de la bañera«, que es una gráfica que representa los fallos durante el periodo de vida útil de un sistema o de una máquina. En este caso, según vemos en la Figura 2, el estado de la infraestructura o las prestaciones de la infraestructura permanecen altos durante un periodo de tiempo, hasta que empiezan a decaer. Para los gestores es necesario conocer el comportamiento de las infraestructuras para tomar decisiones. Sin embargo, muchas veces desconocen en qué posición de la curva se encuentran y, lo que es peor, a qué ritmo se va a deteriorar. Por ejemplo, en la Figura 2 podemos ver que las caídas en las prestaciones de A a B o de B a C son similares, pero la velocidad de deterioro difiere mucho. Y lo que es peor de todo, llega un momento en el que la caída de las prestaciones ocurre de forma muy acelerada, sin capacidad de reacción por parte de los gestores. Por eso se ha utilizado el símil de la «bomba de relojería».
Figura 2. Estado o prestaciones de una infraestructura (Thurlby, 2013)
La gestión y el mantenimiento de los puentes están empezando a ser un problema de magnitud tal que resulta más que preocupante. Algunos datos son un ejemplo de ello: en el año 2019, 47000 puentes de los puentes en Estados Unidos, (más del 20% del total) presentan deficiencias estructurales (American Road & Transportation Builders Association, 2019); en Reino Unido, más de 3000 puentes estaban por debajo de los estándares y requerían reparación (RAC Foundation, 2019). Estos son buenos argumentos para prolongar la vida útil de los puentes.
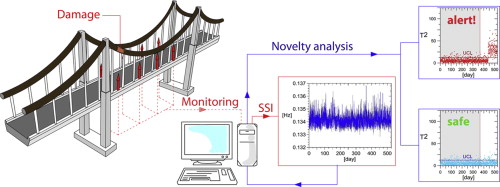
Una de las tecnologías para mejorar la gestión y el mantenimiento de los puentes es la vigilancia de su estado estructural (structural health monitoring, SHM), que busca optimizar el comportamiento de la estructura mediante el aprendizaje de los datos obtenidos a lo largo de su vida útil, a partir de su monitorización (Figura 3). Estos datos sirven para actualizar los modelos y comprobar el estado en que se encuentra la estructura, lo que permite minimizar la incertidumbre de los parámetros empleados en los modelos. Sin embargo, aún no se ha resuelto completamente el paso de la obtención de los datos del puente en tiempo real a la toma de decisiones en la gestión y mantenimiento de los puentes.
Figura 3. Structural health monitoring. https://thestartupgrowth.com/2019/02/21/structural-health-monitoring-market-driven-by-rapid-expansion-in-the-infrastructure-sector-till-2024/
En un artículo anterior se explicó el concepto de gemelos digitales (digital twins). Estos modelos, actualizados constantemente mediante la monitorización del puente, permitirían conocer en tiempo real su estado estructural y predecir su comportamiento ante determinadas circunstancias. Esta información sería clave para tomar decisiones en la gestión y el mantenimiento del puente.
Las preguntas clave que deberíamos responder serían las siguientes: ¿Es el puente seguro? ¿cuánto tiempo durará el puente seguro? ¿cuál es el comportamiento estructural actual del puente? ¿cuándo y cómo deberemos intervenir en el puente?
La respuesta a estas preguntas no es tan evidente como podría parecer a simple vista. Los gestores de infraestructuras deberían ser capaces de comprender y valorar, en su justa medida, los resultados estructurales de los modelos cuyos datos se actualizan en tiempo real. La dificultad radica en conocer no solo los datos, sino también las causas subyacentes a los cambios en el comportamiento estructural. Una ayuda son las técnicas procedentes de la inteligencia artificial, como el aprendizaje profundo, que permiten interpretar ingentes cantidades de datos e identificar patrones y correlaciones entre dichos datos. En un artículo anterior hablamos de este tema. Por otra parte, la actualización de los datos procedentes de la vigilancia de los puentes debería ser automática y en tiempo real. Aquí vuelve a cobrar importancia la inteligencia artificial, aunque nunca debería suplantar el conocimiento ingenieril que permite interpretar los resultados generados por los algoritmos.
Por otra parte, la modelización del riesgo y de la resiliencia es una labor necesaria para comprender la vulnerabilidad de las infraestructuras. De esta forma, seríamos capaces de desarrollar estrategias de mitigación que podrían complementar las estrategias de gestión del deterioro explicadas anteriormente.
Por tanto, existe un auténtico salto entre la investigación dedicada a la monitorización en tiempo real de los puentes y la toma de decisiones para su gestión y mantenimiento. Los gemelos digitales, apoyados en los actuales desarrollos tecnológicos como el «Internet de las cosas«, deberían permitir el paso de la investigación y el desarrollo a la innovación directamente aplicable a la realidad de la gestión de las infraestructuras.
THURLBY, R. (2013). Managing the asset time bomb: a system dynamics approach. Proceedings of the Institution of Civil Engineers – Forensic Engineering, 166(3):134-142.
TONG, X.; YANG, H.; WANG, L.; MIAO, Y. (2019). The development and field evaluation of an IoT system of low-power vibration for bridge health monitoring, Sensors 19(5):1222.
Hace unos días tuvimos la ocasión de presentar una comunicación en la segunda edición de «International Conference on Innovative Applied Energy (IPC’20), que si bien iba a ser presencial en Cambridge (Reino Unido), al final se tuvo que realizar en línea por culpa de la pandemia. A continuación os dejo la presentación que hicimos y un resumen de la misma. Espero que os sea de interés.
Referencia:
SALAS, J.; YEPES, V. (2020). UPSS, a multi-level framework for improved resilient regional planning.Proceedings of the Second Edition of the International Conference on Innovative Applied Energy (IPC’20), 15-16 September, Cambridge, United Kingdom. ISBN (978-1-912532-18-6).
Figura 1. https://www.un.org/sustainabledevelopment/es/2015/09/infraestructura-innovacion-e-industrias-inclusivas-claves-para-el-desarrollo/
La resiliencia es un concepto que viene del mundo de la psicología y representa la capacidad para adaptarse de forma positiva frente a situaciones adversas. Proviene del latín resilio, «volver atrás, volver de un salto, resaltar, rebotar». En el campo de la mecánica, la resiliencia sería la capacidad de un material para recuperar su forma inicial después de haber sido deformado por una fuerza. En la ecología, un sistema es resiliente si puede tolerar una perturbación sin colapsar a un estado completamente distinto, controlado por otro conjunto de procesos. En un entorno tecnológico, este término se relaciona con la capacidad de un sistema de soportar y recuperarse ante desastres y perturbaciones. En este artículo vamos a indagar en el concepto de resiliencia de las infraestructuras.
Así, dentro de los objetivos de desarrollo sostenible de Naciones Unidas (Figura 1), encontramos el Objetivo 9: Construir infraestructuras resilientes, provomer la industrialización sostenible y fomentar la innovación. En efecto, las infraestructuras deben hacer frente al crecimiento de la población, pero también a los crecientes peligros físicos (cinéticos) como el terrorismo, o los asociados al clima extremo y los desastres naturales. La frecuencia y gravedad de estos eventos extremos se prevén crecientes, y, por tanto, es más que previsible un aumento en los costes e impacto humano. Además, debido a la cada vez más informatización y digitalización de las infraestructuras, el riesgo de ataques informáticos a las infraestructuras es más que evidente.
La resiliencia puede asociarse con cuatro atributos: robustez, que es la capacidad para resistir un evento extremo sin que el fracaso en la funcionalidad sea completo; rapidez, que sería la capacidad de recuperarse de forma eficiente y efectiva; la redundancia, que sería la reserva de componentes o de sistemas estructurales sustitutivos; y el ingenio, que sería la eficiencia en la identificación de problemas, priorizando soluciones y movilizando recursos para su solución (Bruneau et al., 2003).
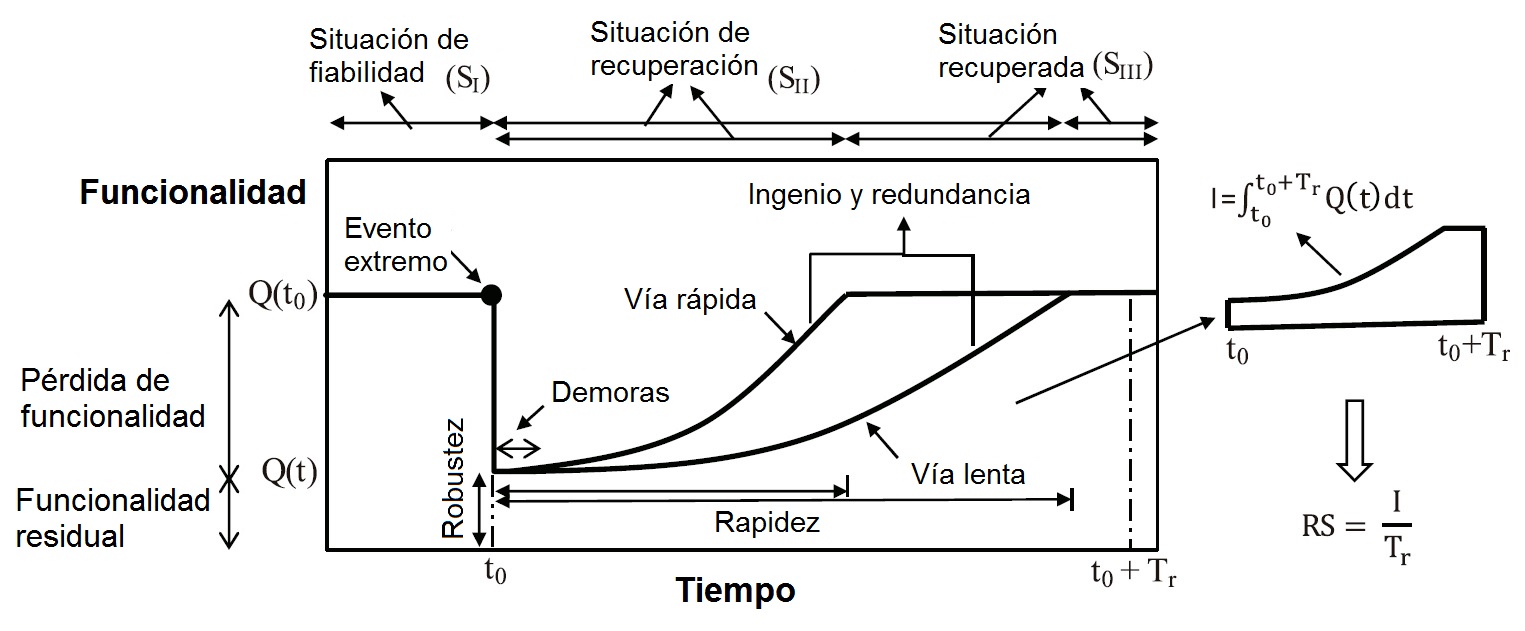
Matemáticamente, se puede evaluar la resiliencia integrando la curva de funcionalidad a lo largo del tiempo (ver Figura 2).
donde Q(t) es la funcionalidad; t0 es el momento en el que ocurre el evento extremo y Tr es el horizonte hasta donde se estudia la funcionalidad.
Figura 2. Valoración de la resiliencia tras un evento extremo (Anwar et al., 2019)
En la Figura 2 se pueden observar los tres estados correspondientes con la funcionalidad. En la situación de fiabilidad, la infraestructura se encuentra con la funcionalidad de referencia, previo al evento extremo. La situación de recuperación comienza tras la ocurrencia del evento extremo, con una pérdida de funcionalidad dependiente de la robustez de la infraestructura, y con una recuperación que depende de los esfuerzos realizados en la reparación, que puede ser rápida o lenta en función del ingenio o la creatividad en las soluciones propuestas, así como de la redundancia de los sistemas previstos. Por último, la situación recuperada es la que ocurre cuando la funcionalidad vuelve a ser la de referencia.
Se comprueba en la Figura 2 cómo una infraestructura pasa de una funcionalidad de referencia a una residual tras el evento extremo. Tras el evento, puede darse una demora en la recuperación de la funcionalidad debido a las tareas de inspección, rediseño, financiación, contratación, permisos, etc.). La recuperación completa de la funcionalidad depende de la forma en la que se han abordado las tareas de reparación. Es fácil verificar que la resiliencia se puede calcular integrando la curva de recuperación de la funcionalidad desde la ocurrencia del evento extremo hasta la completa recuperación, dividiendo dicho valor por el tiempo empleado en dicha recuperación.
Este modelo simplificado permite establecer las pautas para mejorar la resiliencia de una infraestructura:
a) Incrementando la robustez de la infraestructura, es decir, maximizar su funcionalidad residual tras un evento extremo.
b) Acelerando las actividades de recuperación de la funcionalidad de la infraestructura.
En ambos casos, es necesario concebir la infraestructura desde el principio con diseños robustos, con sistemas redundantes y con una previsión de las tareas de reparación necesarias.
Con todo, la capacidad de recuperación comprende cuatro dimensiones interrelacionadas: técnica, organizativa, social y económica (Bruneau et al., 2003). La dimensión técnica de la resiliencia se refiere a la capacidad de los sistemas físicos (incluidos los componentes, sus interconexiones e interacciones, y los sistemas enteros) para funcionar a niveles aceptables o deseables cuando están sujetos a los eventos extremos. La dimensión organizativa de la resiliencia se refiere a la capacidad de las organizaciones que gestionan infraestructuras críticas y tienen la responsabilidad de tomar decisiones y adoptar medidas que contribuyan a lograr la resiliencia descrita anteriormente, es decir, que ayuden a lograr una mayor solidez, redundancia, ingenio y rapidez. La dimensión social de la resiliencia consiste en medidas específicamente diseñadas para disminuir los efectos de los eventos extremos por parte de la población debido a la pérdida de infraestructuras críticas. Análogamente, la dimensión económica de la resiliencia se refiere a la capacidad de reducir tanto las pérdidas directas e indirectas de los eventos extremos.
El problema de estas cuatro dimensiones se pueden sumar de forma homogénea, con interrelaciones entre ellas. El reto consiste en cuantificar y medir la resiliencia en todas sus dimensiones, así como sus interrelaciones. Se trata de un problema de investigación de gran trascendencia y complejidad, que afecta al ciclo de vida de las infraestructuras desde el inicio de la planificación (Salas y Yepes, 2020).
Referencias:
ANWAR, G.A.; DONG, Y.; ZHAI, C. (2020). Performance-based probabilistic framework for seismic risk, resilience, and sustainability assessment of reinforced concrete structures. Advances in Structural Engineering, 23(7):1454-1457.
BRUNEAU, M.; CHANG, S.E.; EGUCHI, R.T. et al. (2003). A framework to quantitatively assess and enhance the seismic resilience of communities. Earthquake Spectra 19(4): 733–752.
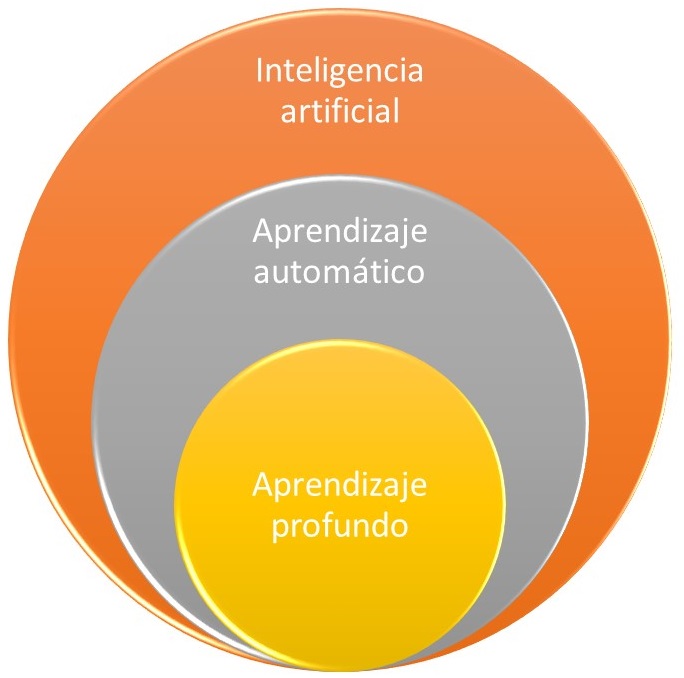
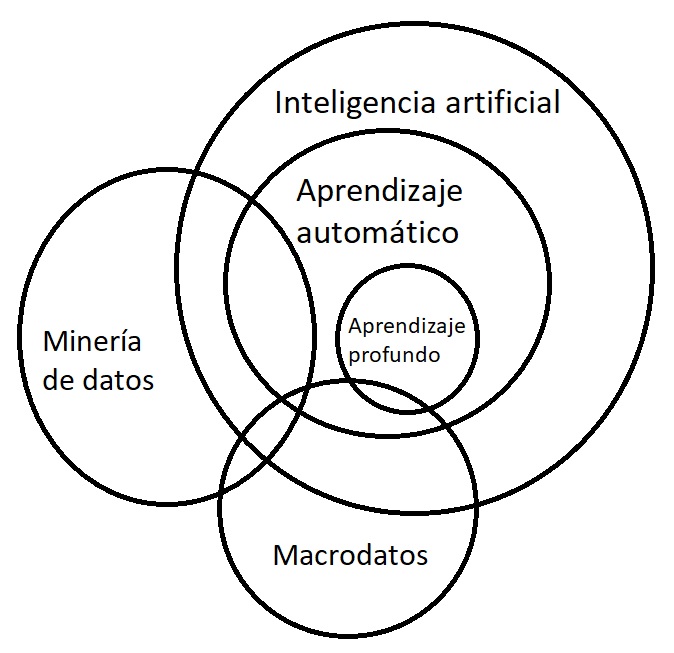
Figura 1. Relación de pertenencia entre la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo
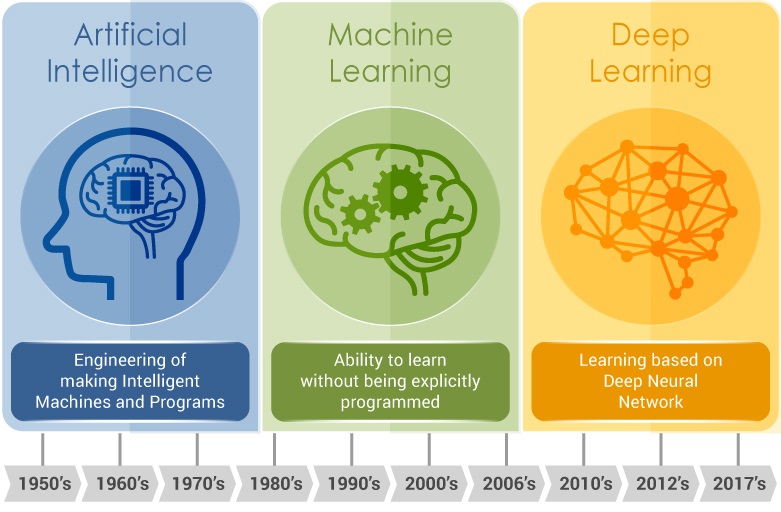
En este artículo vamos a esbozar las posibilidades de la inteligencia artificial en la optimización de estructuras, en particular, el uso del aprendizaje profundo. El aprendizaje profundo (deep learning, DL) constituye un subconjunto del aprendizaje automático (machine learning, ML), que a su vez lo es de la inteligencia artificial (ver Figura 1). Si la inteligencia artificial empezó sobre los años 50, el aprendizaje automático surgió sobre los 80, mientras que el aprendizaje profundo nació en este siglo XXI, a partir del 2010, con la aparición de grandes superordenadores y por el aumento de los datos accesibles. Como curiosidad, uno de los grandes hitos del DL se produjo en 2012, cuando Google fue capaz de reconocer un gato entre los más de 10 millones de vídeos de Youtube, utilizando para ello 16000 ordenadores. Ahora serían necesarios muchos menos medios.
En cualquiera de estos tres casos, estamos hablando de sistemas informáticos capaces de analizar grandes cantidades de datos (big data), identificar patrones y tendencias y, por tanto, predecir de forma automática, rápida y precisa. De la inteligencia artificial y su aplicabilidad a la ingeniería civil ya hablamos en un artículo anterior.
Figura 2. Cronología en la aparición de los distintos tipos de algoritmos de inteligencia artificial. https://www.privatewallmag.com/inteligencia-artificial-machine-deep-learning/
Si pensamos en el cálculo estructural, utilizamos modelos, más o menos sofistificados, que permiten, si se conocen con suficiente precisión las acciones, averiguar los esfuerzos a los que se encuentran sometidos cada uno de los elementos en los que hemos dividido una estructura. Con dichos esfuerzos se identifican una serie de estados límite, que son un conjunto de situaciones potencialmente peligrosas para la estructura y comparar si la capacidad estructural del elemento analizado, dependiente de las propiedades geométricas y de sus materiales constituyentes, supera el valor último de la solicitación a la que, bajo cierta probabilidad, puede llegar a alcanzar el elemento estructural analizado.
Estos métodos tradicionales emplean desde hipótesis de elasticidad y comportamiento lineal, a otros modelos con comportamiento plástico o no lineales más complejos. Suele utilizarse, con mayor o menos sofisticación, el método de los elementos finitos (MEF) y el método matricial de la rigidez. En definitiva, en determinados casos, suelen emplearse los ordenadores para resolver de forma aproximada, ecuaciones diferenciales parciales muy complejas, habituales en la ingeniería estructural, pero también en otros campos de la ingeniería y la física. Para que estos sistemas de cálculo resulten precisos, es necesario alimentar los modelos con datos sobre materiales, condiciones de contorno, acciones, etc., lo más reales posibles. Para eso se comprueban y calibran estos modelos en ensayos reales de laboratorio (Friswell y Mottershead, 1995). De alguna forma, estamos retroalimentando de información al modelo, y por tanto «aprende».
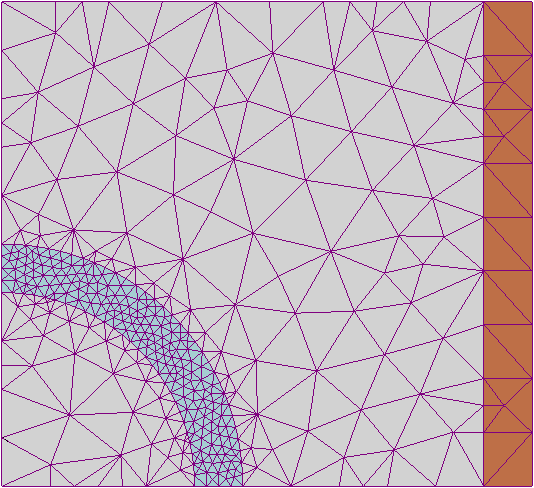
Figura 2. Malla 2D de elementos finitos, más densa alrededor de la zona de mayor interés. Wikipedia.
Si analizamos bien lo que hacemos, estamos utilizando un modelo, más o menos complicado, para predecir cómo se va a comportar la estructura. Pues bien, si tuviésemos una cantidad suficiente de datos procedentes de laboratorio y de casos reales, un sistema inteligente extraería información y sería capaz de predecir el resultado final. Mientras que la inteligencia artificial debería alimentarse de una ingente cantidad de datos (big data), el método de los elementos finitos precisa menor cantidad de información bruta (smart data), pues ha habido una labor previa muy concienzuda y rigurosa, para intentar comprender el fenómeno subyacente y modelizarlo adecuadamente. Pero, en definitiva, son dos procedimientos diferentes que nos llevan a un mismo objetivo: diseñar estructuras seguras. Otro tema será si éstas estructuras son óptimas desde algún punto de vista (economía, sostenibilidad, etc.).
La optimización de las estructuras constituye un campo científico donde se ha trabajado intensamente en las últimas décadas. Debido a que los problemas reales requieren un número elevado de variables, la resolución exacta del problema de optimización asociado es inabordable. Se trata de problemas NP-hard, de elevada complejidad computacional, que requiere de metaheurísticas para llegar a soluciones satisfactorias en tiempos de cálculo razonables.
Una de las características de la optimización mediante metaheurísticas es el elevado número de iteraciones en el espacio de soluciones, lo cual permite generar una inmensa cantidad de datos para el conjunto de estructuras visitadas. Es el campo ideal para la inteligencia artificial, pues permite extraer información para acelerar y afinar la búsqueda de la solución óptima. Un ejemplo de este tipo es nuestro trabajo (García-Segura et al., 2017) de optimización multiobjetivo de puentes cajón, donde una red neuronal aprendía de los datos intermedios de la búsqueda y luego predecía con una extraordinaria exactitud el cálculo del puente, sin necesidad de calcularlo. Ello permitía reducir considerablemente el tiempo final de computación.
Sin embargo, este tipo de aplicación es muy sencilla, pues solo ha reducido el tiempo de cálculo (cada comprobación completa de un puente por el método de los elementos finitos es mucho más lenta que una predicción con una red neuronal). Se trata ahora de dar un paso más allá. Se trata de que la metaheurística sea capaz de aprender de los datos recogidos utilizando la inteligencia artificial para ser mucho más efectiva, y no solo más rápida.
Tanto la inteligencia artificial como el aprendizaje automático no son una ciencia nueva. El problema es que sus aplicaciones eran limitadas por la falta de datos y de tecnologías para procesarlas de forma rápida y eficiente. Hoy en día se ha dado un salto cualitativo y se puede utilizar el DL, que como ya hemos dicho es una parte del ML, pero que utiliza algoritmos más sofisticados, construidos a partir del principio de las redes neuronales. Digamos que el DL (redes neuronales) utiliza algoritmos distintos al ML (algoritmos de regresión, árboles de decisión, entre otros). En ambos casos, los algoritmos pueden aprender de forma supervisada o no supervisada. En las no supervisadas se facilitan los datos de entrada, no los de salida. La razón por la que se llama aprendizaje profundo hace referencia a las redes neuronales profundas, que utilizan un número elevado de capas en la red, digamos, por ejemplo, 1000 capas. De hecho, el DL también se le conoce a menudo como «redes neuronales profundas». Esta técnica de redes artificiales de neuronas es una de las técnicas más comunes del DL.
Figura. Esquema explicativo de diferencia entre ML y DL. https://www.privatewallmag.com/inteligencia-artificial-machine-deep-learning/
Una de las redes neuronales utilizadas en DL son las redes neuronales convolucionales, que es una variación del perceptrón multicapa, pero donde su aplicación se realiza en matrices bidimensionales, y por tanto, son muy efectivas en las tareas de visión artificial, como en la clasificación y segmentación de imágenes. En ingeniería, por ejemplo, se puede utilizar para la monitorización de la condición estructural, por ejemplo, para el análisis del deterioro. Habría que imaginar hasta dónde se podría llegar grabando en imágenes digitales la rotura en laboratorio de estructuras de hormigón y ver la capacidad predictiva de este tipo de herramientas si contaran con suficiente cantidad de datos. Todo se andará. Aquí os dejo una aplicación tradicional típica (Antoni Cladera, de la Universitat de les Illes Balears), donde se explica el modelo de rotura de una viga a flexión en la pizarra y luego se rompe la viga en el laboratorio. ¡Cuántos datos estamos perdiendo en la grabación! Un ejemplo muy reciente del uso del DL y Digital Image Correlation (DIC) aplicado a roturas de probetas en laboratorio es el trabajo de Gulgec et al. (2020).
Sin embargo, aquí nos interesa detenernos en la exploración de la integración específica del DL en las metaheurísticas con el objeto de mejorar la calidad de las soluciones o los tiempos de convergencia cuando se trata de optimizar estructuras. Un ejemplo de este camino novedoso en la investigación es la aplicabilidad de algoritmos que hibriden DL y metaheurísticas. Ya hemos publicado algunos artículos en este sentido aplicados a la optimización de muros de contrafuertes (Yepes et al., 2020; García et al., 2020a, 2020b). Además, hemos propuesto como editor invitado, un número especial en la revista Mathematics (indexada en el primer decil del JCR) denominado «Deep learning and hybrid-metaheuristics: novel engineering applications«.
Dejo a continuación un pequeño vídeo explicativo de las diferencias entre la inteligencia artificial, machine learning y deep learning.
Referencias:
FRISWELL, M.; MOTTERSHEAD, J. E. (1995). Finite element model updating in structural dynamics (Vol. 38). Dordrecht, Netherlands: Springer Science & Business Media.
GARCÍA-SEGURA, T.; YEPES, V.; FRANGOPOL, D.M. (2017). Multi-Objective Design of Post-Tensioned Concrete Road Bridges Using Artificial Neural Networks.Structural and Multidisciplinary Optimization, 56(1):139-150. DOI:1007/s00158-017-1653-0
GULGEC, N.S.; TAKAC, M., PAKZAD S.N. (2020). Uncertainty quantification in digital image correlation for experimental evaluation of deep learning based damage diagnostic.Structure and Infrastructure Engineering, https://doi.org/10.1080/15732479.2020.1815224
La inteligencia artificial (IA) – tecnologías capaces de realizar tareas que normalmente requieren inteligencia humana – constituye un enfoque alternativo a las técnicas de modelización clásicas. La IA es la rama de la ciencia de la computación que desarrolla máquinas y software con una inteligencia que trata de imitar las funciones cognitivas humanas. En comparación con los métodos tradicionales, la IA ofrece ventajas para abordar los problemas asociados con las incertidumbres y es una ayuda efectiva para resolver problemas de elevada complejidad, como son la mayoría de problemas reales en ingeniería. Además, las soluciones aportadas por la IA constituyen buenas alternativas para determinar los parámetros de diseño cuando no es posible efectuar ensayos, lo que supone un ahorro importante en tiempo y esfuerzo dedicado a los experimentos. La IA también es capaz de acelerar el proceso de toma de decisiones, disminuye las tasas de error y aumenta la eficiencia de los cálculos. Entre las diferentes técnicas de IA destacan el aprendizaje automático (machine learning), el reconocimiento de patrones (pattern recognition) y el aprendizaje profundo (deep learning), técnicas que han adquirido recientemente una atención considerable y que se están estableciendo como una nueva clase de métodos inteligentes para su uso en la ingeniería civil.
Todos conocemos problemas de ingeniería civil cuya solución pone al límite las técnicas computacionales tradicionales. Muchas veces se solucionan porque existen expertos con la formación adecuada capaces de intuir la solución más adecuada, para luego comprobarla con los métodos convencionales de cálculo. En este contexto, la inteligencia artificial está tratando de capturar la esencia de la cognición humana para acelerar la resolución de estos problemas complejos. La IA se ha desarrollado basándose en la interacción de varias disciplinas, como son la informática, la teoría de la información, la cibernética, la lingüística y la neurofisiología.
Figura 1. Interrelación entre diferentes técnicas computacionales inteligentes. Elaboración propia basada en Salehi y Burgueño (2018)
A veces el concepto de «inteligencia artificial (IA)» se confunde con el de «inteligencia de máquina (IM)» (machine intelligence). En general, la IM se refiere a máquinas con un comportamiento y un razonamiento inteligente similar al de los humanos, mientras que la IA se refiere a la capacidad de una máquina de imitar las funciones cognitivas de los humanos para realizar tareas de forma inteligente. Otro término importante es la «computación cognitiva (CC)» (cognitive computing), que se inspira en las capacidades de la mente humana. Los sistemas cognitivos son capaces de resolver problemas imitando el pensamiento y el razonamiento humano. Tales sistemas se basan en la capacidad de las máquinas para medir, razonar y adaptarse utilizando la experiencia adquirida.
Las principales características de los sistemas de CC son su capacidad para interpretar grandes datos, el entrenamiento dinámico y el aprendizaje adaptativo, el descubrimiento probabilístico de patrones relevantes. Técnicamente, la IA se refiere a ordenadores y máquinas que pueden comportarse de forma inteligente, mientras que el CC se concentra en la resolución de los problemas empleando el pensamiento humano. La diferencia más significativa entre la IA y la CC puede definirse en función de su interactuación con los humanos. Para cualquier sistema de IA, hay un agente que decide qué acciones deben tomarse. Sin embargo, los sistemas de CC aprenden, razonan e interactúan como los humanos.
Por otra parte, los «sistemas expertos» son una rama de la IA. Un sistema experto se definiría como un programa de ordenador que intenta imitar a los expertos humanos para resolver problemas que exigen conocimientos humanos y experiencia. Por tanto, la IA incluye diferentes ramas como los sistemas expertos, el aprendizaje automático, el reconocimiento de patrones y la lógica difusa.
La IA se ha usado en estas últimas décadas de forma intensiva en las investigaciones relacionadas con la ingeniería civil. Son notables las aplicaciones de las redes neuronales, los algoritmos genéticos, la lógica difusa y la programación paralela. Además, la optimización heurística ha tenido una especial relevancia en muchos campos de la ingeniería civil, especialmente en el ámbito de las estructuras y las infraestructuras. Sin embargo, los métodos más recientes como el reconocimiento de patrones, el aprendizaje automático y el aprendizaje profundo son métodos totalmente emergentes en este ámbito de la ingeniería. Estas técnicas emergentes tienen la capacidad de aprender complicadas interrelaciones entre los parámetros y las variables, y así permiten resolver una diversidad de problemas que son difíciles, o no son posibles, de resolver con los métodos tradicionales.
El aprendizaje automático es capaz de descubrir información oculta sobre el rendimiento de una estructura al aprender la influencia de diversos mecanismos de daño o degradación y los datos recogidos de los sensores. Además, el aprendizaje automático y el aprendizaje profundo tienen una elevada potencialidad en el dominio de la mecánica computacional, como por ejemplo, para optimizar los procesos en el método de elementos finitos para mejorar la eficiencia de los cálculos. Estos métodos también se pueden utilizar para resolver problemas complejos a través del novedoso concepto de la Internet de las Cosas. En este contexto del Internet de las Cosas, se pueden emplear estas técnicas emergentes para analizar e interpretar grandes bases de datos. Esto abre las puertas al desarrollo de infraestructuras, ciudades o estructuras inteligentes.
Sin embargo, aún nos encontramos con limitaciones en el uso de estos métodos emergentes. Entre esas limitaciones figura la falta de selección racional del método de IA, que no se tenga en cuenta el efecto de los datos incompletos o con ruido, que no se considere la eficiencia de la computación, el hecho de que se informe sobre la exactitud de la clasificación sin explorar soluciones alternativas para aumentar el rendimiento, y la insuficiencia de la presentación del proceso para seleccionar los parámetros óptimos para la técnica de IA. Con todo, a pesar de estas limitaciones, el aprendizaje automático, el reconocimiento de patrones y el aprendizaje profundo se postulan como métodos pioneros para aumentar la eficiencia de muchas aplicaciones actuales de la ingeniería civil, así como para la creación de usos innovadores.
Referencias:
GARCÍA-SEGURA, T.; YEPES, V.; FRANGOPOL, D.M. (2017). Multi-Objective Design of Post-Tensioned Concrete Road Bridges Using Artificial Neural Networks.Structural and Multidisciplinary Optimization, 56(1):139-150.
SALEHI, H.; BURGUEÑO, R. (2018). Emerging artificial intelligence methods in structural engineering.Engineering Structures, 171:170-189.
SIERRA, L.A.; YEPES, V.; PELLICER, E. (2018). A review of multi-criteria assessment of the social sustainability of infrastructures.Journal of Cleaner Production, 187:496-513.
YEPES, V.; GARCÍA-SEGURA, T.; MORENO-JIMÉNEZ, J.M. (2015). A cognitive approach for the multi-objective optimization of RC structural problems. Archives of Civil and Mechanical Engineering, 15(4):1024-1036
Os dejo a continuación un informe sobre cómo la inteligencia de máquina permite crear valor y se postula como una herramienta de primer nivel en todos los ámbitos.
Hoy 4 de septiembre, pero del año 2002, tuve la ocasión de defender mi tesis doctoral titulada «Optimización heurística económica aplicada a las redes de transporte del tipo VRPTW«. La tesis fue dirigida por el profesor Josep Ramon Medina Folgado y el tribunal estuvo presidido por José Aguilar, acompañado por José Vicente Colomer, Francesc Robusté, Francisco García Benítez y Jesús Cuartero. La calificación fue de sobresaliente «cum laude» por unanimidad.
Por tanto, mi tesis ya ha cumplido la mayoría de edad. Es un buen momento para reflexionar sobre lo que este trabajo supuso para mí. La realicé a los 38 años, tras haber adquirido una buena trayectoria profesional en la empresa privada (Dragados y Construcciones) y en la administración pública (Generalitat Valenciana). De alguna forma, ya tenía la vida más o menos solucionada, con experiencia acumulada, pero con muchas inquietudes. En aquel momento era profesor asociado a tiempo parcial y, en mis ratos libres, me dediqué a hacer la tesis doctoral. Es innecesario decir las dificultades que supone para cualquiera sacar tiempo de donde no lo hay para hacer algo que, en aquel momento, era simplemente vocacional. No hubo financiación de ningún tipo, ni reducción de la jornada laboral, ni nada por el estilo. En aquel momento ni se me pasó por la cabeza que años después acabaría como catedrático de universidad. Entre 2002 y 2008 seguí trabajando como profesor asociado en la administración pública. Por último, gracias al sistema de habilitación nacional, accedí directamente a la universidad como profesor titular desde la categoría de profesor asociado, algo bastante inusual en aquel momento. Gracias a que era una verdadera oposición con el resto de candidatos, tuve la oportunidad de demostrar mi valía ante un tribunal. Luego la cátedra vino por el sistema de acreditación y la plaza, tras una larga espera a causa de la crisis y de las cuotas de reposición. Pasé en seis años de ser profesor asociado a tiempo parcial a estar habilitado como catedrático de universidad (12 de mayo de 2014). Todo eso se lo debo, entre otras cosas, a la gran producción científica que pude llevar a cabo y que tuvo su origen en esta tesis doctoral.
Por cierto, en aquella época la tesis doctoral tenía que ser inédita, es decir, ningún artículo de la tesis tenía que haberse publicado. Hoy en día es todo lo contrario: conviene tener de 3 a 4 artículos buenos antes de pasar por la defensa. Luego publiqué algunos artículos sobre este tema en revistas nacionales e internacionales, pero sobre todo en actas de congresos.
La tesis supuso, en su momento, aprender en profundidad lo que eran la algoritmia, el cálculo computacional y, sobre todo, la optimización heurística. En aquel momento, al menos en el ámbito de la ingeniería civil, no se sabía nada o muy poco al respecto, aunque era un campo muy activo a nivel internacional. Luego comprobé que todo lo aprendido se pudo aplicar al ámbito de las estructuras, especialmente a los puentes, pero esa es otra historia.
Os dejo las primeras páginas de la tesis y la presentación de PowerPoint que utilicé. Para que os hagáis una idea del momento, la presentación también la imprimí en acetato, ya que aún se empleaba la proyección de transparencias en las clases.
Referencia:
YEPES, V. (2002). Optimización heurística económica aplicada a las redes de transporte del tipo VRPTW. Tesis Doctoral. Escuela Técnica Superior de Ingenieros de Caminos, Canales y Puertos. Universitat Politècnica de València. 352 pp. ISBN: 0-493-91360-2.