 Los problemas de programación lineal consisten en optimizar una ecuación lineal sujeta a una serie de restricciones, formuladas como desigualdades lineales. Para resolverlos, el toolbox de Matlab incluye la función linprog, que emplea tres algoritmos para su solución: el método de larga escala, el método simplex y el de Active Set.
Los problemas de programación lineal consisten en optimizar una ecuación lineal sujeta a una serie de restricciones, formuladas como desigualdades lineales. Para resolverlos, el toolbox de Matlab incluye la función linprog, que emplea tres algoritmos para su solución: el método de larga escala, el método simplex y el de Active Set.
La sintaxis para llamar a esta función es la siguiente:
x = linprog (f ,A, b, Aeq, beq, lb, ub, x0, options)
Donde:
f: es el vector de coeficientes de la función objetivo, organizado según las variables (Matlab intentará minimizar siempre, por tanto, multiplicaremos por -1 si queremos maximizar)
A, b: corresponden a las restricciones de desigualdad, siendo el primero la matriz y el segundo el vector del lado derecho del sistema de inecuaciones Ax<=b.
Aeq, beq: tienen el mismo tratamiento que A y b, respectivamente, teniendo en cuenta que los nuevos corresponden a un sistema de ecuaciones, en tanto que los antiguos constituían un sistema de inecuaciones.
lb, ub: son, respectivamente, los límites inferior y superior de la región donde se espera que se encuentre el punto óptimo.
x0: es el punto inicial para la iteración. Según el algoritmo usado, es posible, o no, omitir este último.
Ejercicio 1:
Un taller confecciona cuatro productos: F, B, V y A, para los que utiliza 2 horas, 3 horas y media, 4 horas y media y 5 horas de máquina y 1, 2, 1 y 10 horas de mano de operario para cada producto, respectivamente. Si se dispone de 3000 horas de máquina y 2000 horas de operario, y sabiendo que los beneficios obtenidos por unidad son de 6, 10, 13 y 30 u.m., respectivamente, calcular el número de productos de cada tipo que deben producirse para obtener el máximo beneficio.
El planteamiento para el primer problema es:
Maximizar: 6×1 + 10×2 + 13×3 + 30×4
Sujeto a: 2×1 + 3,5×2 + 4,5×3 + 5×4 = 3000
x1 + 2×2 + x3 + 10×4 = 2000
x1, x2, x3, x4 ≥ 0
Para definir todas las variables del primer problema, en Matlab, se debe escribir:
>> f = [-6 -10 -13 -30];
>> A = -eye(4); % matriz identidad de tamaño 4×4
>> b = [0 0 0 0];
>> Aeq = [2 3.5 4.5 5 ; 1 2 1 10];
>> beq = [3000 2000];
Finalmente, se usa la sintaxis respectiva con las variables del primer problema, cargadas previamente, para obtener lo siguiente:
>> [x,fval] = linprog(f,A,b,Aeq,beq,lb,ub,x0)
Optimization Terminated.
x =
0.0000
0.0000
500.0000
150.0000
fval =
-1.1000e+004
Ejercicio 2:
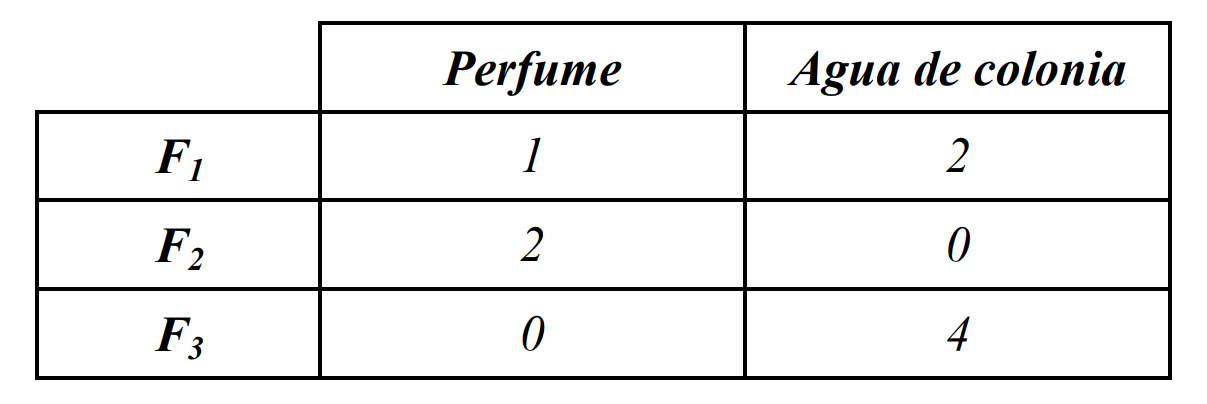
Una empresa dedicada a la producción de frascos de perfume, de agua de colonia y de champú utiliza tres factores productivos, F1, F2 y F3, con 240, 460 y 430 unidades, respectivamente. Las cantidades de dichos factores utilizados en la producción de un frasco por cada producto se detallan en la siguiente tabla:
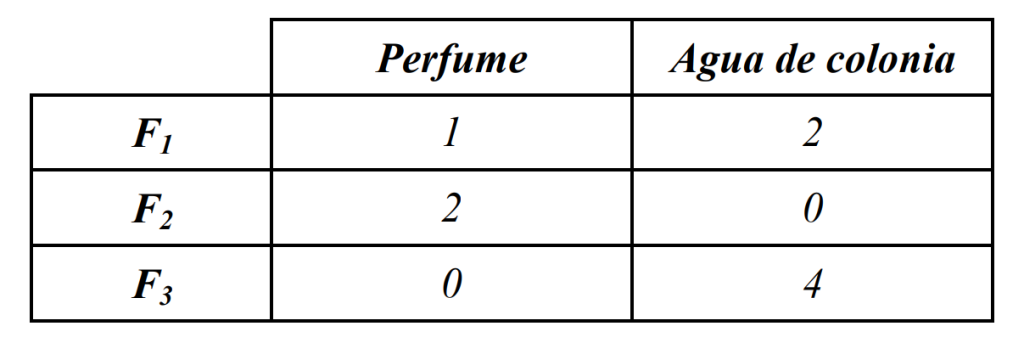
La formulación del segundo problema es: Sabiendo que el precio unitario de venta del perfume es de 5 unidades monetarias, el del agua de colonia de 2 y el del champú de 3, y que se vende todo lo que se produce, calcular el beneficio máximo y el número de frascos de cada tipo que debe producir la empresa para obtenerlo.
Maximizar: 5×1 + 2×2 + 3×3
Sujeto a: F1 ≤ 240
F2 ≤ 460
F3 ≤ 430
La asignación de los valores de las variables, correspondientes al segundo problema, se realiza de la siguiente manera:
>> f = [-5 -2 -3];
>> A = [1 2 1 ; 2 0 3 ; 0 4 1];
>> b = [240 460 430];
>> x0 = [0 0 0];
>> [x,fval] = linprog(f,A,b,[],[],[0 0 0])
Optimization Terminated.
x =
230.0000
5.0000
0.0000
fval =
-1.1600e+003
Os dejo a continuación algunos problemas que, seguro, podréis abordar con Matlab:
Pincha aquí para descargar
Referencia:
Cabezas, I.; Páez, J.D. (2010). Matlab. Toolbox de optimización. Aplicaciones en ciencias económicas. Unidad de Informática y Comunicaciones. Facultad de Ciencias Económicas. Universidad Nacional de Colombia, Bogotá D.C. (enlace).
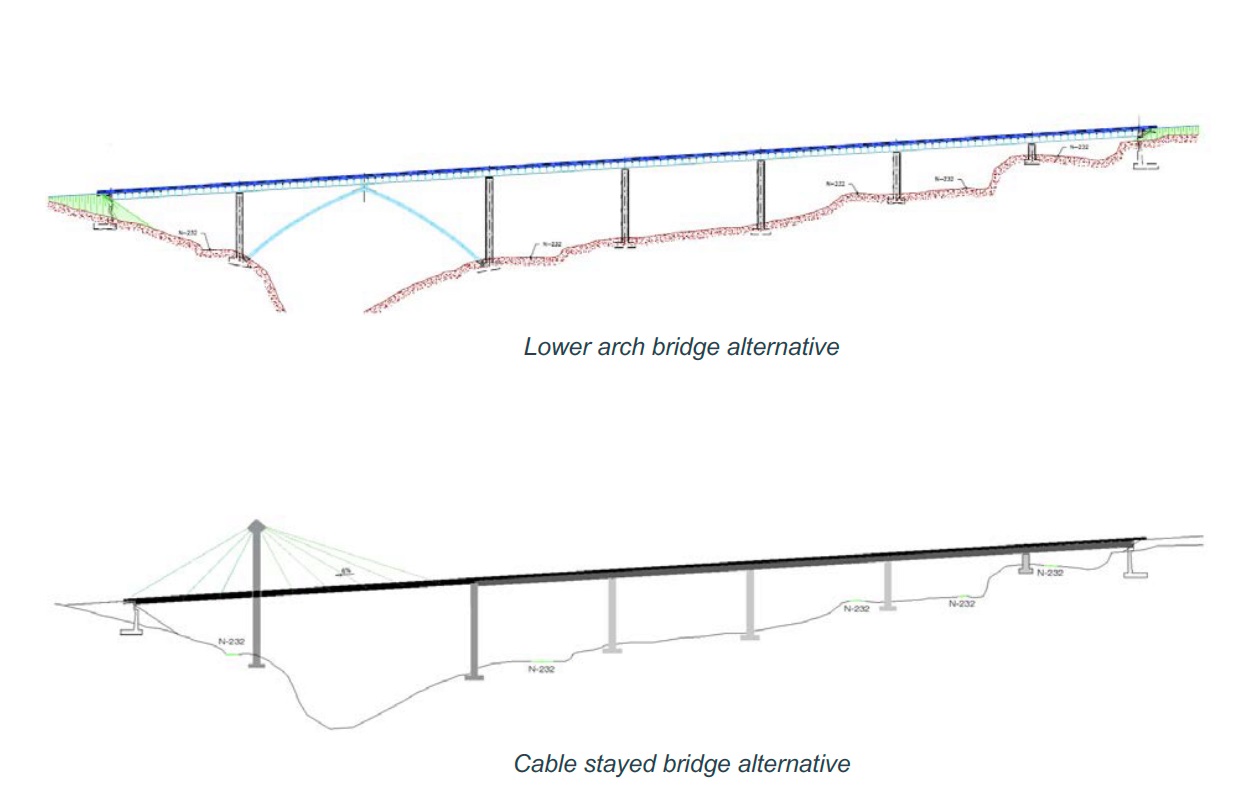 Os dejo a continuación un ejemplo sencillo de aplicación de la técnica AHP de toma de decisiones dirigida a la selección de alternativas en la construcción de un puente mixto en cajón. Se trata de un caso que utilizamos con nuestros estudiantes para enseñar la técnica. Tratamos de evitar que, en los estudios de soluciones, los estudiantes recurran siempre a las matrices de valoración ponderada, donde los pesos de cada criterio siempre se ponen de forma más o menos arbitraria, o bien para justificar la solución preferida. Este tipo de problemas también suelen aparecer en los concursos de licitación de obras públicas.
Os dejo a continuación un ejemplo sencillo de aplicación de la técnica AHP de toma de decisiones dirigida a la selección de alternativas en la construcción de un puente mixto en cajón. Se trata de un caso que utilizamos con nuestros estudiantes para enseñar la técnica. Tratamos de evitar que, en los estudios de soluciones, los estudiantes recurran siempre a las matrices de valoración ponderada, donde los pesos de cada criterio siempre se ponen de forma más o menos arbitraria, o bien para justificar la solución preferida. Este tipo de problemas también suelen aparecer en los concursos de licitación de obras públicas.