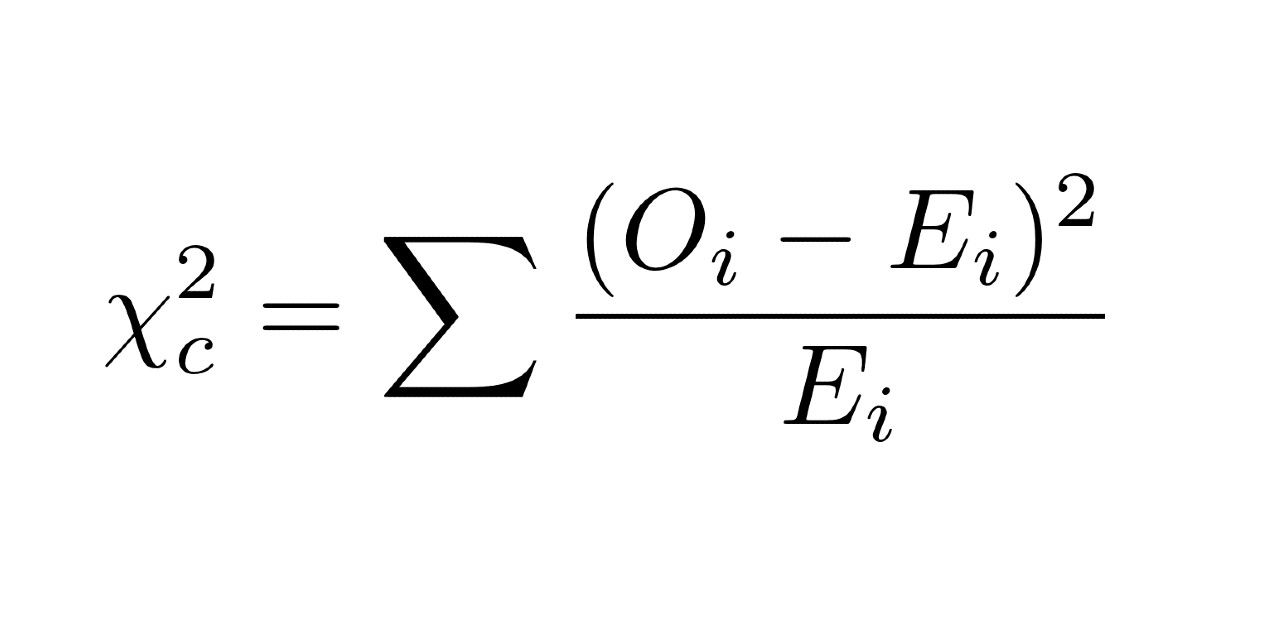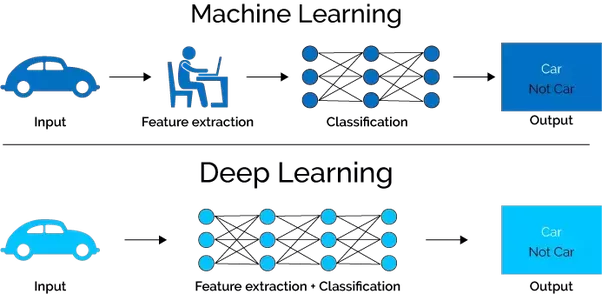En los objetivos de desarrollo sostenible recientemente establecidos se reconoce la importancia de las infraestructuras para lograr un futuro sostenible. A lo largo de su ciclo de vida, las infraestructuras generan una serie de impactos cuya reducción ha sido uno de los principales focos de atención de los investigadores en los últimos años. La optimización de los intervalos de mantenimiento de las estructuras, como los puentes, ha despertado la atención del sector de la ingeniería civil, pues la mayoría de los impactos de las infraestructuras se producen durante la fase de servicio. Así pues, actualmente los puentes se proyectan para atender a los efectos económicos y ambientales derivados de las actividades de mantenimiento. Sin embargo, en esos análisis se suele descuidar el pilar social de la sostenibilidad. Dado que todavía no existe una metodología universalmente aceptada para su evaluación, la dimensión social no se incluye de forma efectiva en las evaluaciones del ciclo de vida de las infraestructuras. En la presente comunicación se evalúan los efectos del ciclo de vida de diseños alternativos de los tableros de hormigón de los puentes en un ambiente costero que requiere mantenimiento. Los intervalos de mantenimiento derivados de la fiabilidad se optimizan primero minimizando los impactos económicos y ambientales. En una segunda etapa del análisis, se incluye la dimensión social en el proceso de optimización y se comparan los resultados. Los resultados de optimización de estas evaluaciones combinadas se obtienen aplicando la técnica de toma de decisiones multicriterio AHP-TOPSIS. En este trabajo se muestra cómo la inclusión de la dimensión social puede conducir a estrategias de mantenimiento óptimo diferentes y más orientadas a la sostenibilidad. El enfoque tridimensional que se aplica aquí ha dado lugar a que se prefieran otras alternativas a las derivadas de la evaluación convencional que considera las perspectivas económica y ambiental. Esa conclusión apoya la idea de que se requieren evaluaciones holísticas del ciclo de vida para el diseño sostenible de las infraestructuras y de que es necesario hacer más esfuerzos urgentes para integrar la dimensión social en las evaluaciones de la sostenibilidad de las estructuras.
Referencia:
NAVARRO, I.J.; YEPES, V.; MARTÍ, J.V. (2020). Role of the social dimension on the sustainability-oriented maintenance optimization of bridges in coastal environments. 10th International Conference on High Performance and Optimum Design of Structures and Materials HPSM/OPTI 2020, pp. 205-215, 3-5 June 2020, Prague, Czech Republic.
Figura 1. Junta de dilatación en un edificio. http://www.trabver.com/juntas-dilatacion-trabajos-verticales-valencia.htm
El aumento o la disminución de la temperatura en las estructuras ocasiona cambios de volumen que deben tenerse en cuenta. En el caso de un pavimento, la pequeña relación entre el espesor y el área superficial implica un incremento de longitud más que evidente. Si dicho elemento se encuentra confinado, aumentan los esfuerzos de compresión y pueden ocasionar efectos como alabeo en las placas o introducir esfuerzos en las estructuras adyacentes. Un efecto similar ocurre en el caso de la retracción y la fluencia del hormigón, por lo que muchas veces se estudian conjuntamente estos efectos con los cambios térmicos. Es por ello que se suele dejar una separación estructural que permita los movimientos diferenciales, tanto horizontales como verticales. A este tipo de juntas se les denomina «juntas de expansión», «juntas de dilatación» o «juntas de aislamiento». ¿Pero son absolutamente necesarias?
El tipo de estructura, su geometría y dimensiones, los materiales utilizados o las circunstancias ambientales, entre otros factores, influyen en el comportamiento que tenga la estructura ante las variaciones térmicas. Incluso la presencia de agua, si se congela, puede incrementar de forma significativa la acción expansiva.
La omisión de este tipo de juntas de dilatación provoca daños en los elementos estructurales (zapatas, muros de sótano, pavimentos, fábricas de ladrillo, etc.). Es por ello que las juntas de dilatación deben considerarse desde el mismo momento del proyecto de la estructura. Normalmente se usan elementos tales como cintas de espuma impregnada para sellar las juntas de dilatación, aunque también se pueden dejar abiertas.
El rango de movimiento de una junta se puede calcular multiplicando el coeficiente de dilatación del material por la dimensión inicial del elemento y por la diferencia esperada de temperaturas. No obstante, el Código Técnico de Edificación (CTE SE-AE 3.4) establece que, en los edificios habituales con elementos estructurales de hormigón o acero, pueden no considerarse las acciones térmicas cuando se dispongan juntas de dilatación de forma que no existan elementos continuos de más de 40 m de longitud, aunque la experiencia nos dice que si son menos de 40 m, mejor. En el caso de edificios de hasta 4 plantas, en zona no sísmica, la junta puede tener 2,5 cm; debiéndose calcular cuando se dan otras condiciones. Para edificios de planta rectangular y estructura a base de fábrica de ladrillo la distancia entre juntas debe ser menor de 30 m. Si la planta tiene alas en forma de “L” o “U”, de longitud mayor a 15 m (50% de 30 m), el CTE (SE-F, 2.2 Juntas de movimiento) establece que se debe disponer de juntas de dilatación cerca de sus líneas de encuentro.
Con todo, hay estudios que demuestran que se pueden superar distancias mayores a las indicadas en el CTE siempre que se cuiden los detalles constructivos de los elementos no estructurales. De hecho, la técnica permite incluso construir edificios de hasta 300 m sin este tipo de juntas. En el caso de estructuras en obras civiles, por ejemplo en puentes, es habitual ver tramos de luces mucho mayores a los 40 m del CTE sin establecer ningún tipo de junta. Incluso en el ámbito de los ferrocarriles, ya está superado el uso de la barra largo soldada, sin juntas. Pero hay que recordar que se deben tener en cuenta en el cálculo los efectos de la temperatura.
Además, no hay que olvidar que cualquier tipo de junta en una estructura supone un problema, tanto en la ejecución, como en el mantenimiento. Un argumento más para considerar los efectos térmicos, de retracción y fluencia en el cálculo estructural e intentar evitar este tipo de juntas. El problema es la dificultad de encontrar herramientas comerciales que permitan el análisis de los efectos termohigrométricos (fluencia, retracción y cambios térmicos) junto con la fisuración, lo que lleva a que muchos técnicos se decanten por cumplir los requerimientos expuestos en el CTE.
Figura 1. Cuadrado grecolatino de orden cuatro. Wikipedia
Un cuadrado greco-latino, cuadrado de Euler o cuadrados latinos ortogonales de orden n se denomina, en matemáticas, a la disposición en una cuadrícula cuadrada n×n de los elementos de dos conjuntos S y T, ambos con n elementos, cada celda conteniendo un par ordenado (s, t), siendo s elemento de S y t de T, de forma que cada elemento de S y cada elemento de T aparezca exactamente una vez en cada fila y en cada columna y que no haya dos celdas conteniendo el mismo par ordenado. Si bien los cuadrados grecolatinos eran una curiosidad matemática, a mediados del siglo XX Fisher demostró su utilidad para el control de experimentos estadísticos.
El diseño de experimentos en cuadrado grecolatino constituye una extensión del cuadrado latino. En este caso se eliminan tres fuentes extrañas de variabilidad, es decir, se controlan tres factores de bloques y un factor de tratamiento. Se trata de un diseño basado en una matriz de «n» letras latinas y «n» letras griegas, de forma que cada letra latina aparece solo una vez al lado de cada letra griega. Lo interesante de este diseño es que se permite la investigación de cuatro factores (filas, columnas, letras latinas y letras griegas), cada una con «n» niveles en solo «n2» corridas. Se llama cuadrado grecolatino porque los cuatro factores involucrados se prueban en la misma cantidad de niveles, de aquí que se pueda escribir como un cuadro. En la Figura 1 se presenta el aspecto de los datos del diseño de orden cuatro. El inconveniente de este modelo es que su utilización es muy restrictiva. El análisis de la varianza permite comprobar las hipótesis de igualdad de letras latinas (tratamientos), de las filas, de las columnas y de las letras griegas.
Si a un cuadrado latino p x p se le superpone un segundo cuadrado latino n x n en el que los tratamientos se denotan con letras griegas, entonces los dos cuadrados tienen la propiedad de que cada letra griega aparece una y sólo una vez con cada letra latina. Este diseño permite controlar sistemáticamente tres fuentes de variabilidad extraña. Ello permite la investigación de cuatro factores (filas, columnas, letras latinas y letras griegas), cada una con p niveles en sólo n2 ensayos.
Por tanto, el diseño de experimentos en cuadrado grecolatino se caracteriza por lo siguiente:
Es un diseño con cuatro factores a n niveles
Se asume que no hay interacciones entre los factores
Requiere de n2 observaciones
Cada nivel de un factor aparece una vez con cada nivel de los otros factores
Se trata de la superposición de dos cuadrados latinos (ver Figura 2)
Figura 2. Superposición de dos cuadrados latinos
En un diseño en cuadrado greco-latino la variable respuesta yij(hp) viene descrita por la siguiente ecuación:
A continuación os presento un caso para aclarar la aplicabilidad de este diseño de experimentos. Se trata de averiguar si la resistencia característica del hormigón a flexocompresión (MPa) varía con cuatro dosificaciones diferentes. Para ello se han preparado amasadas en cuatro amasadoras diferentes, se han utilizado cuatro operarios de amasadora y los ensayos se han realizado en cuatro laboratorios diferentes. Los resultados se encuentran en la tabla que sigue. Se quiere analizar el diseño de experimentos en cuadrado grecolatino realizado.
En el caso que nos ocupa, la variable de respuesta de la resistencia característica del hormigón a flexocompresión (MPa). El factor que se quiere estudiar es la dosificación a cuatro niveles (A, B, C y D). El bloque I es el tipo de amasadora, con cuatro niveles (α, β, γ y δ). El bloque II es el operario de la amasadora, con cuatro niveles (1, 2, 3 y 4). El bloque III es el laboratorio, con cuatro niveles (las filas). Se supone que no hay interacción entre el factor y los bloques entre sí.
Lo que se quiere averiguar es si hay diferencias significativas entre las dosificaciones (el factor a estudiar). De paso, se desea saber si hay diferencias entre los laboratorios, los operarios y las amasadoras (los bloques).
Os paso un pequeño vídeo donde se explica, de forma muy resumida, este caso, tanto para SPSS como para MINITAB.
Os dejo otro vídeo donde también se explica este tipo de diseño de experimentos.
Referencias:
Gutiérrez, H.; de la Vara, R. (2004). Análisis y Diseño de Experimentos. McGraw Hill, México.
Vicente, MªL.; Girón, P.; Nieto, C.; Pérez, T. (2005). Diseño de Experimentos. Soluciones con SAS y SPSS. Pearson, Prentice Hall, Madrid.
Pérez, C. (2013). Diseño de Experimentos. Técnicas y Herramientas. Garceta Grupo Editorial, Madrid.
A continuación recojo uno de los primeros trabajos que hizo nuestro grupo de investigación en el año 2005 sobre optimización heurística de estructuras de hormigón. Se trata de la optimización mediante varias heurísticas (máximo gradiente, aceptación por umbrales y recocido simulado) de un pórtico de paso de carretera de hormigón armado. En este caso se consideraron 28 variables para definir una solución de pórtico. Este artículo se publicó en la revista Hormigón y Acero. Espero que os sea de interés.
Referencia:
CARRERA, J.M.; ALCALÁ, J.; YEPES, V.; GONZÁLEZ-VIDOSA, F. (2005). Optimización heurística de pórticos de paso de carretera de hormigón armado.Hormigón y Acero, 236: 85-95.
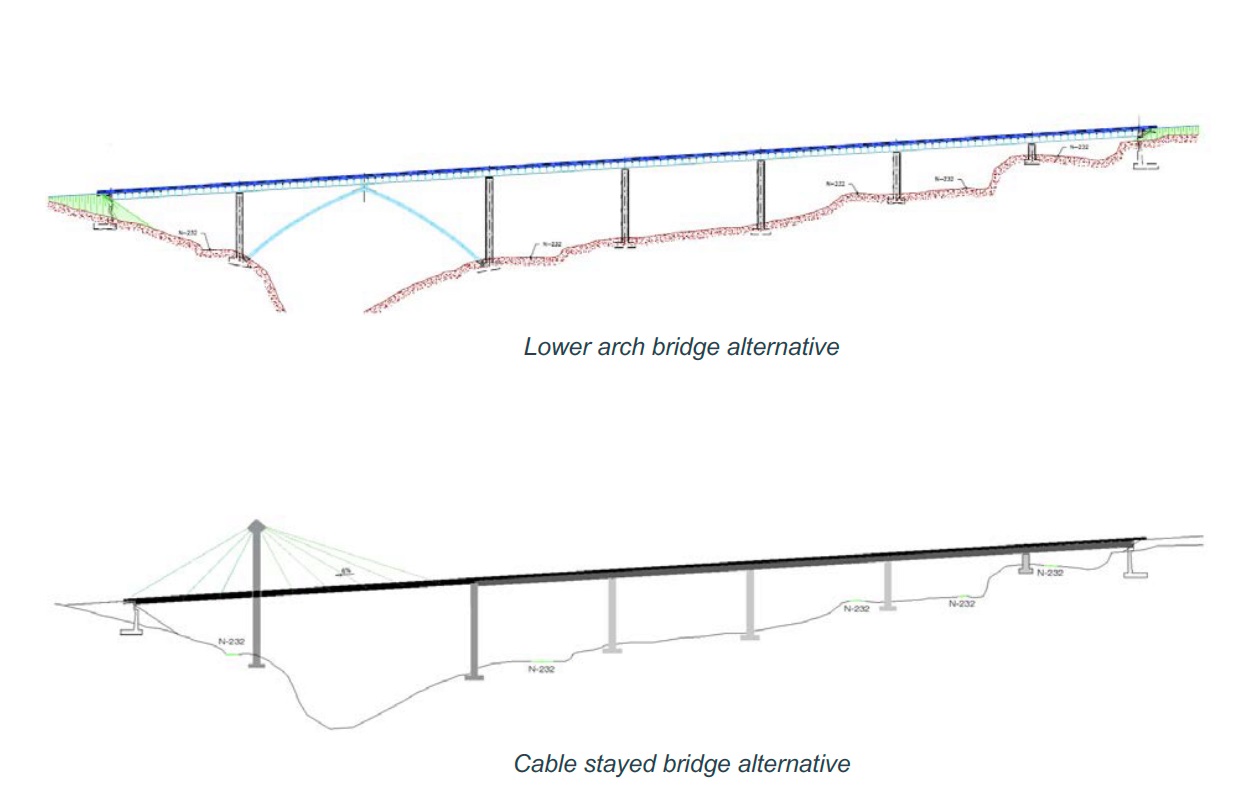
Os dejo a continuación un ejemplo sencillo de aplicación de la técnica AHP de toma de decisiones dirigida a la selección de alternativas en la construcción de un puente mixto en cajón. Se trata de un caso que utilizamos con nuestros estudiantes para enseñar la técnica. Tratamos de evitar que, en los estudios de soluciones, los estudiantes recurran siempre a las matrices de valoración ponderada, donde los pesos de cada criterio siempre se ponen de forma más o menos arbitraria, o bien para justificar la solución preferida. Este tipo de problemas también suelen aparecer en los concursos de licitación de obras públicas.
Referencia:
YEPES, V.; MARTÍNEZ-MUÑOZ, D.; ATA-ALI, N.; MARTÍ, J.V. (2019). Multi-criteria decision analysis techniques applied to the construction of a composite box-girder bridge. 13th annual International Technology, Education and Development Conference (INTED 2019), Valencia, 11th, 12th and 13th of March, 2019, 1458-1467. ISBN: 978-84-09-08619-1
Figura 1. Modelo lineal simple de un tablero de puente losa postesado macizo (Yepes et al., 2009)
Uno de los temas básicos que se estudia en la asignatura de estadística de cualquier grado de ingeniería es la inferencia y los modelos de regresión lineal (Figura 1). A pesar de su sencillez, muchos estudiantes y profesionales aplican, sin más, este tipo de regresiones para interpolar valores en múltiples campos de la ingeniería, la economía, la salud, etc. El conocimiento de algunas nociones básicas nos permitiría evitar errores de bulto. Uno de ellos es intentar forzar las predicciones más allá de las observaciones realizadas. Otro error es confundir la correlación con la regresión. Buscar relaciones donde no las hay (relación espuria, Figura 2). Y por último, uno de los aspectos más descuidados es la no comprobación de las hipótesis básicas que se deben cumplir para que un modelo de regresión lineal sea válido.
Figura 2. Relaciones espuria entre el consumo de chocolate y el número de premios Nobel
Dicho de otra forma, valorar la calidad del ajuste mediante el coeficiente de determinación no equivale a valorar el cumplimiento de las hipótesis básicas del modelo. Si las hipótesis del modelo no se cumplen, se pueden estar cometiendo graves errores en las conclusiones de las inferencias. Así, las hipótesis básicas del modelo de regresión son las siguientes:
Linealidad: los parámetros y su interpretación no tienen sentido si los datos no proceden de un modelo lineal
Normalidad de los errores: se asume que la distribución de los errores es normal
Homocedasticidad: la varianza del error es constante
Independencia de los errores: las variables aleatorias que representan los errores son mutuamente independientes
Las variables explicativas son linealmente independientes
Para aclarar las ideas, he analizado un caso de regresión lineal simple con datos reales procedentes de 26 puentes losa postesados macizos (Yepes et al., 2009). Se trata de conocer la relación que existe entre la luz principal de este tipo de puentes y el canto del tablero. Utilizaremos los programas siguientes: MINITAB, SPSS, EXCEL y MATLAB. También os dejo un vídeo explicativo, muy básico, pero que espero sea de interés. Dejo los detalles matemáticos aparte. Los interesados pueden consultar cualquier manual básico de estadística al respecto.
Charles Darwin en una fotografía tomada por J.M. Cameron en 1869.
Resulta fascinante comprobar cómo, aplicando los mecanismos básicos de la evolución ya descritos por Darwin en su obra fundamental, El origen de las especies por medio de la selección natural, o la preservación de las razas preferidas en la lucha por la vida, publicada en 1859, se pueden generar algoritmos capaces de optimizar problemas complejos. Este tipo de metaheurísticas inspiradas en la naturaleza ya se comentaron en artículos anteriores cuando hablamos de la optimización por colonias de hormigas o de la cristalización simulada. Aunque es un algoritmo ampliamente conocido en la comunidad científica, voy a intentar dar un par de pinceladas con el único afán de divulgar esta técnica. La verdad es que las implicaciones filosóficas que subyacen a la teoría de Darwin son de una profundidad difícil de comprender cuando se llevan a sus últimas consecuencias. Pero el caso es que estos algoritmos funcionan perfectamente en la optimización de estructuras de hormigón, problemas de transporte y otros problemas difíciles de optimización combinatoria.
Para quienes estén interesados, os paso en las referencias un par de artículos en los que hemos aplicado los algoritmos genéticos para optimizar rutas de transporte aéreo o pilas de puente huecas de hormigón armado.
Sin embargo, para aquellos que queráis un buen libro para pensar, os recomiendo «La peligrosa idea de Darwin», de Daniel C. Dennett. A más de uno le hará quitar los cimientos más profundos de sus creencias. Os paso la referencia al final.
Básicamente, los algoritmos genéticos, o “Genetic Algorithms” (GA), simulan el proceso de evolución de las especies que se reproducen sexualmente. De manera muy general, se puede decir que en la evolución de los seres vivos, el problema al que cada individuo se enfrenta diariamente es el de la supervivencia. Para ello, cuenta, entre otras, con las habilidades innatas provistas por su material genético. A nivel de los genes, el problema consiste en buscar adaptaciones beneficiosas en un medio hostil y cambiante. Debido, en parte, a la selección natural, cada especie gana cierta “información” que se incorpora a sus cromosomas.
Durante la reproducción sexual, un nuevo individuo, diferente de sus padres, se genera mediante dos mecanismos fundamentales: el primero es el cruzamiento, que combina parte del patrimonio genético de cada progenitor para elaborar el del nuevo individuo; el segundo es la mutación, que supone una modificación espontánea de esta información genética. La descendencia será diferente de los progenitores, pero conservará parte de sus características. Si los hijos heredan buenos atributos de sus padres, su probabilidad de supervivencia será mayor que la de aquellos que no los tengan. De este modo, los mejores tendrán altas probabilidades de reproducirse y de transmitir su información genética a sus descendientes.
Holland (1975) estableció por primera vez una metaheurística basada en la analogía genética. Un individuo puede asociarse a una solución factible del problema, de modo que pueda codificarse como un vector binario “string”. Entonces, un operador de cruzamiento intercambia las cadenas de los padres para producir un hijo. La mutación se configura como un operador secundario que cambia, con una probabilidad pequeña, algunos elementos del vector hijo. La aptitud del nuevo vector creado se evalúa según una función objetivo.
Los pasos a seguir con esta metaheurística serían los siguientes:
Generar una población de vectores (individuos).
Mientras no se encuentre un criterio de parada:
Seleccionar un conjunto de vectores padres que serán reemplazados por la población.
Emparejar aleatoriamente a los progenitores y cruzarlos para obtener unos vectores hijos.
Aplicar una mutación a cada descendiente.
Evaluar a los hijos.
Introducir a los hijos en la población.
Eliminar a los individuos menos eficaces.
Normalmente este proceso finaliza después de un número determinado de generaciones o cuando la población ya no puede mejorar. La selección de los padres se realiza de forma probabilística hacia los individuos más aptos. Al igual que ocurre en la naturaleza, los sujetos con mayor aptitud difunden sus características a lo largo de toda la población.
Esta descripción de los GA se adapta a cada situación concreta, siendo habitual la codificación en números enteros en lugar de binaria. Del mismo modo, se han sofisticado los distintos operadores de cruzamiento y de mutación.
DENNETT, D.C. (1999). La peligrosa idea de Darwin. Galaxia Gutenberg. Círculo de Lectores, Barcelona.
HOLLAND, J.H. (1975). Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor.
MARTÍNEZ, F.J.; GONZÁLEZ-VIDOSA, F.; HOSPITALER, A.; YEPES, V. (2010). Heuristic Optimization of RC Bridge Piers with Rectangular Hollow Sections.Computers & Structures, 88: 375-386. ISSN: 0045-7949. (link)
MEDINA, J.R.; YEPES, V. (2003). Optimization of touristic distribution networks using genetic algorithms. Statistics and Operations Research Transactions, 27(1): 95-112. ISSN: 1696-2281. (pdf)
PONZ-TIENDA, J.L.; YEPES, V.; PELLICER, E.; MORENO-FLORES, J. (2013). The resource leveling problem with multiple resources using an adaptive genetic algorithm. Automation in Construction, 29(1):161-172. DOI:http://dx.doi.org/10.1016/j.autcon.2012.10.003. (link)
YEPES, V. (2003). Apuntes de optimización heurística en ingeniería. Editorial de la Universidad Politécnica de Valencia. Ref. 2003.249. Valencia, 266 pp. Depósito legal: V-2720-2003.
Figura 1. ¿Depende la calidad del hormigón de un proveedor determinado?
En ocasiones nos encontramos con un par de variables cualitativas que, a priori, no sabemos si están relacionadas entre sí o si pertenecen a una misma población estadística. Recordemos que las variables cualitativas son aquellas cuyo resultado es un valor o categoría de entre un conjunto finito de respuestas (tipo de defecto, nombre del proveedor, color, etc.).
En el ámbito del hormigón, por ejemplo, podríamos tener varios proveedores de hormigón preparado en central y un control del número de cubas-hormigonera aceptadas, aceptadas con defectos menores o rechazadas. Otro ejemplo sería contabilizar el tipo de incumplimiento de una tolerancia por parte de un equipo que está encofrando un muro de contención. En estos casos, se trata de determinar si existe dependencia entre los proveedores o los equipos de encofradores respecto de los defectos detectados. Esto sería interesante en el ámbito del control de la calidad para tomar medidas, como pudiese ser descartar a determinados proveedores o mejorar la formación de un equipo de encofradores.
Así, podríamos tener un problema como el siguiente: Teniendo en cuenta el punto 5.6 del Anejo 11 de la EHE, donde se definen las tolerancias de muros de contención y de sótano, se quiere comprobar si tres equipos de encofradores producen de forma homogénea en la ejecución de muros vistos, o, por el contrario, si unos equipos producen más defectos de un tipo que otro. Todos los equipos emplean el mismo tipo de encofrado. Las tolerancias que deben cumplirse son:
1. Desviación respecto a la vertical
2. Espesor del alzado
3. Desviación relativa de las superficies planas de intradós o de trasdós
4. Desviación de nivel de la arista superior del intradós, en muros vistos
5. Tolerancia de acabado de la cara superior del alzado, en muros vistos
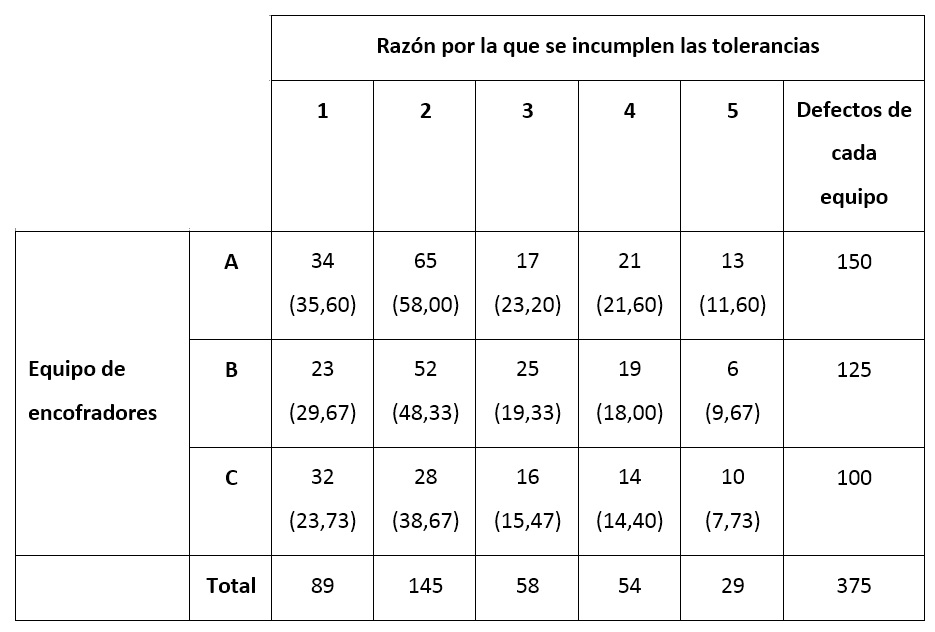
Los equipos han estado trabajando durante un año ejecutando este tipo de unidad de obra. Durante este tiempo el número de defectos en relación con la tolerancia dimensional ha sido pequeño, pero se han contabilizado 375 defectos. El control de calidad ha dado como resultado el conteo de la tabla de la Figura 2.
Figura 2. Conteo de incumplimientos según el equipo de encofradores. En paréntesis figura el valor esperado.
En la Figura 2 se ha representado también la frecuencia esperada para cada uno de los casos. Por ejemplo, la fracción esperada del incumplimiento «1» es de 89/375, mientras que la fracción esperada de defectos del equipo A es de 150/375. Ello implica que el valor esperado de incumplimientos del tipo «1» para el equipo de encofradores «A» sería: (89/375)·(150/375)·375=89·150/375=35,60.
La pregunta que nos podríamos hacer es la siguiente: ¿Influye el tipo de proveedor en la calidad de la recepción del hormigón? Para ello plantearíamos la hipótesis nula: el tipo de proveedor no influye en la calidad de la recepción del hormigón. La hipótesis alternativa sería que sí existe dicha influencia o dependencia entre las variables cualitativas.
Para ello, necesitamos una prueba estadística; en este caso, la prueba χ². El fundamento de la prueba χ² es comparar la tabla de las frecuencias observadas respecto a la de las frecuencias esperadas (que sería la que esperaríamos encontrar si las variables fueran estadísticamente independientes o no estuvieran relacionadas). Esta prueba permite obtener un p-valor (probabilidad de equivocarnos si rechazamos la hipótesis nula) que podremos contrastar con el nivel de confianza que determinemos. Normalmente el umbral utilizado es de 0,05. De esta forma, si p < 0,05, se rechaza la hipótesis nula y, por tanto, diremos que las variables son dependientes. Dicho con mayor precisión, en este caso no existe un nivel de significación suficiente que respalde la independencia de las variables.
Las conclusiones que se obtienen de la prueba son sencillas de interpretar. Si no existe mucha diferencia entre los valores observados y los esperados, no hay razones para dudar de que las variables sean independientes.
No obstante, hay algunos problemas con la prueba χ², entre ellos el relacionado con el tamaño muestral. A mayor número de casos analizados, el valor de la χ² tiende a aumentar. Es decir, si la muestra es excesivamente grande, será más fácil que rechacemos la hipótesis nula de independencia, cuando a lo mejor podrían ser las variables independientes.
Por otra parte, cada una de las celdas de la tabla de contingencia debería contar con un mínimo de 5 observaciones esperadas. Si no fuera así, podríamos agrupar filas o columnas (excepto en tablas 2×2). También se podría eliminar la fila que muestra una frecuencia esperada menor que 5.
Por último, no hay que abusar de la prueba χ². Por ejemplo, podríamos tener una variable numérica, como la resistencia característica del hormigón, y agruparla en una variable categórica en grupos como 25, 30, 35, 40, 45 y 50 MPa. Lo correcto cuando tenemos una escala numérica es aplicar la prueba t de Student; es incorrecto convertirla en una escala ordinal o incluso binaria.
A continuación os dejo el problema anterior resuelto, tanto con el programa SPSS como con MINITAB.
Os presento la segunda edición ampliada del libro que he publicado sobre procedimientos de construcción de cimentaciones y estructuras de contención. El libro trata de los aspectos relacionados con los procedimientos constructivos, maquinaria y equipos auxiliares empleados en la construcción de cimentaciones superficiales, cimentaciones profundas, pilotes, cajones, estructuras de contención de tierras, muros, pantallas de hormigón, anclajes, entibaciones y tablestacas. Pero se ha ampliado esta edición con tres capítulos nuevos dedicados a los procedimientos de contención y control de las aguas subterráneas. Además, de incluir la bibliografía para ampliar conocimientos, se incluyen cuestiones de autoevaluación con respuestas y un tesauro para el aprendizaje de los conceptos más importantes de estos temas. Este texto tiene como objetivo apoyar los contenidos lectivos de los programas de los estudios de grado relacionados con la ingeniería civil, la edificación y las obras públicas.
El libro tiene 480 páginas, 439 figuras y fotografías, así como 430 cuestiones de autoevaluación resueltas. Los contenidos de esta publicación han sido evaluados mediante el sistema doble ciego, siguiendo el procedimiento que se recoge en: http://www.upv.es/entidades/AEUPV/info/891747normalc.html
Sobre el autor: Víctor Yepes Piqueras. Doctor Ingeniero de Caminos, Canales y Puertos. Catedrático de Universidad del Departamento de Ingeniería de la Construcción y Proyectos de Ingeniería Civil de la Universitat Politècnica de València. Número 1 de su promoción, ha desarrollado su vida profesional en empresas constructoras, en el sector público y en el ámbito universitario. Es director académico del Máster Universitario en Ingeniería del Hormigón (acreditado con el sello EUR-ACE®), investigador del Instituto de Ciencia y Tecnología del Hormigón (ICITECH) y profesor visitante en la Pontificia Universidad Católica de Chile. Imparte docencia en asignaturas de grado y posgrado relacionadas con procedimientos de construcción y gestión de obras, calidad e innovación, modelos predictivos y optimización en la ingeniería. Sus líneas de investigación actuales se centran en la optimización multiobjetivo, la sostenibilidad y el análisis de ciclo de vida de puentes y estructuras de hormigón.
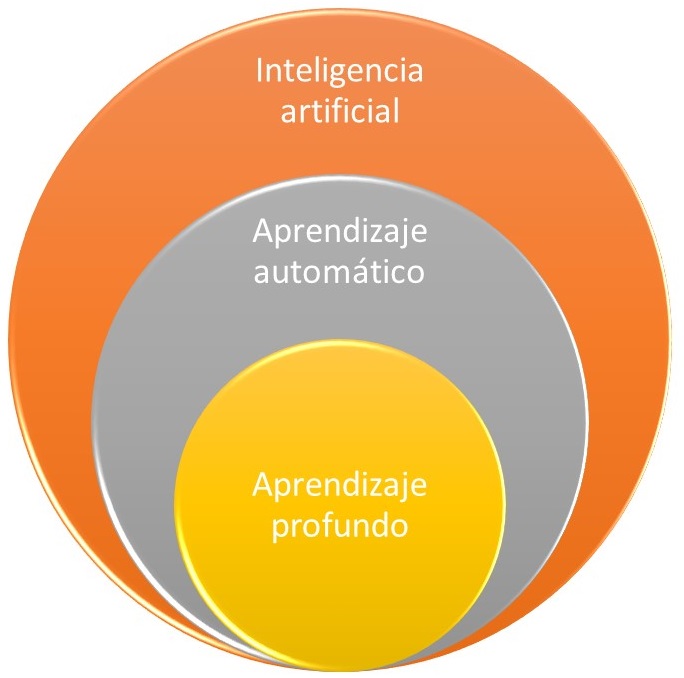
Figura 1. Relación de pertenencia entre la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo
En este artículo vamos a esbozar las posibilidades de la inteligencia artificial en la optimización de estructuras, en particular, el uso del aprendizaje profundo. El aprendizaje profundo (deep learning, DL) constituye un subconjunto del aprendizaje automático (machine learning, ML), que a su vez lo es de la inteligencia artificial (ver Figura 1). Si la inteligencia artificial empezó sobre los años 50, el aprendizaje automático surgió sobre los 80, mientras que el aprendizaje profundo nació en este siglo XXI, a partir del 2010, con la aparición de grandes superordenadores y por el aumento de los datos accesibles. Como curiosidad, uno de los grandes hitos del DL se produjo en 2012, cuando Google fue capaz de reconocer un gato entre los más de 10 millones de vídeos de Youtube, utilizando para ello 16000 ordenadores. Ahora serían necesarios muchos menos medios.
En cualquiera de estos tres casos, estamos hablando de sistemas informáticos capaces de analizar grandes cantidades de datos (big data), identificar patrones y tendencias y, por tanto, predecir de forma automática, rápida y precisa. De la inteligencia artificial y su aplicabilidad a la ingeniería civil ya hablamos en un artículo anterior.
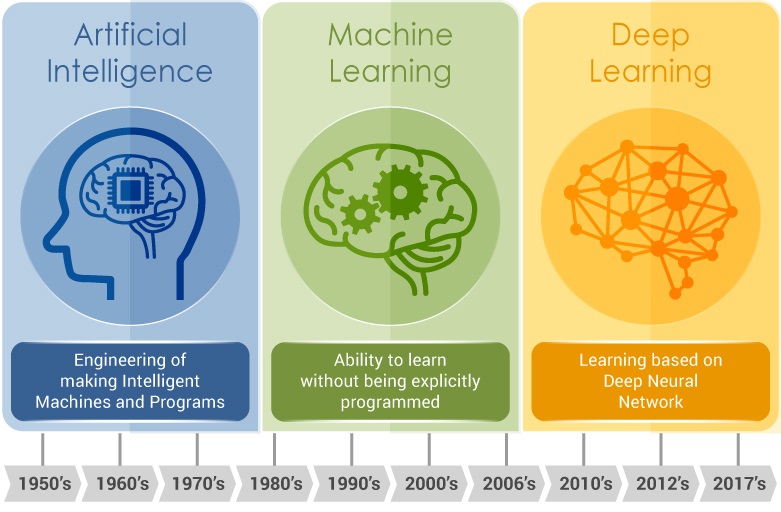
Figura 2. Cronología en la aparición de los distintos tipos de algoritmos de inteligencia artificial. https://www.privatewallmag.com/inteligencia-artificial-machine-deep-learning/
Si pensamos en el cálculo estructural, utilizamos modelos, más o menos sofistificados, que permiten, si se conocen con suficiente precisión las acciones, averiguar los esfuerzos a los que se encuentran sometidos cada uno de los elementos en los que hemos dividido una estructura. Con dichos esfuerzos se identifican una serie de estados límite, que son un conjunto de situaciones potencialmente peligrosas para la estructura y comparar si la capacidad estructural del elemento analizado, dependiente de las propiedades geométricas y de sus materiales constituyentes, supera el valor último de la solicitación a la que, bajo cierta probabilidad, puede llegar a alcanzar el elemento estructural analizado.
Estos métodos tradicionales emplean desde hipótesis de elasticidad y comportamiento lineal, a otros modelos con comportamiento plástico o no lineales más complejos. Suele utilizarse, con mayor o menos sofisticación, el método de los elementos finitos (MEF) y el método matricial de la rigidez. En definitiva, en determinados casos, suelen emplearse los ordenadores para resolver de forma aproximada, ecuaciones diferenciales parciales muy complejas, habituales en la ingeniería estructural, pero también en otros campos de la ingeniería y la física. Para que estos sistemas de cálculo resulten precisos, es necesario alimentar los modelos con datos sobre materiales, condiciones de contorno, acciones, etc., lo más reales posibles. Para eso se comprueban y calibran estos modelos en ensayos reales de laboratorio (Friswell y Mottershead, 1995). De alguna forma, estamos retroalimentando de información al modelo, y por tanto «aprende».
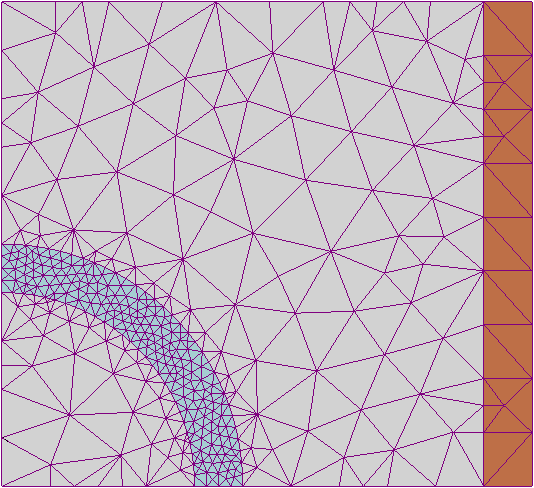
Figura 2. Malla 2D de elementos finitos, más densa alrededor de la zona de mayor interés. Wikipedia.
Si analizamos bien lo que hacemos, estamos utilizando un modelo, más o menos complicado, para predecir cómo se va a comportar la estructura. Pues bien, si tuviésemos una cantidad suficiente de datos procedentes de laboratorio y de casos reales, un sistema inteligente extraería información y sería capaz de predecir el resultado final. Mientras que la inteligencia artificial debería alimentarse de una ingente cantidad de datos (big data), el método de los elementos finitos precisa menor cantidad de información bruta (smart data), pues ha habido una labor previa muy concienzuda y rigurosa, para intentar comprender el fenómeno subyacente y modelizarlo adecuadamente. Pero, en definitiva, son dos procedimientos diferentes que nos llevan a un mismo objetivo: diseñar estructuras seguras. Otro tema será si éstas estructuras son óptimas desde algún punto de vista (economía, sostenibilidad, etc.).
La optimización de las estructuras constituye un campo científico donde se ha trabajado intensamente en las últimas décadas. Debido a que los problemas reales requieren un número elevado de variables, la resolución exacta del problema de optimización asociado es inabordable. Se trata de problemas NP-hard, de elevada complejidad computacional, que requiere de metaheurísticas para llegar a soluciones satisfactorias en tiempos de cálculo razonables.
Una de las características de la optimización mediante metaheurísticas es el elevado número de iteraciones en el espacio de soluciones, lo cual permite generar una inmensa cantidad de datos para el conjunto de estructuras visitadas. Es el campo ideal para la inteligencia artificial, pues permite extraer información para acelerar y afinar la búsqueda de la solución óptima. Un ejemplo de este tipo es nuestro trabajo (García-Segura et al., 2017) de optimización multiobjetivo de puentes cajón, donde una red neuronal aprendía de los datos intermedios de la búsqueda y luego predecía con una extraordinaria exactitud el cálculo del puente, sin necesidad de calcularlo. Ello permitía reducir considerablemente el tiempo final de computación.
Sin embargo, este tipo de aplicación es muy sencilla, pues solo ha reducido el tiempo de cálculo (cada comprobación completa de un puente por el método de los elementos finitos es mucho más lenta que una predicción con una red neuronal). Se trata ahora de dar un paso más allá. Se trata de que la metaheurística sea capaz de aprender de los datos recogidos utilizando la inteligencia artificial para ser mucho más efectiva, y no solo más rápida.
Tanto la inteligencia artificial como el aprendizaje automático no son una ciencia nueva. El problema es que sus aplicaciones eran limitadas por la falta de datos y de tecnologías para procesarlas de forma rápida y eficiente. Hoy en día se ha dado un salto cualitativo y se puede utilizar el DL, que como ya hemos dicho es una parte del ML, pero que utiliza algoritmos más sofisticados, construidos a partir del principio de las redes neuronales. Digamos que el DL (redes neuronales) utiliza algoritmos distintos al ML (algoritmos de regresión, árboles de decisión, entre otros). En ambos casos, los algoritmos pueden aprender de forma supervisada o no supervisada. En las no supervisadas se facilitan los datos de entrada, no los de salida. La razón por la que se llama aprendizaje profundo hace referencia a las redes neuronales profundas, que utilizan un número elevado de capas en la red, digamos, por ejemplo, 1000 capas. De hecho, el DL también se le conoce a menudo como «redes neuronales profundas». Esta técnica de redes artificiales de neuronas es una de las técnicas más comunes del DL.
Figura. Esquema explicativo de diferencia entre ML y DL. https://www.privatewallmag.com/inteligencia-artificial-machine-deep-learning/
Una de las redes neuronales utilizadas en DL son las redes neuronales convolucionales, que es una variación del perceptrón multicapa, pero donde su aplicación se realiza en matrices bidimensionales, y por tanto, son muy efectivas en las tareas de visión artificial, como en la clasificación y segmentación de imágenes. En ingeniería, por ejemplo, se puede utilizar para la monitorización de la condición estructural, por ejemplo, para el análisis del deterioro. Habría que imaginar hasta dónde se podría llegar grabando en imágenes digitales la rotura en laboratorio de estructuras de hormigón y ver la capacidad predictiva de este tipo de herramientas si contaran con suficiente cantidad de datos. Todo se andará. Aquí os dejo una aplicación tradicional típica (Antoni Cladera, de la Universitat de les Illes Balears), donde se explica el modelo de rotura de una viga a flexión en la pizarra y luego se rompe la viga en el laboratorio. ¡Cuántos datos estamos perdiendo en la grabación! Un ejemplo muy reciente del uso del DL y Digital Image Correlation (DIC) aplicado a roturas de probetas en laboratorio es el trabajo de Gulgec et al. (2020).
Sin embargo, aquí nos interesa detenernos en la exploración de la integración específica del DL en las metaheurísticas con el objeto de mejorar la calidad de las soluciones o los tiempos de convergencia cuando se trata de optimizar estructuras. Un ejemplo de este camino novedoso en la investigación es la aplicabilidad de algoritmos que hibriden DL y metaheurísticas. Ya hemos publicado algunos artículos en este sentido aplicados a la optimización de muros de contrafuertes (Yepes et al., 2020; García et al., 2020a, 2020b). Además, hemos propuesto como editor invitado, un número especial en la revista Mathematics (indexada en el primer decil del JCR) denominado «Deep learning and hybrid-metaheuristics: novel engineering applications«.
Dejo a continuación un pequeño vídeo explicativo de las diferencias entre la inteligencia artificial, machine learning y deep learning.
Referencias:
FRISWELL, M.; MOTTERSHEAD, J. E. (1995). Finite element model updating in structural dynamics (Vol. 38). Dordrecht, Netherlands: Springer Science & Business Media.
GARCÍA-SEGURA, T.; YEPES, V.; FRANGOPOL, D.M. (2017). Multi-Objective Design of Post-Tensioned Concrete Road Bridges Using Artificial Neural Networks.Structural and Multidisciplinary Optimization, 56(1):139-150. DOI:1007/s00158-017-1653-0
GULGEC, N.S.; TAKAC, M., PAKZAD S.N. (2020). Uncertainty quantification in digital image correlation for experimental evaluation of deep learning based damage diagnostic.Structure and Infrastructure Engineering, https://doi.org/10.1080/15732479.2020.1815224