La inteligencia artificial (IA) está transformando de manera radical el diseño arquitectónico y la edificación. En la actualidad, el sector de la construcción se enfrenta a tres tendencias clave: la industrialización, la sostenibilidad y la transformación digital e inteligente. La convergencia de estos factores genera numerosas oportunidades, pero también desafíos significativos.
La inteligencia artificial (IA) está transformando de manera radical el diseño arquitectónico y la edificación. En la actualidad, el sector de la construcción se enfrenta a tres tendencias clave: la industrialización, la sostenibilidad y la transformación digital e inteligente. La convergencia de estos factores genera numerosas oportunidades, pero también desafíos significativos.
Los proyectos contemporáneos son cada vez más grandes y complejos, y están sujetos a requisitos ambientales más estrictos, lo que aumenta la presión sobre los equipos de diseño en términos de procesamiento de información, tiempo y recursos. En este contexto, la IA no solo optimiza los procesos, sino que también mejora la eficiencia de los métodos tradicionales de diseño.
A continuación, analizamos cómo la IA puede impulsar la eficiencia del diseño, fomentar la innovación y contribuir a la sostenibilidad de los proyectos. La tecnología ya está presente en todas las etapas del ciclo de vida del edificio, desde el análisis predictivo y la supervisión de la construcción hasta el mantenimiento de las instalaciones.
La digitalización ha transformado profundamente la forma en que concebimos, proyectamos y gestionamos las infraestructuras. Tras la aparición del diseño asistido por ordenador (CAD) y el modelado de información para la construcción (BIM), la inteligencia artificial (IA) se presenta como el siguiente gran avance tecnológico. A diferencia de otras herramientas, la IA no solo automatiza tareas, sino que también aprende, genera propuestas y ayuda a tomar decisiones complejas de manera óptima. Como señalan Li, Chen, Yu y Yang (2025), la IA se está consolidando como una herramienta fundamental para aumentar la eficiencia en el diseño arquitectónico e integrar criterios de sostenibilidad, industrialización y digitalización en toda la cadena de valor.
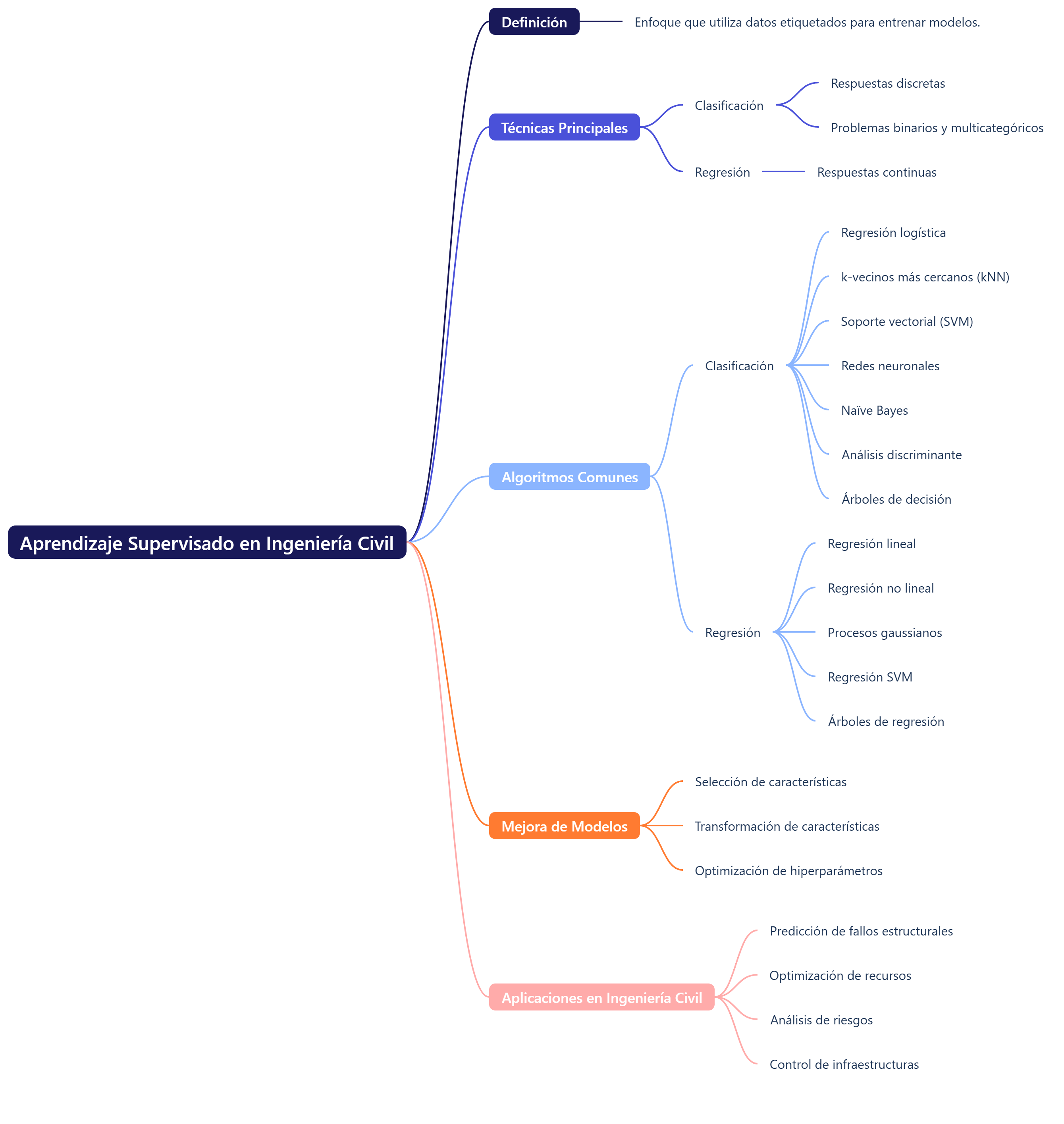
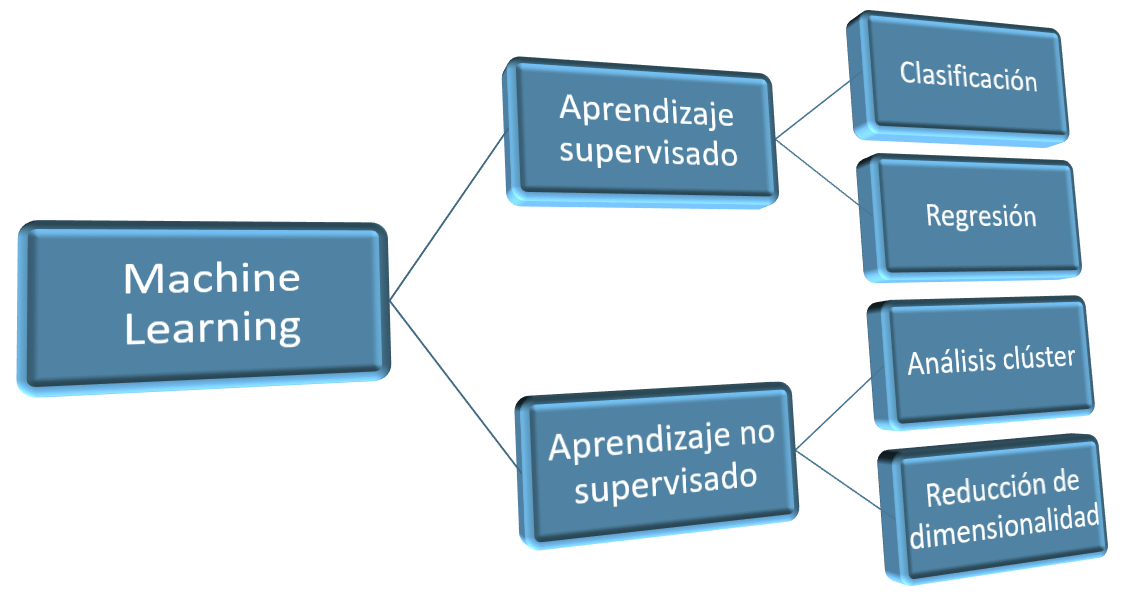
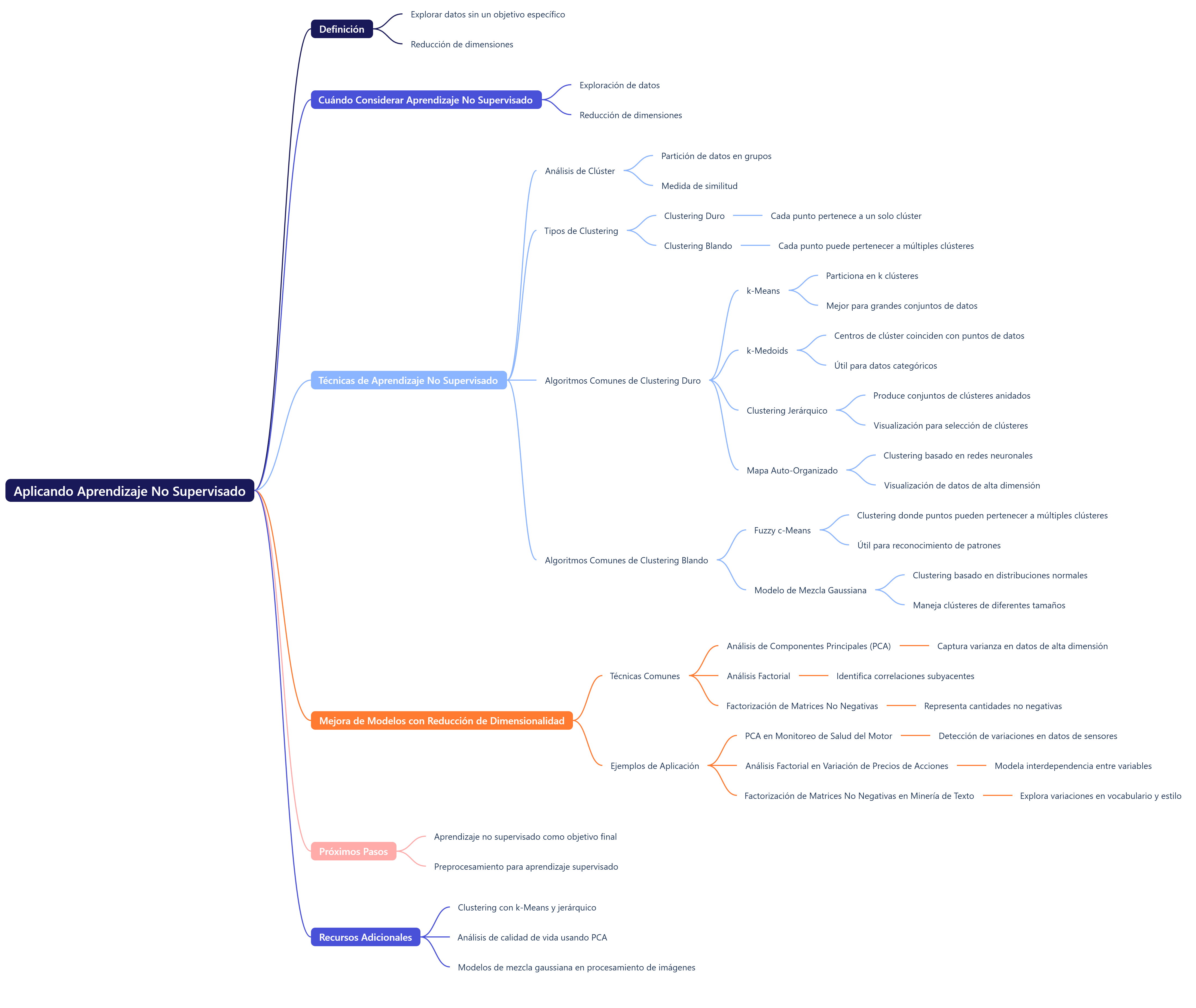
La IA se puede definir como un conjunto de técnicas informáticas que buscan reproducir procesos propios de la inteligencia humana, como el razonamiento, el aprendizaje o el reconocimiento de patrones. Entre sus ramas se incluyen el aprendizaje automático (machine learning o ML), basado en algoritmos que identifican patrones en grandes volúmenes de datos; las redes neuronales artificiales, que imitan el funcionamiento del cerebro y permiten resolver problemas complejos, como la predicción energética (Chen et al., 2023); los algoritmos genéticos, que simulan procesos evolutivos para hallar soluciones óptimas en problemas con múltiples variables, y la IA generativa, capaz de crear contenidos originales, como imágenes o planos, a partir de descripciones textuales. Este último enfoque, también conocido como AIGC (contenido generado por IA), ha popularizado herramientas como Stable Diffusion o Midjourney (Li et al., 2025).
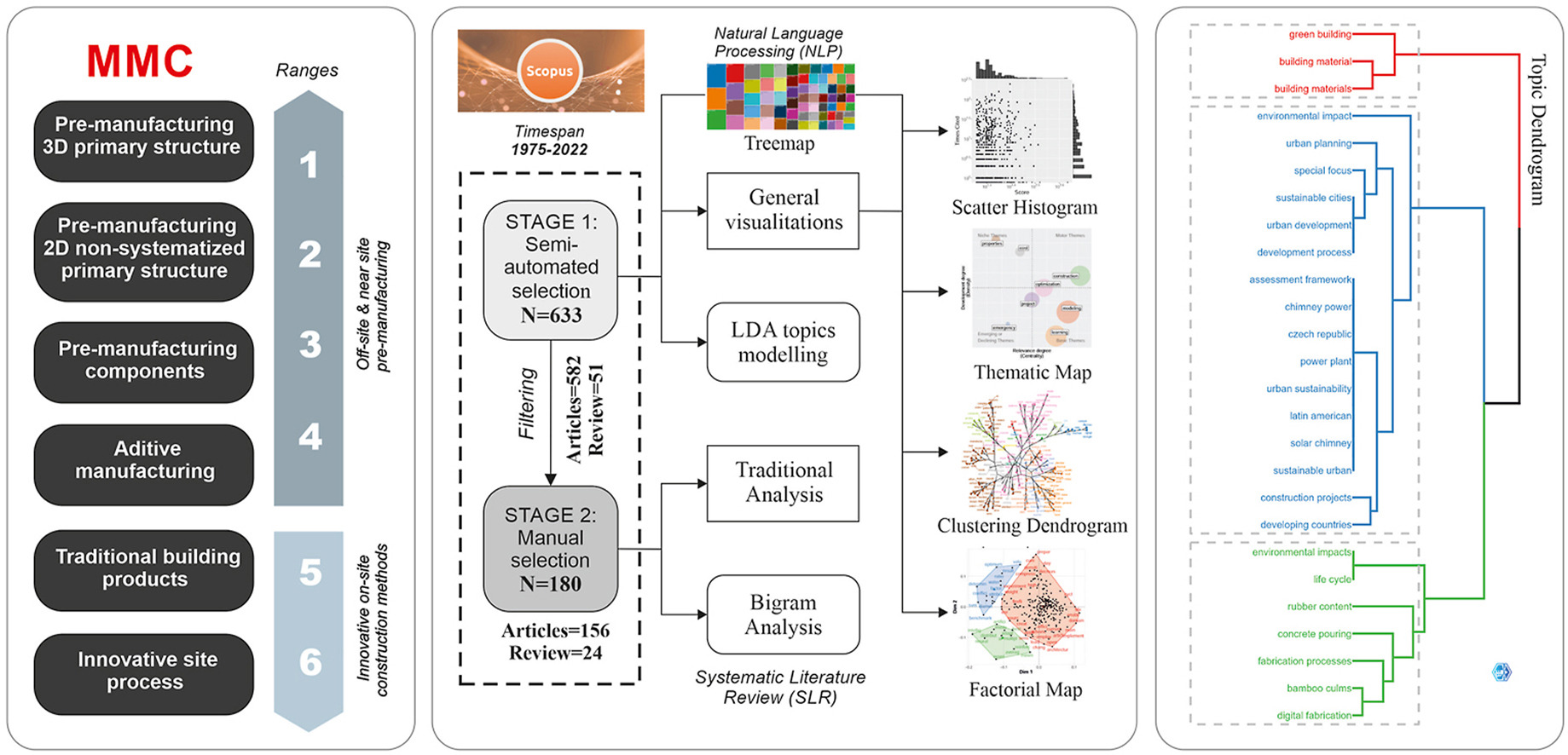
En el sector de la construcción confluyen tres grandes tendencias: la industrialización, vinculada a la modularización y la prefabricación de componentes; el desarrollo sostenible, que impulsa diseños energéticamente eficientes y con menor impacto ambiental; y la digitalización inteligente, en la que la IA desempeña un papel protagonista (Asif, Naeem y Khalid, 2024). Estas tres dinámicas están interrelacionadas: sin tecnologías de análisis avanzado, como la IA, sería mucho más difícil cumplir los objetivos de sostenibilidad o gestionar procesos constructivos industrializados.
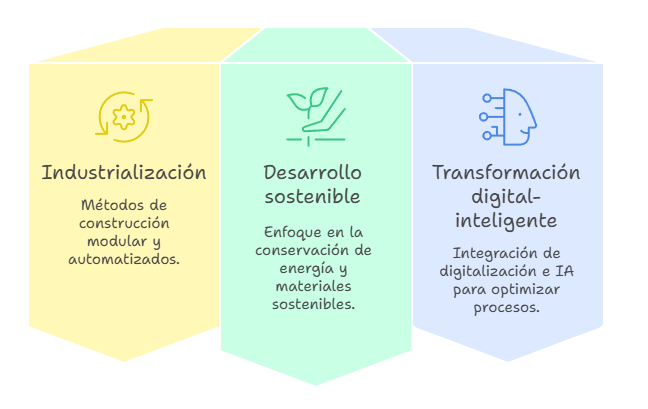
Las aplicaciones de la IA se extienden a lo largo de todo el ciclo de vida del edificio. En las primeras fases de diseño, los algoritmos generan en segundos múltiples alternativas de distribución, optimizando la orientación, la iluminación natural o la ventilación. El diseño paramétrico asistido por IA permite explorar variaciones infinitas ajustando solo unos pocos parámetros (Li et al., 2025). Durante la fase de proyecto, los sistemas basados en procesamiento del lenguaje natural pueden interpretar normativas y detectar incumplimientos de forma automática, lo que reduce la probabilidad de modificaciones en obra (Xu et al., 2024). Además, las técnicas de simulación permiten prever el comportamiento estructural, acústico o energético de un edificio antes de su construcción, lo que proporciona seguridad y precisión en la toma de decisiones.
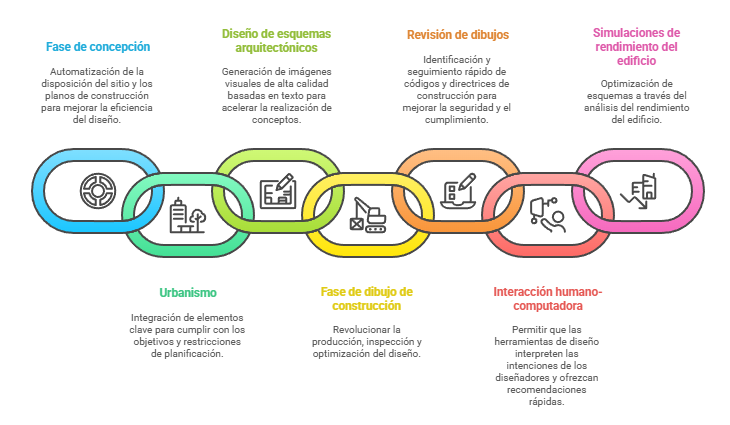
En el sector de la construcción, la IA se combina con sensores y análisis de datos en tiempo real para optimizar la producción y la logística. En la construcción industrializada, los algoritmos ajustan la fabricación de elementos prefabricados, optimizan los cortes y los ensamblajes, y mejoran la gestión de las obras (Li et al., 2025). Al mismo tiempo, la monitorización inteligente permite anticiparse a las desviaciones, planificar los recursos con mayor eficiencia e incrementar la seguridad en entornos complejos.
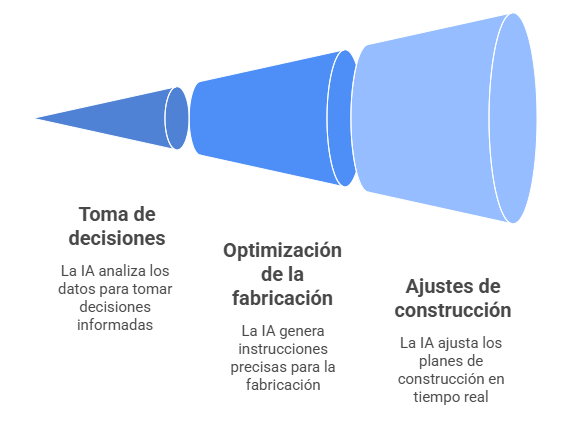
Uno de los campos más avanzados es la predicción y optimización del consumo energético. Algoritmos como las redes neuronales, las máquinas de soporte vectorial o los métodos evolutivos permiten modelizar con gran precisión el comportamiento energético, incluso en las fases preliminares (Chen et al., 2023). Gracias a estas técnicas, es posible seleccionar soluciones constructivas más sostenibles, diseñar envolventes eficientes e integrar energías renovables en el proyecto. Como señalan Ding et al. (2018), estas herramientas facilitan el cumplimiento de los sistemas de evaluación ambiental y apoyan la transición hacia edificios de energía casi nula.
Las ventajas de la IA son evidentes: aumenta la eficiencia, reduce los errores y permite generar múltiples alternativas en mucho menos tiempo (Li et al., 2025). También optimiza los aspectos energéticos y estructurales, lo que hace que los proyectos sean más fiables y competitivos. La automatización de tareas repetitivas agiliza la creación de planos y documentos, mientras que los profesionales pueden dedicarse a tareas creativas. Además, las herramientas de gestión de proyectos con IA ayudan a organizar mejor los recursos y los plazos. Gracias a su capacidad para analizar grandes volúmenes de datos, fomentan la innovación, diversifican los métodos de diseño y facilitan la selección de materiales y el rendimiento energético.

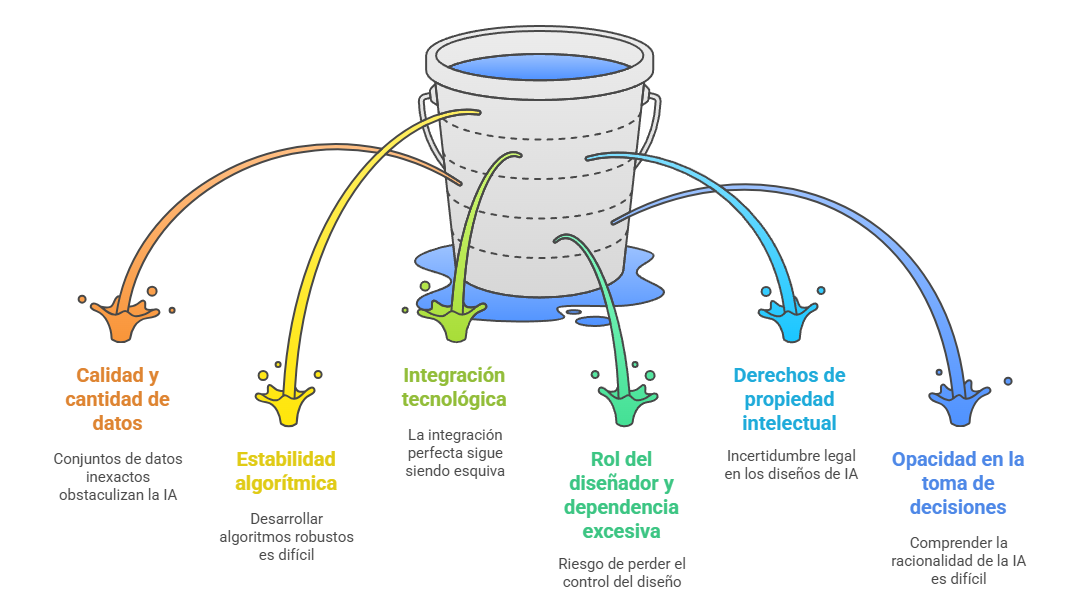
Sin embargo, la IA también plantea importantes desafíos. Su eficacia depende de la calidad de los datos; sin información fiable, los algoritmos pierden precisión. Además, integrarla con plataformas como CAD o BIM sigue siendo complicado (Xu et al., 2024). A esto se suman cuestiones éticas y legales, como la propiedad intelectual de los diseños generados por IA, la opacidad en la toma de decisiones y el riesgo de que los diseñadores pierdan cierto control. En algunos lugares, como EE. UU., se han revocado derechos de autor sobre obras generadas por IA, lo que refleja la incertidumbre legal existente.
Otros retos son la homogeneización del diseño si todos usan herramientas similares, la reticencia de algunos profesionales a adoptar soluciones de IA por dudas sobre la personalización y la fiabilidad, y los altos costes y la limitada disponibilidad de hardware y software especializados. Aún así, la IA sigue siendo una herramienta poderosa que, si se utiliza correctamente, puede transformar la eficiencia, la creatividad y la sostenibilidad en el sector de la construcción, abriendo un futuro lleno de oportunidades.
Ya existen ejemplos prácticos que muestran el potencial de estas tecnologías. Herramientas como Stable Diffusion o FUGenerator pueden generar imágenes y maquetas a partir de descripciones en lenguaje natural y actúan como asistentes que multiplican la productividad del proyectista (Li et al., 2025). Estas plataformas no sustituyen la creatividad humana, pero ofrecen un apoyo decisivo en la fase de ideación.
La IA se está convirtiendo en un pilar fundamental de la construcción, integrándose cada vez más con tecnologías como la realidad aumentada (RA), la realidad virtual (RV), la realidad mixta (RM) y los gemelos digitales. Gracias a esta combinación, no solo es posible visualizar cómo será un edificio, sino también anticipar su comportamiento estructural, energético o acústico antes de su construcción (Xu et al., 2024). Esto permite a los diseñadores y a los clientes evaluar las propuestas en las primeras etapas, lo que mejora la calidad del diseño y la experiencia del usuario.
La IA del futuro será más inteligente y adaptable, capaz de predecir con gran precisión los resultados del diseño y ofrecer soluciones personalizadas. Su impacto no se limita al diseño arquitectónico: la gestión de la construcción se beneficiará de la robótica asistida, lo que aumentará la seguridad y la eficiencia en tareas complejas o de alto riesgo; la operación de los edificios podrá monitorizar su rendimiento, anticipar las necesidades de mantenimiento y prolongar su vida útil, lo que reducirá los costes, y el análisis de mercado aprovechará el big data para prever la demanda y los precios de los materiales, lo que optimizará la cadena de suministro.
En ingeniería civil, la integración de la IA y las tecnologías avanzadas permite tomar decisiones más fundamentadas, minimizar riesgos y entregar proyectos más seguros y sostenibles (Xu et al., 2024). Así, la construcción del futuro se perfila como un proceso más eficiente, innovador y conectado, en el que la tecnología y la planificación estratégica trabajan juntas para lograr resultados óptimos.
En conclusión, la IA no pretende sustituir a los ingenieros y arquitectos, sino ampliar sus capacidades, como ya hicieron el CAD o el BIM (Asif et al., 2024; Li et al., 2025). Automatiza tareas repetitivas, agiliza el diseño, facilita la toma de decisiones basada en datos y ayuda a elegir materiales, mejorar la eficiencia energética y estructural e inspirar soluciones creativas. Su impacto trasciende el diseño y se extiende a la planificación, la supervisión de la construcción y la gestión del ciclo de vida del edificio. No obstante, su adopción plantea desafíos como los altos costes, la escasez de software disponible y la necesidad de contar con datos de calidad y algoritmos robustos. Si se depende en exceso de la IA, los diseños podrían homogeneizarse, por lo que es fundamental definir claramente los roles entre los arquitectos y la IA. Si se utiliza correctamente, la IA puede potenciar la creatividad, la eficiencia y la sostenibilidad, y ofrecer un futuro más innovador y dinámico para la construcción.
Os dejo un vídeo que resume las ideas más importantes.
Referencias:
-
Li, Y., Chen, H., Yu, P., & Yang, L. (2025). A review of artificial intelligence in enhancing architectural design efficiency. Applied Sciences, 15(3), 1476. https://doi.org/10.3390/app15031476
- García, J., Villavicencio, G., Altimiras, F., Crawford, B., Soto, R., Minatogawa, V., Franco, M., Martínez-Muñoz, D., & Yepes, V. (2022). Machine learning techniques applied to construction: A hybrid bibliometric analysis of advances and future directions. Automation in Construction, 142, 104532.
-
Asif, M., Naeem, G., & Khalid, M. (2024). Digitalization for sustainable buildings: Technologies, applications, potential, and challenges. Journal of Cleaner Production, 450, 141814. https://doi.org/10.1016/j.jclepro.2024.141814
-
Ding, Z. K., Fan, Z., Tam, V. W. Y., Bian, Y., Li, S. H., Illankoon, I. M. C. S., & Moon, S. K. (2018). Green building evaluation system implementation. Building and Environment, 133, 32–40.https://doi.org/10.1016/j.buildenv.2018.02.012
- Maureira, C., Pinto, H., Yepes, V., & García, J. (2021). Towards an AEC-AI industry optimization algorithmic knowledge mapping: an adaptive methodology for macroscopic conceptual analysis. IEEE Access, 9, 110842-110879.
-
Xu, K., Chen, Z., Xiao, F., Zhang, J., Zhang, H. B., & Ma, T. Y. (2024). Semantic model-based large-scale deployment of AI-driven building management applications. Automation in Construction, 165, 105579. https://doi.org/10.1016/j.autcon.2024.105579
-
Chen, Z. L., O’Neill, Z., Wen, J., Pradhan, O., Yang, T., Lu, X., Lin, G. J., Miyata, S. H., Lee, S. J., & Shen, C. (2023). A review of data-driven fault detection and diagnostics for building HVAC systems. Applied Energy, 339, 121030. https://doi.org/10.1016/j.apenergy.2023.121030
Glosario de términos clave
- Inteligencia Artificial (IA): Una disciplina científica y tecnológica de vanguardia que simula el aprendizaje y la innovación humanos para extender el alcance de la aplicación de la tecnología.
- Inteligencia Artificial Generativa (GAI): Un subconjunto de la IA que utiliza el aprendizaje automático y las capacidades de procesamiento del lenguaje natural para que las computadoras simulen la creatividad y el juicio humanos, produciendo automáticamente contenido que cumple con los requisitos.
- Diseño Paramétrico: Un método de diseño en el que se utilizan algoritmos para definir la relación entre los elementos de diseño, permitiendo la generación de diversas variaciones de diseño mediante el ajuste de parámetros.
- Diseño Asistido por IA: Métodos en los que las herramientas de IA ayudan a los diseñadores a optimizar diseños, analizar datos, resolver problemas y explorar conceptos creativos.
- Colaboración Hombre-Máquina: Un enfoque en el que humanos y máquinas trabajan juntos en tareas complejas, con la IA apoyando la innovación humana y el intercambio de información eficiente.
- Redes Neuronales Artificiales (RNA o ANN): Un tipo de algoritmo de IA, modelado a partir del cerebro humano, que se utiliza para modelar relaciones complejas entre entradas y salidas, a menudo empleadas en la predicción del consumo de energía de los edificios.
- Aprendizaje Profundo (Deep Learning): Un subcampo del aprendizaje automático que utiliza redes neuronales con múltiples capas (redes neuronales profundas o DNN) para aprender representaciones de datos con múltiples niveles de abstracción.
- Redes Neuronales Profundas (DNN): Redes neuronales con numerosas capas ocultas que permiten que el modelo aprenda patrones más complejos en los datos, mejorando la precisión en tareas como la predicción del consumo de energía.
- Máquinas de Vectores de Soporte (SVM): Un algoritmo de aprendizaje supervisado utilizado para tareas de clasificación y regresión, especialmente eficaz con conjuntos de datos pequeños y para identificar relaciones no lineales.
- Procesamiento del Lenguaje Natural (PLN o NLP): Un campo de la IA que se ocupa de la interacción entre las computadoras y el lenguaje humano, permitiendo a los sistemas interpretar y generar lenguaje humano.
- Modelado de Información de Construcción (BIM): Una metodología para la gestión de la información de construcción a lo largo de su ciclo de vida, utilizada con la IA para mejorar las simulaciones de rendimiento del edificio.
- Algoritmos Genéticos (GA): Una clase de algoritmos de optimización inspirados en el proceso de selección natural, utilizados para encontrar soluciones óptimas en tareas de diseño complejas.
- Adaptación de Bajo Rango (LoRA): Un método de ajuste de bajo rango para modelos de lenguaje grandes, que permite modificar el comportamiento de los modelos añadiendo y entrenando nuevas capas de red sin alterar los parámetros del modelo original.
- Stable Diffusion: Una herramienta avanzada de IA para generar imágenes a partir de descripciones de texto o dibujos de referencia, que a menudo utiliza el modelo LoRA para estilos específicos.
- Inception Score (IS) y Fréchet Inception Distance (FID): Métricas cuantitativas utilizadas para evaluar la calidad y diversidad de las imágenes generadas por modelos de IA, con IS evaluando la calidad y FID la similitud de la distribución entre imágenes reales y generadas.
- FUGenerator: Una plataforma que integra varios modelos de IA (como Diffusion Model, GAN, CLIP) para respaldar múltiples escenarios de aplicación de diseño arquitectónico, desde la descripción semántica hasta la generación de bocetos y el control.
- Industrialización (en construcción): Énfasis en métodos de construcción modulares y automatizados para mejorar la eficiencia y estandarización.
- Desarrollo Ecológico (en construcción): Enfoque en la conservación de energía durante el ciclo de vida, el uso de materiales sostenibles y la reducción del impacto ambiental.
- Transformación Digital-Inteligente (en construcción): Integración de sistemas de digitalización e inteligencia, aprovechando tecnologías como la GAI para optimizar procesos y mejorar la creación de valor.
- Problema Mal Definido (Ill-defined problem): Problemas de diseño, comunes en arquitectura, que tienen propósitos y medios iniciales poco claros.
- Problema Malicioso (Wicked problem): Problemas de diseño caracterizados por interconexiones y objetivos poco claros, que requieren enfoques de resolución complejos.
- Integración del Internet de las Cosas (IoT): La interconexión de dispositivos físicos con sensores, software y otras tecnologías para permitir la recopilación y el intercambio de datos, crucial para los sistemas de control de edificios inteligentes

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.