Introducción: El genio oculto en el caos natural.
Introducción: El genio oculto en el caos natural.
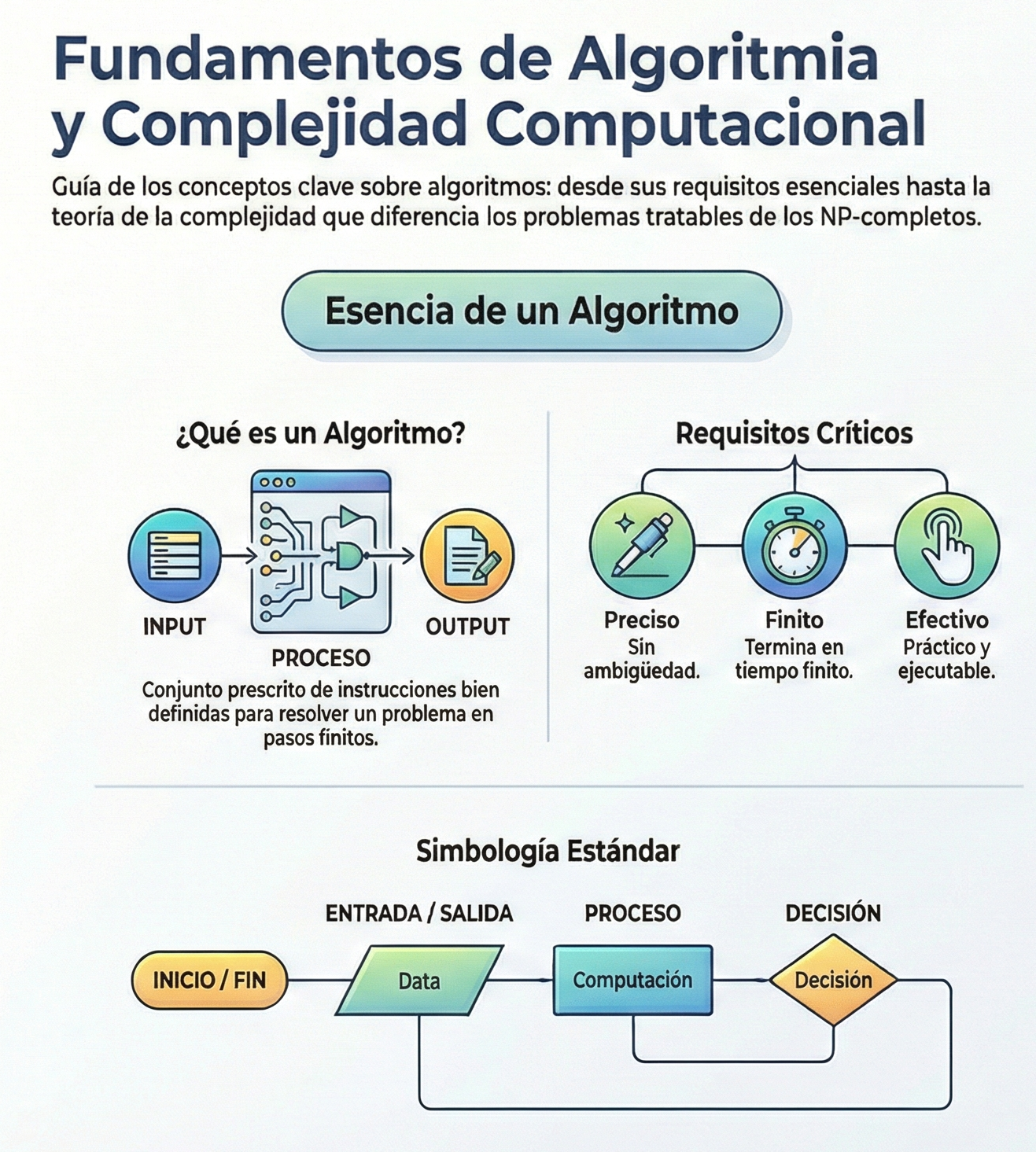
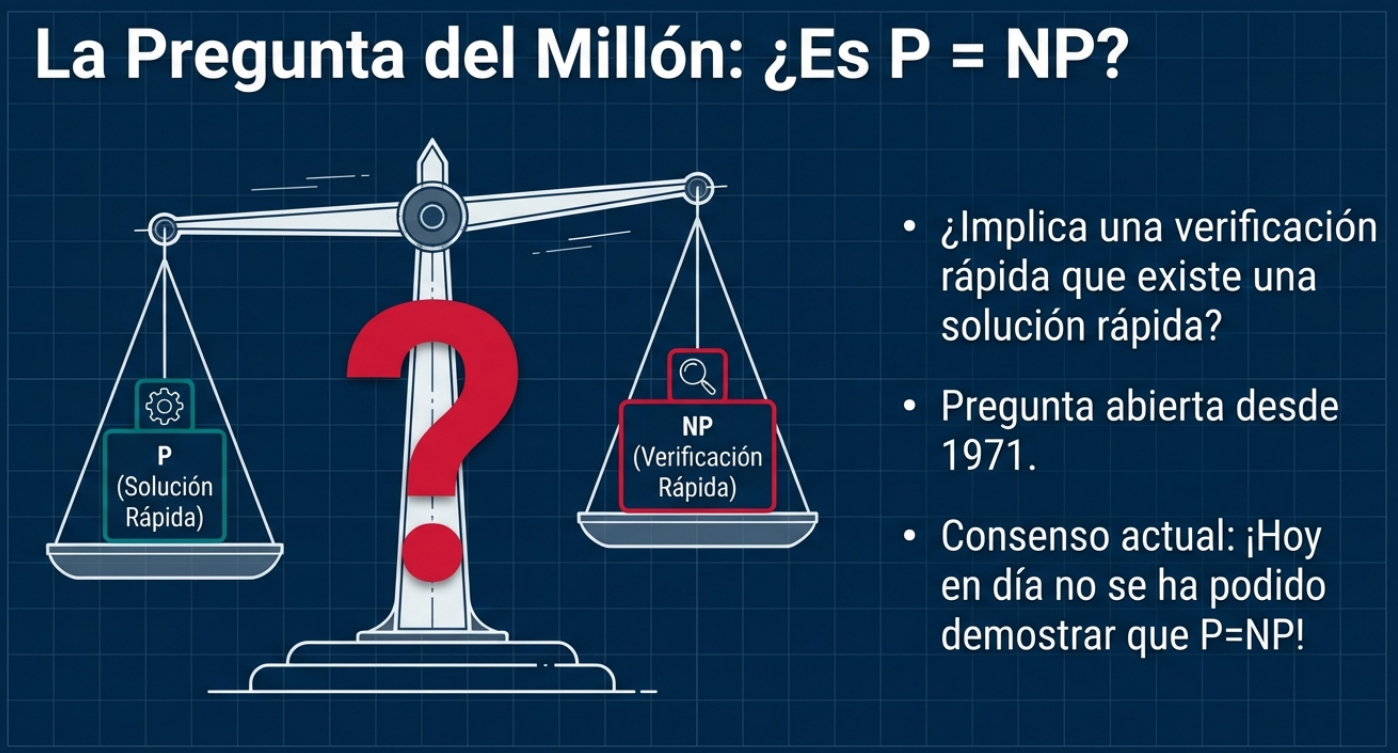
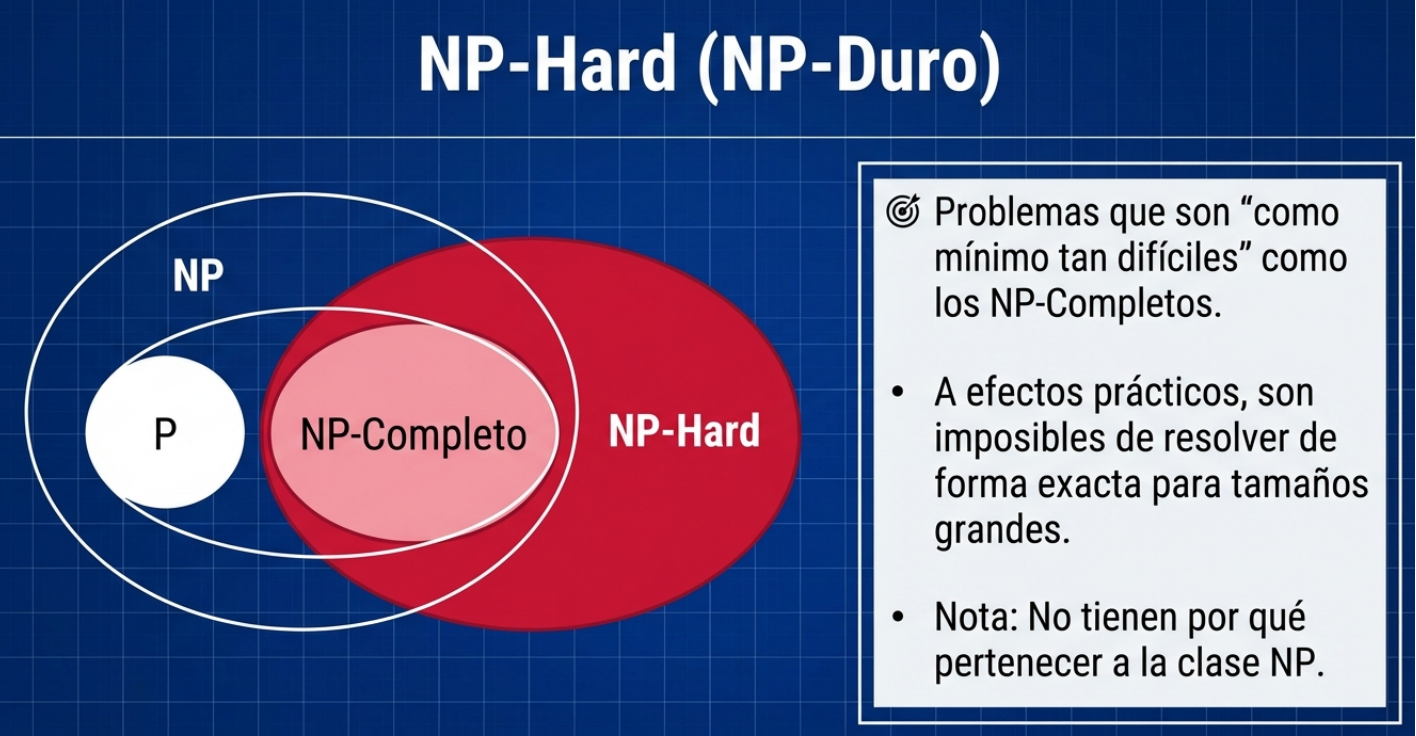
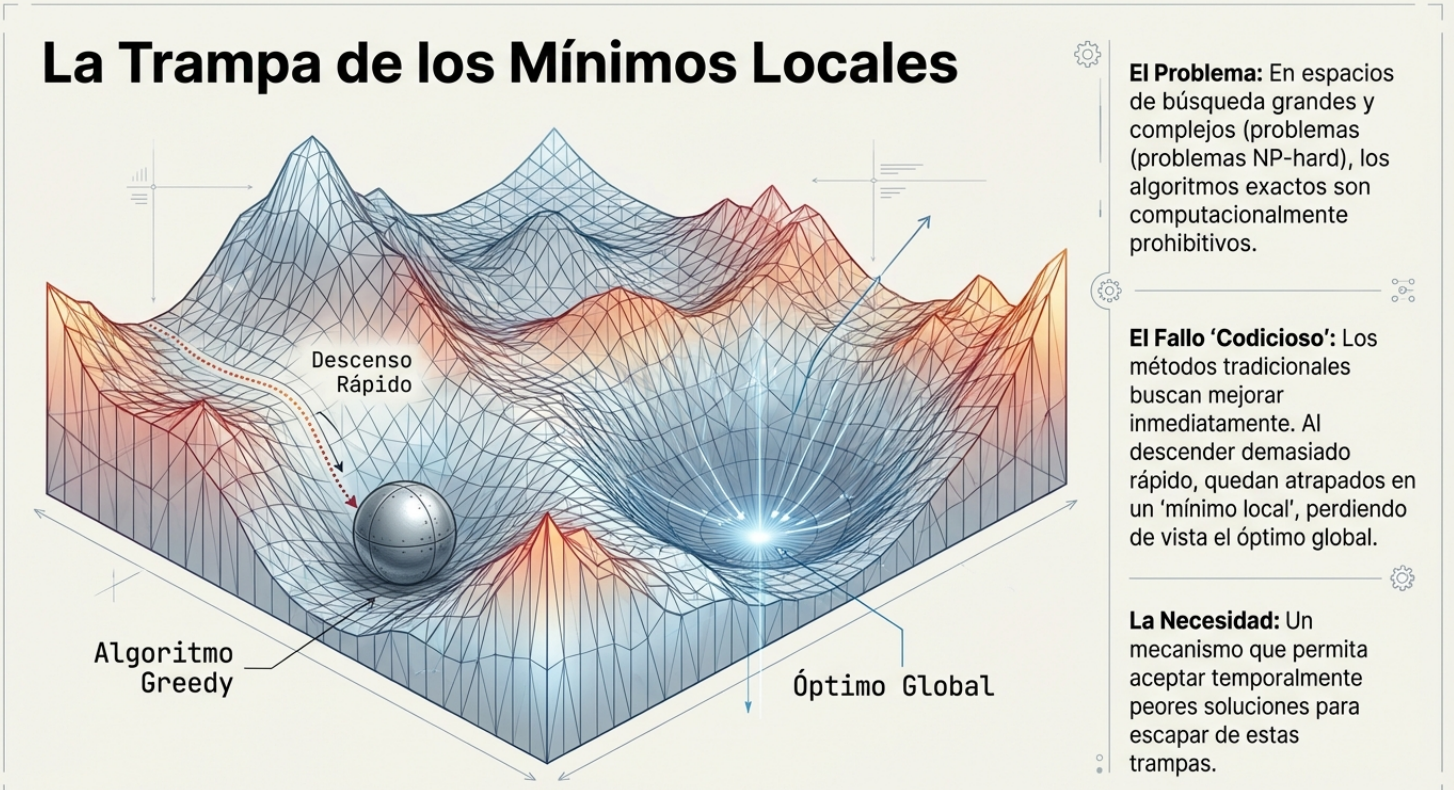
En el vasto universo de la gestión de situaciones complejas, nos enfrentamos a desafíos que cuestionan la lógica convencional: los problemas NP-difíciles.
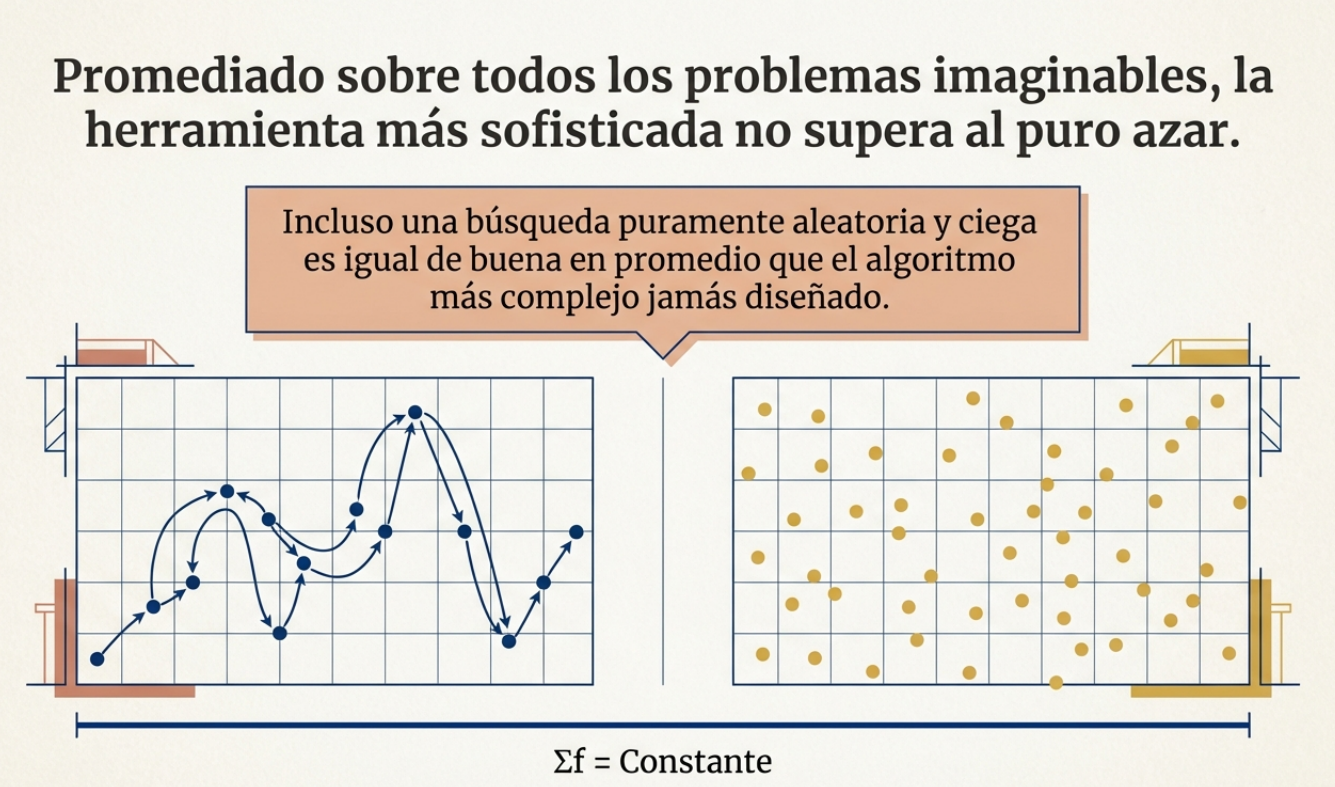
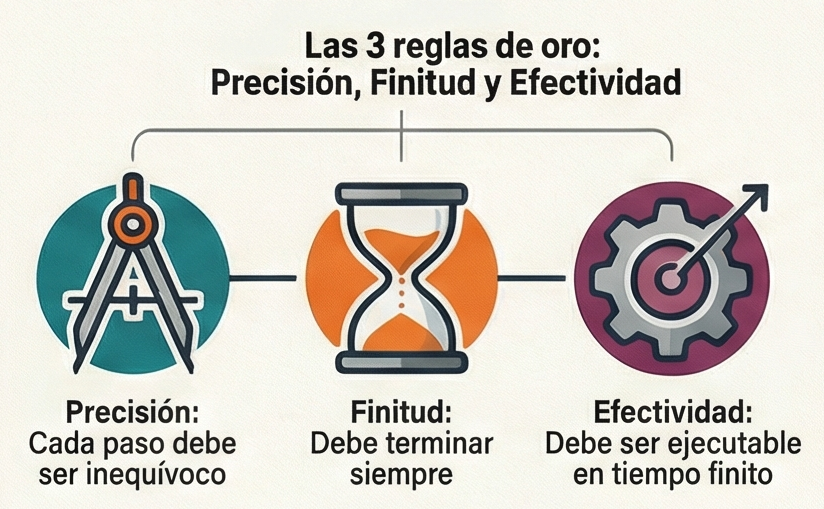
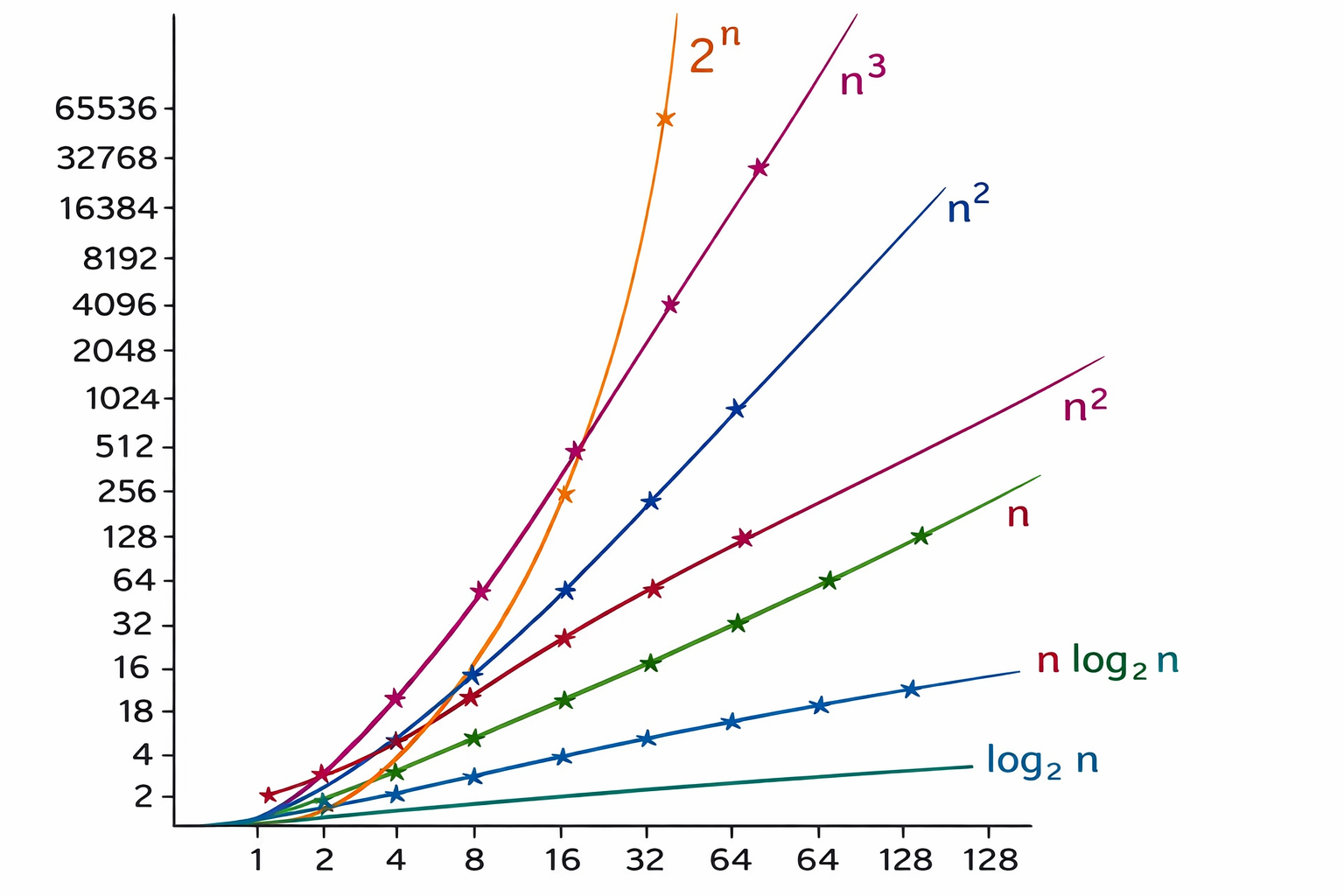
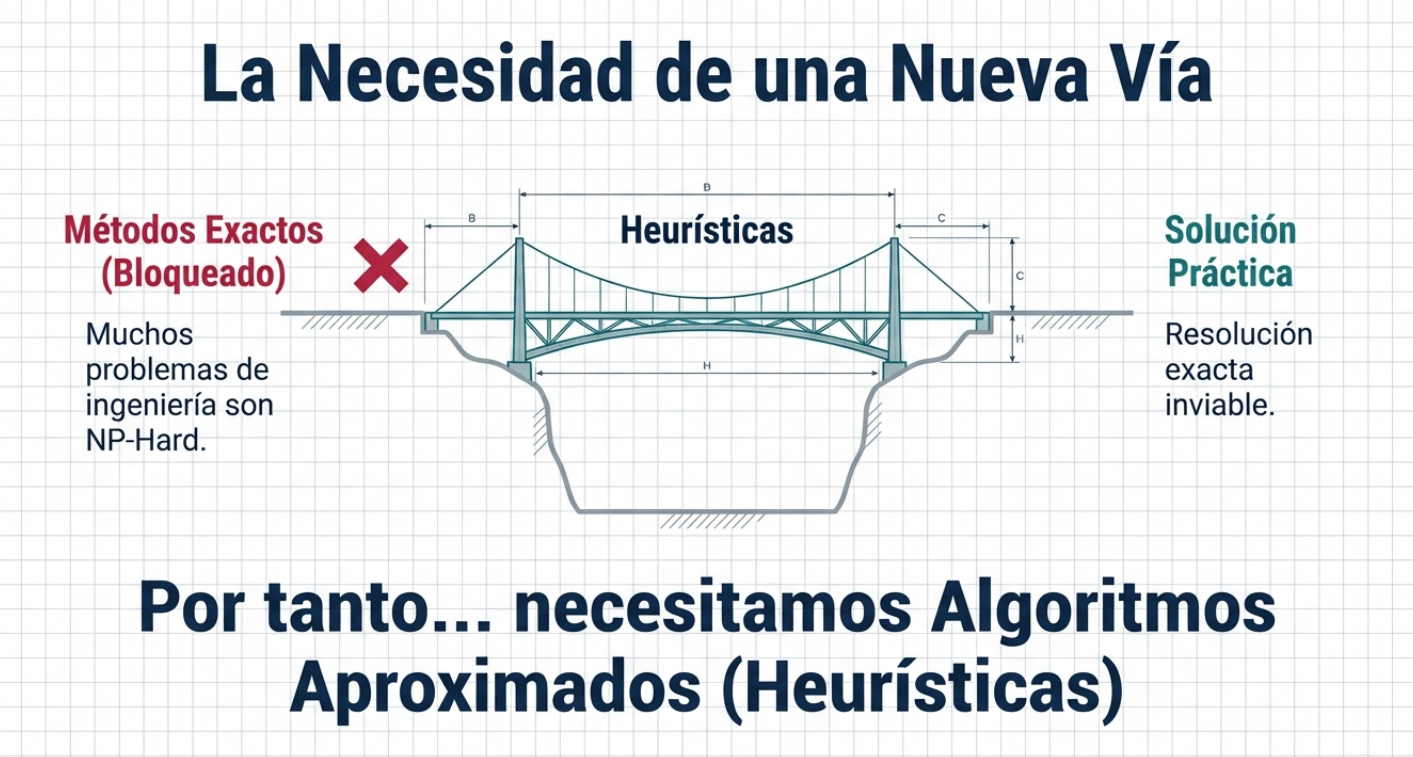
Estos enigmas se caracterizan por que, a medida que el tamaño del problema aumenta, el tiempo necesario para resolverlo mediante fuerza bruta crece de manera exponencial. Esto hace que una búsqueda exhaustiva sea prácticamente imposible, incluso para las supercomputadoras más potentes. De este modo, cuando los métodos deterministas fallan y no hay garantía de hallar la solución perfecta, los expertos recurren a las metaheurísticas.
Al observar cómo la naturaleza optimiza los recursos para la supervivencia, hemos descubierto que el ensayo y el error no son fruto del azar, sino de un diseño refinado a lo largo de milenios de evolución. Los investigadores han dejado de mirar exclusivamente las pizarras para descifrar el genio oculto en los sistemas biológicos, físicos y químicos y han traducido procesos naturales en ecuaciones de optimización asombrosamente eficientes.
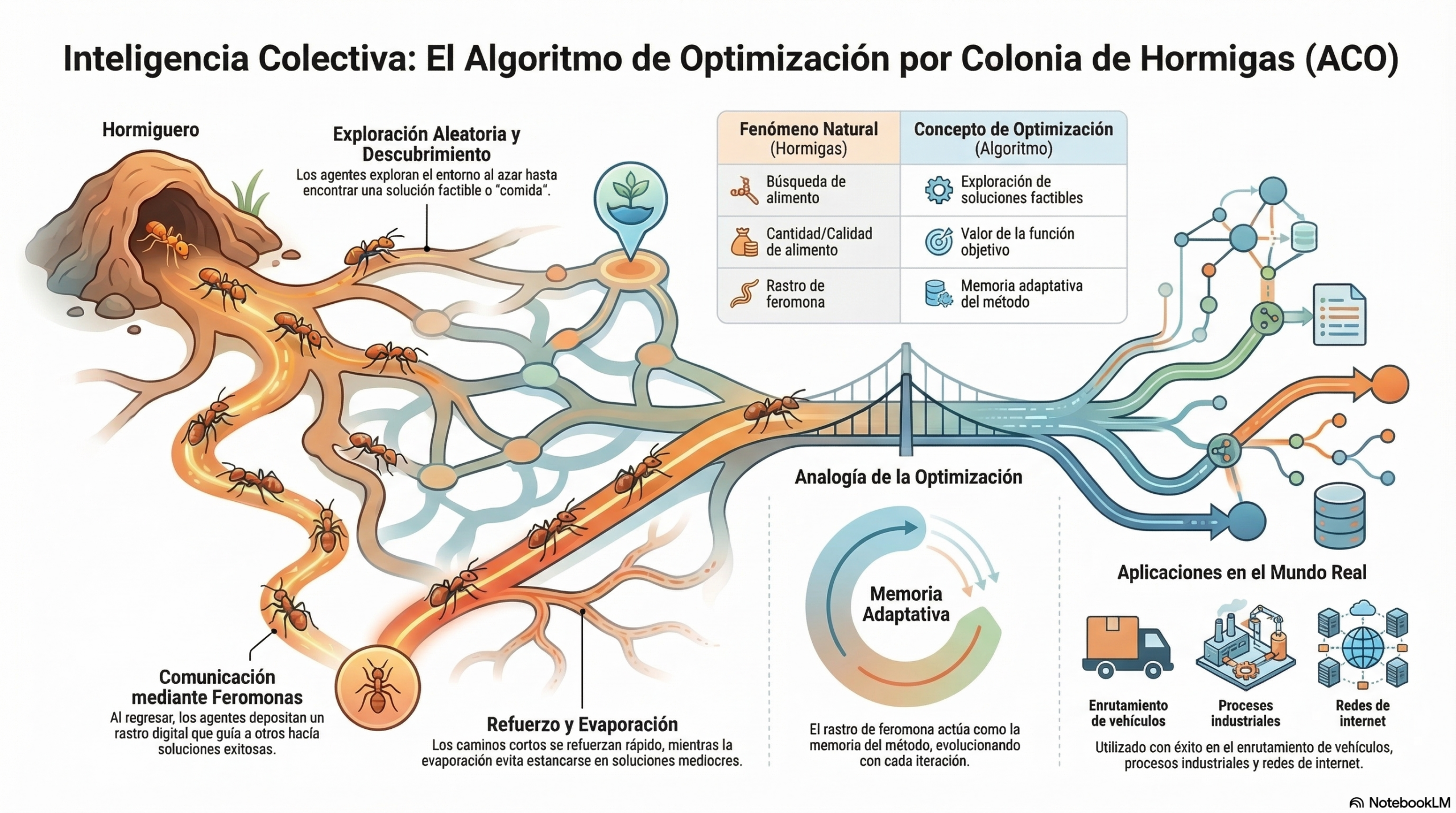
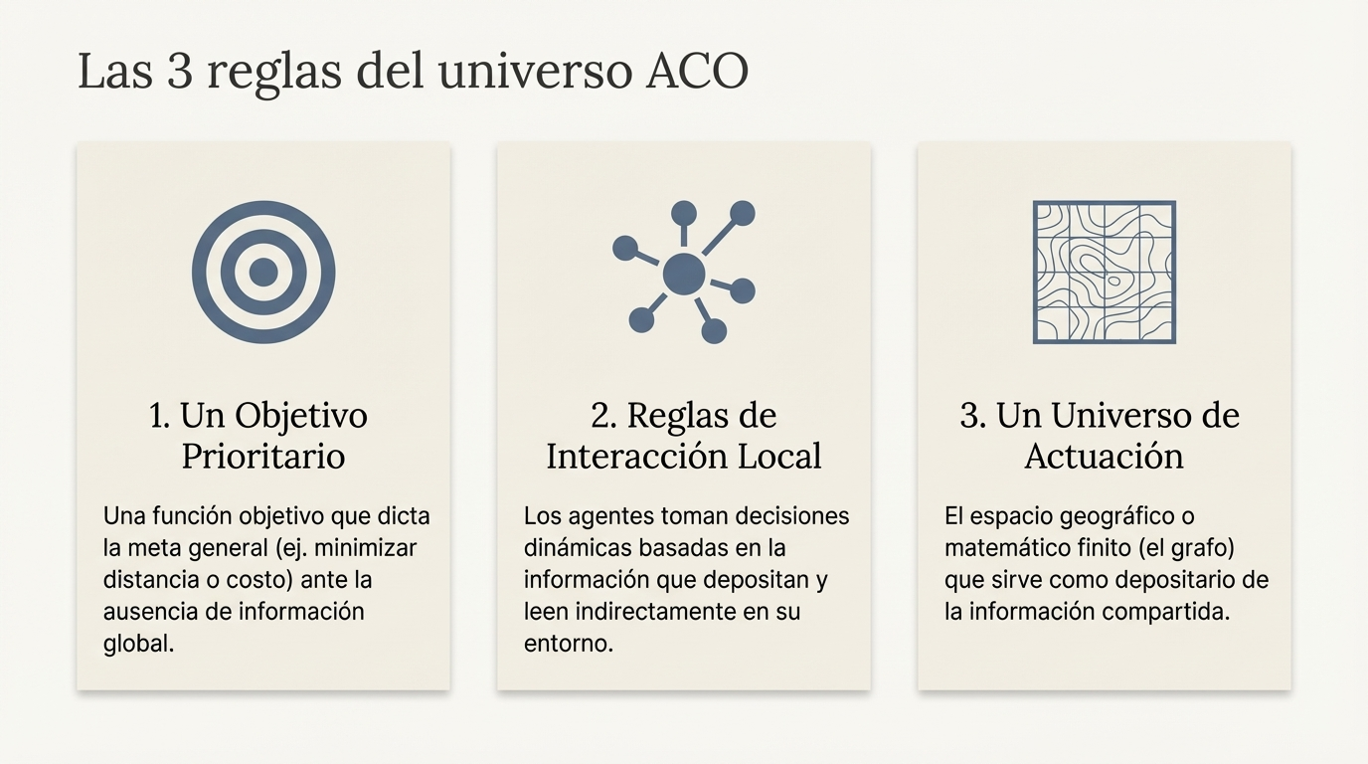
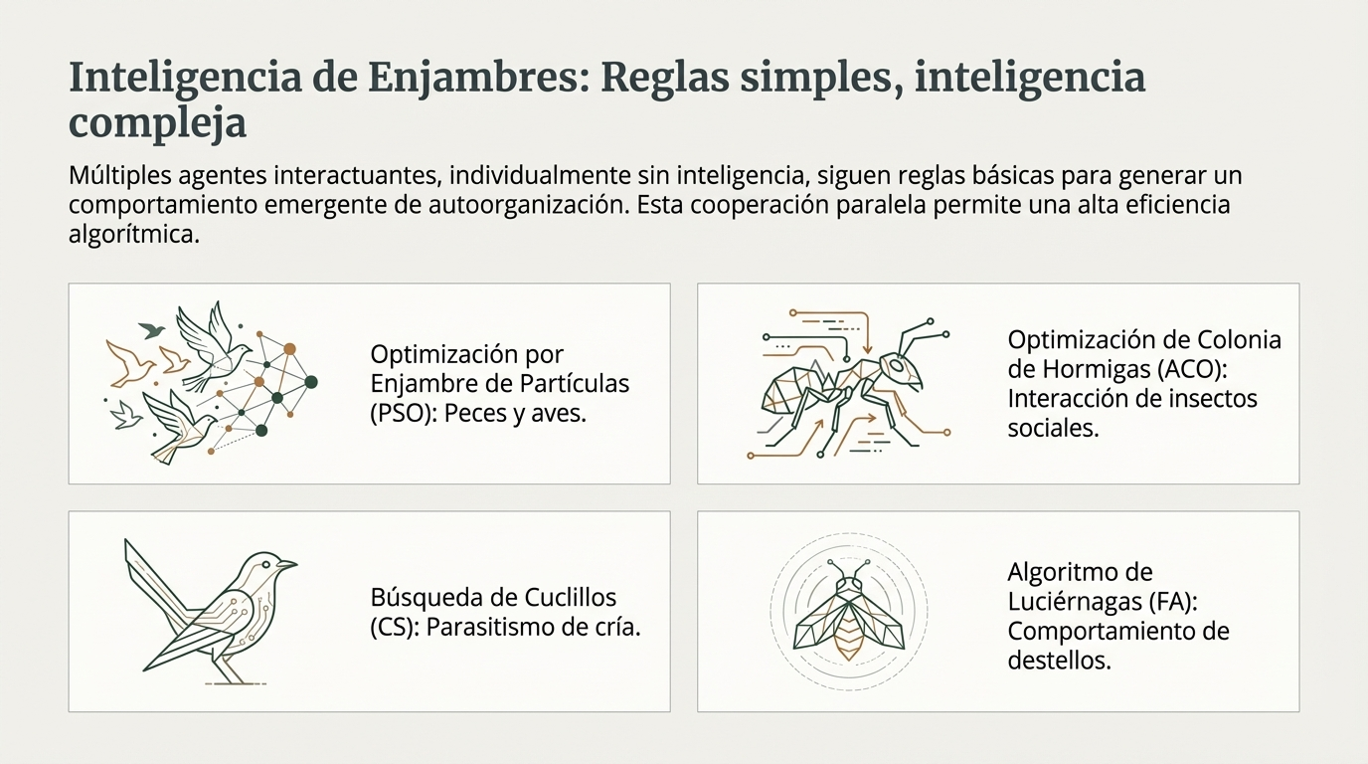
La inteligencia de enjambre: el poder de la multitud «sin inteligencia».
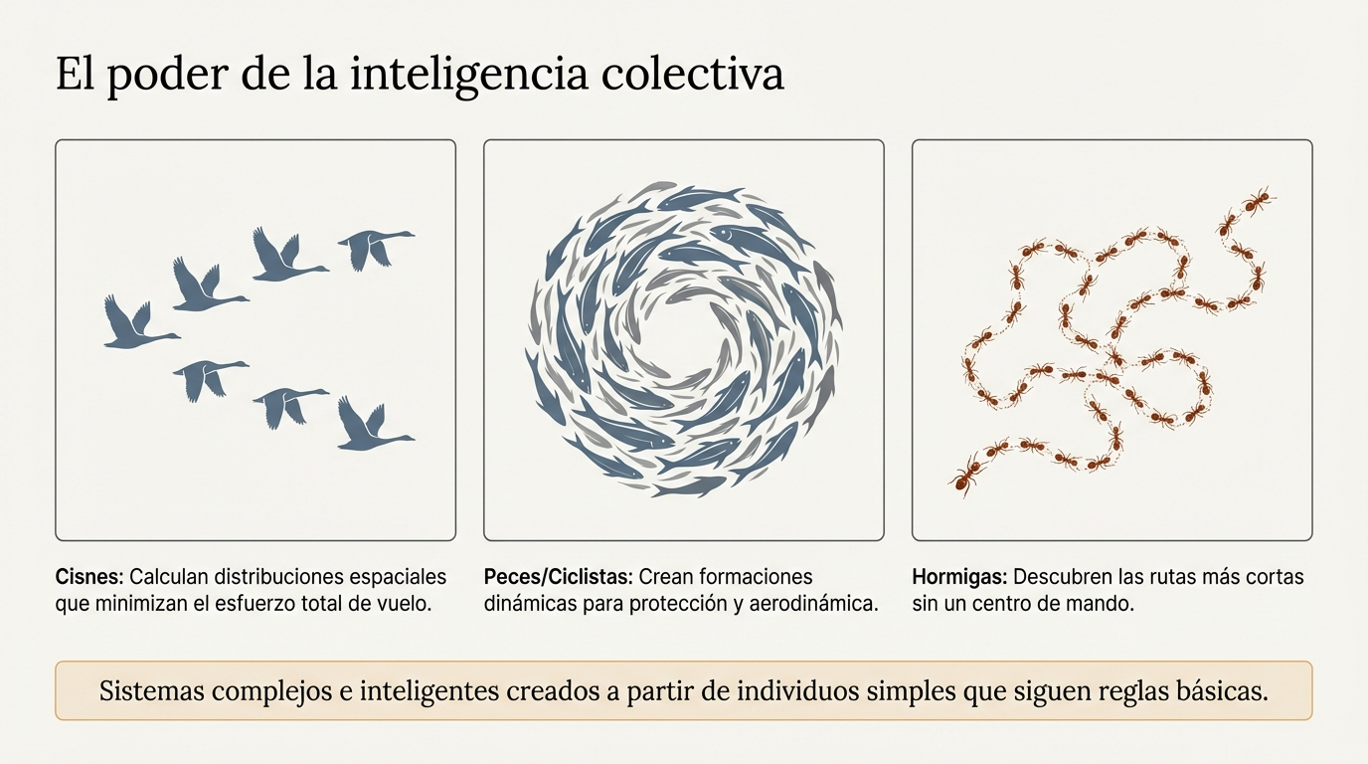
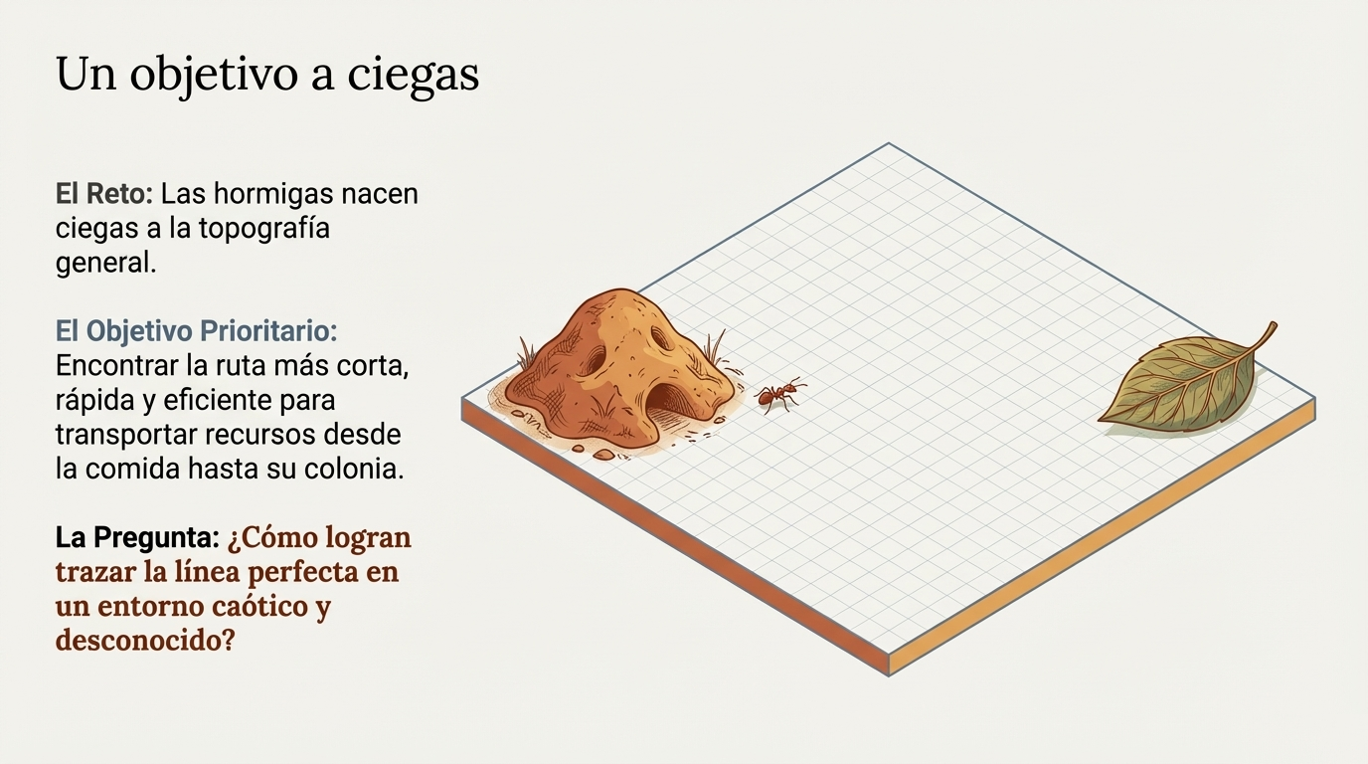
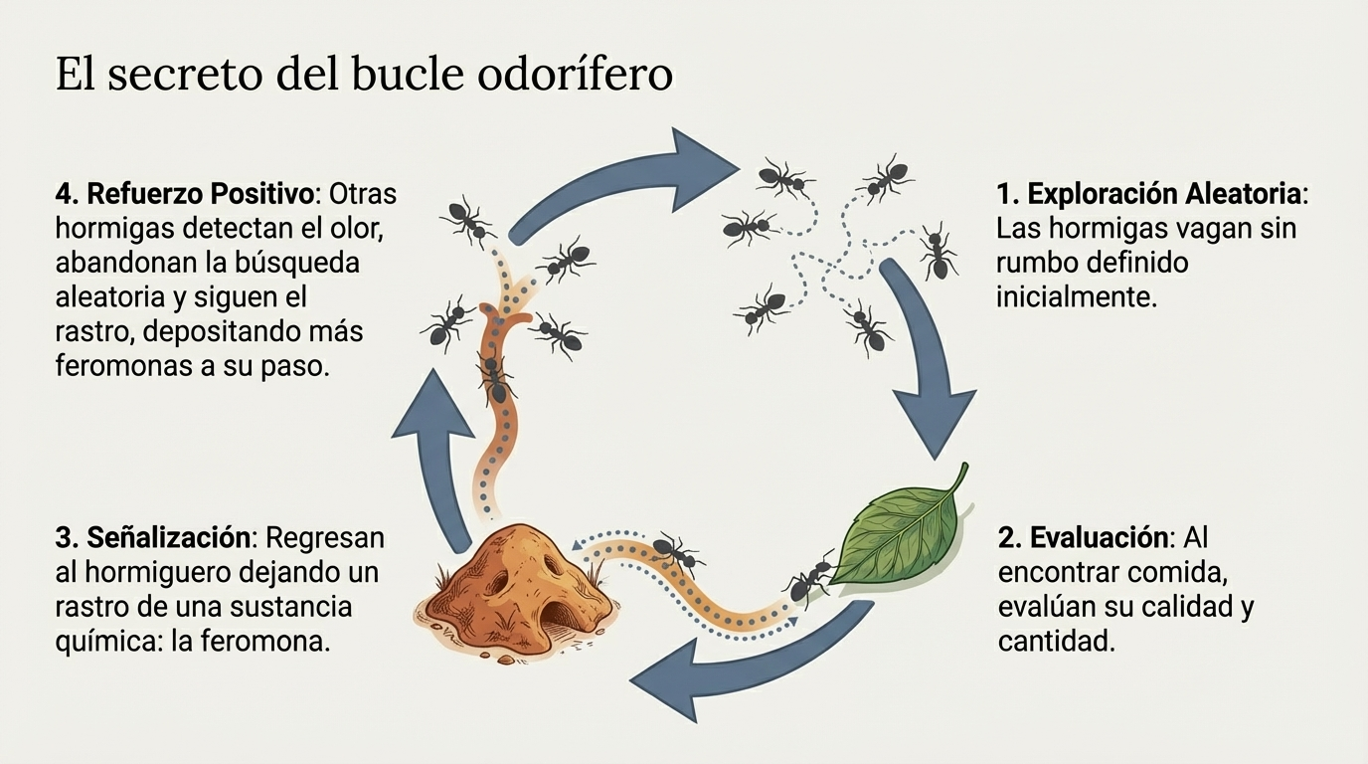
Uno de los pilares más fascinantes de esta disciplina es la inteligencia de enjambre (SI, por sus siglas en inglés). Este concepto se basa en el comportamiento colectivo emergente de múltiples agentes que interactúan según reglas muy sencillas. Ya sea en colonias de hormigas, enjambres de abejas o destellos de luciérnagas, el sistema logra una autorganización compleja sin necesidad de un mando central.
Lo más sorprendente es cómo la capacidad del colectivo trasciende las limitaciones del individuo. Un solo agente puede ser limitado, pero el enjambre, como unidad, exhibe una gran capacidad para resolver problemas. Como señala la literatura académica sobre este fenómeno:
«Aunque cada agente puede ser considerado como ininteligente, el sistema completo de múltiples agentes puede mostrar un comportamiento de autoorganización y, por lo tanto, puede comportarse como una suerte de inteligencia colectiva».
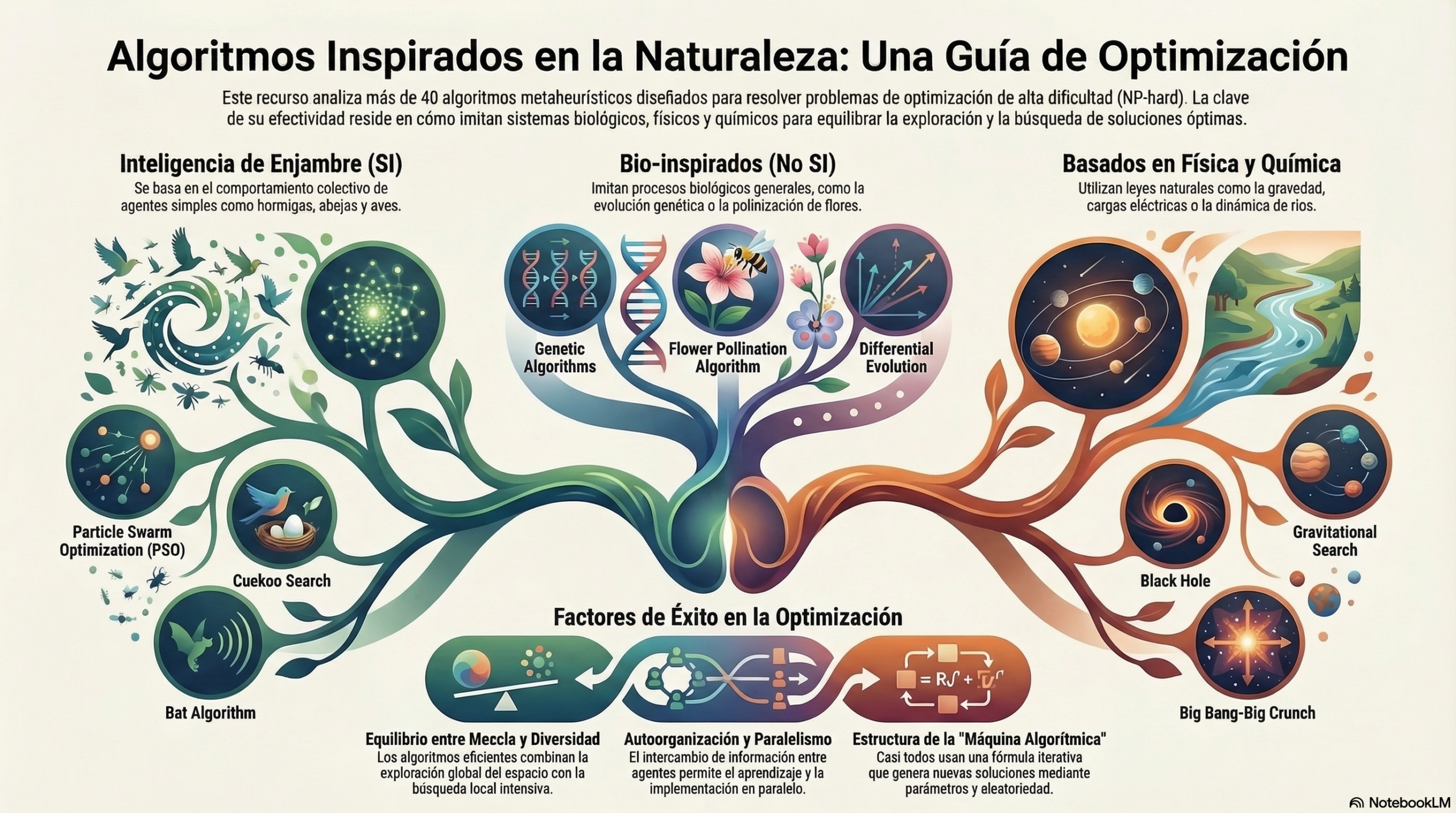
Más allá de la biología: la optimización se encuentra con la física y la música.
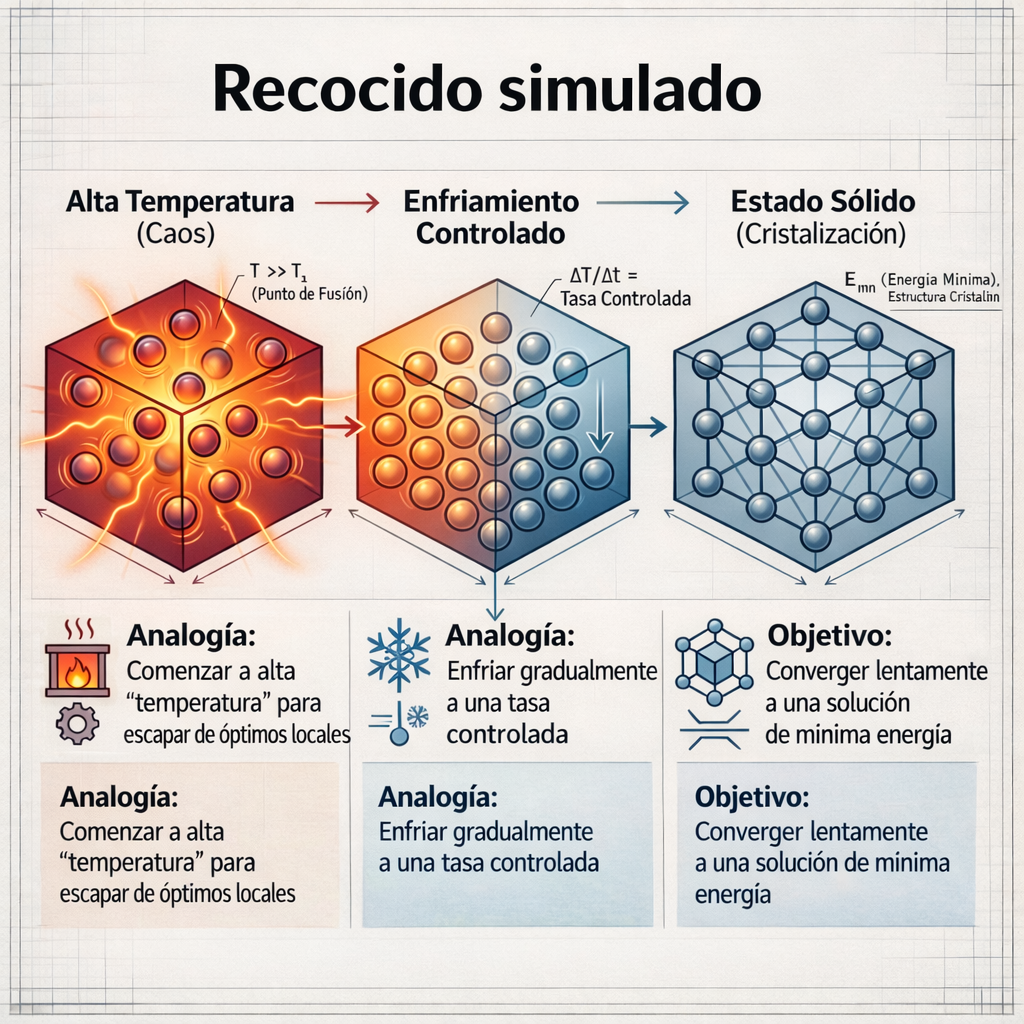
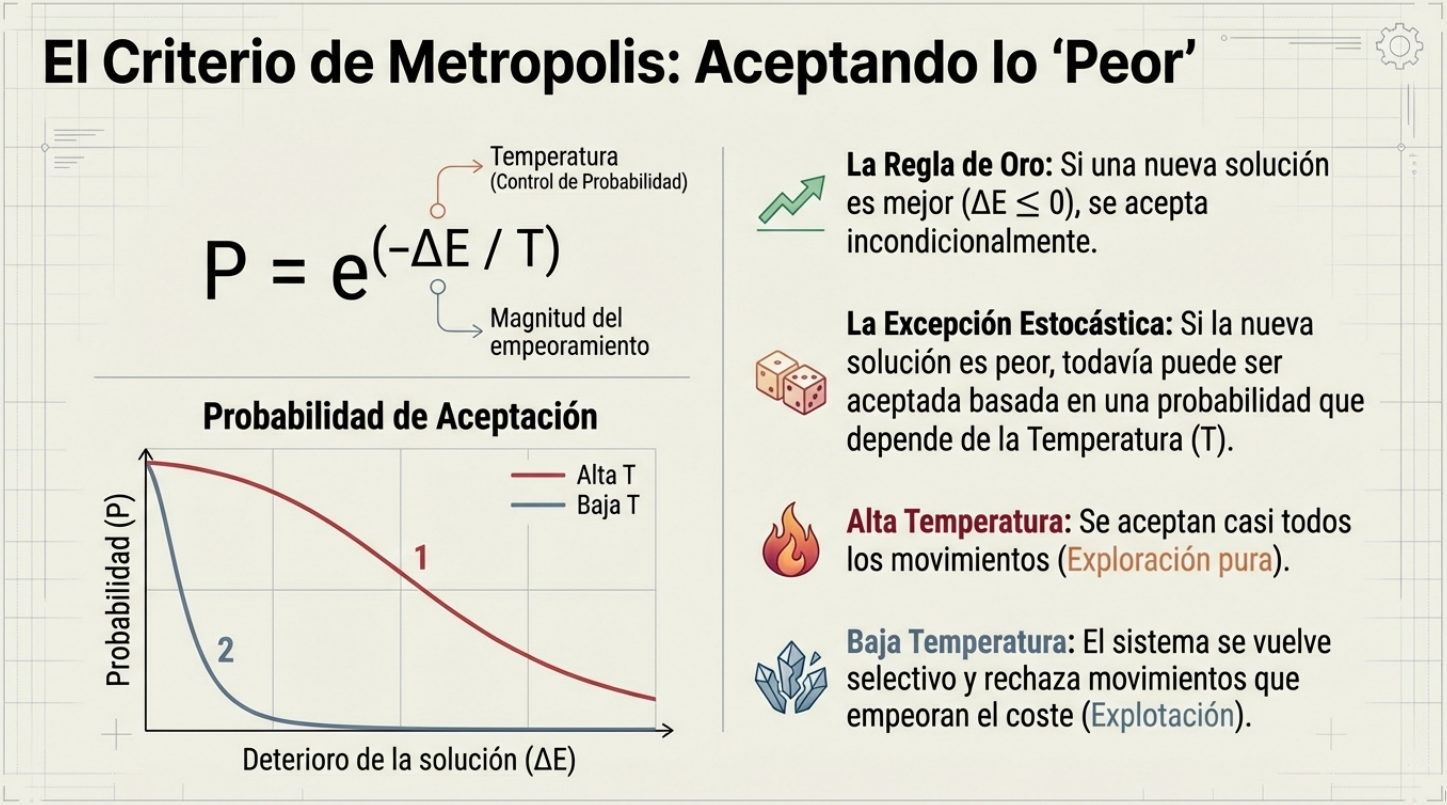
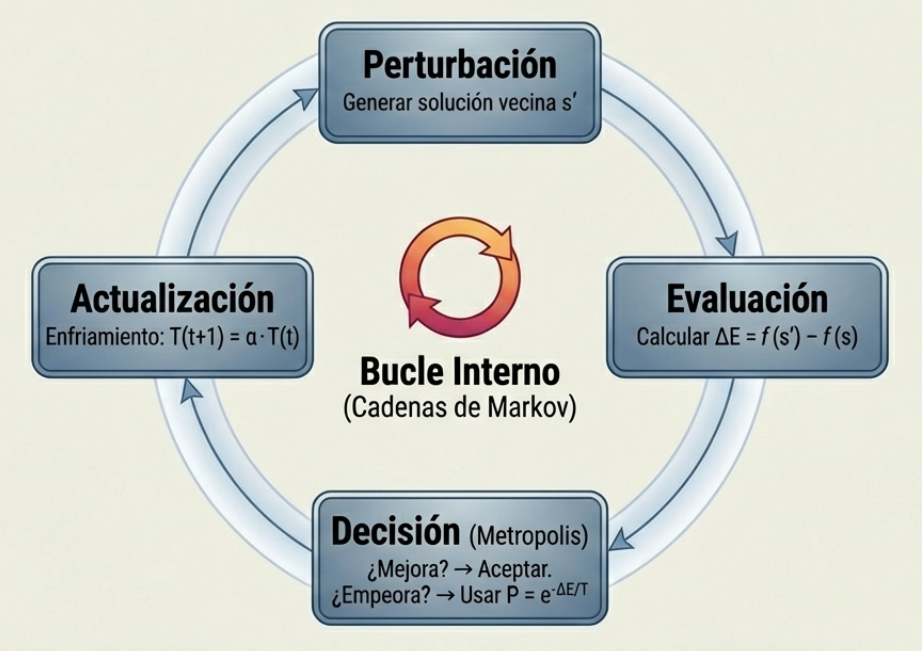
Aunque la biología es una fuente muy rica, la informática inspirada en la naturaleza trasciende mucho más. Para un especialista, la clasificación de estos algoritmos no se limita a su «musa», sino a su comportamiento matemático. Podemos categorizarlos según su trayectoria de búsqueda (como el Simulated Annealing) o según si se basan en poblaciones (como el Particle Swarm Optimization o el Firefly Algorithm).
Existen sistemas basados en leyes físicas y químicas, como los algoritmos que imitan la fuerza de la gravedad, las cargas eléctricas o la dinámica de formación de ríos. Incluso el arte tiene su lugar en el algoritmo Harmony Search (Búsqueda Armónica), que imita el proceso estético de un músico que persigue el «estado de armonía» o el acorde perfecto. Esta universalidad demuestra que los conceptos de disciplinas tan dispares pueden traducirse en reglas de actualización precisas para hallar soluciones casi óptimas en ingeniería y logística.
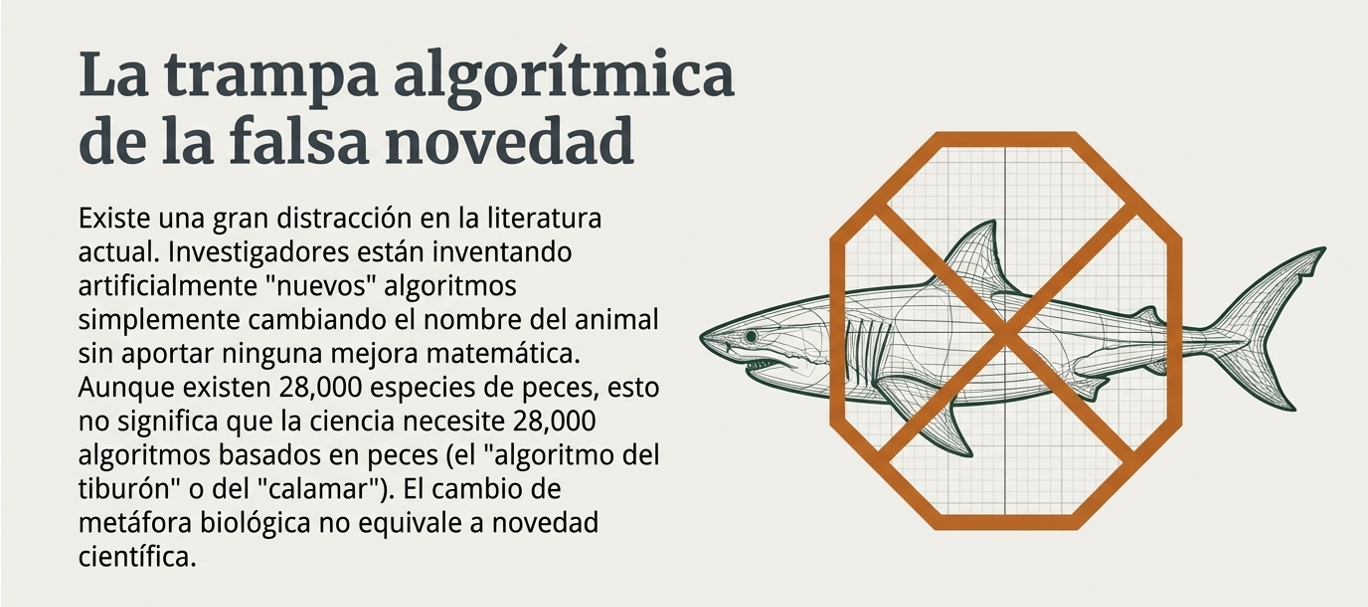
La trampa de las 28 000 especies: el desafío de la verdadera novedad.
A pesar del auge de estas técnicas, la comunidad científica se enfrenta a una realidad crítica: la proliferación de algoritmos que carecen de innovación real. Aunque en el mundo existen aproximadamente 28 000 especies de peces, esto no justifica la creación de 28 000 variantes algorítmicas (por ejemplo, el algoritmo del tiburón, de la trucha, etc.) que solo cambian los nombres de las variables sin aportar una mejora sustancial al motor de búsqueda.
En los últimos años, el mundo de la optimización ha experimentado una auténtica explosión de metaheurísticas. Nuevos algoritmos “inspirados en la naturaleza” están apareciendo como setas tras la lluvia. Solo en el último lustro, la comunidad científica se ha encontrado con miles de propuestas que se presentan como completamente originales.
El problema es que, en muchos casos, esas supuestas “novedades” no aportan ideas realmente nuevas. Son simplemente variantes, más o menos ingeniosas, de algoritmos ya conocidos y consolidados. Cambia el nombre, cambia la metáfora biológica o social, pero el mecanismo interno apenas difiere del de otros modelos existentes.
La situación ha llegado a tal punto que varias revistas científicas de alto impacto han decidido poner freno a esta tendencia. Muchas de ellas ya no aceptan trabajos que presenten una “nueva metaheurística” si no demuestran aportaciones metodológicas auténticas y verificables.
Esto supone una llamada a la acción para priorizar el rigor por encima de la «marca» comercial del algoritmo. Los expertos advierten sobre el peligro de la «pseudoinnovación» con fines de publicación:
No basta con bautizar un algoritmo con un nombre llamativo; tiene que resolver mejor los problemas reales.
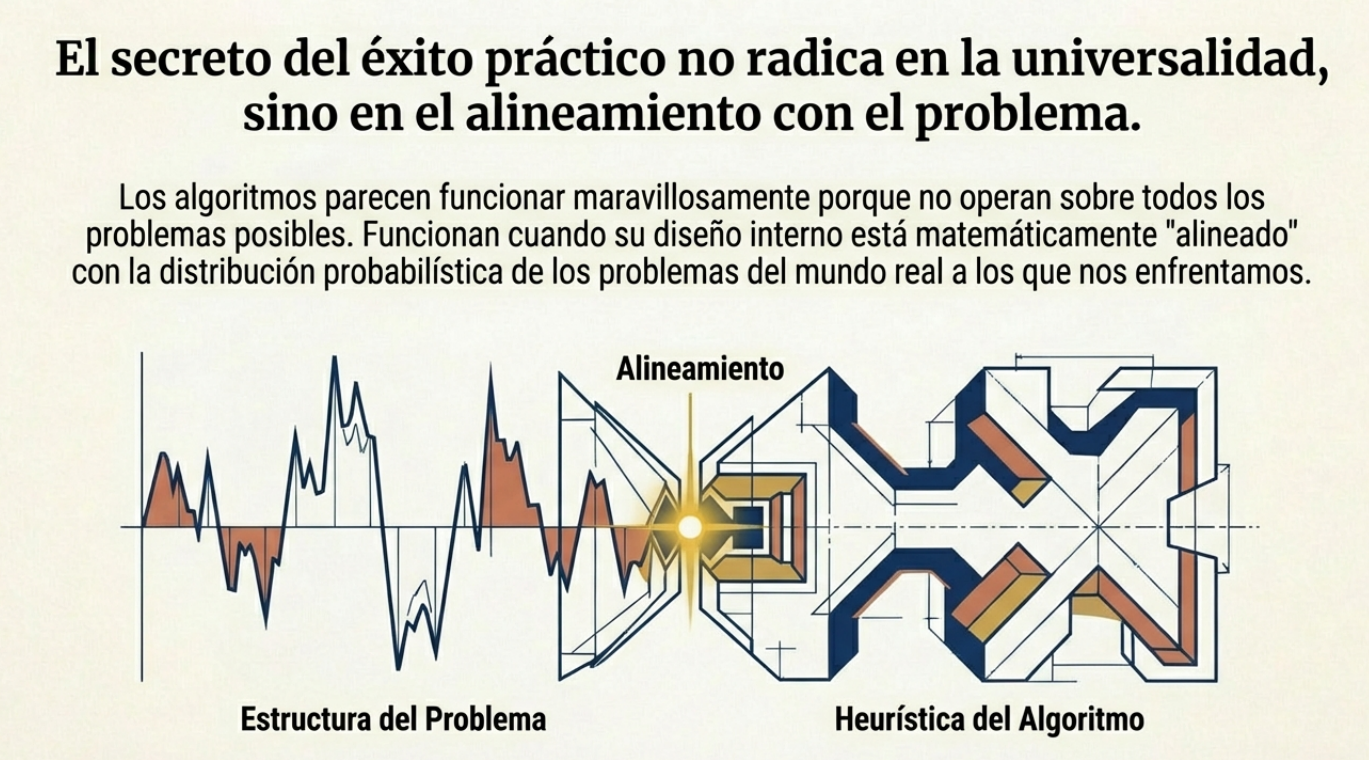
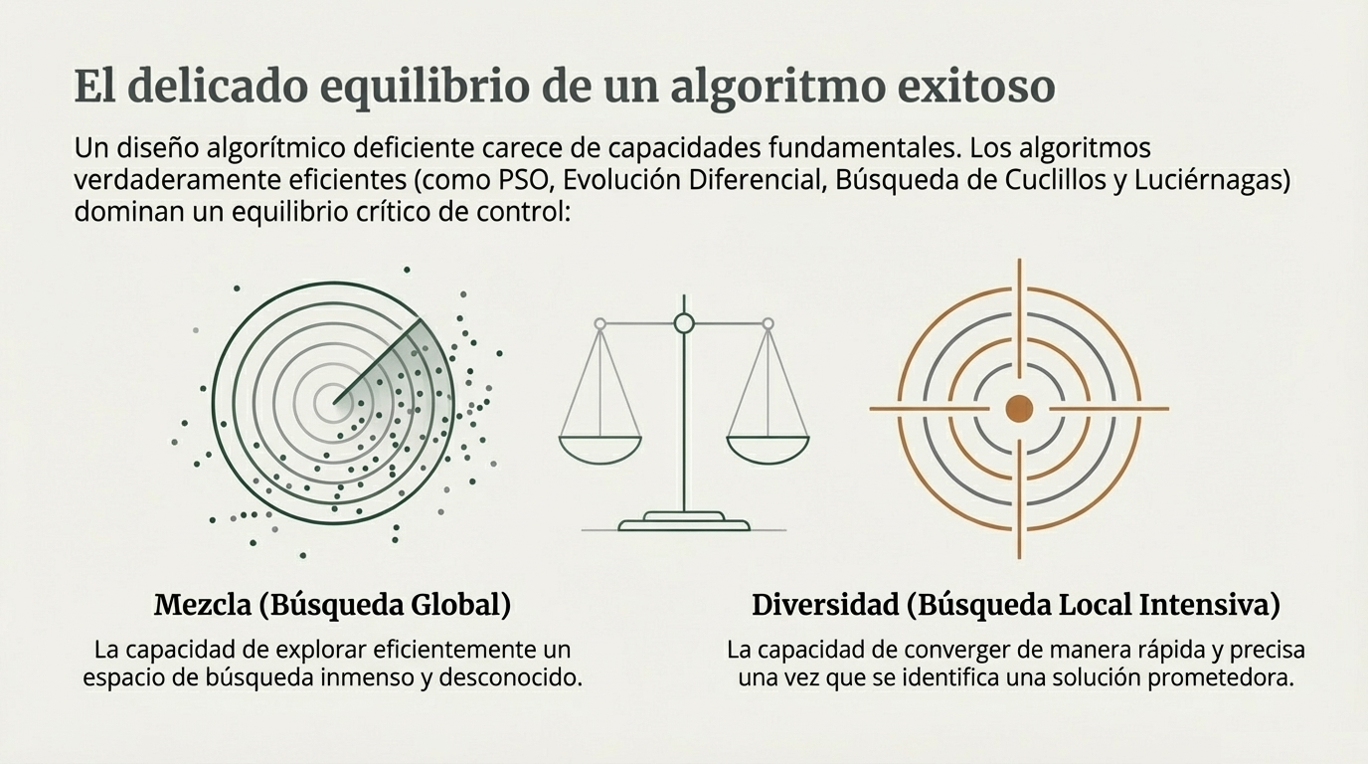
La receta del éxito: mezcla, diversidad y paralelismo.
¿Por qué algoritmos como Cuckoo Search o el Firefly Algorithm triunfan, mientras que otros caen en el olvido? El éxito de un metaheurístico radica en su capacidad para equilibrar dos fuerzas opuestas:
- Diversidad (búsqueda global/exploración): es la capacidad del algoritmo para explorar exhaustivamente el amplio espacio de búsqueda y evitar quedar atrapado en soluciones locales que parecen buenas, pero no lo son.
- Mezcla (búsqueda local/explotación): es el proceso de recombinación e interacción entre soluciones que permite al algoritmo converger rápidamente hacia el punto óptimo una vez identificada una región prometedora.
Además, una ventaja competitiva de los algoritmos de inteligencia de enjambre es su facilidad de paralelización. Al basarse en múltiples agentes independientes, estos procesos pueden ejecutarse simultáneamente en hardware moderno, lo que permite optimizar problemas a gran escala en el mundo real por primera vez de forma práctica y eficiente.
Conclusión: hacia una nueva era de resolución de problemas.
Los algoritmos inspirados en la naturaleza han dejado de ser una mera curiosidad para convertirse en el estándar de oro para los problemas de alta complejidad. Es por ello que el futuro de esta disciplina no radica en buscar «más especies» que imitar, sino en profundizar en el marco matemático que permite que la diversidad y la mezcla funcionen en armonía. Solo a través de la comprensión real de estos mecanismos podremos hacer frente a los enormes desafíos de la tecnología moderna.
Al observar la elegancia con la que un enjambre encuentra su camino o un sistema físico alcanza el equilibrio, surge una pregunta inevitable: ¿existe algún límite a lo que podemos aprender sobre la eficiencia de la naturaleza o apenas estamos empezando a descifrar su código más fundamental?
En esta conversación puedes escuchar algunas de las ideas más interesantes sobre este tema.
En este vídeo se resumen algunos de los conceptos más importantes abordados.
Referencias:
GARCÍA, J.; YEPES, V.; MARTÍ, J.V. (2020). A hybrid k-means cuckoo search algorithm applied to the counterfort retaining walls problem. Mathematics, 8(4), 555. DOI:10.3390/math8040555
GARCÍA, J.; MARTÍ, J.V.; YEPES, V. (2020). The buttressed walls problem: An application of a hybrid clustering particle swarm optimization algorithm. Mathematics, 8(6):862. DOI:10.3390/math8060862
GARCÍA-SEGURA, T.; YEPES, V.; ALCALÁ, J.; PÉREZ-LÓPEZ, E. (2015). Hybrid harmony search for sustainable design of post-tensioned concrete box-girder pedestrian bridges. Engineering Structures, 92:112-122. DOI:10.1016/j.engstruct.2015.03.015
GARCÍA-SEGURA, T.; YEPES, V.; MARTÍ, J.V.; ALCALÁ, J. (2014). Optimization of concrete I-beams using a new hybrid glow-worm swarm algorithm. Latin American Journal of Solids and Structures, 11(7):1190 – 1205. DOI:10.1590/S1679-78252014000700007
YEPES, V.; ALCALÁ, J.; PEREA, C.; GONZÁLEZ-VIDOSA, F. (2008). A Parametric Study of Optimum Earth Retaining Walls by Simulated Annealing. Engineering Structures, 30(3): 821-830. DOI:10.1016/j.engstruct.2007.05.023
YEPES, V. (2026). Heuristic Optimization Using Simulated Annealing. In: Kulkarni, A.J., Mezura-Montes, E., Bonakdari, H. (eds) Encyclopedia of Engineering Optimization and Heuristics. Springer, Singapore. https://doi.org/10.1007/978-981-96-8165-5_48-1

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.