La tesis doctoral leída recientemente por Lorena Yepes Bellver se centra en la optimización del diseño de puentes de losa de hormigón pretensado para pasos elevados con el fin de mejorar la sostenibilidad económica y ambiental mediante la minimización de costes, energía incorporada y emisiones de CO₂. Con el fin de reducir la elevada carga computacional del análisis estructural, la metodología emplea un marco de optimización de dos fases asistido por modelos sustitutos, en el que se destaca el uso de Kriging y redes neuronales artificiales (RNA).
La tesis doctoral leída recientemente por Lorena Yepes Bellver se centra en la optimización del diseño de puentes de losa de hormigón pretensado para pasos elevados con el fin de mejorar la sostenibilidad económica y ambiental mediante la minimización de costes, energía incorporada y emisiones de CO₂. Con el fin de reducir la elevada carga computacional del análisis estructural, la metodología emplea un marco de optimización de dos fases asistido por modelos sustitutos, en el que se destaca el uso de Kriging y redes neuronales artificiales (RNA).
En concreto, la optimización basada en Kriging condujo a una reducción de costes del 6,54 % al disminuir significativamente el consumo de hormigón y acero activo sin comprometer la integridad estructural. Si bien las redes neuronales demostraron una mayor precisión predictiva global, el modelo Kriging resultó más eficaz para identificar los óptimos locales durante el proceso de búsqueda. El estudio concluye que las configuraciones de diseño óptimas priorizan el uso de altos coeficientes de esbeltez y suponen una reducción del hormigón y del acero activo en favor del acero pasivo, con el fin de mejorar la eficiencia energética. Finalmente, la investigación integra la toma de decisiones multicriterio (MCDM, por sus siglas en inglés) para evaluar de manera integral los diseños en función de sus objetivos económicos, estructurales y ambientales.
Cuando pensamos en la construcción de grandes infraestructuras, como los puentes, suele venirnos a la mente la imagen de proyectos masivos, increíblemente caros y con un gran impacto ambiental. Son gigantes de hormigón y acero que, aunque necesarios, parecen irrenunciablemente vinculados a un alto coste económico y ecológico.
Sin embargo, ¿y si la inteligencia artificial nos estuviera mostrando un camino para que estos gigantes de hormigón fueran más ligeros, económicos y respetuosos con el planeta? Una reciente tesis doctoral sobre la optimización de puentes está desvelando hallazgos impactantes y, en muchos casos, sorprendentes. Este artículo resume esa compleja investigación en cinco lecciones clave y a menudo sorprendentes que no solo se aplican a los puentes, sino que anuncian una nueva era en el diseño de infraestructuras.

1. La sostenibilidad cuesta mucho menos de lo que crees.
Uno de los descubrimientos más importantes de la investigación es que la idea de que la sostenibilidad siempre implica un alto sobrecoste es, en gran medida, un mito. La optimización computacional demuestra que la viabilidad económica y la reducción del impacto ambiental no son objetivos opuestos.
La tesis doctoral lo cuantifica con precisión: un modesto aumento de los costes de construcción (inferior al 1 %) puede reducir sustancialmente las emisiones de CO₂ (en más de un 2 %). Este dato es muy relevante, ya que demuestra que con un diseño inteligente asistido por modelos predictivos se puede conseguir un beneficio medioambiental significativo con una inversión mínima. La sostenibilidad y la rentabilidad pueden y deben coexistir en el diseño de las infraestructuras del futuro.
2. El secreto está en la esbeltez: cuanto más fino, más eficiente.
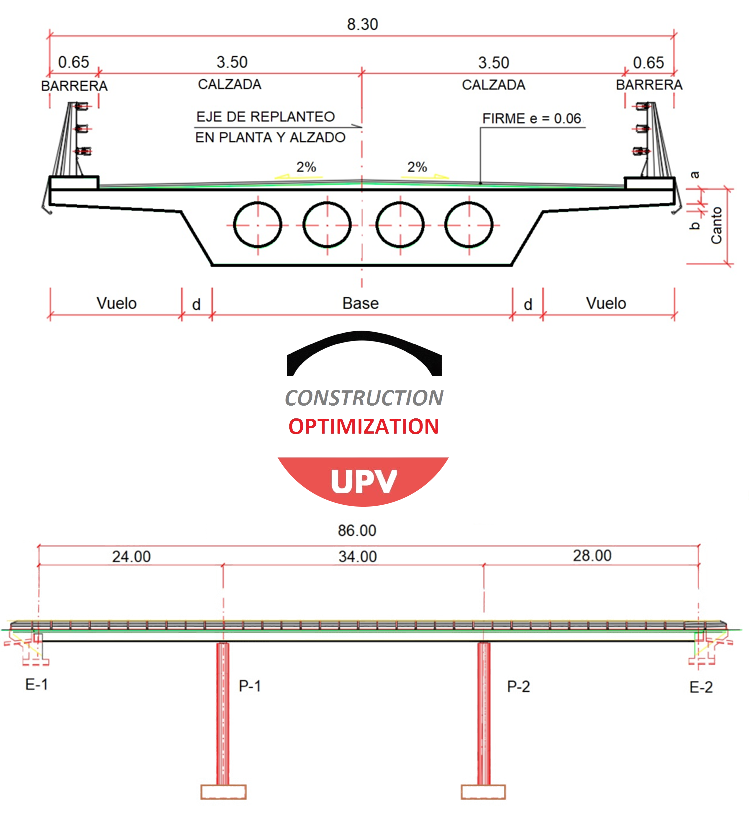
En el diseño de un puente, la «relación de esbeltez» es un concepto clave que define la proporción entre la altura del tablero (su grosor) y la longitud del vano principal. Tradicionalmente, podríamos pensar que «más robusto es más seguro», pero la investigación demuestra lo contrario.
El estudio identificó una relación de esbeltez óptima para minimizar el impacto ambiental. Concretamente, el estudio halló una relación de esbeltez de aproximadamente 1/30 para optimizar las emisiones de CO₂ y de aproximadamente 1/28 para optimizar la energía incorporada. Esto significa que, en lugar de construir puentes masivos por defecto, los modelos de IA demuestran que un diseño más esbelto y afinado no solo es estructuralmente sólido, sino también mucho más eficiente en el uso de materiales. Este diseño más esbelto se logra no solo usando menos material en general, sino también mediante un sorprendente reequilibrio entre los componentes clave de la estructura, como veremos a continuación.
3. El equilibrio de materiales: menos hormigón, más acero (pasivo).
Quizás uno de los descubrimientos más sorprendentes es que el diseño más sostenible no consiste simplemente en utilizar menos cantidad de todos los materiales. La solución óptima es más un reequilibrio inteligente que una simple reducción general.
La investigación revela que los diseños optimizados lograron reducir el uso de hormigón en un 14,8 % y de acero activo (el acero de pretensado que tensa la estructura) en un 11,25 %. Sin embargo, este descenso se compensa con un aumento de la armadura pasiva (el acero convencional que refuerza el hormigón). Esto resulta contraintuitivo, ya que la intuición ingenieril a menudo favorece una reducción uniforme de los materiales. Sin embargo, los modelos computacionales identifican un complejo intercambio —sacrificar un material más barato (hormigón) por otro más caro (acero pasivo)— para alcanzar un diseño globalmente óptimo en términos de coste y emisiones de CO₂, un equilibrio que sería extremadamente difícil de lograr con métodos de diseño tradicionales.
4. Precisión frente a dirección: El verdadero poder de los modelos predictivos.
Al comparar diferentes modelos de IA, como las redes neuronales artificiales y los modelos Kriging, la tesis doctoral reveló una lección fundamental sobre su verdadero propósito en ingeniería.
El estudio reveló que, si bien las redes neuronales ofrecían predicciones absolutas más precisas, el modelo Kriging era más eficaz para identificar las regiones de diseño óptimas. Esto pone de manifiesto un aspecto crucial sobre el uso de la IA en el diseño: su mayor potencial no radica en predecir un valor exacto, como si fuera una bola de cristal, sino en guiar al ingeniero hacia la «región» del diseño donde se encuentran las mejores soluciones posibles. La IA es una herramienta de exploración y dirección que permite navegar por un universo de posibilidades para encontrar de forma eficiente los diseños más prometedores.
5. La optimización va directo al bolsillo: reducción de costes superior al 6 %.
Más allá de los objetivos medioambientales, la investigación demuestra que estos modelos de IA son herramientas muy potentes para la optimización económica directa. Este descubrimiento no se refiere al equilibrio entre coste y sostenibilidad, sino a la reducción pura y dura de los costes del proyecto.
La tesis doctoral muestra que el método de optimización basado en Kriging consigue una reducción de costes del 6,54 %. Esta importante reducción se consigue principalmente minimizando el uso de materiales: un 14,8 % menos de hormigón y un 11,25 % menos de acero activo, el acero de pretensado más especializado y costoso. Esto demuestra de forma contundente que los modelos sustitutivos no solo sirven para alcanzar metas ecológicas, sino que también son una herramienta de gran impacto para la optimización económica en proyectos a gran escala.
Conclusión: Diseñando el futuro, un puente a la vez.
La inteligencia artificial y los modelos de optimización han dejado de ser conceptos abstractos para convertirse en herramientas prácticas que permiten descubrir formas novedosas y eficientes de construir la infraestructura del futuro. Los resultados de esta investigación demuestran que es posible diseñar y construir puentes que sean más económicos y sostenibles al mismo tiempo.
Estos descubrimientos no solo se aplican a los puentes, sino que abren la puerta a una nueva forma de entender la ingeniería. Si la IA puede rediseñar algo tan grande como un puente para hacerlo más sostenible, ¿qué otras grandes industrias están a punto de transformarse con un enfoque similar?
En este audio podéis escuchar una conversación sobre este tema.
Este vídeo resume las ideas principales.
Aquí tenéis un documento resumen de las ideas básicas.
Referencias:
YEPES-BELLVER, L.; ALCALÁ, J.; YEPES, V. (2025). Predictive modeling for carbon footprint optimization of prestressed road flyovers. Applied Sciences, 15(17), 9591. DOI:10.3390/app15179591
VILLALBA, P.; SÁNCHEZ-GARRIDO, A.; YEPES-BELLVER, L.; YEPES, V. (2025). A Hybrid Fuzzy DEMATEL–DANP–TOPSIS Framework for Life Cycle-Based Sustainable Retrofit Decision-Making in Seismic RC Structures. Mathematics, 13(16), 2649. DOI:10.3390/math13162649
ZHOU, Z.; WANG, Y.J.; YEPES-BELLVER, L.; ALCALÁ, J.; YEPES, V. (2025). Intelligent monitoring of loess landslides and research on multi-factor coupling damage. Geomechanics for Energy and the Environment, 42:100692. DOI:10.1016/j.gete.2025.100692
ZHOU, Z.; YEPES-BELLVER, L.; ALCALÁ, J.; YEPES, V. (2025). Study on the failure mechanism of deep foundation pit of high-rise building: comprehensive test and microstructure coupling. Buildings, 15(8), 1270. DOI:10.3390/buildings15081270
YEPES-BELLVER, L.; BRUN-IZQUIERDO, A.; ALCALÁ, J.; YEPES, V. (2025). Surrogate-assisted cost optimization for post-tensioned concrete slab bridges. Infrastructures, 10(2): 43. DOI:10.3390/infrastructures10020043.
BLIGHT, T.; MARTÍNEZ-PAGÁN, P.; ROSCHIER, L.; BOULET, D.; YEPES-BELLVER, L.; YEPES, V. (2025). Innovative approach of nomography application into an engineering educational context. Plos One, 20(2): e0315426. DOI:10.1371/journal.pone.0315426
NAVARRO, I.J.; VILLALBA, I.; YEPES-BELLVER, L.; ALCALÁ, J. Social Life Cycle Assessment of Railway Track Substructure Alternatives. J. Clean. Prod. 2024, 450, 142008.
YEPES-BELLVER, L.; BRUN-IZQUIERDO, A.; ALCALÁ, J.; YEPES, V. (2024). Artificial neural network and Kriging surrogate model for embodied energy optimization of prestressed slab bridges. Sustainability, 16(19), 8450. DOI:10.3390/su16198450
YEPES-BELLVER, L.; BRUN-IZQUIERDO, A.; ALCALÁ, J.; YEPES, V. (2023). Embodied energy optimization of prestressed concrete road flyovers by a two-phase Kriging surrogate model. Materials, 16(20); 6767. DOI:10.3390/ma16206767
YEPES-BELLVER, L.; BRUN-IZQUIERDO, A.; ALCALÁ, J.; YEPES, V. (2022). CO₂-optimization of post-tensioned concrete slab-bridge decks using surrogate modeling. Materials, 15(14):4776. DOI:10.3390/ma15144776

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.