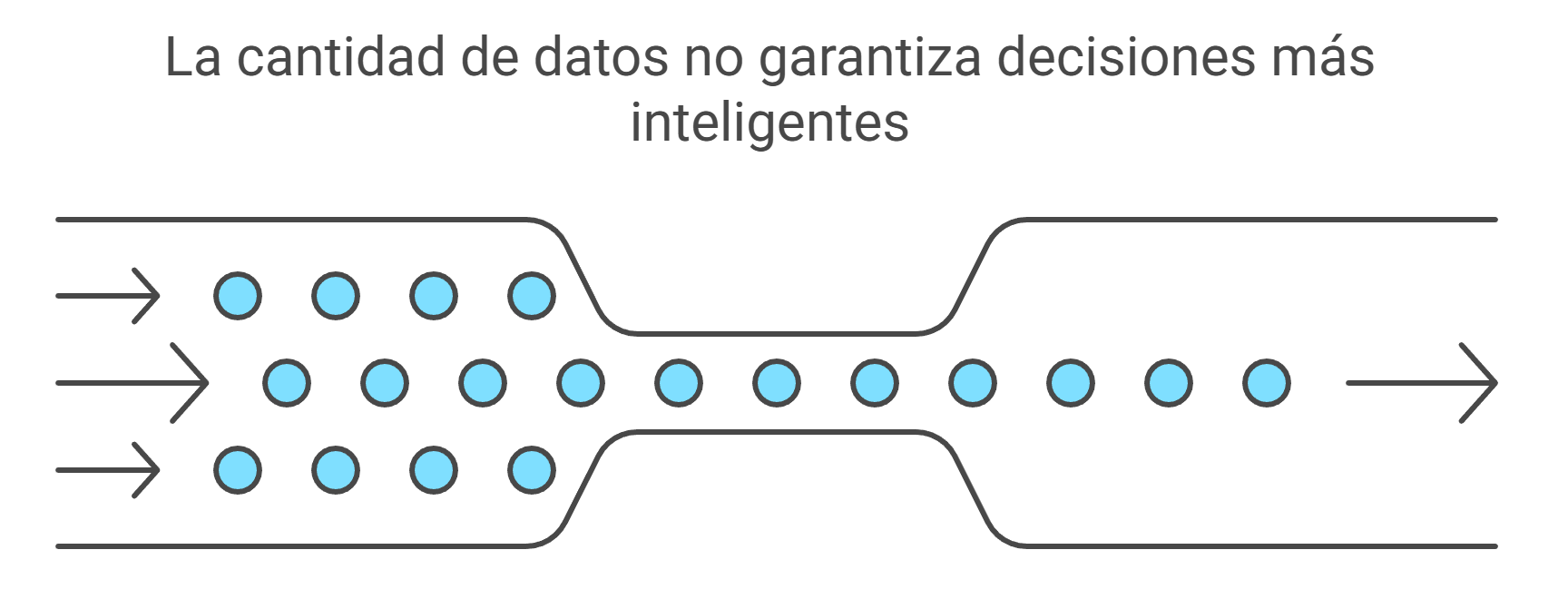
En la era del Big Data, tenemos, casi instintivamente, la idea de que más información siempre es mejor. Acumular más datos parece el camino directo hacia decisiones más inteligentes, resultados más fiables y una certeza casi absoluta. Creemos que si medimos algo diez, cien o mil veces, nuestra comprensión del fenómeno será inevitablemente más profunda y precisa.
Sin embargo, en el ámbito de la experimentación científica rigurosa, esta intuición puede resultar peligrosamente engañosa. Existe un concepto fundamental que a menudo se pasa por alto y que es mucho más importante que la mera cantidad de mediciones. No se trata de cuántos datos se recogen, sino de cómo se recogen. La estructura de un experimento es clave para su eficacia.
En este artículo se desglosan tres ideas clave del diseño experimental que revelan por qué la arquitectura de un estudio es más relevante que la cantidad de datos brutos. Prepárate para descubrir el secreto del éxito en los experimentos.
1. ¿Quién es nuestro protagonista? La unidad experimental.
Todo experimento comparativo tiene una estrella principal, un elemento central en torno al cual gira toda la acción. No se trata del tratamiento aplicado ni de la variable medida, sino de la unidad experimental (UE). Pero, ¿qué es exactamente?
Una unidad experimental es el elemento más pequeño al que se puede asignar un tratamiento de forma completamente independiente. Es la pieza fundamental sobre la que se realizan las mediciones para determinar qué ocurre. Piensa en ella como el «sujeto» de tu experimento.
Los ejemplos concretos ayudan a entenderlo mejor:
En la agricultura, si quieres comparar dos tipos de fertilizantes, la unidad experimental podría ser una parcela de terreno de un tamaño determinado.
En un estudio médico, la unidad experimental suele ser un paciente.
En entomología, podría tratarse de un insecto concreto o incluso de una colonia entera.
La clave está en que la definición de la unidad experimental depende de los objetivos de la investigación. Se trata de la pieza fundamental sobre la que se construye toda la comparación. Definir esta unidad es el primer paso, pero el verdadero desafío surge cuando empezamos a tomar mediciones en ella, lo que nos lleva a una de las trampas más comunes de la ciencia.
2. El espejismo de los «diez datos»: por qué medir más no siempre es medir mejor.
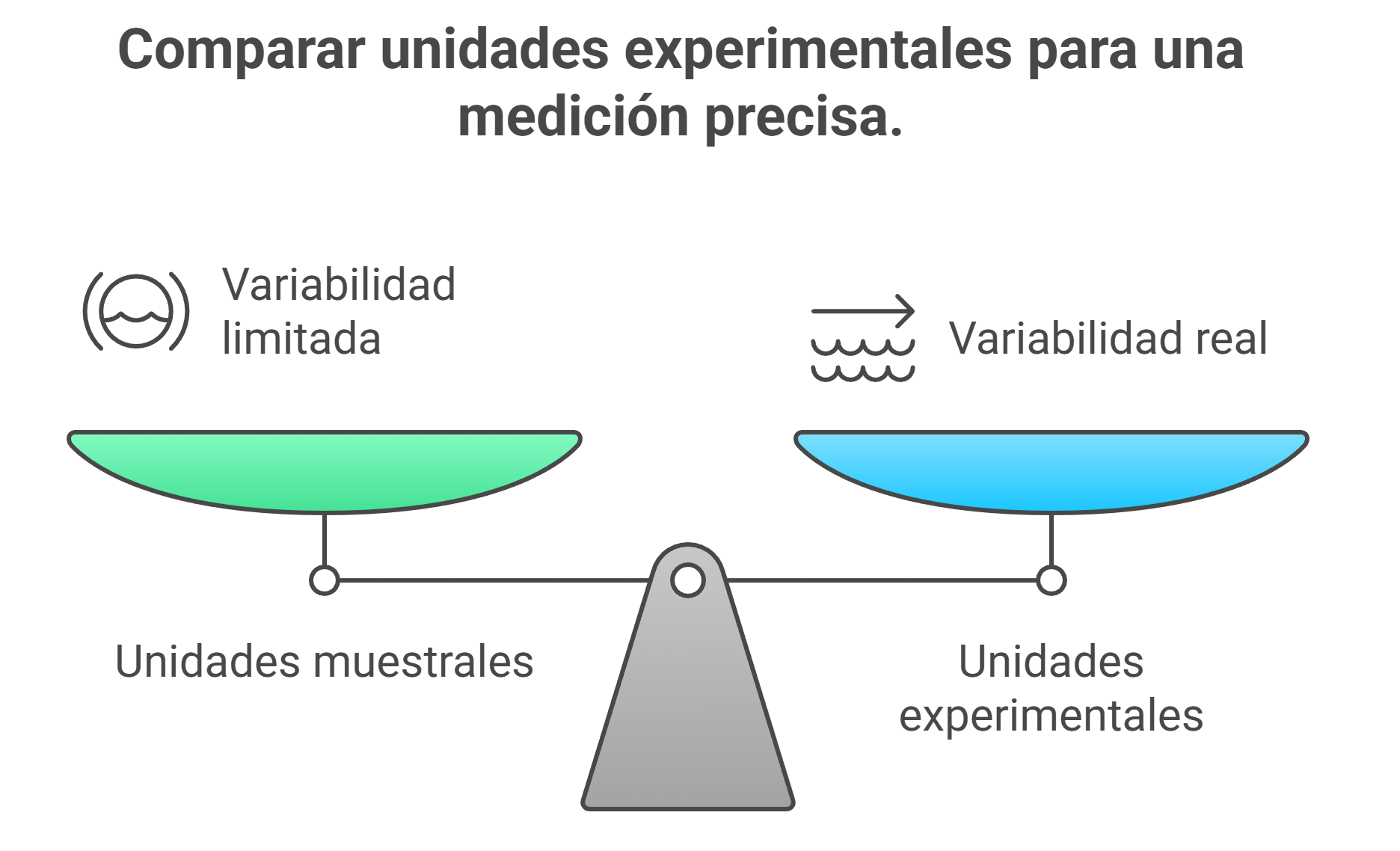
Esta es una de las confusiones más frecuentes. A menudo, en una unidad experimental podemos tomar varias mediciones. A estos subelementos los llamamos «unidades muestrales». Por ejemplo, en una parcela de terreno (la UE) podríamos analizar diez plantas distintas (las unidades muestrales).
Parecería que tenemos diez datos, ¿verdad? Técnicamente, sí, pero no son lo que parecen. Hay una regla de oro en el diseño experimental que lo cambia todo:
Las unidades muestrales dentro de una misma unidad experimental deben recibir el mismo tratamiento. Por ello, la asignación del tratamiento a estas unidades muestrales no es independiente entre sí.
Esto tiene unas implicaciones enormes. Las diez plantas de la misma parcela son como hermanos que crecieron en la misma casa. Comparten el mismo terreno, la misma cantidad de luz solar y la misma cantidad de agua. Medirlas por separado no es lo mismo que entrevistar a diez personas de distintas partes de la ciudad. Su similitud y su falta de independencia significan que no se obtienen diez puntos de vista únicos, sino diez variaciones sobre el mismo punto de vista. Confundir estas muestras con diez unidades experimentales independientes es uno de los errores más frecuentes al interpretar resultados.
Entonces, si multiplicar las muestras en una misma parcela no aumenta la fiabilidad, ¿cómo podemos estar seguros de que nuestro tratamiento funciona? La respuesta no consiste en acumular más mediciones, sino en comprender y medir correctamente el «ruido» del sistema.
3. Abraza el ruido: por qué el «error experimental» es tu mejor aliado.
La palabra «error» tiene una connotación negativa, pero en la ciencia el error experimental es tu mejor aliado. No se refiere a una equivocación ni a un fallo de medición. Se trata simplemente de la variabilidad natural entre las unidades experimentales. Es el «ruido» de fondo inevitable del sistema que estás estudiando. Dos pacientes nunca son idénticos ni dos parcelas de terreno son clones perfectos.
Para medir este «ruido» natural, necesitamos comparar manzanas con manzanas. Por eso la unidad experimental (Idea 1) es tan importante. La pequeña variación entre diez plantas de la misma parcela (las unidades muestrales de la idea 2) no nos dice nada sobre la variabilidad natural entre parcelas. El verdadero error experimental solo puede medirse comparando las diferencias entre múltiples parcelas completas que recibieron el mismo tratamiento.
La diferencia de altura entre dos plantas situadas a pocos centímetros entre sí en la misma parcela bien fertilizada será mínima. Esta pequeña variación no nos dice nada sobre la eficacia del fertilizante en general, especialmente si lo comparamos con otra parcela que, por su composición natural, presenta un suelo completamente diferente. La variación entre las parcelas es lo que constituye el verdadero desafío. La esencia de un buen experimento consiste en determinar si el efecto del tratamiento es mayor que la variabilidad natural. Sin una medición honesta de este error, es imposible sacar conclusiones válidas.
Conclusión: mirar más allá de los números.
La validez de un experimento no depende de la cantidad de mediciones, sino de la correcta definición, asignación y comparación de sus unidades experimentales. Es la estructura, no el volumen, lo que permite separar la señal del ruido.
La próxima vez que leas sobre un nuevo estudio, ignora por un momento el deslumbrante número de mediciones. En su lugar, busca a la verdadera protagonista: la unidad experimental. Pregúntate cómo la definieron los investigadores y cómo la utilizaron para medir el ruido de fondo. Esa es la diferencia entre una montaña de datos y un verdadero descubrimiento.
En esta conversación puedes descubrir alguna de las ideas de este artículo.
También puedes ver este vídeo, donde se recogen los conceptos más interesantes del tema.
En la actualidad, la inteligencia artificial (IA) está cada vez más presente en nuestra vida diaria, transformando industrias y planteando nuevas preguntas sobre la sociedad, la economía y, por supuesto, la educación. Entre las herramientas de IA emergentes, los «chatbots» generativos como ChatGPT han llamado especialmente la atención, ya que prometen revolucionar la enseñanza y el aprendizaje. Estas potentes plataformas pueden simular conversaciones humanas, ofrecer explicaciones e incluso generar textos complejos como poemas o ensayos. Sin embargo, a medida que educadores y legisladores consideran la implementación de estas tecnologías innovadoras en el ámbito educativo, es crucial reflexionar sobre las implicaciones éticas que conllevan. Aunque los beneficios potenciales son innegables, desde una mayor accesibilidad hasta experiencias de aprendizaje personalizadas, también existen desafíos significativos.
En este artículo, exploramos las consideraciones éticas clave relacionadas con el uso de chatbots generativos en la educación superior. La información que se presenta a continuación se basa en el artículo «The ethical implications of using generative chatbots in higher education» de Ryan Thomas Williams, publicado en Frontiers in Education.
A continuación, se examinan las implicaciones éticas de integrar chatbots generativos, como ChatGPT, en la educación superior. Se abordan preocupaciones clave como la privacidad de los datos de los estudiantes y los desafíos para cumplir con las regulaciones de protección de datos cuando la información es procesada y almacenada por la IA. El artículo también explora el sesgo algorítmico y señala cómo los prejuicios inherentes a los datos de entrenamiento pueden perpetuar estereotipos, además de abordar el impacto en la autoeficacia de los estudiantes al depender excesivamente de la IA, lo que podría disminuir el pensamiento crítico. Por último, se aborda el creciente problema del plagio y las «alucinaciones» de la IA, donde los chatbots generan información incorrecta, y se sugiere la necesidad de políticas claras, detección avanzada y métodos de evaluación innovadores.
1. ¿Cuáles son las principales implicaciones éticas de integrar los chatbots generativos en la educación superior?
La integración de chatbots generativos en la educación superior, como ChatGPT, aborda varias cuestiones éticas fundamentales. En primer lugar, la gestión de los datos sensibles de los estudiantes plantea importantes desafíos de privacidad, por lo que es necesario cumplir estrictamente con las normativas de protección de datos, como el RGPD, lo cual puede ser complejo debido a la naturaleza de los algoritmos de aprendizaje automático que aprenden de los datos y complican su «verdadera» eliminación. En segundo lugar, existe un riesgo significativo de sesgo algorítmico, ya que los chatbots aprenden de vastas fuentes de datos de internet que pueden perpetuar sesgos sociales (por ejemplo, de género o raciales), lo que podría afectar negativamente a la experiencia de aprendizaje del estudiante y a su visión del mundo. En tercer lugar, si bien los chatbots pueden fomentar la autonomía en el aprendizaje al ofrecer acceso bajo demanda a recursos y explicaciones personalizadas, existe la preocupación de que una dependencia excesiva pueda reducir la autoeficacia académica de los estudiantes, desincentivando el pensamiento crítico y la participación en actividades de aprendizaje más profundas. Finalmente, el plagio emerge como una preocupación primordial, ya que la capacidad de los chatbots para generar contenido sofisticado podría alentar a los estudiantes a presentar el trabajo generado por la IA como propio, lo que comprometería la integridad académica.
2. ¿Cómo afectan los chatbots generativos a la privacidad de los datos de los estudiantes en entornos educativos?
La implementación de chatbots en entornos educativos implica la recopilación, el análisis y el almacenamiento de grandes volúmenes de datos de los estudiantes, que pueden incluir desde su rendimiento académico hasta información personal sensible. Esta «gran cantidad de datos» permite experiencias de aprendizaje personalizadas y la identificación temprana de estudiantes en situación de riesgo. Sin embargo, esto genera importantes preocupaciones relacionadas con la privacidad. Existe el riesgo de uso indebido o acceso no autorizado a estos datos. Además, las regulaciones actuales de privacidad de datos, como el RGPD, permiten a los individuos solicitar la eliminación de sus datos, pero la naturaleza del aprendizaje automático significa que los algoritmos subyacentes ya han aprendido de los datos de entrada, por lo que es difícil aplicar un verdadero «derecho al olvido» o «eliminación». También hay una falta de transparencia algorítmica por parte de las empresas sobre la implementación de los algoritmos de los chatbots y sus bases de conocimiento, lo que dificulta el cumplimiento total de la ley de protección de datos, que exige que las personas estén informadas sobre el procesamiento de sus datos. Para mitigar estas preocupaciones, las instituciones educativas deben establecer directrices claras para la recopilación, almacenamiento y uso de datos, alineándose estrictamente con la normativa de protección de datos y garantizando la transparencia con todas las partes interesadas.
3. ¿Qué es el sesgo algorítmico en los chatbots educativos y cómo se puede abordar?
El sesgo algorítmico ocurre cuando los sistemas de IA, incluidos los chatbots, asimilan y reproducen los sesgos sociales presentes en los grandes conjuntos de datos con los que son entrenados. Esto puede manifestarse en forma de sesgos de género, raciales o de otro tipo que, si se reflejan en el contenido generado por la IA (como casos de estudio o escenarios), pueden perpetuar estereotipos y afectar a la experiencia de aprendizaje de los estudiantes. Para abordar esta situación, es fundamental que los conjuntos de datos utilizados para entrenar los sistemas de IA sean diversos y representativos, evitando fuentes de datos únicas o limitadas que no representen adecuadamente a grupos minoritarios. Se proponen asociaciones entre institutos educativos para compartir datos y garantizar su representatividad. Además, se deben realizar auditorías regulares de las respuestas del sistema de IA para identificar y corregir los sesgos. Es fundamental que se sea transparente sobre la existencia de estos sesgos y que se eduque a los estudiantes para que evalúen críticamente el contenido generado por la IA en lugar de aceptarlo como una verdad objetiva. El objetivo no es que la IA sea inherentemente sesgada, sino que los datos generados por humanos que la entrenan pueden contener sesgos, por lo que se requiere un enfoque deliberado y crítico para el desarrollo e implementación de la IA en la educación.
4. ¿Cómo impacta la dependencia de los estudiantes de los chatbots en su autoeficacia académica y su pensamiento crítico?
Si bien los chatbots pueden ofrecer una autonomía significativa en el aprendizaje al proporcionar acceso inmediato a recursos y respuestas personalizadas, existe la preocupación de que una dependencia excesiva pueda reducir la autoeficacia académica de los estudiantes. Esta dependencia puede llevar a los estudiantes a no comprometerse con el aprendizaje auténtico, lo que les disuade de participar en seminarios, lecturas recomendadas o discusiones colaborativas. A diferencia de las tecnologías informáticas tradicionales, la IA intenta reproducir habilidades cognitivas, lo que plantea nuevas implicaciones para la autoeficacia de los estudiantes con la IA. Además, la naturaleza en tiempo real de las interacciones con el chatbot puede fomentar respuestas rápidas y reactivas en lugar de una consideración reflexiva y profunda, lo que limita el desarrollo del pensamiento crítico. Las tecnologías de chatbot suelen promover formas de comunicación breves y condensadas, lo que puede restringir la profundidad de la discusión y las habilidades de pensamiento crítico que se cultivan mejor a través de una instrucción más guiada e interactiva, como las discusiones entre compañeros y los proyectos colaborativos. Por lo tanto, es crucial equilibrar la autonomía que ofrecen los chatbots con la orientación y supervisión de educadores humanos para fomentar un aprendizaje holístico.
5. ¿Cuál es la preocupación principal con respecto al plagio en la era de los chatbots generativos y qué soluciones se proponen?
El plagio se ha convertido en una preocupación ética crítica debido a la integración de herramientas de IA como ChatGPT en la educación. La capacidad de los chatbots para generar respuestas textuales sofisticadas, resolver problemas complejos y redactar ensayos completos crea un entorno propicio para la deshonestidad académica, ya que los estudiantes pueden presentar la producción de la IA como propia. Esto es especialmente problemático en sistemas educativos que priorizan los resultados (calificaciones, cualificaciones) sobre el proceso de aprendizaje. Los estudiantes pueden incurrir incluso en plagio no intencional si utilizan chatbots para tareas administrativas o para mejorar su escritura en inglés sin comprender completamente las implicaciones. Para abordar esta situación, es necesario un enfoque integral que incluya educar a los estudiantes sobre la importancia de la honestidad académica y las consecuencias del plagio. También se propone desplegar software avanzado de detección de plagio capaz de identificar texto generado por IA, aunque se reconoce que estas metodologías deben evolucionar continuamente para mantenerse al día con los avances de la IA. Más allá de la detección, es esencial reevaluar las estrategias de evaluación y diseñar tareas que evalúen la comprensión de los estudiantes y fomenten el pensamiento original, la creatividad y las habilidades que actualmente están más allá del alcance de la IA, como las presentaciones orales y los proyectos en grupo. También es crucial fomentar la transparencia sobre el uso de la IA en el aprendizaje, algo similar a lo que se hace con los correctores ortográficos.
6. ¿Qué se entiende por «alucinaciones» de la IA en los chatbots educativos y por qué son problemáticas?
Las «alucinaciones» de la IA se refieren a las respuestas generadas por modelos de lenguaje de IA que contienen información falsa o engañosa presentada como si fuera real. Este fenómeno ganó atención generalizada con la llegada de los grandes modelos de lenguaje (LLM), como ChatGPT, donde los usuarios notaron que los chatbots insertaban frecuentemente falsedades aleatorias en sus respuestas. Si bien el término «alucinación» ha sido criticado por su naturaleza antropomórfica, el problema subyacente es la falta de precisión y fidelidad a fuentes de conocimiento externas. Las alucinaciones pueden surgir de discrepancias en grandes conjuntos de datos, errores de entrenamiento o secuencias sesgadas. Para los estudiantes, esto puede llevar al desarrollo de conceptos erróneos, lo que afecta a su comprensión de conceptos clave y a su confianza en la IA como herramienta educativa fiable. Para los educadores, el uso de contenido generado por IA como recurso en el aula plantea un desafío ético significativo, ya que son los responsables de garantizar la precisión de la información presentada. Los estudios han descubierto que un porcentaje considerable de referencias generadas por chatbots son falsas o inexactas. Si bien la IA puede reducir la carga de trabajo de los docentes, la supervisión humana sigue siendo esencial para evitar imprecisiones, lo que puede crear una carga administrativa adicional.
7. ¿Cómo pueden las instituciones educativas equilibrar los beneficios de los chatbots con sus riesgos éticos?
Para conseguirlo, las instituciones educativas deben adoptar un enfoque reflexivo y multifacético. Esto implica establecer límites éticos firmes para proteger los intereses de los estudiantes, los educadores y la comunidad educativa en general. Se recomienda implementar políticas claras y sólidas de recopilación, almacenamiento y uso de datos, alineándose estrictamente con regulaciones de protección de datos como el RGPD, a pesar de los desafíos relacionados con la eliminación de datos y la transparencia algorítmica. Para mitigar el sesgo algorítmico, las instituciones deben garantizar que los conjuntos de datos de entrenamiento sean diversos y representativos, y realizar auditorías regulares. Para evitar una dependencia excesiva y mantener la autoeficacia académica de los estudiantes, los educadores deben fomentar la autonomía en el aprendizaje sin comprometer el pensamiento crítico ni el compromiso auténtico. Con respecto al plagio, es fundamental educar a los estudiantes sobre la integridad académica, utilizar software avanzado de detección de plagio y reevaluar los métodos de evaluación para fomentar el pensamiento original y las habilidades que la IA no puede replicar. Por último, es crucial que se conciencie a la sociedad sobre las «alucinaciones» de la IA, para lo cual los educadores deben verificar la exactitud de la información generada por la IA y reconocer su naturaleza evolutiva, comparándola con los primeros días de Wikipedia. Es una responsabilidad colectiva de todas las partes interesadas garantizar que la IA se utilice de una manera que respete la privacidad, minimice el sesgo, apoye la autonomía equilibrada del aprendizaje y mantenga el papel vital de los maestros humanos.
8. ¿Qué papel juega la transparencia en el uso ético de los chatbots de IA en la educación?
La transparencia es un pilar fundamental para el uso ético de los chatbots de IA en la educación, ya que aborda varias de las preocupaciones éticas clave. En el ámbito de la privacidad de los datos, es esencial que los usuarios estén informados sobre las prácticas de gestión de datos para aliviar sus preocupaciones y generar confianza en los chatbots adoptados. Esto incluye informar a los usuarios sobre cómo se recopilan, almacenan y utilizan sus datos. Con respecto al sesgo algorítmico, la transparencia significa reconocer que los chatbots pueden mostrar sesgos ocasionalmente debido a los datos de entrenamiento subyacentes. Se debe alentar a los estudiantes a evaluar críticamente la producción de los chatbots, en lugar de aceptarla como una verdad objetiva, teniendo en cuenta que el sesgo no es inherente a la IA, sino a los datos generados por humanos con los que se entrena. En la prevención del plagio, la transparencia en la educación es vital para el uso responsable de las herramientas de IA; los estudiantes deben ser conscientes de que deben reconocer la ayuda recibida de la IA, de la misma manera en que se acepta la ayuda de herramientas como los correctores ortográficos. Además, para las «alucinaciones» de la IA, es importante que los educadores y los estudiantes sean conscientes de la posibilidad de que los chatbots generen información falsa o engañosa, lo que requiere un escrutinio humano continuo para su verificación. En general, la transparencia fomenta la alfabetización digital y la conciencia crítica, y empodera a los usuarios para navegar por el panorama de la IA de manera más efectiva.
Referencia:
WILLIAMS, R. T. (2024). The ethical implications of using generative chatbots in higher education. In Frontiers in Education (Vol. 8, p. 1331607). Frontiers Media SA.
Glosario de términos clave
Inteligencia artificial (IA): La capacidad de un sistema informático para imitar funciones cognitivas humanas como el aprendizaje y la resolución de problemas (Microsoft, 2023). En el contexto del estudio, se refiere a sistemas que pueden realizar tareas que normalmente requieren inteligencia humana.
Chatbots generativos: Programas de IA capaces de simular conversaciones humanas y generar respuestas creativas y nuevas, como poemas, historias o ensayos, utilizando Procesamiento del Lenguaje Natural (PLN) y vastos conjuntos de datos.
Procesamiento del lenguaje natural (PLN): Un subcampo de la IA que permite a las máquinas entender, responder y generar lenguaje humano. Es fundamental para la funcionalidad de los chatbots avanzados.
Aprendizaje automático (ML): Un subconjunto de la IA que permite a los sistemas aprender de los datos sin ser programados explícitamente. Los chatbots modernos utilizan ML para mejorar sus respuestas a lo largo del tiempo.
Privacidad de datos: La protección de la información personal de los individuos, asegurando que se recopile, almacene y utilice de forma ética y legal. En el contexto educativo, se refiere a la información sensible de los estudiantes.
Reglamento general de protección de datos (GDPR): Una ley de la Unión Europea sobre protección de datos y privacidad en el Área Económica Europea y el Reino Unido. Es relevante para la gestión de datos sensibles de estudiantes.
Ley de protección de la privacidad en línea de los niños (COPPA): Una ley de Estados Unidos que impone ciertos requisitos a los operadores de sitios web o servicios en línea dirigidos a niños menores de 13 años.
Derecho al olvido: El derecho de un individuo a que su información personal sea eliminada de los registros de una organización, un concepto que se complica con la naturaleza del aprendizaje de los algoritmos de IA.
Transparencia algorítmica: La capacidad de entender cómo funcionan los algoritmos de IA y cómo toman decisiones, incluyendo el acceso a los detalles de su implementación y bases de conocimiento.
Big Data: Conjuntos de datos tan grandes y complejos que los métodos tradicionales de procesamiento de datos no son adecuados. En los chatbots, se utilizan para personalizar experiencias.
Sesgo algorítmico: Ocurre cuando los sistemas de IA asimilan y reproducen sesgos sociales presentes en los datos con los que fueron entrenados, lo que puede llevar a resultados injustos o estereotipados.
Autoeficacia académica: La creencia de un estudiante en su capacidad para tener éxito en sus tareas académicas. El estudio explora cómo una dependencia excesiva de la IA podría impactarla negativamente.
Autoeficacia en IA: La confianza de un individuo en su capacidad para usar y adaptarse a las tecnologías de inteligencia artificial. Distinto de la autoeficacia informática tradicional debido a las capacidades cognitivas de la IA.
Plagio: La práctica de tomar el trabajo o las ideas de otra persona y presentarlas como propias, sin la debida atribución. Se convierte en una preocupación crítica con la capacidad de los chatbots para generar texto.
Software de detección de plagio: Herramientas diseñadas para identificar instancias de plagio comparando un texto con una base de datos de otros textos. La evolución de la IA plantea desafíos para su eficacia.
Alucinación de IA: Una respuesta generada por un modelo de lenguaje de IA que contiene información falsa, inexacta o engañosa, presentada como si fuera un hecho.
Modelos de lenguaje grandes (LLMs): Modelos de IA muy grandes que han sido entrenados con inmensas cantidades de texto para comprender, generar y responder al lenguaje humano de manera sofisticada. ChatGPT es un ejemplo de LLM.
Integridad académica: El compromiso con la honestidad, la confianza, la justicia, el respeto y la responsabilidad en el aprendizaje, la enseñanza y la investigación. Es fundamental para el entorno educativo y está amenazada por el plagio asistido por IA.
Os dejo este artículo, pues está en acceso abierto:
Acaban de publicarnos un artículo en la revista científica Applied Sciences (indexada en el JCR, Q2) un artículo que trata sobre el análisis del ciclo de vida de puentes usando redes bayesianas y matemática difusa. El trabajo se enmarca dentro del proyecto de investigación DIMALIFE que dirijo como investigador principal en la Universitat Politècnica de València.
En la actualidad, reducir el impacto de la industria de la construcción en el medio ambiente es fundamental para lograr un desarrollo sostenible. Son muchos los que utilizan programas informáticos para evaluar el impacto ambiental de los puentes. Sin embargo, debido a la complejidad y la diversidad de los factores medioambientales de la industria de la construcción, es difícil actualizarlos y determinarlos rápidamente, lo que provoca la pérdida de datos en las bases de datos. La mayoría de los datos perdidos se optimizan mediante la simulación de Monte Carlo, lo que reduce en gran medida la fiabilidad y precisión de los resultados de la investigación. Este trabajo utiliza la teoría matemática difusa avanzada bayesiana para resolverlo. En la investigación, se establece una evaluación de la teoría matemática difusa bayesiana y un modelo de discriminación prioritaria de sensibilidad de varios niveles, y se definen los pesos y los grados de pertenencia de los factores de influencia para lograr una cobertura completa de los mismos. Con el apoyo de la modelización teórica, se evalúan exhaustivamente todos los factores de influencia en las distintas etapas del ciclo de vida de la estructura del puente. Los resultados muestran que la fabricación de materiales, el mantenimiento y el funcionamiento del puente siguen produciendo contaminación ambiental; la fuente principal de las emisiones supera el 53 % del total. El factor de impacto efectivo alcanza el 3,01. Al final del artículo, se establece un modelo de sensibilidad de «big data». Optimizando con estas técnicas, las emisiones contaminantes del tráfico se redujeron en 330 toneladas. Se confirma la eficacia y la practicidad del modelo de evaluación integral de la metodología propuesta para abordar los factores inciertos en la evaluación del desarrollo sostenible en el caso de los puentes. Los resultados de la investigación contribuyen a alcanzar los objetivos de desarrollo sostenible en la industria de la construcción.
At present, reducing the construction industry’s impact on the environment is the key to achieving sustainable development. Countries worldwide are using software systems to bridge environmental impact assessment. However, due to the complexity and discreteness of ecological factors in the construction industry, they are difficult to update and determine quickly, and data is missing in the database. Most of the lost data are optimized by Monte Carlo simulation, which significantly reduces the reliability and accuracy of the research results. This paper uses Bayesian advanced fuzzy mathematics theory to solve this problem. In the research, a Bayesian fuzzy mathematics evaluation and a multi-level sensitivity priority discrimination model are established, and the weights and membership degrees of influencing factors were defined to achieve comprehensive coverage of influencing factors. With the support of theoretical modeling, software analysis and fuzzy mathematics theory are used to comprehensively evaluate the five stages’ influencing factors in the bridge structure’s life cycle. The results show that the bridge’s material manufacturing, maintenance, and operation still produce environmental pollution; the primary source of the emissions exceeds 53% of the total emissions. The practical impact factor reaches 3.01. A big data sensitivity model was established at the end of the article. Significant data innovation and optimization analysis reduced traffic pollution emissions by 330 tonnes. Modeling the comprehensive research model application clearly confirms the effectiveness and practicality of the Bayesian network fuzzy number comprehensive evaluation model in dealing with uncertain factors in evaluating the sustainable development of the construction industry. The research results have made important contributions to realizing the sustainable development goals of the construction industry.
Keywords:
Construction industry; environmental; impact factor; analysis; contribution
La ciudad Estado de Singapur desarrolla una copia virtual de sí misma, un proyecto basado en big data, IoT, computación en la nube y realidad virtual. https://www.esmartcity.es/2019/03/22/singapur-gemelo-digital-posibilidades-ofrece-ciudad-inteligente-tener-copia-virtual-exacta
En menos de una década, gran parte de los ingenieros dejarán de hacer proyectos, tal y como lo conocemos ahora, y pasarán a ser gestores de gemelos híbridos digitales de infraestructuras.
Este podría ser un buen titular periodístico que, incluso podría parecer ciencia ficción, pero que tiene todos los visos de convertirse en realidad en menos tiempo del previsto. Se podría pensar que las tecnologías BIM o los modelos digitales actuales ya son una realidad, es decir, se trata de dar un nuevo nombre a lo que ya conocemos y está en desarrollo, pero de lo que estamos hablando es de un nuevo paradigma que va a revolver los cimientos de la tecnología actual en el ámbito de la ingeniería. Voy a desgranar esta conclusión explicando cada uno de los avances y los conceptos que subyacen al respecto.
La semana pasada tuve la ocasión de escuchar la conferencia magistral, en el Congreso CMMoST, de Francisco Chinesta, catedrático en la ENSAM ParisTech e ingeniero industrial egresado por la Universitat Politècnica de València. Trataba de un nuevo paradigma en la ingeniería basada en datos y no era otra que la de los gemelos híbridos digitales, un paso más allá de la modelización numérica y de la minería de datos. Este hecho coincidió con el anuncio en prensa de que Google había publicado en la prestigiosa revista Nature un artículo demostrando la supremacía cuántica, un artículo no exento de polémica, pues parece ser que se diseñó un algoritmo que tiene como objetivo generar números aleatorios mediante un procedimiento matemático muy complejo y que obligaría al superordenador Summit, que es actualmente el más potente del mundo gracias a sus 200 petaflops, a invertir 10.000 años en resolver el problema, que que el procesador cuántico Sycamore de 54 qubits de Google habría resuelto en tres minutos y 20 segundos.
Si nos centramos en la supuesta supremacía cuántica de Google, se debería matizar la noticia al respecto. En efecto, IBM ya se ha defendido diciendo que su ordenador Summit no se encuentra tan alejado, pues se ha resuelto un problema muy específico relacionado con generar números aleatorios y que parece que Sycamore sabe resolver muy bien. De hecho, IBM afirma que ha reajustado su superordenador y que ahora es capaz de resolver ese mismo problema en 2,5 días con un margen de error mucho menor que el ordenador cuántico. Aquí lo importante es saber si esta computación cuántica estará, sin trabas o límites, accesible a cualquier centro de investigación o empresa para resolver problemas de altísima complejidad computacional (problemas NP-hard como pueden ser los de optimización combinatoria). Tal vez los superordenadores convencionales servirán para resolver unos problemas específicos en tareas convencionales, y los cuánticos, imparables en resolver otro tipo de problemas. Todo se andará, pero parece que esto es imparable.
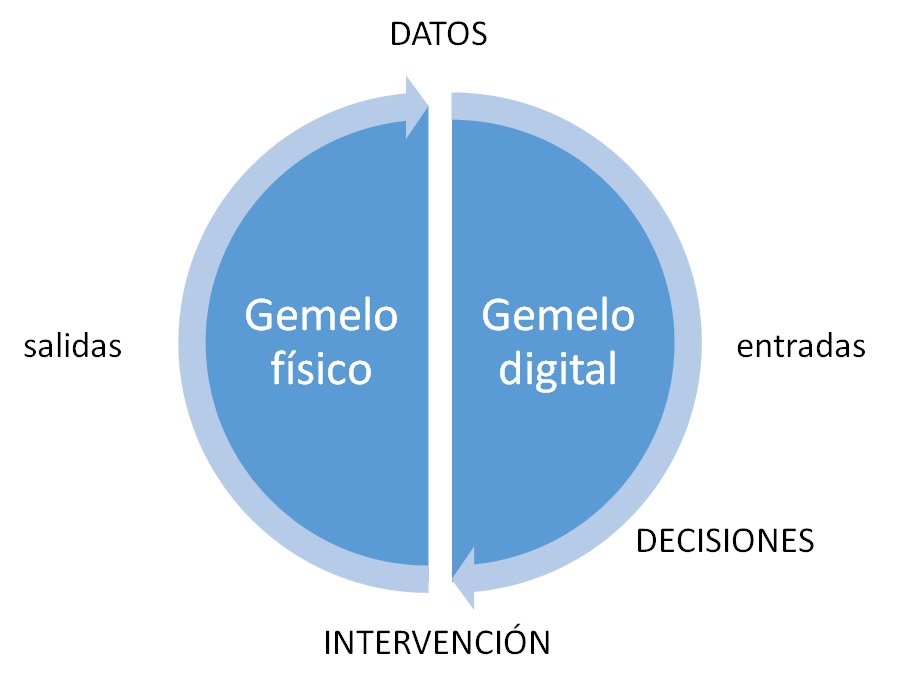
Por tanto, parece que el hardware necesario para la una computación ultrarrápida está o estará a nuestro alcance en un futuro no muy lejano. Ahora se trata de ver cómo ha cambiado el paradigma de la modelización matemática. Para ello podríamos empezar definiendo al «gemelo digital», o digital twin. Se trata de un modelo virtual de un proceso, producto o servicio que sirve de enlace entre un ente en el mundo real y su representación digital que está utilizando continuamente datos de los sensores. A diferencia del modelado BIM, el gemelo digital no representa exclusivamente objetos espaciales, sino que también podría representar procesos, u otro tipo de entes sin soporte físico. Se trata de una tecnología que, según todos los expertos, marcarán tendencia en los próximos años y que, según el informe «Beyond the hype«, de KPMG, será la base de la cuarta Revolución Industrial.
Sin embargo, el gemelo digital no es una idea nueva, pues a principios de este siglo ya la introdujo Michael Grieves, en colaboración con John Vickers, director de tecnología de la NASA. Esta tecnología se aplica al Internet de las Cosas, que se refiere a la interconexión digital de objetos cotidianos con internet. Además, se encuentra muy relacionada con la inteligencia artificial y con la minería de datos «data-mining«. Empresas como Siemens ya están preparando convertir sus plantas industriales en fábricas de datos con su gemelo digital, o General Electric, que cuenta ya con 800.000 gemelos digitales para monitorizar virtualmente la cadena de suministro.
Con todo, tal y como explicó el profesor Chinesta (Chinesta et al., 2018), existe actualmente un cambio de paradigma hacia los gemelos digitales híbridos que, extrapolando su uso, va a significar la gran revolución en la forma de proyectar y gestionar las infraestructuras, tal y como avancé al principio del artículo.
En efecto, los modelos utilizados en ciencia y en ingeniería son muy complejos. La simulación numérica, la modelización y la experimentación han sido los tres pilares sobre los que se ha desarrollado la ingeniería en el siglo XX. La modelización numérica, que sería el nombre tradicional que se ha dado al «gemelo digital» presenta problemas prácticos por ser modelos estáticos, pues no se retroalimentan de forma continua de datos procedentes del mundo real a través de la monitorización continua. Estos modelos numéricos (usualmente elementos finitos, diferencias finitas, volumen finito, etc.) son suficientemente precisos si se calibran bien los parámetros que lo definen. La alternativa a estos modelos numéricos son el uso de modelos predictivos basados en datos masivos big-data, constituyendo «cajas negras» con alta capacidad de predicción debido a su aprendizaje automático «machine-learning«, pero que esconden el fundamento físico que sustentan los datos (por ejemplo, redes neuronales). Sin embargo, la experimentación es extraordinariamente cara y lenta para alimentar estos modelos basados en datos masivos.
El cambio de paradigma, por tanto, se basa en el uso de datos inteligentes «smart-data paradimg«. Este cambio se debe basar, no en la reducción de la complejidad de los modelos, sino en la reducción dimensional de los problemas, de la retroalimentación continua de datos del modelo numérico respecto a la realidad monitorizada y el uso de potentes herramientas de cálculo que permitan la interacción en tiempo real, obteniendo respuestas a cambios paramétricos en el problema. Dicho de otra forma, deberíamos poder interactuar a tiempo real con el gemelo virtual. Por tanto, estamos ante otra realidad, que es el gemelo virtual híbrido.
Por tanto, estamos ahora en disposición de centrarnos en la afirmación que hice al principio. La nueva tecnología en gemelos digitales híbridos, junto con la nueva capacidad de cálculo numérico en ciernes, va a transformar definitivamente la forma de entender, proyectar y gestionar las infraestructuras. Ya no se trata de proyectar, por ejemplo, un puente. Ni tampoco estamos hablando de diseñar un prototipo en 3D del mismo puente, ni siquiera de modelar en BIM dicha estructura. Estamos hablando de crear un gemelo digital que se retroalimentará continuamente del puente real, que estará monitorizado. Se reajustarán los parámetros de cálculo del puente con los resultados obtenidos de la prueba de carga, se podrán predecir las labores de mantenimiento, se podrá conocer con antelación el comportamiento ante un fenómeno extraordinario como una explosión o un terremoto. Por tanto, una nueva profesión, que será la del ingeniero de gemelos virtuales híbridos de infraestructuras será una de las nuevas profesiones que reemplazarán a otras que quedarán obsoletas.
Se tratará de gestionar el gemelo durante el proyecto, la construcción, la explotación e incluso el desmantelamiento de la infraestructura. Se podrán analizar cambios de usos previstos, la utilización óptima de recursos, monitorizar la seguridad, y lo más importante, incorporar nuevas funciones objetivo como son la sostenibilidad económica, medioambiental y social a lo largo del ciclo de vida completo. Este tipo de enfoque es el que nuestro grupo de investigación tiene en el proyecto DIMILIFE. Proyectos como puentes, presas, aeropuertos, redes de carreteras, redes de ferrocarriles, centrales nucleares, etc. tendrán su gemelo digital. Para que sea efectivo, se deberá prever, desde el principio, la monitorización de la infraestructura para ayudar a la toma de decisiones. Además, servirá para avanzar en la aproximación cognitiva en la toma de decisiones (Yepes et al., 2015).
Os paso a continuación un vídeo sobre el uso de los gemelos digitales en la ciudad de Singapur.
A continuación os pongo un vídeo sacado de la página de Elías Cueto, de la Universidad de Zaragoza, en la que vemos cómo se interactúa con un gemelo virtual de un conejo.
En este otro vídeo, el profesor Chinesta explica el cambio de paradigma del que hemos hablado anteriormente en el artículo.
¿Qué es la computación cuántica? Aquí tenemos un vídeo de Eduardo Sáenz de Cabezón:
Referencias:
Chinesta, F.; Cueto, E.; Abisset-Chavanne, E.; Duval, J.L. (2018). Virtual, Digital and Hybrid Twins: A New Paradigm in Data-Based Engineering and Engineered Data.Archives of Computational Methods in Engineering, DOI: 10.1007/s11831-018-9301-4
Yepes, V.; García-Segura, T.; Moreno-Jiménez, J.M. (2015). A cognitive approach for the multi-objective optimization of RC structural problems. Archives of Civil and Mechanical Engineering, 15(4):1024-1036. DOI:10.1016/j.acme.2015.05.001
En una entrada anterior que denominé «La ingeniería de caminos en el siglo XXI, ¿quo vadis?«, puse de manifiesto la incertidumbre que suponía la desaparición de la titulación de ingeniero de caminos, canales y puertos con motivo de la reestructuración de las enseñanzas universitarias en grado y máster. Las preguntas que dejaban en el aire adquirían un tinte dramático cuando se contextualizaban en una situación de profunda crisis económica, especialmente fuerte en el sector de la construcción.
Otra reflexión sobre el futuro de la profesión la dejé en la entrada «¿Qué entendemos por «Smart Construction»? ¿Una nueva moda?«. Allí dejé constancia de las modas que igual que aparecen, desaparecen, pero que suponen cambios sustanciales en una profesión como la de ingeniero civil. Allí expresé mi esperanza de que el término de “construcción inteligente” tuviera algo más de recorrido y pudiera suponer un punto de inflexión en nuestro sector. Este término presenta, como no podía ser de otra forma, numerosas interpretaciones y tantas más aplicaciones. Es un concepto que se asocia al diseño digital, a las tecnologías de la información y de la comunicación, la inteligencia artificial, al BIM, al Lean Construction, la prefabricación, los drones, la robotización y automatización, a la innovación y a la sostenibilidad, entre otros muchos conceptos. Entre estos conceptos, uno que me interesa especialmente es la asociación con el de los nuevos métodos constructivos (término que incluye nuevos productos y nuevos procedimientos constructivos). Su objetivo es mejorar la eficiencia del negocio, la calidad, la satisfacción del cliente, el desempeño medioambiental, la sostenibilidad y la previsibilidad de los plazos de entrega. Por lo tanto, los métodos modernos de construcción son algo más que un enfoque particular en el producto. Involucran a la gente a buscar mejoras, a través de mejores procesos, en la entrega y ejecución de la construcción.
 En la era del Big Data, tenemos, casi instintivamente, la idea de que más información siempre es mejor. Acumular más datos parece el camino directo hacia decisiones más inteligentes, resultados más fiables y una certeza casi absoluta. Creemos que si medimos algo diez, cien o mil veces, nuestra comprensión del fenómeno será inevitablemente más profunda y precisa.
En la era del Big Data, tenemos, casi instintivamente, la idea de que más información siempre es mejor. Acumular más datos parece el camino directo hacia decisiones más inteligentes, resultados más fiables y una certeza casi absoluta. Creemos que si medimos algo diez, cien o mil veces, nuestra comprensión del fenómeno será inevitablemente más profunda y precisa.