Introducción: El dilema de las medias engañosas.
Introducción: El dilema de las medias engañosas.
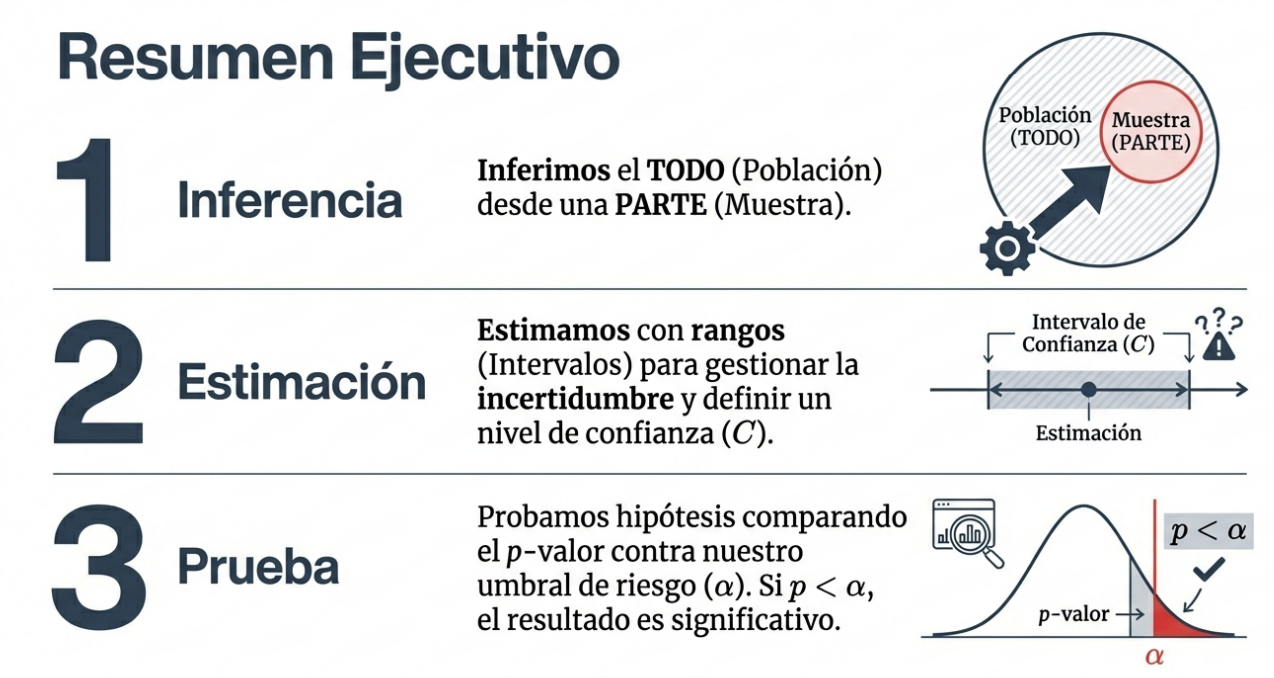
Imagine que supervisa a tres profesores con métodos pedagógicos diferentes o que analiza la viscosidad de cinco lotes de producción. Al revisar los resultados, observa que las medias no son iguales. Entonces surge la pregunta crítica que separa a un gestor de un estratega: ¿esta diferencia indica una verdadera oportunidad operativa o es simplemente ruido estadístico?
Actuar basándose en el «ruido» genera una ineficiencia operativa masiva: se podría detener una línea de producción sin necesidad o ignorar un fallo sistémico costoso simplemente por falta de rigor. Para resolver este dilema, la estadística nos ofrece la herramienta «detective» definitiva: el ANOVA (Análisis de Varianza), diseñado para determinar si las diferencias entre tres o más grupos son lo suficientemente significativas como para justificar una decisión empresarial.
¿Por qué la prueba t no es suficiente?
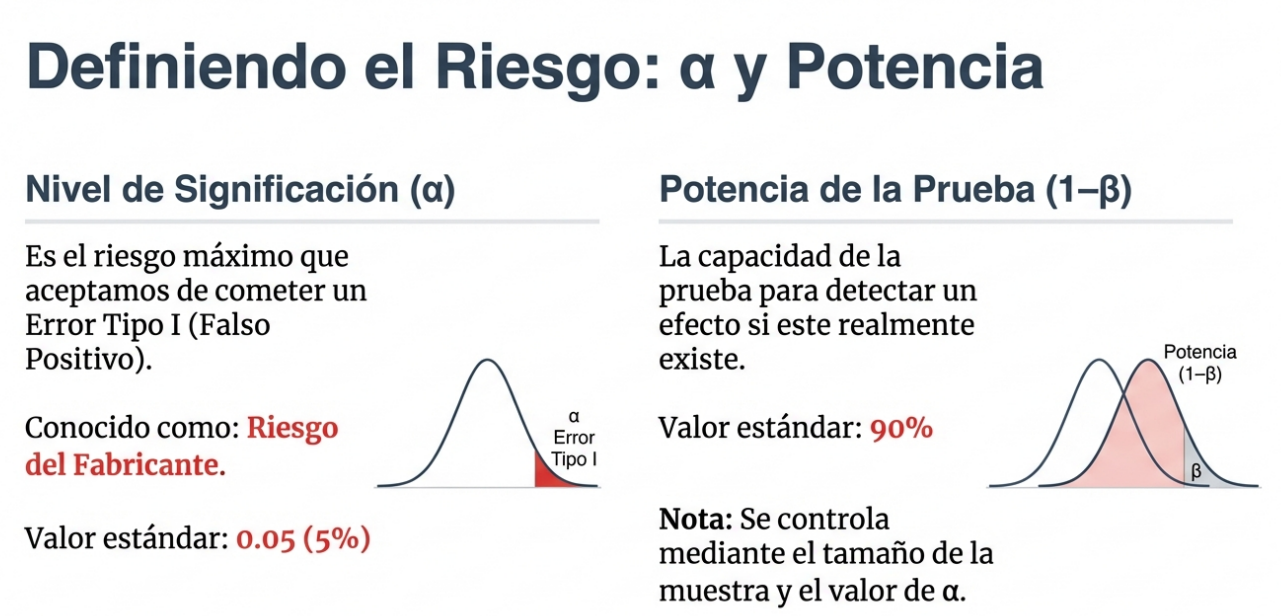
Para comparar dos niveles (por ejemplo, hombres frente a mujeres), la prueba t de Student es adecuada. Sin embargo, cuando enfrentamos tres o más grupos, el ANOVA es obligatorio por una razón técnica crucial: la inflación del error alfa.
Si intentáramos comparar múltiples pares usando pruebas t individuales (lote 1 frente a lote 2, lote 2 frente a lote 3 y lote 1 frente a lote 3), el riesgo de error se acumularía. Cada prueba individual tiene una probabilidad del 5 % de detectar una «falsa diferencia» (falso positivo). Al encadenar pruebas, ese riesgo del 5 % crece exponencialmente, lo que nos lleva a conclusiones erróneas. El ANOVA neutraliza este riesgo al analizar todos los grupos simultáneamente bajo una premisa fundamental:
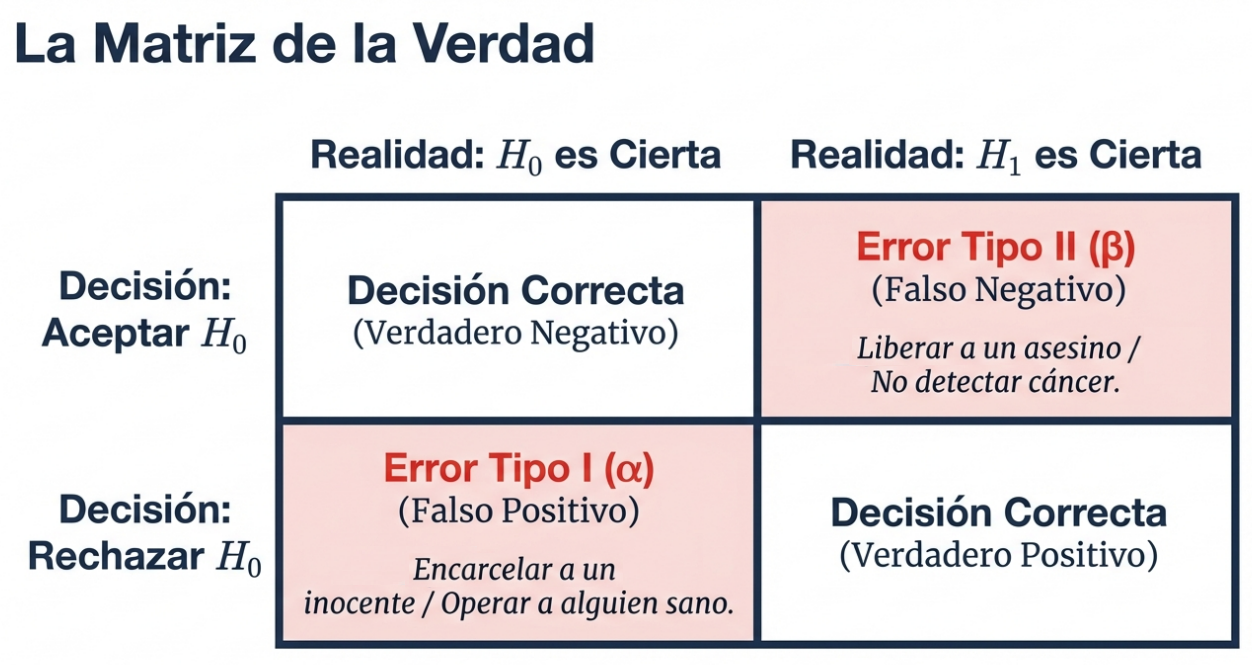
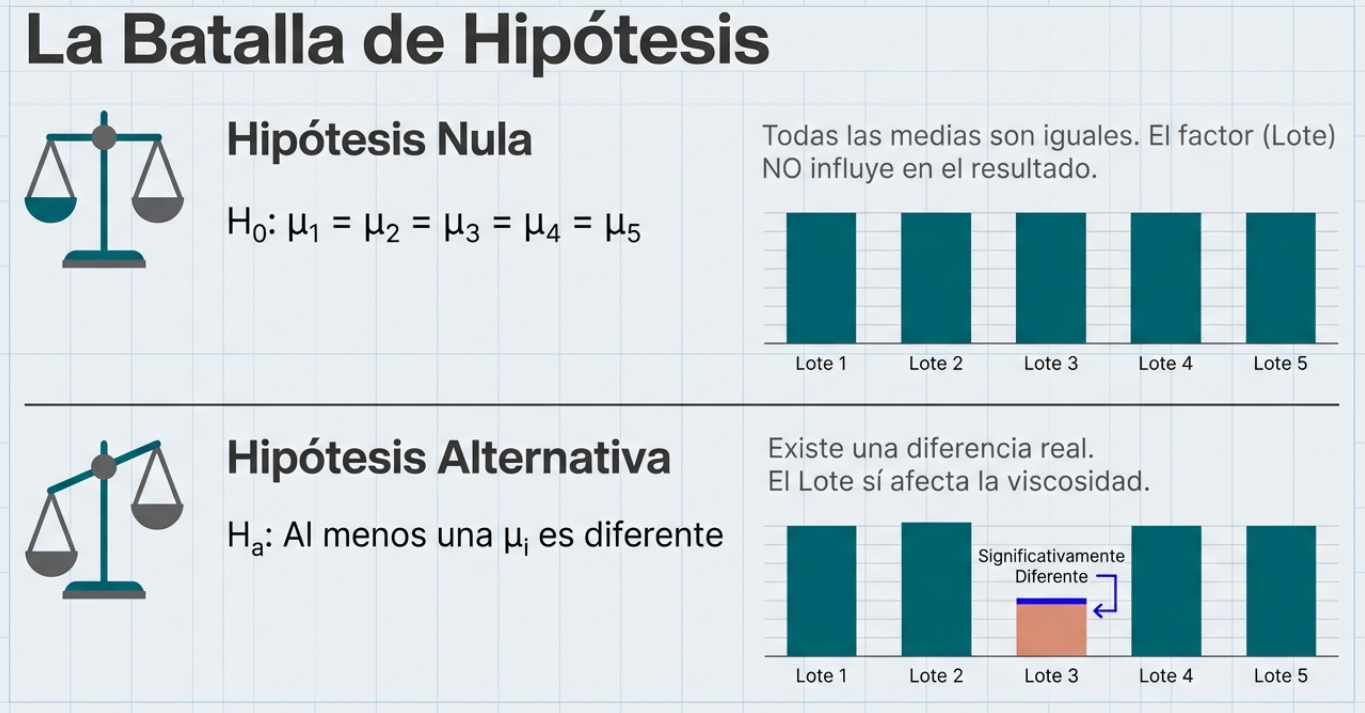
Hipótesis nula (H₀): todas las medias poblacionales son iguales (H₀: μ₁ = μ₂ = ⋯ = μk). El punto de partida estratégico consiste en asumir que el factor estudiado no tiene influencia real hasta que la varianza demuestre lo contrario.
La paradoja central: comparar medias al analizar la variabilidad.
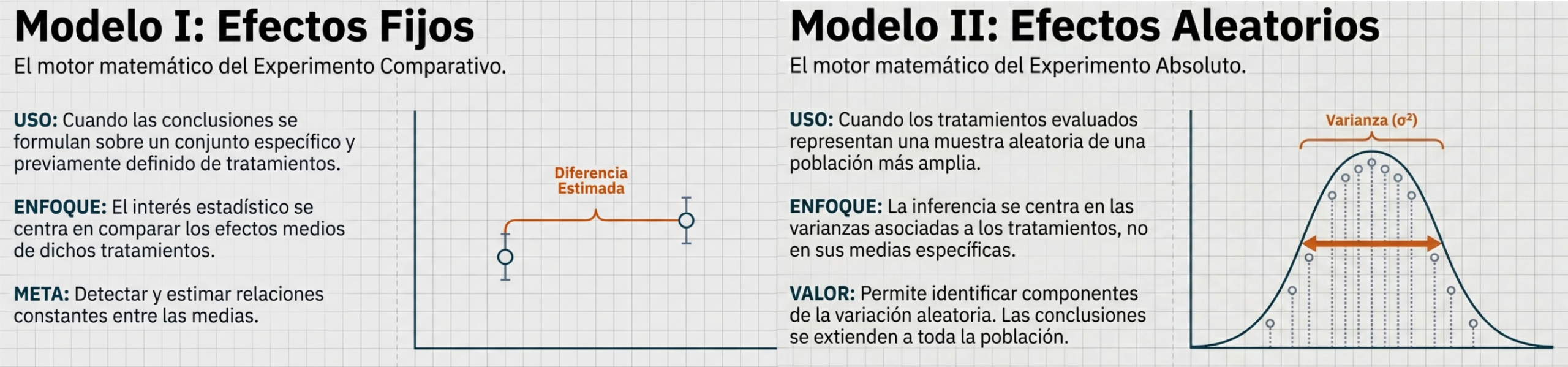
El concepto más contraintuitivo del ANOVA es que, para saber si las medias son distintas, no estudiamos las medias, sino la varianza. El análisis descompone la variabilidad total en dos fuentes:
- Variación entre grupos (factor): el efecto real del tratamiento o de la variable (por ejemplo, el impacto de un nuevo fertilizante).
- Variación dentro de los grupos (error): el ruido aleatorio o las diferencias que no pueden explicarse por el azar.
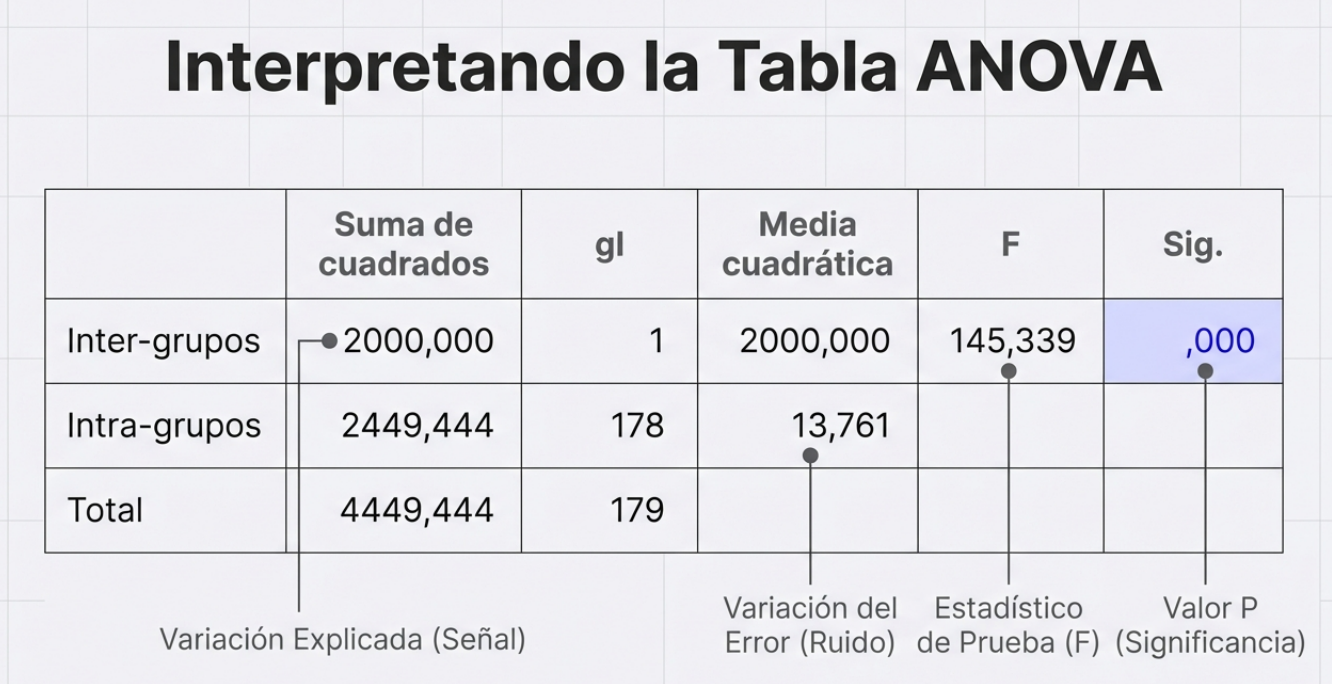
Un estratega sénior no solo busca diferencias, sino que también cuantifica la variabilidad explicada. Usando la relación (SCE/SCT) × 100, podemos determinar qué porcentaje del «caos» de los datos corresponde a la responsabilidad directa del factor analizado. Si el lote explica, por ejemplo, el 44,95 % de la variación de la viscosidad, se trata de un hallazgo de alto impacto administrativo.
El valor p y la razón F: tu seguro contra la casualidad.
Si el ANOVA es un detective, la razón F es su lupa. Matemáticamente, es la relación entre la media de los cuadrados del factor y la media de los cuadrados del error (MCFactor/MCError). Si la razón F es significativamente mayor que 1, la «señal» del factor es más fuerte que el «ruido» del azar.
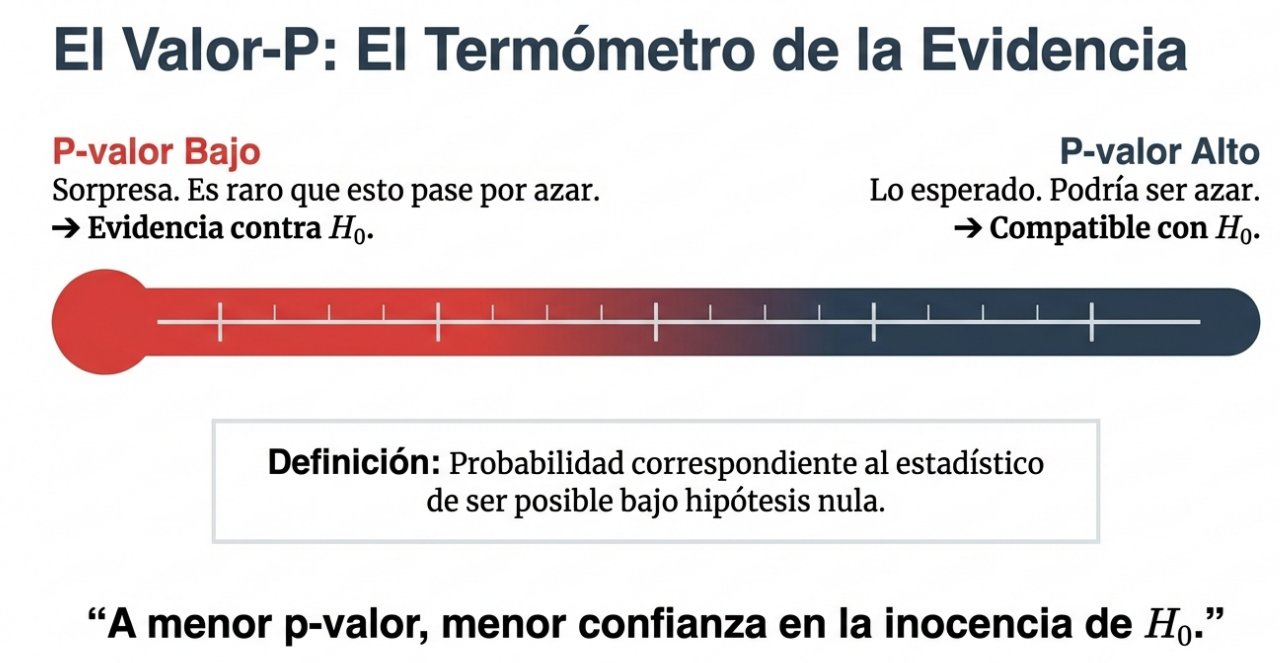
Esta potencia se traduce en el valor p, que es nuestra medida de riesgo. Consideremos el caso del gel adhesivo: tras las quejas de los clientes, se analizaron cinco lotes. El lote 3 mostró una media de 26,77, notablemente inferior al estándar de 30. El ANOVA arrojó un valor p de 0,0012, lo que constituye una prueba contundente para que la gerencia intervenga específicamente en ese lote.
Definición del valor p: probabilidad de observar una varianza en las medias muestrales por mero azar. Un valor p inferior a 0,05 indica que el riesgo de que se trate de un espejismo es lo suficientemente bajo como para actuar.
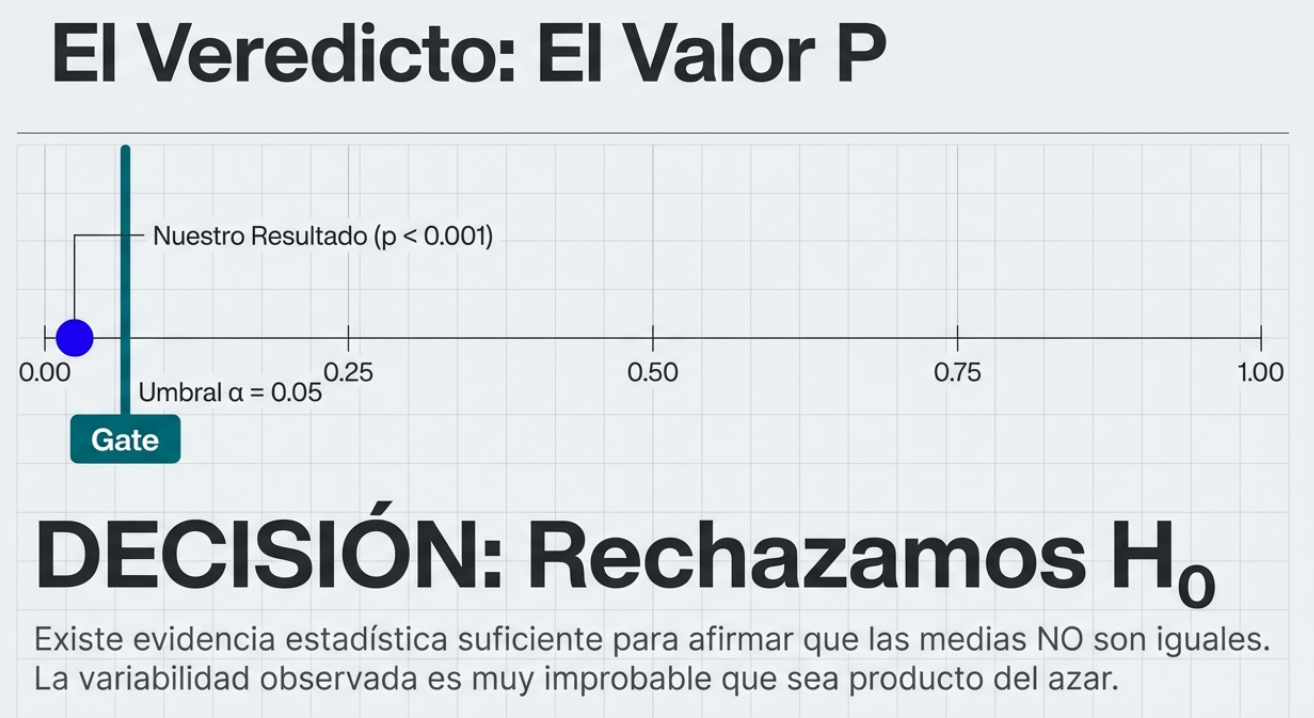
El ANOVA no es una brújula, sino una alarma.
Es un error común creer que el ANOVA señala al «culpable». En realidad, el ANOVA funciona como una alarma: confirma que «no todas las medias son iguales», pero no especifica cuál es la diferente.
Una vez que suena la alarma (p < 0,05), el estratega debe utilizar una «brújula»: las pruebas de comparación múltiple. Herramientas como la prueba de Tukey-Kramer o la HSD de Tukey permiten comparar pares de grupos para identificar exactamente dónde se encuentra la anomalía y realizar una inversión de recursos quirúrgicos de manera eficiente.
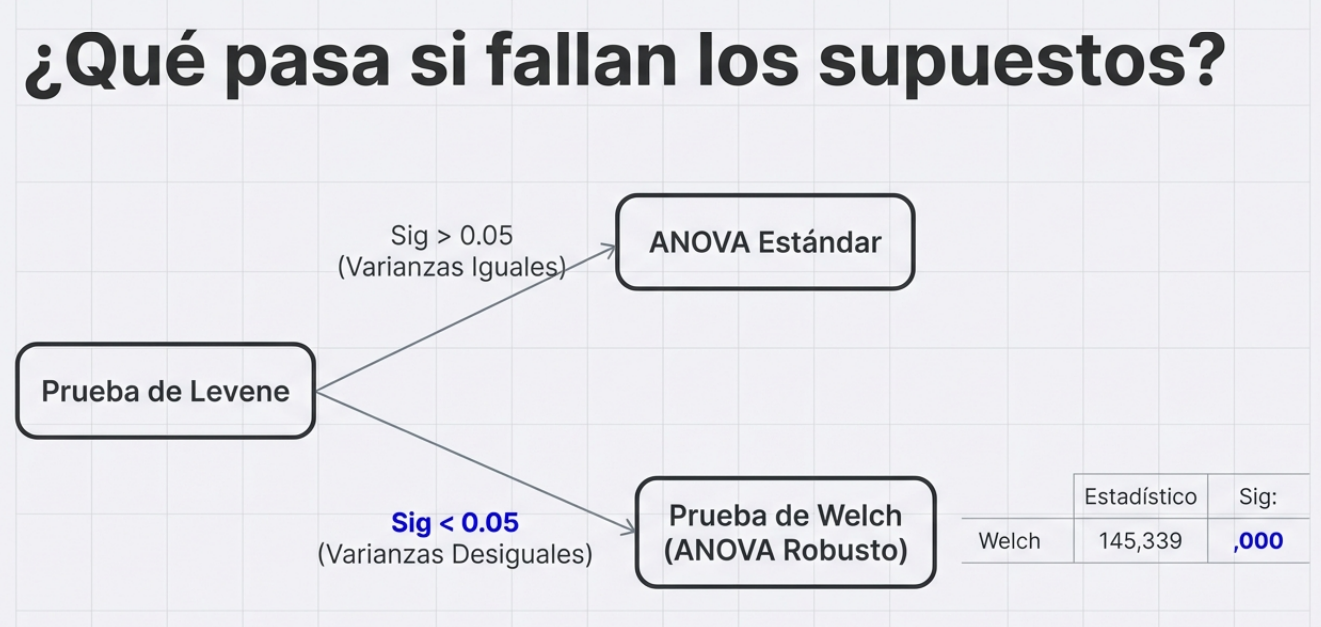
Resiliencia estadística: qué hacer cuando las reglas se rompen.
Para que un ANOVA tradicional sea fiable, los datos deben ser normales y presentar homocedasticidad, es decir, igualdad de varianzas. La prueba de Levene es el filtro crítico aquí.
- Si el valor p de Levene es mayor que 0,05, las varianzas son iguales y el ANOVA es el camino seguro.
- Si Levene es significativo (p < 0,05), las reglas se han roto y el ANOVA estándar pierde validez.
En este escenario de crisis de datos, el investigador recurre a la prueba de Welch. Se trata de una alternativa robusta que permite comparar medias con precisión, incluso cuando las varianzas son desiguales, y que preserva la investigación sin sacrificar el rigor científico.
Conclusión: del dato a la decisión inteligente.
El ANOVA transforma los datos brutos en pruebas de la influencia. Ya sea para validar si un medicamento reduce el tiempo de curación o si un cambio en la composición del hormigón aumenta su resistencia, esta técnica nos permite distinguir entre casualidad y causalidad.
En última instancia, la excelencia en la gestión no consiste en promedios simples, sino en comprender qué parte de los resultados se debe a la variabilidad explicada por las decisiones adoptadas y qué parte es ruido.
Reflexione sobre su operación de hoy: ¿qué variaciones observa en sus procesos que podrían validarse —o descartarse— mediante el rigor del ANOVA?
En esta conversación puedes escuchar algunas de las ideas más importantes sobre ANOVA.
Este vídeo resume bien el tema.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.