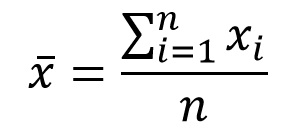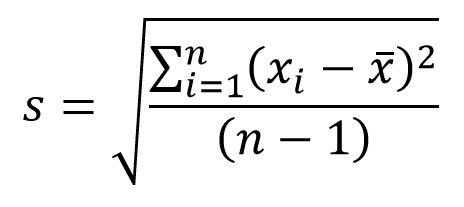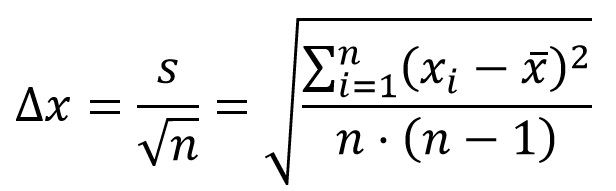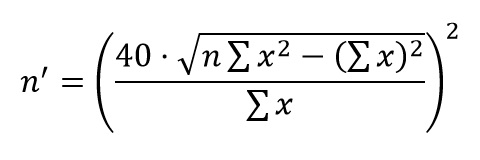Las escalas Likert son un estándar en la investigación social, educativa y empresarial gracias a su simplicidad y eficacia para medir percepciones y actitudes. En ingeniería, son fundamentales para recopilar datos en estudios de usabilidad, en la gestión de proyectos y en el análisis de riesgos, entre otros.
Este artículo amplía el debate sobre las escalas Likert, abordando su diseño, implementación, análisis y aplicaciones prácticas en diversos campos de la ingeniería.
¿Qué son las escalas Likert?

Desarrolladas por Rensis Likert en 1932, estas escalas son un método para medir actitudes mediante una serie de afirmaciones ante las que el encuestado expresa su nivel de acuerdo o desacuerdo. Generalmente, tienen entre 5 y 7 puntos, aunque en ciertas situaciones se utilizan versiones más específicas. Su unidimensionalidad y simplicidad las hacen ideales para capturar datos subjetivos de forma sistemática.
Las principales características son la unidimensionalidad, ya que los ítems deben medir un único constructo (satisfacción, percepción o actitud), la versatilidad, que permite evaluar dimensiones como la frecuencia, la importancia y la probabilidad en diversos contextos, y la comparabilidad, debido a que la estandarización de las respuestas facilita la comparación entre grupos y estudios a lo largo del tiempo.
Los componentes de una escala Likert incluyen afirmaciones o ítems, que son declaraciones sobre las que el encuestado expresa su nivel de acuerdo o desacuerdo; opciones de respuesta, que representan un rango de valores como «Totalmente en desacuerdo», «Neutral» y «Totalmente de acuerdo»; y la puntuación, en la que las respuestas se codifican numéricamente para facilitar el análisis estadístico.
El diseño de un cuestionario con escala Likert
El diseño de un cuestionario bien estructurado es fundamental para garantizar la calidad de los datos recopilados. Esto incluye desde la redacción de las preguntas hasta la elección del tipo de respuesta.
- Redacción de ítems: La calidad de un cuestionario depende de la claridad y precisión de sus elementos, por lo que se recomienda evitar ambigüedades, expresar una sola idea por ítem, utilizar afirmaciones neutrales para minimizar sesgos emocionales y adaptar el lenguaje al contexto, teniendo en cuenta el nivel de comprensión del grupo objetivo. Por ejemplo, la pregunta «Estoy satisfecho con la calidad y el precio del servicio» debería descomponerse en dos preguntas distintas. Formulaciones como «¿Está de acuerdo con que los políticos son corruptos?» introducen sesgos emocionales.
- Opciones de respuesta: Para diseñar opciones de respuesta efectivas, es relevante que sean claras, equidistantes y exhaustivas. El número de categorías debe tenerse en cuenta; cinco es el estándar, mientras que escalas de siete puntos ofrecen mayor precisión y escalas con menos de tres puntos limitan la variabilidad. Además, elegir entre escalas pares o impares influye en los resultados: las pares eliminan el punto medio neutro, lo que obliga a los encuestados a posicionarse en uno de los dos extremos.
- Organización y estructura: La organización y estructura de un cuestionario deben seguir un flujo lógico, aplicando la técnica del embudo, que consiste en comenzar con preguntas generales y poco sensibles, avanzar hacia ítems más específicos y personales y agrupar por temas para mantener la coherencia y reducir la fatiga cognitiva.
- Realización de pretests: Es esencial para evaluar la comprensión, la fluidez y la relevancia del cuestionario, lo que permite identificar y corregir errores antes de su implementación final.
Análisis de datos obtenidos con escalas Likert
La fortaleza de las escalas Likert radica en su capacidad para adaptarse a diversos métodos analíticos. Los datos obtenidos pueden proporcionar información valiosa, ya sea en análisis descriptivos o en modelos avanzados.
1. Análisis descriptivo
- Tendencia central: La media y la mediana resumen la tendencia general de las respuestas.
- Dispersión: Indicadores como el rango o la desviación estándar ayudan a comprender la variabilidad de las respuestas.
- Visualización: Gráficos de barras, histogramas y diagramas de cajas facilitan la interpretación rápida.
2. Relación entre variables
El análisis bivariado permite explorar cómo se relacionan diferentes variables dentro de la escala Likert:
- Correlación de Pearson: evalúa la relación lineal entre dos variables continuas.
- Tablas de contingencia: adecuadas para analizar categorías derivadas de respuestas de Likert.
3. Análisis factorial exploratorio (AFE)
Este enfoque permite identificar dimensiones latentes que subyacen en los ítems:
- Validación estructural: Determina si los ítems agrupan un único constructo o múltiples dimensiones.
- Técnicas de reducción: PCA (Análisis de Componentes Principales) y AFE ayudan a simplificar la interpretación.
4. Evaluación de la fiabilidad
La consistencia interna de una escala se mide comúnmente mediante el alfa de Cronbach. Valores superiores a 0,7 suelen considerarse aceptables.
Ventajas y limitaciones
Entre sus ventajas destacan su accesibilidad, ya que son fáciles de implementar y de entender, su flexibilidad, al adaptarse a diversas áreas de investigación, y su simplicidad analítica, que permite análisis tanto básicos como avanzados. Sin embargo, presentan limitaciones: la deseabilidad social, donde las respuestas pueden estar influenciadas por lo que es socialmente aceptable; la ambigüedad en las opciones medias, ya que categorías como «Neutral» pueden interpretarse de manera diferente; y la unidimensionalidad no garantizada, por lo que es necesario validar su estructura interna mediante análisis factorial.
Aplicaciones en ingeniería
Las escalas Likert tienen amplias aplicaciones en ingeniería, por ejemplo, en estudios de satisfacción para evaluar la percepción de los usuarios sobre productos o servicios, en gestión de riesgos para analizar actitudes hacia posibles escenarios de riesgo en proyectos y en usabilidad de software para medir la experiencia del usuario en el diseño y la funcionalidad de las interfaces. En la evaluación de proyectos, sirven para recopilar información sobre aspectos como el cumplimiento de plazos, la calidad del producto y la eficiencia del equipo.
Conclusión
Las escalas de Likert son una herramienta esencial para medir percepciones, actitudes y comportamientos. Su versatilidad y facilidad de implementación las convierten en una opción popular en investigaciones de ingeniería y de ciencias sociales. El diseño riguroso del cuestionario y el análisis adecuado de los datos garantizan resultados fiables que pueden orientar la toma de decisiones, mejorando procesos y productos en diversos ámbitos de la ingeniería.
A continuación, os dejo una presentación que hice en Santiago de Chile sobre el análisis de cuestionarios basados en escalas de Likert. Espero que sea de vuestro interés.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.