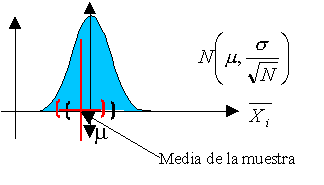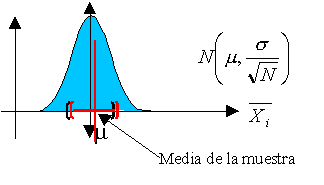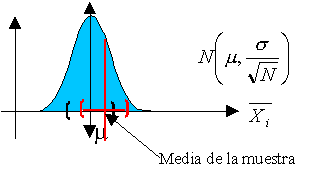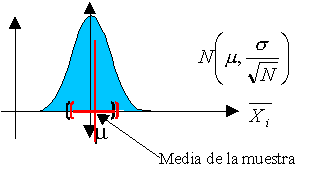
El problema de laestimación puntual y por intervalos para una muestra de una población normal es una actividad muy frecuente en el ámbito de la ingeniería y de la investigación. Supongamos que tenéis una muestra de 5 elementos extraída de una población normal (por ejemplo, de la resistencia a compresión simple de una probeta de hormigón a 28 días procedente de una misma amasada). El objetivo es establecer inferencias estadísticas usando un nivel de significación α=0.05. Deberíais ser capaces de realizar las siguientes actividades:
Calcular el intervalo de confianza para la media, suponiendo que la desviación típica de la población es conocida y vale lo mismo que la desviación típica de la muestra. (Se empleará la distribución normal).
Calcular el intervalo de confianza para la media, suponiendo que la desviación típica de la población es desconocida. (Se empleará la distribución t de Student).
Calcular el intervalo de confianza para la desviación típica de la muestra. (Se empleará la distribución chi-cuadrado).
A continuación os dejo un pequeño tutorial para proceder al cálculo de dichos intervalos utilizando el paquete estadístico Minitab.
Os paso unos vídeos explicativos para que entendáis los conceptos. Espero que os gusten:
The use of novel materials and new structural concepts nowadays is not restricted to highly technical areas like aerospace, aeronautical applications or the automotive industry, but affects all engineering fields including those such as civil engineering and architecture.
The conference addresses issues involving advanced types of structures, particularly those based on new concepts or new materials and their system design. Contributions will highlight the latest development in design, optimisation, manufacturing and experimentation in those areas. The meeting also aims to search for higher performance sustainable materials.
Most high performance structures require the development of a generation of new materials, which can more easily resist a range of external stimuli or react in a non-conventional manner. Particular emphasis will be placed on intelligent structures and materials as well as the application of computational methods for their modelling, control and management.
The conference also addresses the topic of design optimisation. Contributions on numerical methods and different optimisation techniques are also welcome, as well as papers on new software. Optimisation problems of interest to the meeting involve those related to size, shape and topology of structures and materials. Optimisation techniques have much to offer to those involved in the design of new industrial products.
The development of new algorithms and the appearance of powerful commercial computer codes with easy to use graphical interfaces has created a fertile field for the incorporation of optimisation in the design process in all engineering disciplines.
This scientific event is a new edition of the High Performance and Optimum Design of Structures and Materials Conference and follows the success of a number of meetings on structures and materials and on optimum design that originated in Southampton as long ago as 1989. As the meetings evolved they gave rise to the current series, which started in Seville in 2002, and followed by Ancona in 2004, Ostend in 2006, the Algarve in 2008, Tallinn in 2010, the New Forest, home of the Wessex Institute in 2012, Ostend in 2014, Siena in 2016 and Ljubljana in 2018.
The meeting will provide a friendly and useful forum for the interchange of ideas and interaction amongst researchers, designers and scholars in the community to share advances in the scientific fields related to the conference topics
Topics
The following list covers some of the topics to be presented at HPSM/OPTI 2020. Papers on other topics related to the objectives of the conference are welcome
Composite materials
Material characterisation
Experiments and numerical analysis
Natural fibre composites
Nanocomposites
Green composites
Composites for automotive applications
Transformable structures
Environmentally friendly and sustainable structures
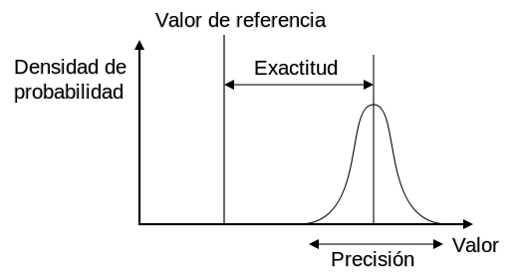
Diferencias entre la exactitud y la precisión de una medida
El uso de calculadoras electrónicas y ordenadores nos hace perder el orden de magnitud de un problema. Como ya comenté en un artículo anterior, el uso masivo de herramientas informáticas atrofian la capacidad intuitiva y de cálculo de los futuros profesionales. Un buen ingeniero o científico debería tener un «número gordo» del resultado antes, incluso, de resolver un problema.
Cuando se miden ciertas cantidades, lo valores medidos se conocen solo dentro de los límites de la incertidumbre experimental. Usamos el número de cifras significativas como una medición que sirve para expresar algo de dicha incertidumbre. De hecho, todas las cifras significativas importan información veraz de la medición, excepto la última, que es incierta.
Para conocer el número correcto de cifras significativas, se siguen las siguientes normas:
Los ceros situados en medio de números diferentes de cero son significativos, por ejemplo, 709 cm tiene tres cifras significativas.
Los ceros a la izquierda del primer número no son significativos, por ejemplo, 0,000057 presenta dos cifras significativas.
Para los números mayores que uno, los ceros escritos a la derecha de la coma decimal también cuentan como cifras significativas, por ejemplo 6,0 tiene dos cifras significativas.
En los números enteros, los ceros situados después de un dígito distinto de cero, pueden ser o no cifras significativas, por ejemplo 8000, puede tener una cifra significativa (el número 8), pero también cuatro. Para evitar el problema se puede usar la notación científica, indicando el número 8000 como 8·103 teniendo solo una cifra significativa (el número 8) o 8,0·103, tenemos dos cifras significativas (8,0).
Existen reglas empíricas que permiten conocer el número de cifras significativas en el caso de operaciones básicas:
Cuando se multiplican o dividen varias cifras, el resultado tiene el mismo número de cifras significativas que el número de menor cifras significativas
Cuando dos números se sumen o resten, el número de lugares decimales en el resultado debe ser igual al número más pequeño de lugares decimales de cualquier término en la suma
El error de medición se define como la diferencia entre el valor medido y el «valor verdadero». Los errores de medición afectan a cualquier instrumento de medición y pueden deberse a distintas causas. Las que se pueden de alguna manera prever, calcular, eliminar mediante calibraciones y compensaciones, se denominan deterministas o sistemáticos y se relacionan con la exactitud de las mediciones. Los que no se pueden prever, pues dependen de causas desconocidas, o estocásticas se denominan aleatorios y están relacionados con la precisión del instrumento.
Sin embargo, para establecer el error en una medida, se debe disponer, junto con la medida de la magnitud, su error y la unidad de medida del Sistema Internacional. En este caso, se deben seguir las siguientes normas:
El error se da con una sola cifra significativa. Se trata del primer dígito comenzando por la izquierda distinto de cero, redondeando por exceso en una unidad si la segunda cifra es 5 o mayor de 5. Sin embargo, como excepción se dan dos cifras significativas para el error si la primera cifra significativa es 1, o bien siendo la primera un 2, la segunda no llega a 5.
La última cifra significativa en el valor de una magnitud física y su error, expresados en las mismas unidades, deben de corresponder al mismo orden de magnitud (centenas, decenas, unidades, décimas, centésimas).
Con una sola medida, se indica el error instrumental, que es la mitad de la menor división de la escala del instrumento usado. Sin embargo, con n medidas directas consecutivas, se considera el error cuadrático de la media (una desviación estándar de la población de las medias). A todo caso, se utilizará el mayor de ambos errores.
En este vídeo explico los aspectos básicos de los errores de medición:
Por otra parte, hay que conocer que los errores se propagan cuando hacemos operaciones matemáticas. Simplificando, cuando tenemos sumas o restas, las cotas de error absoluto se suman; cuando hay productos o divisiones, las cotas de error relativo se suman.
Pero mejor será que os deje un vídeo explicativo del profesor de la UPV, Marcos Herminio Jiménez Valentín. Espero que os aclare este tema.
Este otro vídeo también es de interés para conocer con mayor profundidad la propagación de los errores.
Os dejo también unos pequeños apuntes del profesor Antonio Miguel Posadas Chinchilla, de la Universidad de Almería, que os podéis descargar de este enlace: https://w3.ual.es/~aposadas/TeoriaErrores.pdf
Algunas herramientas que utilizamos en Programación de Proyectos, como las redes de flechas, se basan en la teoría de grafos. Conceptos como nodo, arco, flecha, camino, bucle, etc. son necesarios conocerlos de forma previa al estudio de las técnicas de programación. Os dejo a continuación unos Polimedias de la profesora Cristina Jordán donde se explican brevemente los conceptos básicos de esta teoría. Espero que os gusten.
Referencias:
PELLICER, E.; YEPES, V. (2007). Gestión de recursos, en Martínez, G.; Pellicer, E. (ed.): Organización y gestión de proyectos y obras. Ed. McGraw-Hill. Madrid, pp. 13-44. ISBN: 978-84-481-5641-1. (link)
YEPES, V.; PELLICER, E. (2008). Resources Management, in Pellicer, E. et al.: Construction Management. Construction Managers’ Library Leonardo da Vinci: PL/06/B/F/PP/174014. Ed. Warsaw University of Technology, pp. 165-188. ISBN: 83-89780-48-8.
YEPES, V.; MARTÍ, J.V.; GONZÁLEZ-VIDOSA, F.; ALCALÁ, J. (2012). Técnicas de planificación y control de obras. Editorial de la Universitat Politècnica de València. Ref. 189. Valencia, 94 pp. Depósito Legal: V-423-2012