La inteligencia artificial (IA) se ha ido integrando en la ingeniería civil y la construcción a lo largo de siete décadas, transformando los procesos de diseño, análisis, gestión y ejecución. El siguiente recorrido histórico muestra los avances más relevantes, que han pasado de meras exploraciones teóricas a aplicaciones prácticas que mejoran la eficiencia, la precisión y la toma de decisiones en proyectos de infraestructura.
La inteligencia artificial (IA) se ha ido integrando en la ingeniería civil y la construcción a lo largo de siete décadas, transformando los procesos de diseño, análisis, gestión y ejecución. El siguiente recorrido histórico muestra los avances más relevantes, que han pasado de meras exploraciones teóricas a aplicaciones prácticas que mejoran la eficiencia, la precisión y la toma de decisiones en proyectos de infraestructura.
El artículo examina la evolución histórica de la IA en la ingeniería civil, desde sus fundamentos teóricos en las décadas de los 50 y 60 hasta la actualidad. A continuación, aborda su popularización en la programación y el diseño a través de los sistemas expertos en las décadas de los 70 y 80. En las décadas siguientes, se integró en el análisis estructural y el diseño, y surgió el auge del aprendizaje automático y el análisis de datos para la gestión de proyectos. Más recientemente, la IA se ha combinado con la robótica y otras tecnologías avanzadas para aplicaciones en obra y monitorización. Finalmente, se vislumbra la creación de infraestructuras inteligentes mediante la convergencia de la IA y el Internet de las Cosas.
1. 1950 s–1960 s: Fundación de la IA
En la década de 1950, la IA surgió como disciplina académica, centrada en el desarrollo de máquinas capaces de simular funciones cognitivas humanas. Los primeros trabajos se orientaron hacia el razonamiento simbólico, los sistemas basados en reglas y los algoritmos de resolución de problemas. Estas investigaciones sentaron las bases teóricas necesarias para posteriores aplicaciones en ingeniería civil, aunque en aquel momento todavía no existían implementaciones específicas en el sector de la construcción.
2. 1970 s–1980 s: Sistemas expertos y sistemas basados en conocimiento
Entre los años 1970 y 1980 se popularizaron los sistemas expertos, que imitaban la forma en que los especialistas en dominios concretos tomaban decisiones. En ingeniería civil, estos sistemas se aplicaron a tareas como la programación de proyectos (scheduling), la optimización de diseños y la evaluación de riesgos, emulando el saber de ingenieros veteranos. Paralelamente, los sistemas basados en el conocimiento centralizaban esta información en bases de datos y ofrecían asistencia automatizada para la toma de decisiones en obra y en oficina técnica.
3. 1990 s–2000 s: Integración en análisis estructural y diseño
Durante los años 90 y principios de los 2000, la IA comenzó a tener un impacto directo en el análisis estructural y la optimización del diseño. Se emplearon redes neuronales y lógica difusa para modelar comportamientos complejos de materiales y estructuras. Al mismo tiempo, surgieron los primeros sistemas de monitorización de la salud estructural que, mediante algoritmos de IA, permitían evaluar el estado de puentes y edificios en tiempo real. En gestión de obra, las primeras herramientas asistidas por IA empezaron a abordar la programación, la estimación de costes y el análisis de riesgos.
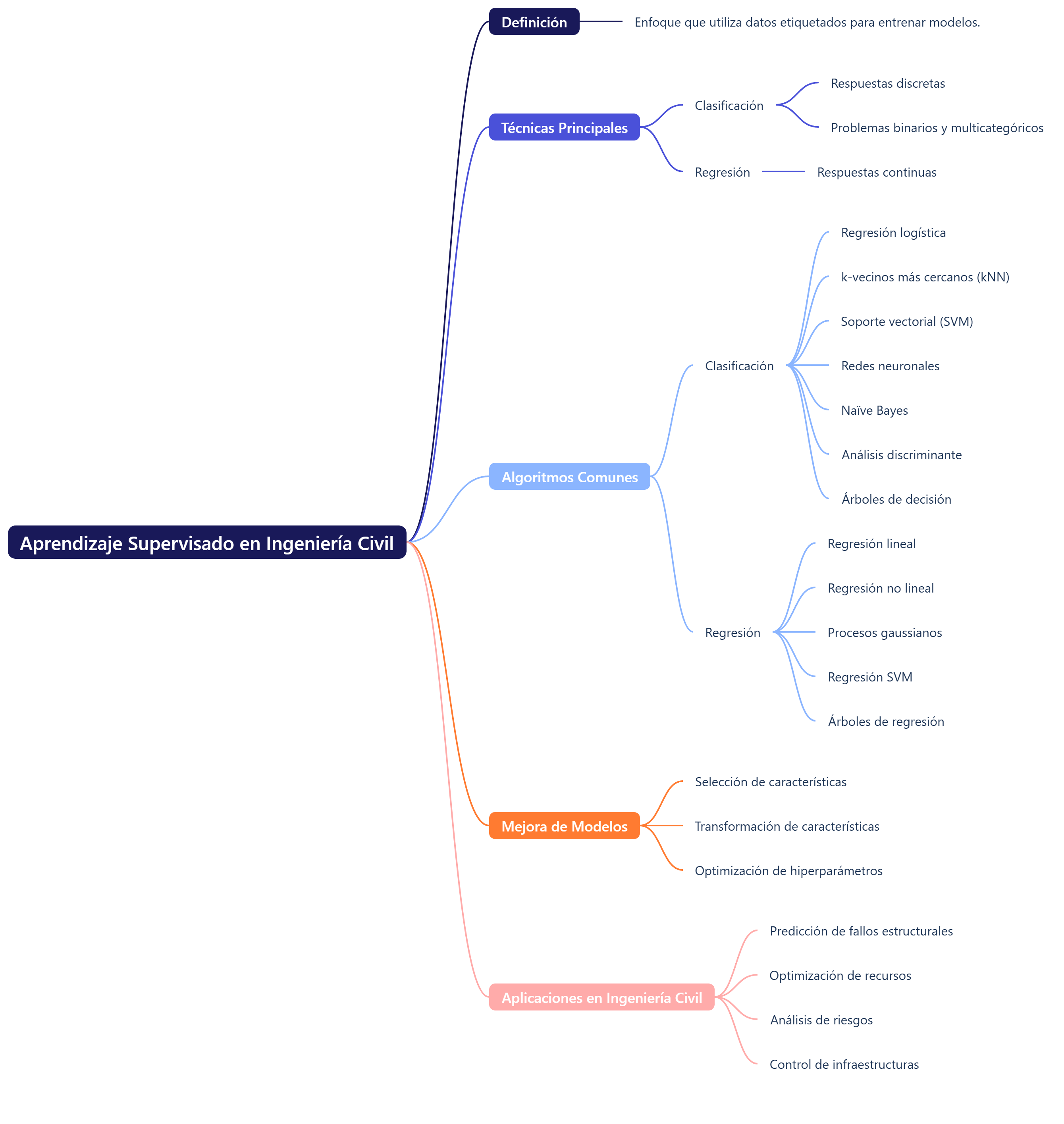
4. 2000 s–2010 s: Aprendizaje automático y analítica de datos
La explosión del machine learning y el big data en estos años transformó la previsión de plazos, recursos y costes. Las técnicas de aprendizaje supervisado y no supervisado se integraron en plataformas de gestión de proyectos, mientras que la Modelización de la Información de Edificación (BIM) incorporó algoritmos de inteligencia artificial para mejorar la colaboración multidisciplinar, la detección de conflictos (clash detection) y la toma de decisiones basada en datos.
5. 2010 s–presente: Aplicaciones avanzadas y robótica
A partir de 2010, se intensificó la convergencia entre la inteligencia artificial y la robótica en obra. Aparecieron vehículos autónomos para tareas de excavación, drones integrados con visión por ordenador para inspeccionar los progresos y brazos robóticos en plantas de prefabricados. Asimismo, se generalizó el uso de la realidad virtual y aumentada para visualizar diseños y realizar simulaciones en tiempo real, lo que permite realizar ajustes adaptativos durante la ejecución de los proyectos.
6. Perspectivas futuras: IA e infraestructuras inteligentes
El documento señala la próxima convergencia de la IA con el Internet de las Cosas (IoT) para el desarrollo de infraestructuras inteligentes que puedan monitorizarse de forma continua y realizar mantenimiento predictivo. También se espera la aparición de materiales inteligentes y técnicas de diseño generativo que optimicen la sostenibilidad y la resiliencia de las construcciones, cerrando el ciclo de operación, mantenimiento y rehabilitación de infraestructuras.
Conclusión
Este artículo repasa la trayectoria que va desde los inicios teóricos de la IA hasta sus aplicaciones robóticas y de análisis en tiempo real actuales. Cada etapa ha aportado nuevas herramientas al ingeniero civil: desde los sistemas expertos de los años setenta hasta las infraestructuras inteligentes del mañana, la IA continuará redefiniendo la práctica de la ingeniería civil, haciéndola más eficiente, segura y sostenible.
Glosario de términos clave
- Inteligencia Artificial (IA): Disciplina académica centrada en el desarrollo de máquinas capaces de simular funciones cognitivas humanas.
- Sistemas Expertos: Programas informáticos que imitan la forma en que los especialistas en dominios concretos toman decisiones, utilizando conocimiento y reglas.
- Sistemas Basados en Conocimiento: Sistemas que centralizan información en bases de datos para ofrecer asistencia automatizada en la toma de decisiones.
- Razonamiento Simbólico: Enfoque inicial de la IA que se basa en la manipulación de símbolos para representar conocimiento y realizar inferencias.
- Algoritmos de Resolución de Problemas: Procedimientos sistemáticos o heurísticos utilizados por la IA para encontrar soluciones a problemas definidos.
- Redes Neuronales: Modelos computacionales inspirados en la estructura y funcionamiento del cerebro humano, utilizados para reconocer patrones y aprender de datos.
- Lógica Difusa: Enfoque que permite el razonamiento con información imprecisa o incierta, utilizando grados de verdad en lugar de valores booleanos (verdadero/falso).
- Monitorización de la Salud Estructural: Evaluación continua del estado de estructuras como puentes y edificios para detectar deterioros o fallos.
- Machine Learning (Aprendizaje Automático): Subcampo de la IA que permite a los sistemas aprender de datos sin ser programados explícitamente, utilizando algoritmos para identificar patrones y hacer predicciones.
- Big Data: Conjuntos de datos extremadamente grandes y complejos que requieren herramientas y técnicas avanzadas para su análisis.
- Aprendizaje Supervisado: Tipo de machine learning donde el algoritmo aprende de datos de entrenamiento etiquetados (con resultados conocidos).
- Aprendizaje No Supervisado: Tipo de machine learning donde el algoritmo busca patrones y estructuras en datos no etiquetados.
- Modelización de la Información de Edificación (BIM): Proceso inteligente basado en modelos 3D que proporciona información sobre un proyecto de construcción a lo largo de su ciclo de vida.
- Detección de Conflictos (Clash Detection): Proceso en BIM que identifica colisiones o interferencias entre diferentes elementos o sistemas de un diseño.
- Robótica: Campo que combina la ingeniería y la ciencia para diseñar, construir, operar y aplicar robots.
- Visión por Ordenador: Campo de la IA que permite a los ordenadores “ver” e interpretar imágenes y videos.
- Realidad Virtual: Tecnología que crea un entorno simulado por ordenador con el que el usuario puede interactuar.
- Realidad Aumentada: Tecnología que superpone información digital (imágenes, sonidos, datos) sobre el mundo real.
- Internet de las Cosas (IoT): Red de objetos físicos (“cosas”) integrados con sensores, software y otras tecnologías para recopilar e intercambiar datos a través de internet.
- Infraestructuras Inteligentes: Infraestructuras equipadas con sensores y sistemas de comunicación que utilizan IA e IoT para monitorizarse, gestionarse y optimizarse de forma autónoma.
- Mantenimiento Predictivo: Estrategia de mantenimiento que utiliza datos y algoritmos para predecir cuándo es probable que falle un equipo o componente, permitiendo realizar acciones de mantenimiento antes de que ocurra la falla.
- Diseño Generativo: Proceso de diseño donde los algoritmos de IA exploran un vasto espacio de posibles soluciones basándose en un conjunto de parámetros y objetivos definidos.
Referencias:
DONAIRE-MARDONES, S.; BARRAZA ALONSO, R.; MARTÍNEZ-PAGÁN, P.; YEPES-BELLVER, L.; YEPES, V.; MARTÍNEZ-SEGURA, M.A. (2024). Innovación educativa con realidad aumentada: perspectivas en la educación superior en ingeniería. En libro de actas: X Congreso de Innovación Educativa y Docencia en Red. Valencia, 11 – 12 de julio de 2024. DOI: https://doi.org/10.4995/INRED2024.2024.18365
GARCÍA, J.; VILLAVICENCIO, G.; ALTIMIRAS, F.; CRAWFORD, B.; SOTO, R.; MINTATOGAWA, V.; FRANCO, M.; MARTÍNEZ-MUÑOZ, D.; YEPES, V. (2022). Machine learning techniques applied to construction: A hybrid bibliometric analysis of advances and future directions. Automation in Construction, 142:104532. DOI:10.1016/j.autcon.2022.104532
FERNÁNDEZ-MORA, V.; NAVARRO, I.J.; YEPES, V. (2022). Integration of the structural project into the BIM paradigm: a literature review. Journal of Building Engineering, 53:104318. DOI:10.1016/j.jobe.2022.104318.
YEPES, V.; KRIPKA, M.; YEPES-BELLVER, L.; GARCÍA, J. (2023). La inteligencia artificial en la ingeniería civil: oportunidades y desafíos. IC Ingeniería Civil, 642:20-23.