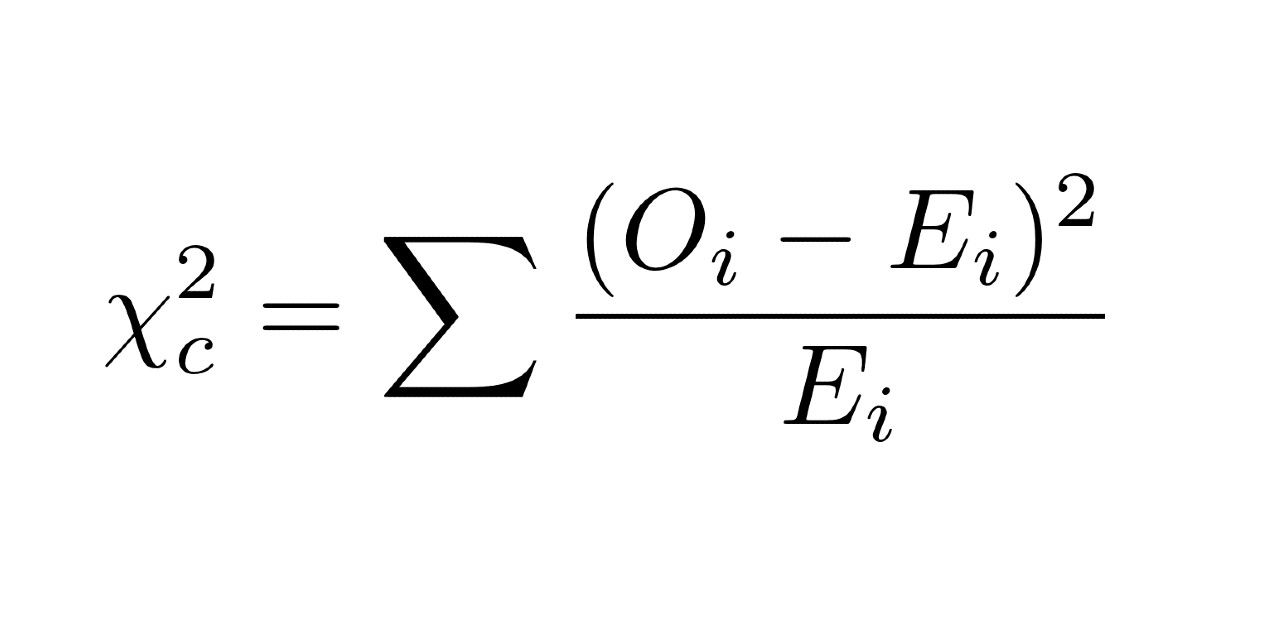Laboratorio de materiales de ICITECH. https://icitech.blogs.upv.es/index.php/home/laboratorio-de-materiales/
En la asignatura de “Modelos predictivos y de optimización de estructuras de hormigón”, del Máster en Ingeniería del Hormigón, se desarrollan laboratorios informáticos. En este caso, os traigo un ejemplo de aplicación de un diseño de experimentos. En este caso, un diseño de experimentos por bloques aleatorizados resuelto con SPSS y MINITAB.
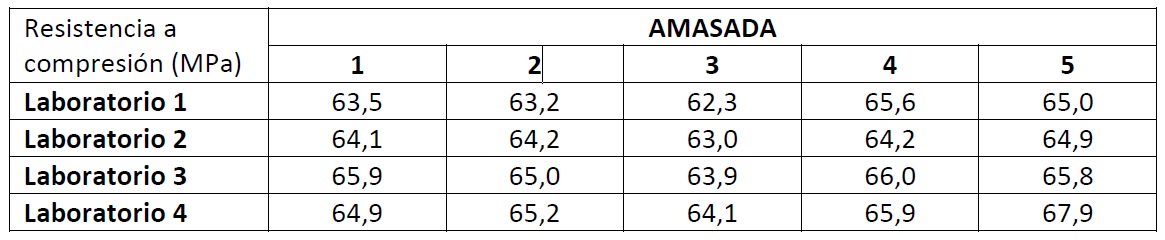
Se pretende comparar la resistencia a compresión simple a 28 días obtenidos por cuatro laboratorios diferentes. Para ello se realizan cinco amasadas diferentes y se obtienen las resistencias medias para cada amasada por cada uno de los laboratorios. Los resultados se encuentran en la tabla que sigue.
Os paso la resolución de este laboratorio informático. Espero que os sea de interés.
Figura 1. ¿Depende la calidad del hormigón de un proveedor determinado?
En ocasiones nos encontramos con un par de variables cualitativas que, a priori, no sabemos si están relacionadas entre sí o si pertenecen a una misma población estadística. Recordemos que las variables cualitativas son aquellas cuyo resultado es un valor o categoría de entre un conjunto finito de respuestas (tipo de defecto, nombre del proveedor, color, etc.).
En el ámbito del hormigón, por ejemplo, podríamos tener varios proveedores de hormigón preparado en central y un control del número de cubas-hormigonera aceptadas, aceptadas con defectos menores o rechazadas. Otro ejemplo sería contabilizar el tipo de incumplimiento de una tolerancia por parte de un equipo que está encofrando un muro de contención. En estos casos, se trata de determinar si existe dependencia entre los proveedores o los equipos de encofradores respecto de los defectos detectados. Esto sería interesante en el ámbito del control de la calidad para tomar medidas, como pudiese ser descartar a determinados proveedores o mejorar la formación de un equipo de encofradores.
Así, podríamos tener un problema como el siguiente: Teniendo en cuenta el punto 5.6 del Anejo 11 de la EHE, donde se definen las tolerancias de muros de contención y de sótano, se quiere comprobar si tres equipos de encofradores producen de forma homogénea en la ejecución de muros vistos, o, por el contrario, si unos equipos producen más defectos de un tipo que otro. Todos los equipos emplean el mismo tipo de encofrado. Las tolerancias que deben cumplirse son:
1. Desviación respecto a la vertical
2. Espesor del alzado
3. Desviación relativa de las superficies planas de intradós o de trasdós
4. Desviación de nivel de la arista superior del intradós, en muros vistos
5. Tolerancia de acabado de la cara superior del alzado, en muros vistos
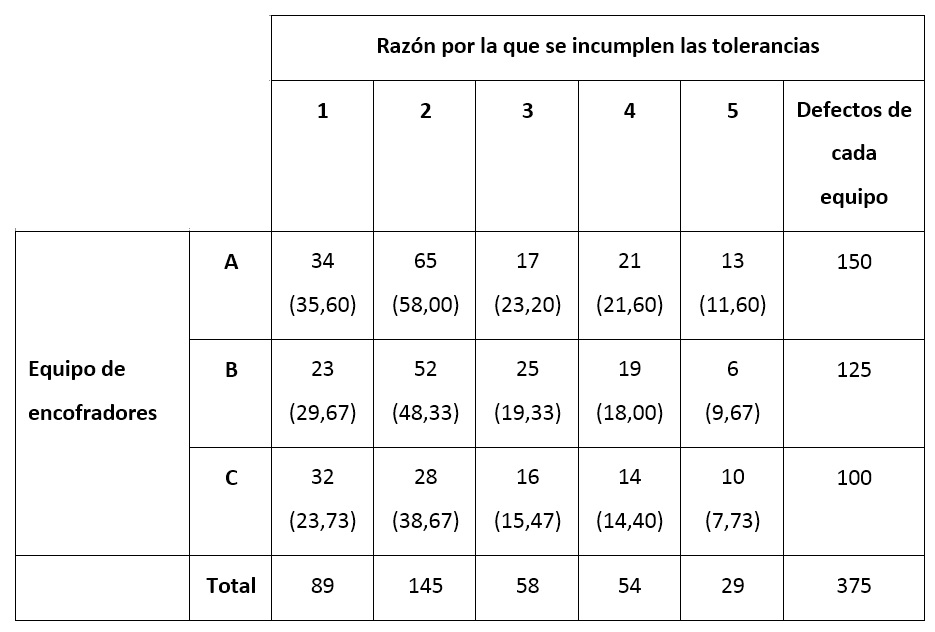
Los equipos han estado trabajando durante un año ejecutando este tipo de unidad de obra. Durante este tiempo el número de defectos en relación con la tolerancia dimensional ha sido pequeño, pero se han contabilizado 375 defectos. El control de calidad ha dado como resultado el conteo de la tabla de la Figura 2.
Figura 2. Conteo de incumplimientos según el equipo de encofradores. En paréntesis figura el valor esperado.
En la Figura 2 se ha representado también la frecuencia esperada para cada uno de los casos. Por ejemplo, la fracción esperada del incumplimiento «1» es de 89/375, mientras que la fracción esperada de defectos del equipo A es de 150/375. Ello implica que el valor esperado de incumplimientos del tipo «1» para el equipo de encofradores «A» sería: (89/375)·(150/375)·375=89·150/375=35,60.
La pregunta que nos podríamos hacer es la siguiente: ¿Influye el tipo de proveedor en la calidad de la recepción del hormigón? Para ello plantearíamos la hipótesis nula: el tipo de proveedor no influye en la calidad de la recepción del hormigón. La hipótesis alternativa sería que sí existe dicha influencia o dependencia entre las variables cualitativas.
Para ello, necesitamos una prueba estadística; en este caso, la prueba χ². El fundamento de la prueba χ² es comparar la tabla de las frecuencias observadas respecto a la de las frecuencias esperadas (que sería la que esperaríamos encontrar si las variables fueran estadísticamente independientes o no estuvieran relacionadas). Esta prueba permite obtener un p-valor (probabilidad de equivocarnos si rechazamos la hipótesis nula) que podremos contrastar con el nivel de confianza que determinemos. Normalmente el umbral utilizado es de 0,05. De esta forma, si p < 0,05, se rechaza la hipótesis nula y, por tanto, diremos que las variables son dependientes. Dicho con mayor precisión, en este caso no existe un nivel de significación suficiente que respalde la independencia de las variables.
Las conclusiones que se obtienen de la prueba son sencillas de interpretar. Si no existe mucha diferencia entre los valores observados y los esperados, no hay razones para dudar de que las variables sean independientes.
No obstante, hay algunos problemas con la prueba χ², entre ellos el relacionado con el tamaño muestral. A mayor número de casos analizados, el valor de la χ² tiende a aumentar. Es decir, si la muestra es excesivamente grande, será más fácil que rechacemos la hipótesis nula de independencia, cuando a lo mejor podrían ser las variables independientes.
Por otra parte, cada una de las celdas de la tabla de contingencia debería contar con un mínimo de 5 observaciones esperadas. Si no fuera así, podríamos agrupar filas o columnas (excepto en tablas 2×2). También se podría eliminar la fila que muestra una frecuencia esperada menor que 5.
Por último, no hay que abusar de la prueba χ². Por ejemplo, podríamos tener una variable numérica, como la resistencia característica del hormigón, y agruparla en una variable categórica en grupos como 25, 30, 35, 40, 45 y 50 MPa. Lo correcto cuando tenemos una escala numérica es aplicar la prueba t de Student; es incorrecto convertirla en una escala ordinal o incluso binaria.
A continuación os dejo el problema anterior resuelto, tanto con el programa SPSS como con MINITAB.
Una tarea básica en cualquier trabajo científico o tecnológico que requiera el análisis de una muestra de datos es su caracterización estadística y la comprobación de la normalidad de dicha muestra. Dado un conjunto de datos, por ejemplo 20 resultados de rotura a compresión simple de una probeta normalizada de hormigón a 28 días, deberíais ser capaces de calcular lo siguiente:
Calcular la media aritmética muestral, la desviación típica muestral, la varianza muestral , el coeficiente de variación muestral, la mediana y la moda
Determinar el intervalo de confianza para la media muestral y para la desviación típica muestral para un nivel de confianza del 95%.
Determinar las medidas de forma –coeficientes de asimetría y curtosis-.
Determinar el recorrido o rango de la muestra. También el recorrido relativo de la muestra.
Representar el histograma con un número de barras que sea la raíz cuadrada del número de datos
Calcular la desviación media respecto al valor mínimo.
Determinar el primer, segundo y tercer cuartil, así como el rango intercuartílico.
Determinar el cuantil del 5%, del 50% y del 95%.
Dibujar el diagrama de caja y bigotes y determinar los valores atípicos potenciales.
Establecer con un nivel de confianza del 95% si la muestra procede de una población normal mediante la prueba de normalidad de Kolmogorov-Smirnov.
Para ello podéis utilizar cualquier programa estadístico. Para facilitar vuestro aprendizaje, os dejo un vídeo tutorial sobre cómo extraer datos estadísticos básicos con el programa SPSS. Espero que os sea útil.