 En el panorama actual de la educación superior, la integridad académica se enfrenta a un desafío sin precedentes. La explosión de los modelos de lenguaje extensos (LLM), personificada por ChatGPT —que alcanzó la asombrosa cifra de 100 millones de usuarios en apenas dos meses—, ha sumido a las instituciones en una carrera frenética para detectar el contenido generado por máquinas. Sin embargo, en esta búsqueda de certezas surge una pregunta que todo docente debe hacerse: ¿estamos interpretando correctamente las herramientas en las que confiamos?
En el panorama actual de la educación superior, la integridad académica se enfrenta a un desafío sin precedentes. La explosión de los modelos de lenguaje extensos (LLM), personificada por ChatGPT —que alcanzó la asombrosa cifra de 100 millones de usuarios en apenas dos meses—, ha sumido a las instituciones en una carrera frenética para detectar el contenido generado por máquinas. Sin embargo, en esta búsqueda de certezas surge una pregunta que todo docente debe hacerse: ¿estamos interpretando correctamente las herramientas en las que confiamos?
Un estudio fundamental de Lucky E. Atamhenwan (2026) arroja luz crítica y necesaria sobre el detector de IA de Turnitin. A través de un análisis riguroso de 81 guiones que mezclaban prosa humana con contenido generado por modelos como ChatGPT (GPT-4o), Copilot, Gemini y Grammarly, Atamhenwan explora una frontera donde chocan la estadística y la pedagogía: ¿qué tan preciso es Turnitin cuando lo humano y lo artificial se entrelazan?
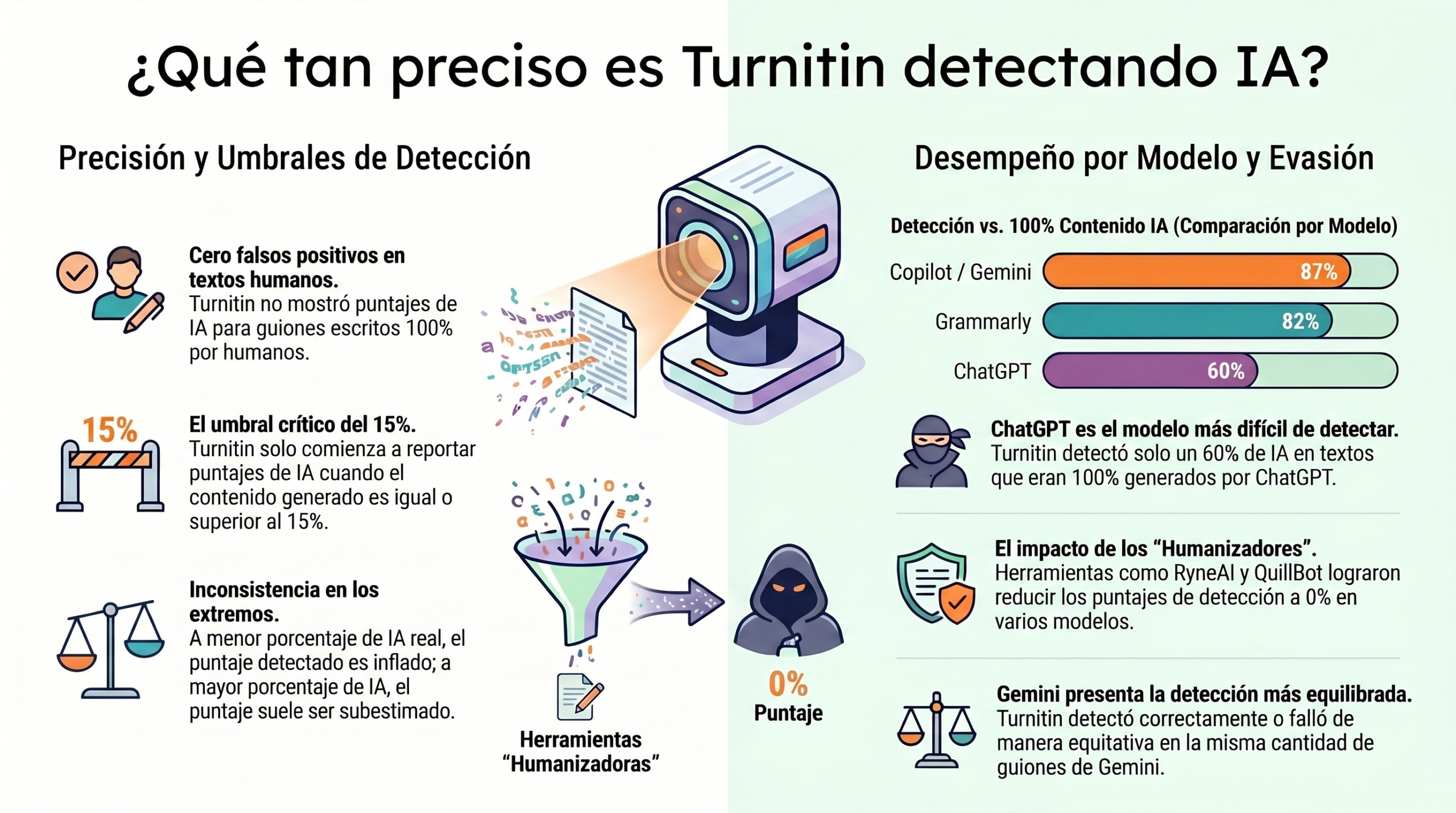
Este estudio investiga la capacidad de Turnitin para identificar el contenido generado por diversas inteligencias artificiales frente al contenido escrito por humanos. El autor analizó ochenta y un documentos con distintos porcentajes de mezcla y descubrió que la herramienta es inconsistente y tiende a fallar cuando el contenido de IA es bajo. Los resultados demuestran que Turnitin solo activa sus alarmas cuando el texto generado por máquinas supera el 15 %, aunque sus puntuaciones rara vez son exactas. Además, la investigación revela que el uso de herramientas de parafraseo puede eludir con éxito la detección, lo que hace que los textos artificiales parezcan humanos. Ante estos desafíos, el autor sugiere la implementación de exámenes presenciales con navegadores bloqueados y la promoción de la cooperación entre instituciones y desarrolladores de tecnología. En definitiva, el artículo advierte que los educadores no deben confiar ciegamente en los porcentajes de detección al tomar decisiones académicas importantes.
1. El «punto ciego» del 15 %: cuando la IA pasa desapercibida.
Una de las realidades más contundentes que revela la investigación es la existencia de un umbral de invisibilidad técnica. El estudio analizó guiones con un 5 % y un 10 % de contenido generado por IA, mezclados con texto humano. En estos niveles, Turnitin no detectó la presencia de IA y mostró un asterisco en su interfaz.
Para el educador, es fundamental comprender que este asterisco no es un error, sino que indica una puntuación inferior al umbral de notificación (menos del 15 %). Si un estudiante utiliza la IA de manera puntual —para ajustar párrafos aislados o pulir transiciones—, la herramienta es esencialmente ciega. Sin embargo, como analista, debo destacar un dato del análisis de regresión del estudio: el valor de R2 de Nagelkerke de 0,825 indica que el 82,5 % de la varianza en los resultados de Turnitin se explica por la presencia real de IA. Esto significa que, aunque Turnitin no sea preciso en cuanto al volumen, si la herramienta marca cualquier cifra superior al 15 %, es casi seguro que hay intervención de un LLM, incluso si el porcentaje indicado es inexacto.

2. La paradoja de la proporción: menos es más (y viceversa).
Quizás el hallazgo más inquietante de Atamhenwan sea la falta de linealidad en las puntuaciones. No existe una relación proporcional directa entre la cantidad de IA presente y lo que informa Turnitin. De hecho, la herramienta incurre en una contradicción sistemática que he denominado «Paradoja de la Proporción»:
- Contenido de IA bajo (15-40 %): Turnitin tiende a arrojar puntuaciones exageradamente altas, lo que distorsiona la percepción del uso de IA.
- Contenido de IA alto (70-100 %): la herramienta subestima la presencia artificial y arroja puntuaciones consistentemente más bajas de lo que debería.
Esta distorsión es tan marcada que el autor la sintetiza de forma magistral:
«Cuanto menor sea el porcentaje de palabras generadas realmente por un gran modelo de lenguaje (LLM) en un texto, más inexactamente elevada será la puntuación de la IA de Turnitin. Por el contrario, cuanto mayor sea el porcentaje de palabras generadas por un LLM, más inexactamente baja será la puntuación de la IA de Turnitin».

3. El maestro del disfraz: la ironía de ChatGPT frente a Gemini.
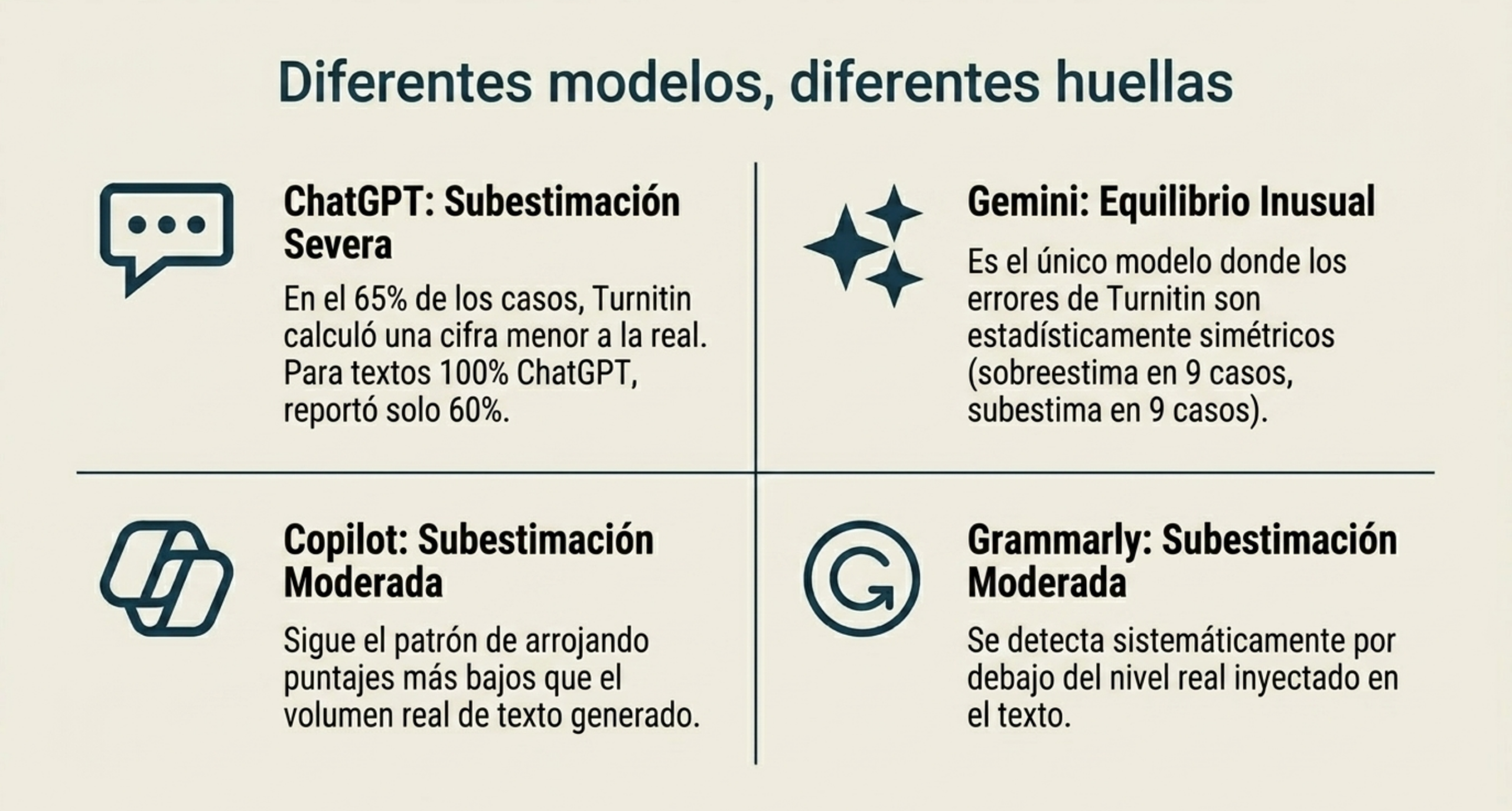
Resulta fascinante —y profundamente irónico— que el modelo más popular sea el más difícil de detectar. Aunque Turnitin afirma haber sido entrenado específicamente para detectar los patrones de OpenAI, ChatGPT (GPT-4o) demostró ser el maestro del disfraz en este estudio de 2026.
Turnitin clasificó el contenido de ChatGPT como «escrito por humanos» en 13 de los 20 guiones que probó. La disparidad es alarmante: en los guiones en los que el texto era 100 % generado por ChatGPT, Turnitin apenas detectó un 60 %. En comparación, Gemini de Google mostró resultados mucho más equilibrados, con 9 guiones detectados por encima y 9 por debajo del valor real. Como analista de tecnología, esta diferencia sugiere que, mientras Gemini mantiene patrones lingüísticos que Turnitin identifica con mayor frecuencia, ChatGPT ha evolucionado hacia una sofisticación que incluso elude a los detectores entrenados para vigilarlo.
4. El escudo de la «humanización» y el rastro de OpenAI.
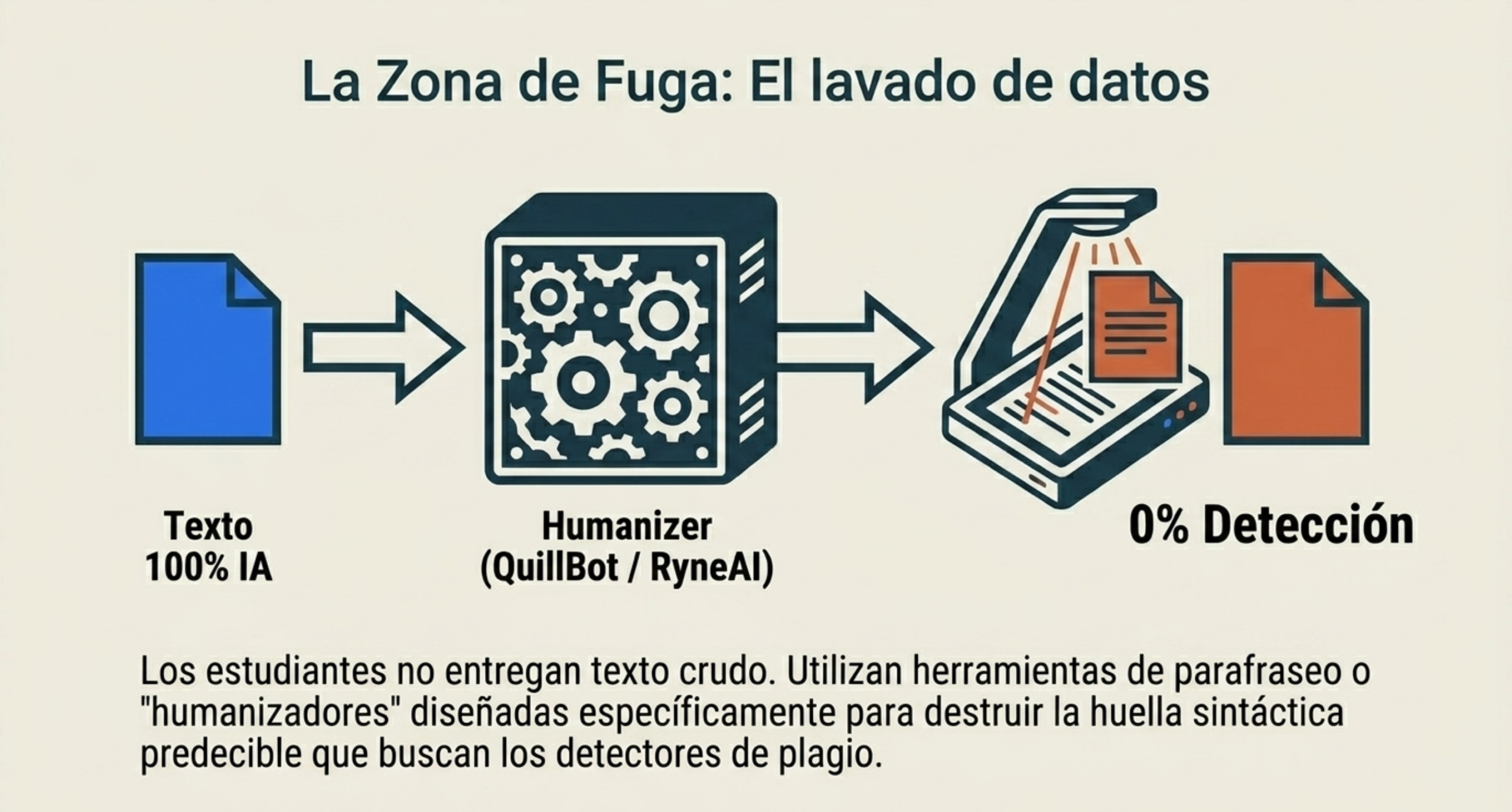
El estudio abordó el «juego del gato y el ratón» entre los detectores y los denominados «humanizadores» de texto, como QuillBot y RyneAI. Los resultados confirman que estas herramientas son armas efectivas para erosionar la integridad académica:
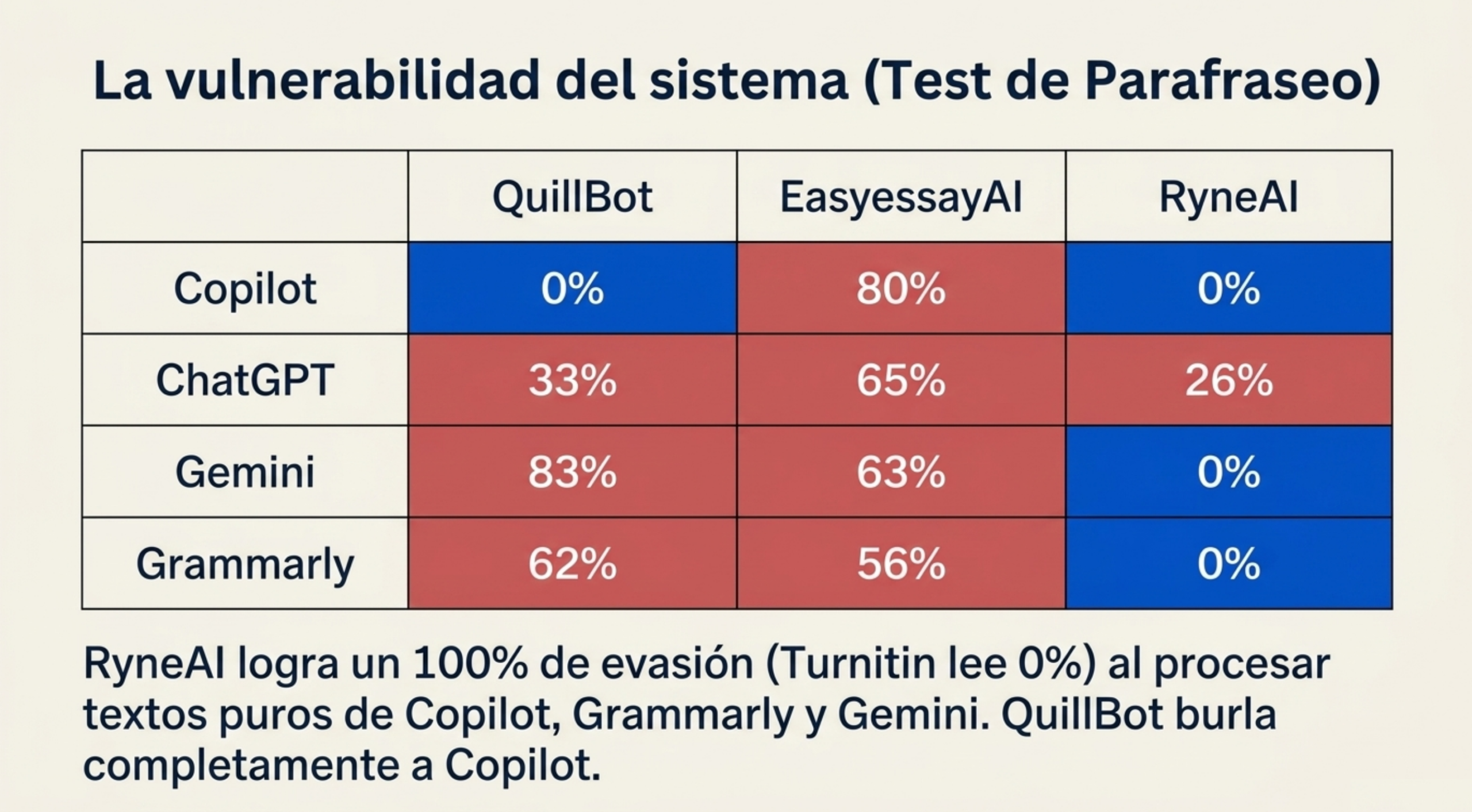
- QuillBot logró reducir a 0 % la puntuación de textos generados al 100 % por Copilot. Sin embargo, ante ChatGPT, su efectividad se redujo hasta un 33 %.
- RyneAI fue el más eficaz, logrando puntuaciones del 0 % (totalmente humano) en Copilot, Grammarly y Gemini.
No obstante, existe un matiz crítico: RyneAI falló al intentar borrar por completo el rastro de ChatGPT, que Turnitin detectó en un 26 %. Esto demuestra que Turnitin posee una «memoria» específica de los patrones de OpenAI que incluso los algoritmos de parafraseo más avanzados tienen dificultades para neutralizar por completo.
5. La confianza en el cero: el valor de la autoría auténtica.
A pesar de las inconsistencias en el volumen de detección, el estudio de Atamhenwan ofrece una base sólida para la justicia académica: Turnitin confirma con una precisión excepcional la autoría humana auténtica. En todas las pruebas con guiones escritos al 100 % por humanos, la herramienta no mostró puntuaciones atribuibles a la IA.
Esta ausencia de «falsos positivos» en textos puramente humanos es la principal fortaleza de la herramienta. Para un docente, esto simplifica el panorama: una puntuación del 0 % es una señal casi infalible de integridad. La herramienta no inventa fantasmas donde no los hay; su problema no es la calumnia, sino la precisión en la medición de la falta.
Conclusión: hacia una nueva pedagogía de la integridad.
Los datos de Atamhenwan nos obligan a adoptar una regla de oro en la evaluación: la puntuación de Turnitin no debe ser el único criterio, especialmente en el rango del 15 % al 40 %. La recomendación para el docente es clara: si el detector marca un 30 %, el uso real podría ser apenas del 15 %, pero si marca un 80 %, es muy probable que el texto sea 100 % artificial.
Dada la capacidad de los LLM para realizar cualquier tarea escrita, debemos pasar de la «detección» a la «invigilancia». La solución a corto plazo consiste en el uso de navegadores bloqueados (lockdown browsers) para evaluaciones sumativas controladas, en las que el estudiante debe demostrar su conocimiento en tiempo real. A largo plazo, se requiere una cooperación entre varios actores que permita a los educadores acceder a las fuentes originales de los contenidos detectados.
En última instancia, debemos reflexionar: en un mundo en el que la IA puede «humanizarse» con un clic, ¿deberíamos centrarnos menos en la vigilancia tecnológica y más en diseñar evaluaciones que exijan una demostración auténtica del pensamiento crítico?
En esta conversación puedes escuchar las ideas más interesantes de este artículo.
Este vídeo resume bien los aspectos más importantes tratados.
Referencia:
Atamhenwan, L.E. How are combinations of human-written words and LLM-generated words by ChatGPT, Copilot, Gemini and Grammarly detected by Turnitin?. Educ Inf Technol (2026). https://doi.org/10.1007/s10639-026-14049-2

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.