Un valor atípico (outlier, en inglés) es una observación que numéricamente es muy distinta al resto de elementos de una muestra. Estos datos nos pueden causar problemas en la interpretación de lo que ocurre en un proceso o en una población. Por ejemplo, en el cálculo de la resistencia media a compresión simple de unas probetas de hormigón, la mayoría se encuentran entre 25 y 30 MPa. ¿Qué ocurriría si, de repente, medimos una probeta con una resistencia de 60 MPa? La mediana de los datos puede ser 27 MPa, pero la resistencia media podría llegar a 45 MPa. En este caso, la mediana refleja mejor el valor central de la muestra que la media.
La pregunta que nos podemos plantear es inmediata. ¿Qué hacemos con esos valores atípicos? La opción de ignorarlos a veces no es la mejor de las soluciones posibles si pretendemos conocer qué ha pasado con estos valores. Lo bien cierto es que distorsionan los resultados del análisis, por lo que hay que identificarlos y tratarlos de forma adecuada. A veces se excluyen si son resultado de un error, pero otras veces son datos potencialmente interesantes en la detección de anomalías.
Los valores atípicos pueden deberse a errores en la recolección de datos válidos que muestran un comportamiento diferente, pero reflejan la aleatoriedad de la variable en estudio. Es decir, valores que pueden haber aparecido como parte del proceso, aunque parezcan extraños. Si los valores atípicos son parte del proceso, deben conservarse. En cambio, si ocurren por algún tipo de error (medida, codificación…), lo adecuado es su eliminación. En la Tabla 1 se recogen algunas de las causas comunes de los valores atípicos y sus acciones posibles.
Tabla 1. Causas comunes de los valores atípicos. Fuente: Soporte de Minitab(R) 18.
| Causa | Acciones posibles |
|---|---|
| Error de entrada de datos | Corregir el error y volver a analizar los datos. |
| Problema del proceso | Investigar el proceso para determinar la causa del valor atípico. |
| Factor faltante | Determinar si no se consideró un factor que afecta el proceso. |
| Probabilidad aleatoria | Investigar el proceso y el valor atípico para determinar si este se produjo en virtud de las probabilidades; realice el análisis con y sin el valor atípico para ver su impacto en los resultados. |
Los valores atípicos a veces son subjetivos y existen numerosos métodos para clasificarlos. La detección de valores atípicos se puede realizar a nivel univariante usando gráficos sencillos como histogramas o diagramas de caja y bigotes. A nivel bivariante se pueden localizar mediante análisis de diagrama de dispersión o análisis de los residuos. En el ámbito multivariante se pueden descubrir los valores atípicos mediante un análisis de la matriz de residuos.
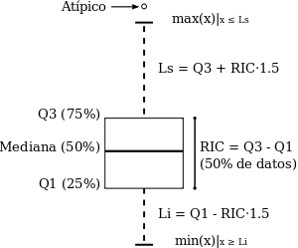
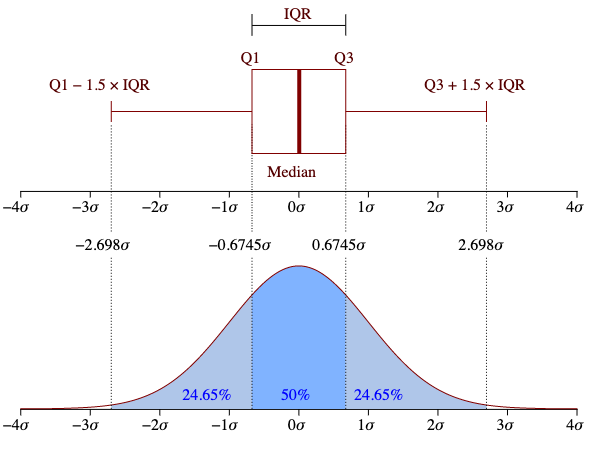
El método más habitual por su sencillez y resultados es el test de Tukey, que toma como referencia la diferencia entre el primer cuartil (Q1) y el tercer cuartil (Q3), o rango intercuartílico. En un diagrama de caja se considera un valor atípico el que se encuentra 1,5 veces esa distancia de uno de esos cuartiles (atípico leve) o a 3 veces esa distancia (atípico extremo). Se trata de un método paramétrico que supone que la población es normal (Figura 2). No obstante, también existen métodos no paramétricos cuando la muestra no supere la prueba de normalidad correspondiente.
Os dejo algún vídeo donde se explica cómo detectar los valores atípicos.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.