 Introducción: El dilema del exceso de información.
Introducción: El dilema del exceso de información.
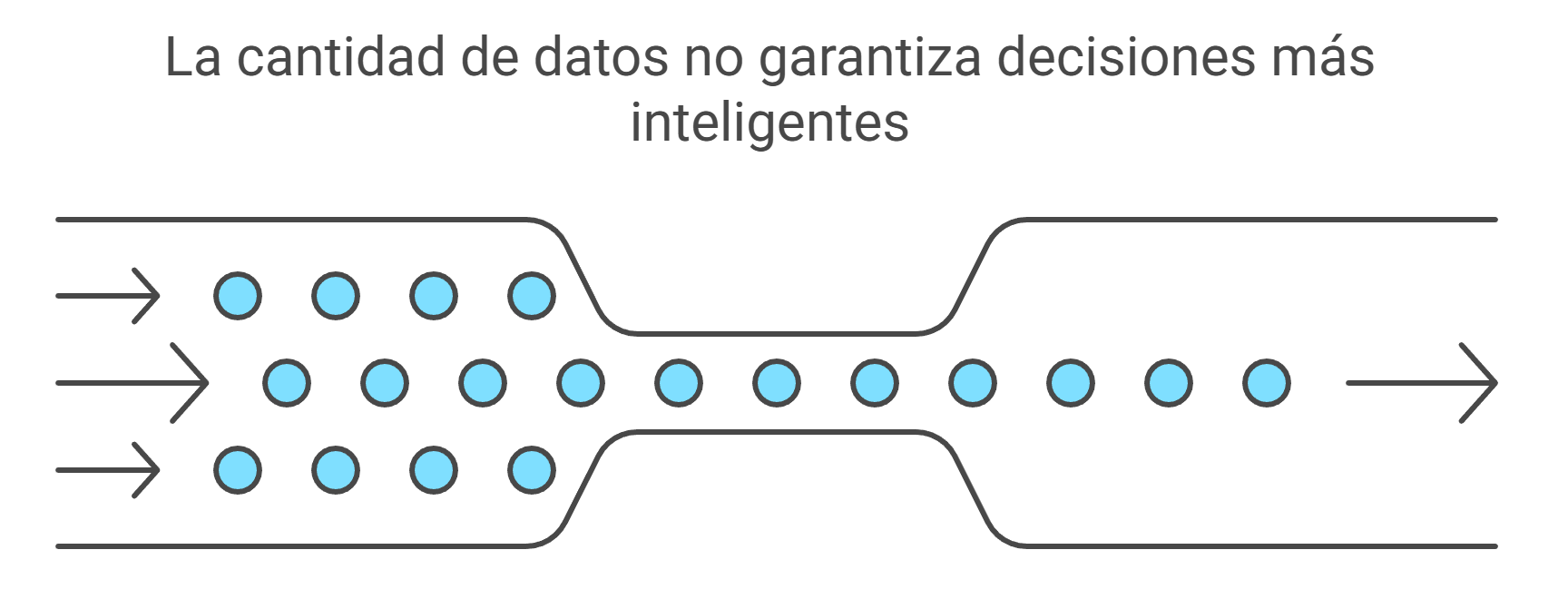
Imagine que se encuentra frente a una base de datos con cientos de columnas que detallan cada aspecto de su actividad. A primera vista, parece un tesoro, pero en la práctica, tener «demasiada» información a menudo paraliza la toma de decisiones. El ruido de los datos irrelevantes y la redundancia de variables que dicen esencialmente lo mismo ocultan las tendencias estratégicas reales.
Es aquí donde el análisis de componentes principales (PCA) resulta indispensable. Más que una técnica estadística de análisis multivariante, el PCA actúa como un «traductor inteligente» que simplifica la complejidad. Su función es transformar el caos de variables correlacionadas en un conjunto claro de factores que revelan la estructura real de su negocio.
Punto 1: Menos es más (la simplificación inteligente).
La esencia del PCA radica en la reducción de la dimensionalidad. En lugar de intentar procesar 20 variables que fluctúan juntas, esta técnica las sintetiza en un nuevo subconjunto de «factores» independientes.
Simplificar no implica pérdida de información. En el mundo del análisis de datos, simplificar significa ganar claridad. Al eliminar la redundancia, el PCA nos permite centrarnos en las fuerzas subyacentes que realmente marcan la diferencia. Como establece un principio fundamental del análisis multivariante:
«El exceso de variables dificulta el análisis de la información y genera redundancia; el PCA examina la interdependencia para reducir la dimensión a variables no observables».
Punto 2: La regla del 80 %. ¿Cuándo es «suficiente» información?
Para un estratega de datos, el rigor matemático debe equilibrarse con la utilidad práctica. ¿Cuánta información debemos conservar para que el modelo refleje fielmente la realidad? Las fuentes técnicas dictan criterios claros basados en la varianza explicada acumulada:
- El mínimo académico: en ciertos contextos, explicar el 60 % de la varianza constituye el umbral básico aceptable.
- Propósitos descriptivos: para entender las tendencias generales, suele bastar con alcanzar el 80 %.
- Análisis predictivos: si los componentes se integran en modelos de machine learning posteriores, se recomienda capturar al menos el 90 %.
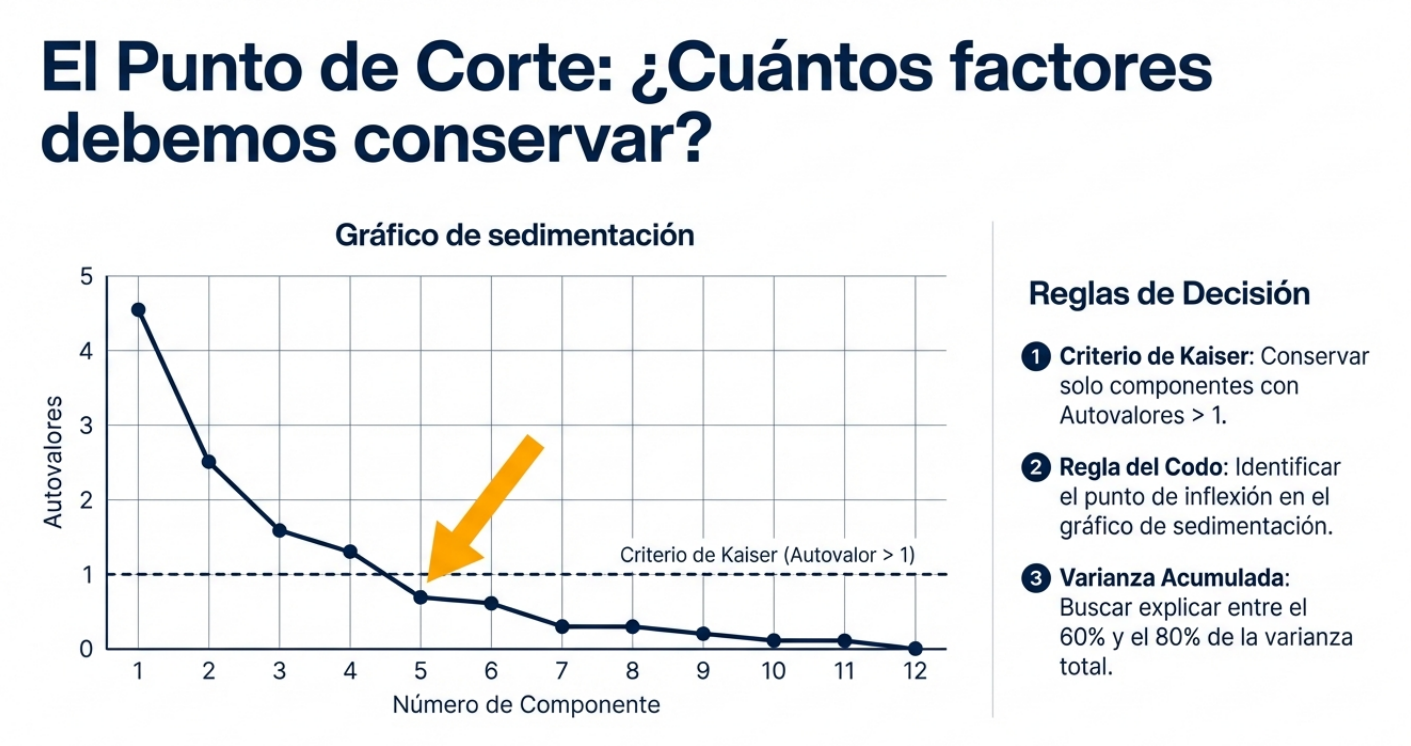
- Criterio de Kaiser: establece que, para ser eficientes, solo se deben conservar los componentes con autovalores superiores a 1. Si un componente no explica más variación que una sola variable original, se trata de ruido estratégico y debe descartarse.
Punto 3: descubriendo variables «invisibles».
El PCA puede revelar estructuras que no existen en ninguna columna específica, pero que rigen el sistema. Para descubrir estas estructuras «invisibles», primero debemos decidir matemáticamente dónde termina la señal y dónde empieza el ruido.
Veamos dos ejemplos del mundo real presentes en los materiales de análisis:
- Estabilidad financiera: al analizar variables como ingresos, educación, edad, empleo y ahorros, el PCA permite agruparlas en una dimensión principal denominada «estabilidad financiera a largo plazo». Asimismo, las deudas y las tarjetas de crédito pueden consolidarse en un factor denominado «historial crediticio».
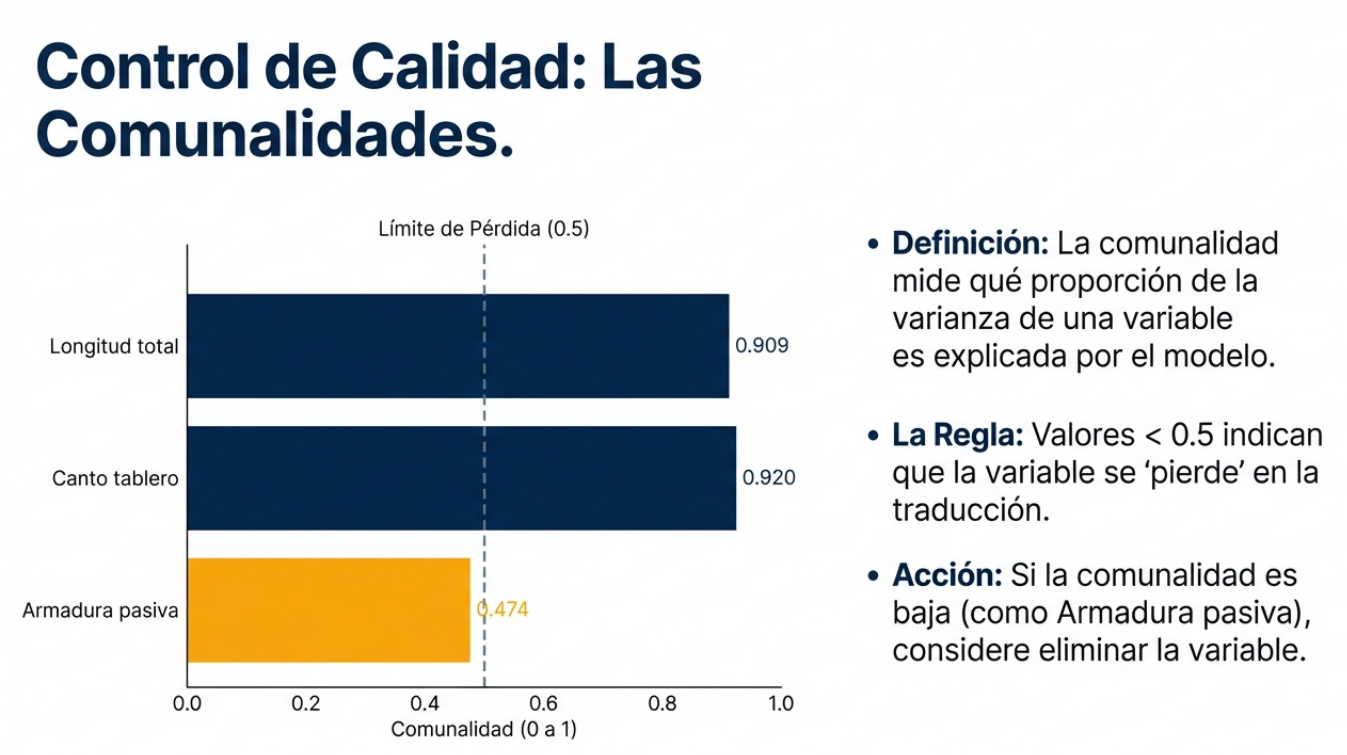
- Ingeniería de puentes: En un estudio de 61 puentes de losa, variables técnicas como la luz principal y el canto del tablero se fusionan matemáticamente para definir la «proporción geométrica» de la estructura, mientras que la armadura activa y el hormigón definen su «capacidad estructural».
El PCA nos permite dejar de ver filas de números y empezar a ver conceptos abstractos y accionables.
Punto 4: Gráfico de sedimentación. La «luz» en el camino.
Para evitar la subjetividad, el analista confía en el gráfico de sedimentación. Esta herramienta visual ordena los autovalores de mayor a menor y muestra una caída que finalmente se estabiliza.
La clave está en identificar el «punto de inflexión» o el «codo» de la gráfica. Los componentes que se encuentran en la pendiente pronunciada, antes de que la curva se transforme en una línea plana (la zona de sedimentación), son los que contienen la esencia de los datos. Este método garantiza que la reducción se base en la evidencia y no en la intuición.
Punto 5: El «giro» necesario (la potencia de la rotación).
Un resultado inicial de PCA puede ser técnicamente correcto, pero «estratégicamente inútil» si las variables originales tienen pesos similares en varios componentes. Es como mirar una imagen desenfocada.
La solución es la rotación (específicamente, el método Varimax con normalización de Kaiser). Este ajuste matemático redistribuye las cargas para que cada variable original se asocie claramente a un único factor. La rotación no altera la información, sino que «ajusta la lente» para que la interpretación de cada dimensión sea nítida, lo que permite a los interesados comprender exactamente qué significa cada componente.

Punto 6: Rigor técnico y tamaño de la muestra.
El PCA no es un acto de magia, sino que requiere cimientos sólidos. La efectividad de la técnica depende de la presencia de correlaciones significativas (superiores a 0,3) y de contar con una muestra representativa. Desde el punto de vista académico, se exige un mínimo de 5 observaciones por variable, aunque el ratio óptimo es de 10 a 1.
Además, la validez de una carga factorial depende directamente del tamaño de la muestra, como se detalla en la siguiente escala de rigor:
| Tamaño de la muestra | Carga factorial mínima requerida |
| 350 observaciones | 0,30 |
| 200 observaciones | 0,40 |
| 150 observaciones | 0,45 |
| 120 observaciones | 0,50 |
| 100 observaciones | 0,55 |
| 85 observaciones | 0,60 |
| 70 observaciones | 0,65 |
| 60 observaciones | 0,70 |
| 50 observaciones | 0,75 |
Un paso crítico final es el análisis de las comunalidades. Si una variable tiene una comunalidad inferior a 0,5, significa que el modelo no logra explicar su varianza de manera satisfactoria. En términos estratégicos, esa variable se considera «carente de explicación» y debería eliminarse para no contaminar el análisis.
Conclusión: mirando al futuro de tus datos.
El análisis de componentes principales es una pieza angular de la preparación de datos. Al eliminar el ruido, preparamos el terreno para técnicas avanzadas de aprendizaje automático, como el agrupamiento o la predicción, que funcionan con mayor agilidad sobre datos sintetizados.
En un mercado saturado de información, la ventaja competitiva pertenece a quienes logran destilar el conocimiento. ¿Cómo cambiaría su visión estratégica si pudiera reducir sus 100 indicadores de rendimiento a solo tres dimensiones maestras que realmente explicaran el éxito de su organización?

Este vídeo puede servirles para introducir las ideas más importantes.
En esta conversación puedes escuchar las ideas más interesantes sobre este tema.
El vídeo sintetiza bien lo más importante del análisis de componentes principales.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.