
Como ya habréis observado, en muchos de mis artículos os doy pistas sobre cómo utilizar determinadas herramientas que nos permiten, si sabemos utilizarlas, obtener información relevante y muchas veces no evidente de nuestras bases de datos. En esta ocasión os voy a hablar de los métodos jerárquicos de análisis cluster, y en particular, de los dendrogramas. En el contexto de la minería de datos, se consideran los algoritmos de agrupamiento (clustering), como una técnica de aprendizaje no supervisado.
Los llamados métodos jerárquicos buscan formar agrupaciones de elementos de forma sucesiva, de modo que se minimice alguna distancia o maximice alguna medida de similitud. Estos métodos se dividen, a su vez, en métodos aglomerativos -también llamados ascendentes- que comienzan con tantos grupos como individuos haya, formándose grupos de forma ascendente, de forma que al final todos los casos se engloban en un mismo aglomerado. Por contra, los métodos disociativos -descendentes- hacen lo contrario, comienzan con un conglomerado que engloba todos los casos y, con sucesivas divisiones, se forman grupos cada vez más pequeños hasta llegar a tantas agrupaciones como casos.
Un dendrograma es una representación gráfica de los datos en forma de árbol que los organiza en subcategorías que se van dividiendo hasta llegar al nivel de detalle deseado. Para formar este diagrama se forman conglomerados de observaciones en cada paso y sus niveles de similitud. El nivel de similitud se mide en el eje vertical (aunque también se puede mostrar el nivel de distancia), y las diferentes observaciones se especifican en el eje horizontal.
Veamos cómo se puede utilizar dicha herramienta. Para eso vamos a utilizar los datos recopilados de 61 puentes losa postesados aligerados (Yepes et al., 2009). Utilizamos el software Minitab para este análisis. En la Figura 2 se ha realizado un análisis para las 61 observaciones. Aunque permite determinar qué puentes son más parecidos entre sí, la verdad es que la información que nos deja es difícil de manejar.
En cambio, si realizamos el mismo análisis respecto a las variables que definen el puente y a su coste, obtenemos información relevante, tal y como se puede observar en la Figura 3. El conglomerado de variables a sí obtenido comienza con todas las variables separadas, cada una formando su propio conglomerado. En el primer paso, las dos variables más cercanas entre sí se unen. En el siguiente paso, una tercera variable se une a las primeras dos u otras dos variables se unen para formar un conglomerado diferente. Este proceso continuará hasta que todos los conglomerados se unan en un solo conglomerado. En el caso estudiado, se ha utilizado como medición de la distancia la correlación y el método de vinculación completo. De esta forma conseguimos que un conglomerado se encuentre dentro de una distancia máxima, tendiéndose a producir conglomerados con diámetros similares.
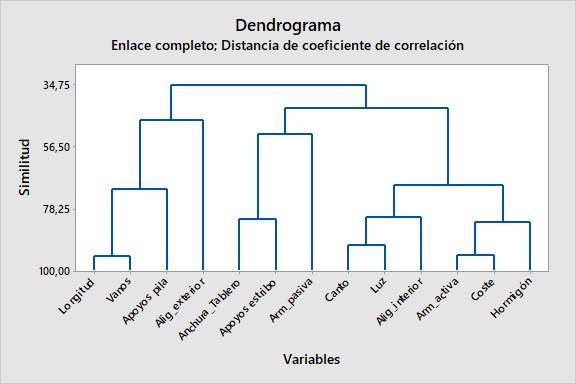
La Figura 3 ya nos permite interpretar cómo se relacionan las variables de un puente losa postesado, siendo un análisis que es coherente con los resultados obtenidos en Yepes et al. (2009). Se observa que el coste está muy relacionado con la cuantía de armadura activa, y también, con la cuantía de hormigón empleado. También se observa la estrecha relación entre el canto y la luz del puente, que junto con la cuantía del aligeramiento interior, se aglomeran a otro nivel para configurar el coste. Otras relaciones son evidentes, como que la longitud total del puente y el número de vanos son magnitudes muy relacionadas, o cómo la anchura del tablero se relaciona con el número de apoyos existentes en el estribo.
Referencias:
YEPES, V.; DÍAZ, J.; GONZÁLEZ-VIDOSA, F.; ALCALÁ, J. (2009). Statistical Characterization of Prestressed Concrete Road Bridge Decks. Revista de la Construcción, 8(2):95-109.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.