 ¿Cómo podemos determinar la intención de voto de toda una nación o evaluar la eficacia de un nuevo fármaco sin entrevistar a todos los ciudadanos ni tratar a todos los pacientes del planeta? En nuestra vida cotidiana, nos enfrentamos constantemente al reto de tomar decisiones globales basadas en información limitada. Medir el total de elementos suele ser física o económicamente inviable.
¿Cómo podemos determinar la intención de voto de toda una nación o evaluar la eficacia de un nuevo fármaco sin entrevistar a todos los ciudadanos ni tratar a todos los pacientes del planeta? En nuestra vida cotidiana, nos enfrentamos constantemente al reto de tomar decisiones globales basadas en información limitada. Medir el total de elementos suele ser física o económicamente inviable.
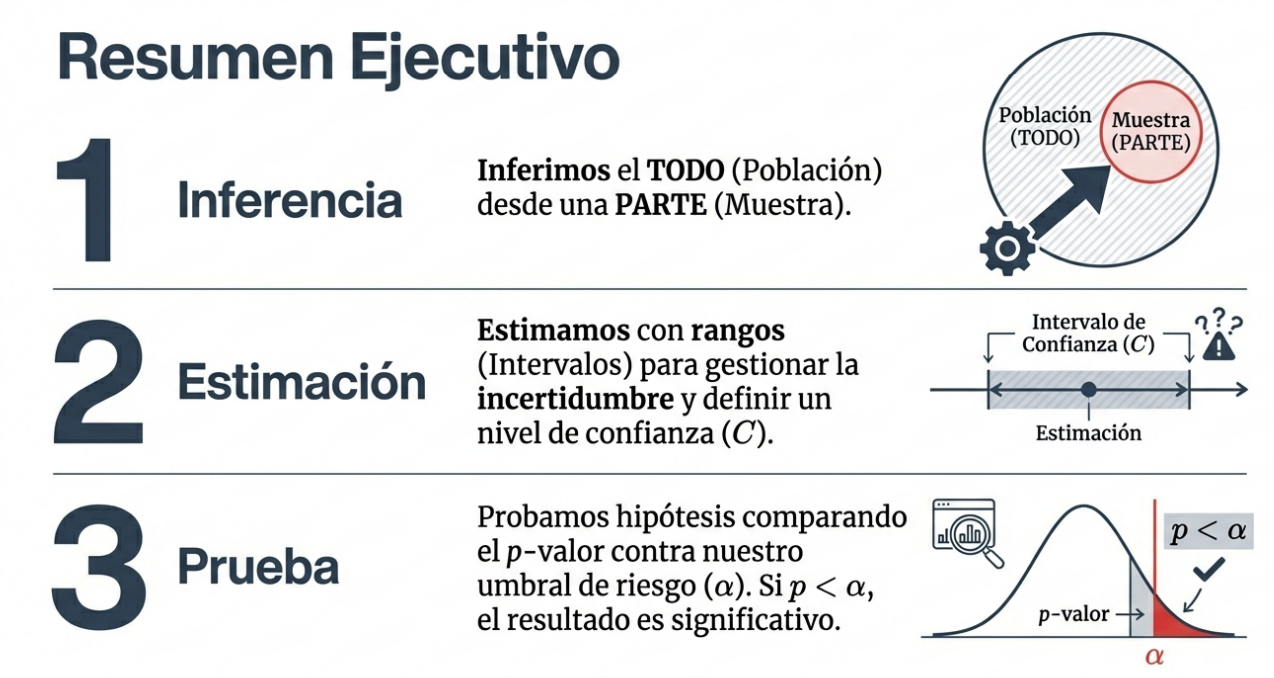
Como expertos en comunicación de datos, consideramos la inferencia estadística como el puente intelectual definitivo. Es la disciplina que nos permite pasar de lo que vemos —una pequeña muestra— a la realidad oculta de la población total. En esencia, es la herramienta científica que transforma la observación de unos pocos en el conocimiento preciso de la mayoría.
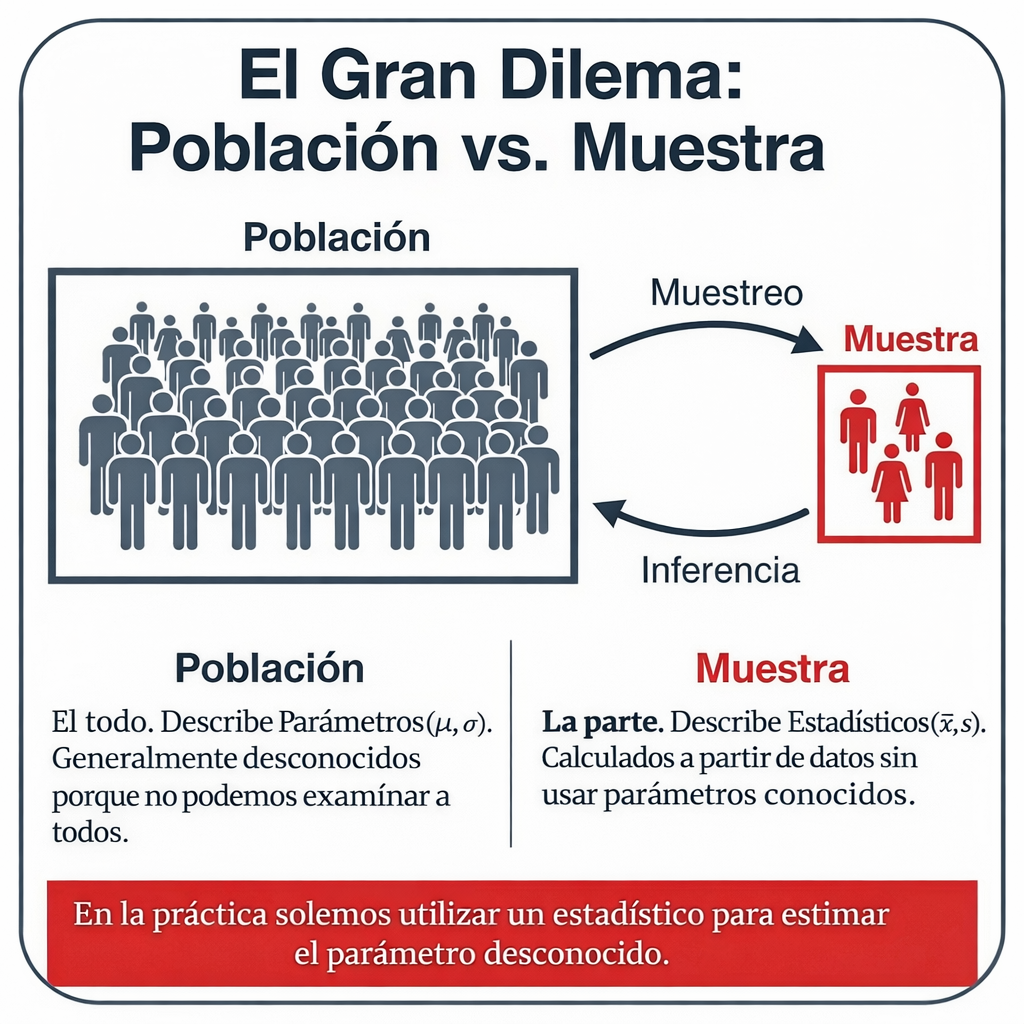
Población frente a muestra: la ventana hacia la verdad
Para descifrar la realidad, primero debemos distinguir entre los dos protagonistas del análisis: la población y la muestra. La población es el conjunto total que deseamos estudiar y la muestra es un subconjunto extraído de forma aleatoria que nos sirve de ventana para observar la población.
En este proceso, manejamos conceptos que debemos diferenciar con rigor:
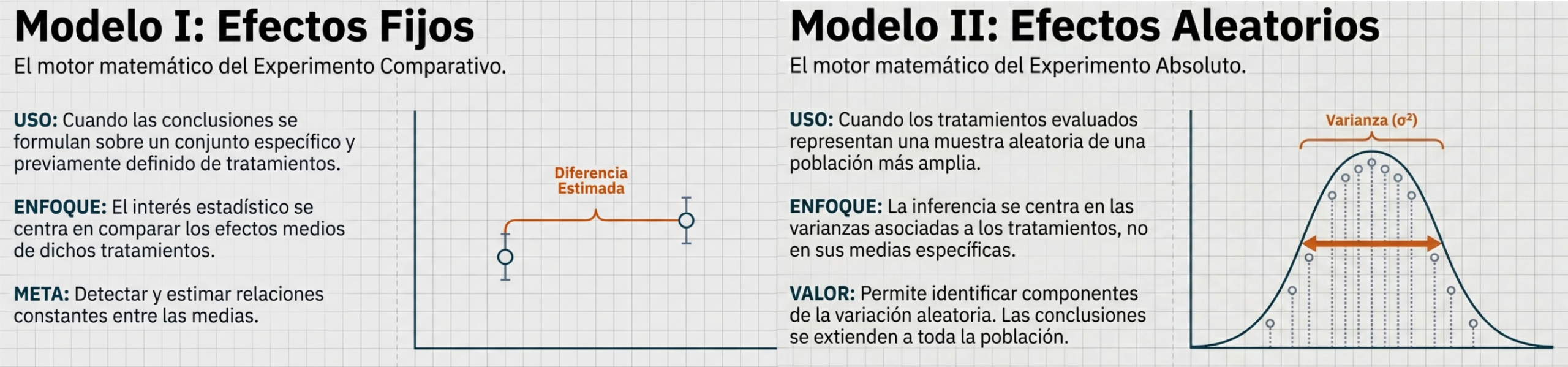
- Parámetro: Es el número «secreto» que describe la población. En la práctica, su valor es desconocido porque no podemos examinar a cada individuo. Usamos símbolos como la media poblacional (μ), la desviación típica (σ), la varianza (σ²) o el porcentaje o la proporción poblacional (p).
- Estadístico: Es el número que calculamos directamente a partir de los datos muestrales. En este ámbito operamos con la media muestral, la desviación típica muestral, la varianza o la proporción muestral.
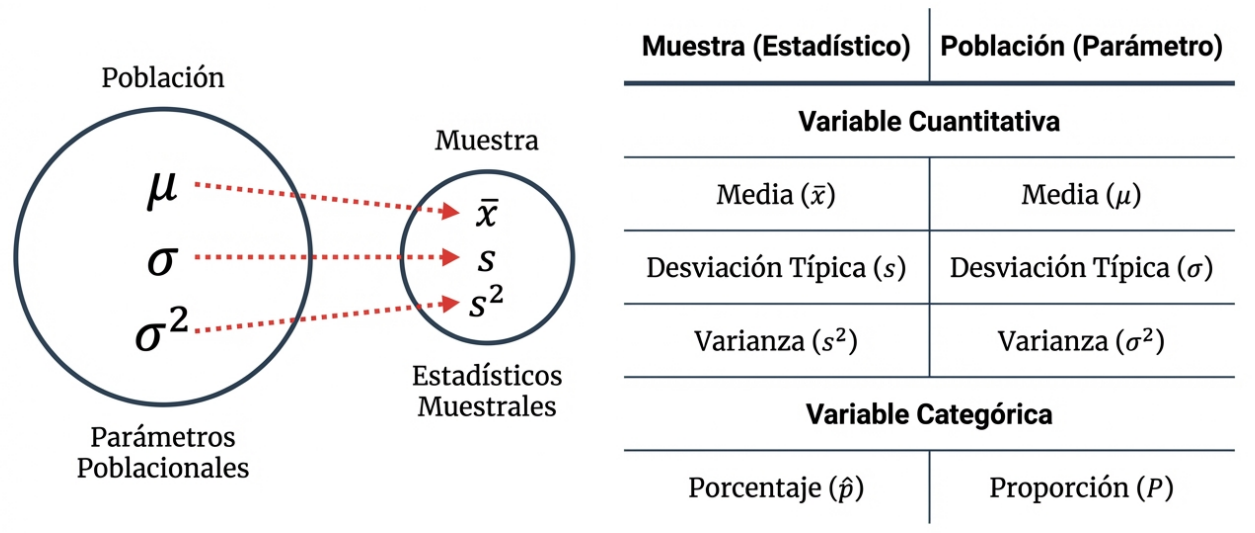
Dado que no podemos conocer el parámetro real, nos vemos obligados a operar en el mundo de los estadísticos para realizar estimaciones. El objetivo es claro:
«Extraer conclusiones sobre una población a partir de los datos de una muestra».
El intervalo de confianza: ¿qué tan cerca estamos de la realidad?
Dado que trabajar con muestras implica un error aleatorio inevitable, la estadística no ofrece un único número como verdad absoluta. En su lugar, construimos un intervalo de confianza de nivel C.
Conceptualmente, este rango se define mediante una estructura lógica: estimación ± error de la estimación.
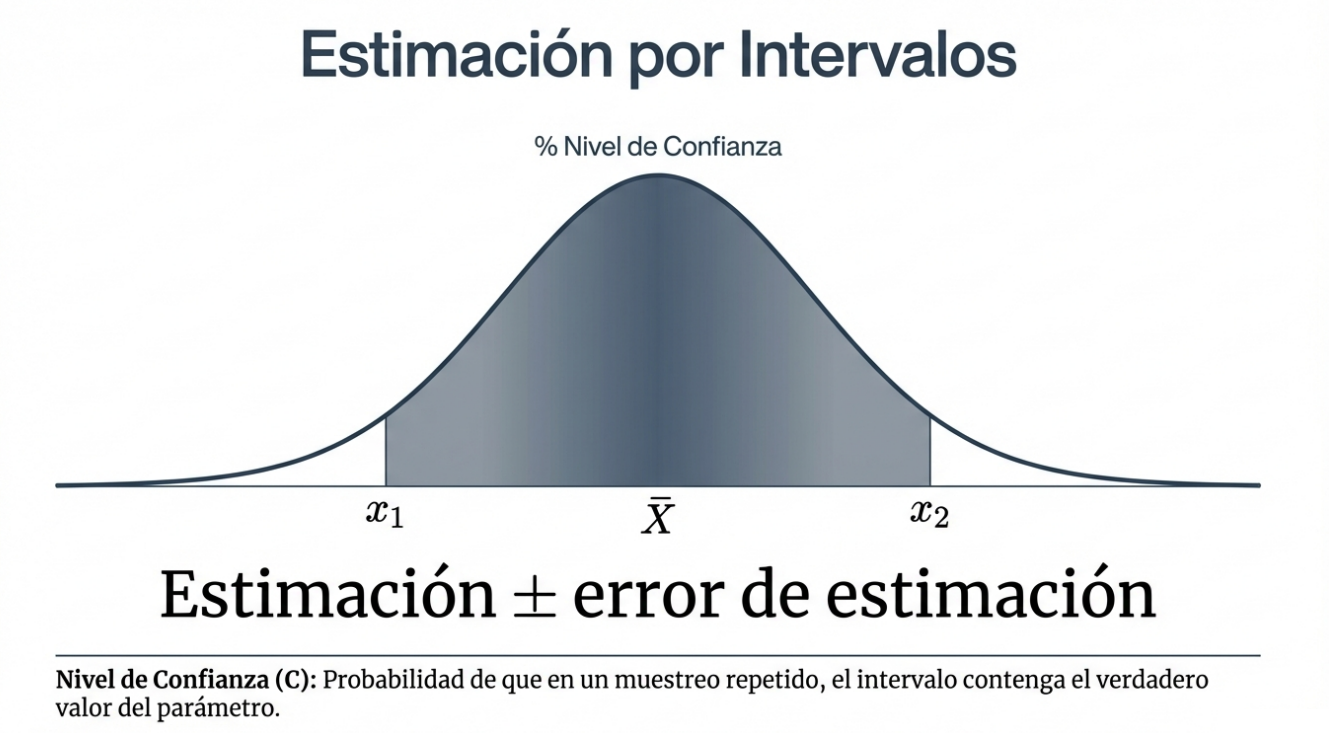
No proporcionamos un único valor porque, en la práctica, el parámetro no se conoce. Por ello, el nivel de confianza C no es solo un porcentaje, sino la respuesta a una pregunta vital sobre la fiabilidad de nuestro trabajo: «¿Con qué frecuencia daría una respuesta correcta este método si lo utilizara muchas veces?». Si afirmamos que tenemos un 95 % de confianza, estamos diciendo que, si repitiéramos el muestreo el 95 % de las veces, nuestro intervalo contendría el verdadero valor del parámetro.
Inocente hasta que se demuestre lo contrario: la hipótesis nula (H0)
Como expertos, empleamos el contraste de hipótesis para evaluar si la evidencia de la muestra es suficiente para inferir una condición en toda la población. Este mecanismo examina dos afirmaciones opuestas:
La hipótesis nula (H0) representa el estado «habitual» o lo que cabría esperar si no hubiera cambios. Es una afirmación de «ausencia de efecto» o de «no diferencia». Algunos ejemplos críticos de H₀ son:
- El acusado no es culpable (es inocente).
- No hay embarazo.
- No hay presencia de cáncer.
Para decidir si rechazamos la hipótesis nula, calculamos el p-valor (o significación muestral). A diferencia de lo que se cree popularmente, el p-valor no es un corte arbitrario, sino la probabilidad de obtener nuestros resultados si la hipótesis nula fuera cierta. Comparamos este p-valor con el nivel de significación (α), que es el límite preestablecido. Si p ≤ α, la evidencia es tan fuerte que rechazamos la situación «habitual» en favor de la hipótesis alternativa.
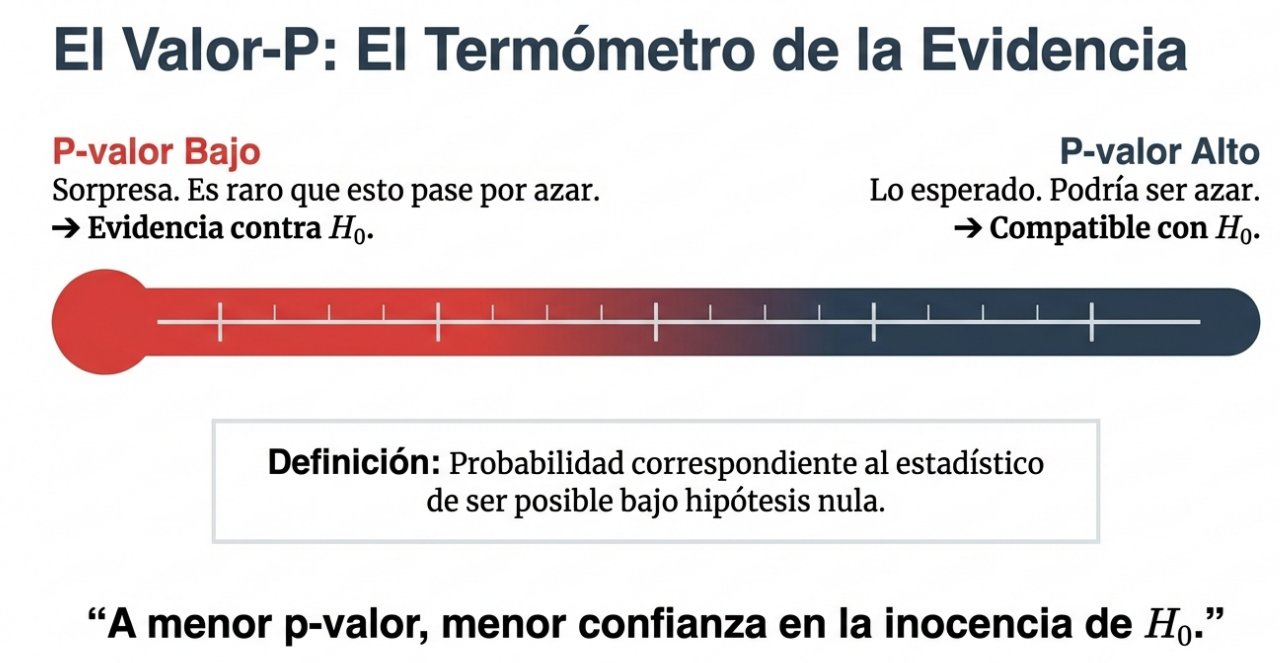
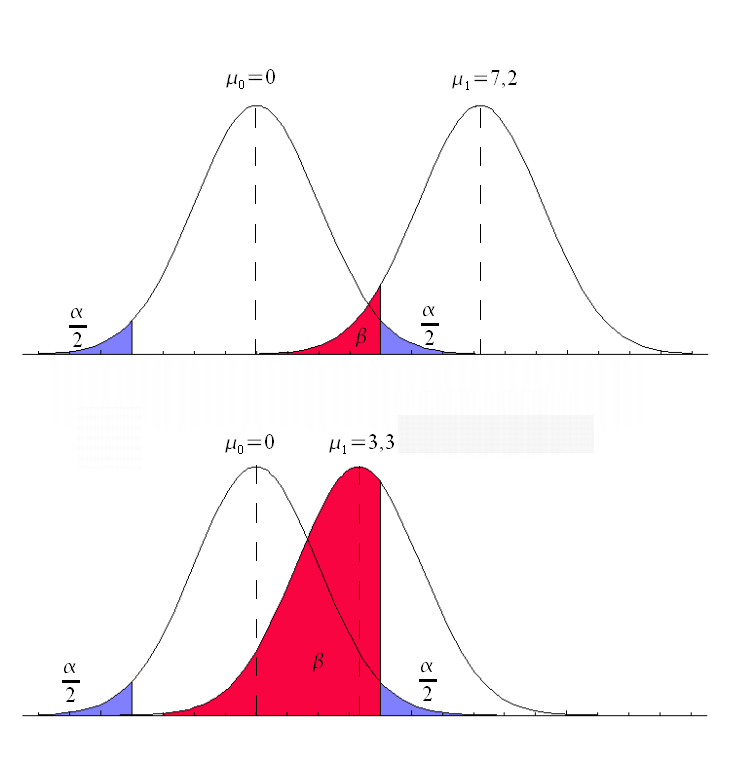
El dilema del error: falsos positivos y falsos negativos
En cualquier prueba estadística, asumimos el riesgo de tomar una decisión equivocada. Estos errores se dividen en dos categorías fundamentales:
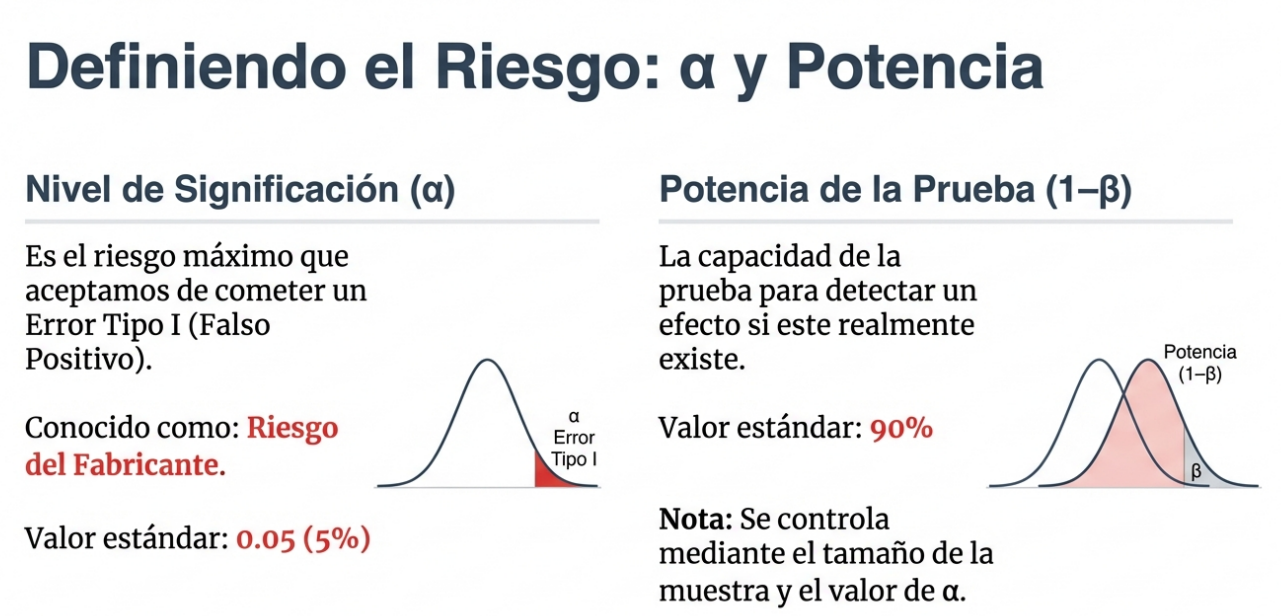
- Error tipo I (α): el «falso positivo» o riesgo del fabricante. Ocurre cuando rechazamos la hipótesis nula cuando esta es verdadera (por ejemplo, operar a una persona sana o condenar a un inocente).
- Error tipo II (β): el «falso negativo». Sucede cuando aceptamos la hipótesis nula cuando es falsa (por ejemplo, declarar inocente a un asesino o no detectar una enfermedad).
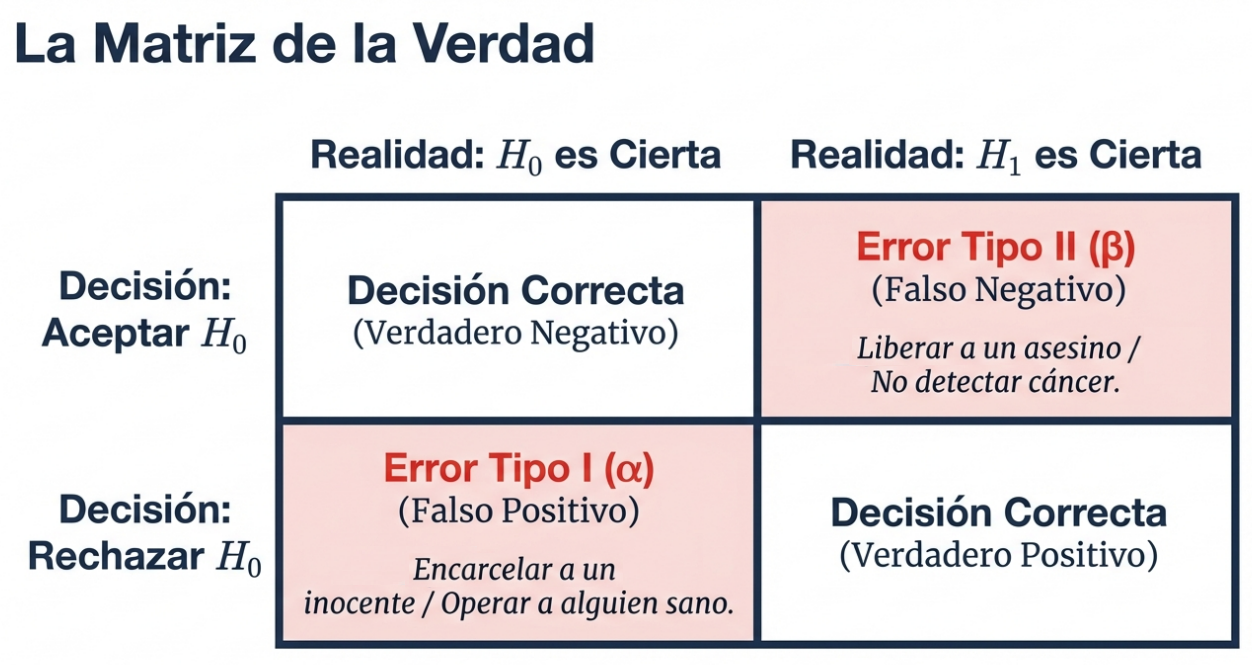
Para minimizar estos riesgos, no solo tenemos en cuenta el nivel de significación (típicamente fijado en el 5 %), sino que también buscamos maximizar la potencia de la prueba (1 – β). Esta potencia representa nuestra capacidad para detectar un efecto cuando realmente existe y depende directamente del tamaño de la muestra y del nivel de significación. Decimos que un resultado tiene significación estadística cuando es tan improbable que no puede atribuirse razonablemente al azar (p ≤ α).
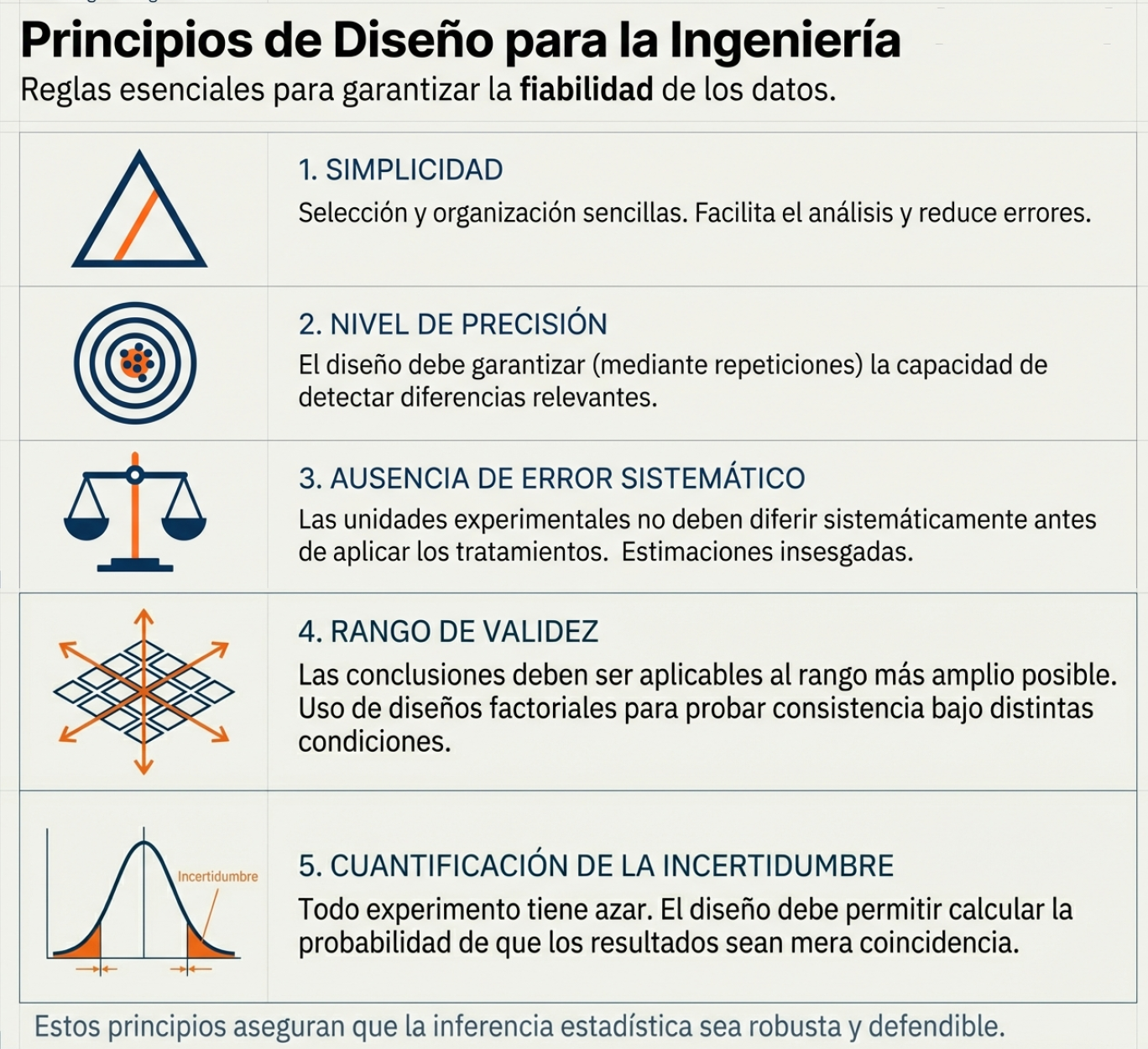
Propiedades del buen estimador
Para que nuestras conclusiones sean robustas, los métodos que utilizamos deben poseer cuatro pilares técnicos extraídos de la teoría de la probabilidad:
- Sesgo: el estimador debe carecer de desviaciones sistemáticas; su media debe coincidir con el parámetro real.
- Eficiencia: buscamos la menor variabilidad posible en los resultados.
- Convergencia y consistencia: estas propiedades garantizan la fiabilidad del método a largo plazo.
La lógica matemática que hay detrás de la eficiencia es poderosa: si aumenta el tamaño de la muestra, disminuye la varianza del estimador. Esta es la razón técnica por la que una encuesta con miles de personas es más «eficiente» y nos acerca más a la verdad que una consulta informal: al reducir la varianza, estrechamos el margen de error y ganamos precisión.
Conclusión: una mirada al futuro de las decisiones
La inferencia estadística es la ciencia que se ocupa de gestionar la incertidumbre para alcanzar la precisión. Nos enseña que, si bien es imposible tener certeza absoluta sobre una población masiva, el rigor matemático nos permite actuar con una seguridad asombrosa.
Aceptar que nuestras conclusiones conviven con un nivel de confianza y un riesgo de error no debilita el conocimiento, sino que lo fortalece al hacerlo verificable y científico. La próxima vez que lea el titular de una encuesta electoral o el estudio de un nuevo tratamiento, no se quede en la superficie. Pregúntese: ¿cuál es el margen de error?, ¿es el p-valor realmente significativo? Si posee estas cinco claves, pasará de ser un consumidor pasivo de datos a ser un pensador crítico capaz de ver lo invisible.
En esta conversación puedes escuchar las ideas más interesantes sobre inferencia estadística.
El vídeo resume bien los conceptos más importantes de este tema.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.