Los modelos de ecuaciones estructurales (SEM, por sus siglas en inglés) son una técnica estadística multivariante utilizada para analizar y estimar relaciones causales, combinando datos estadísticos con suposiciones cualitativas sobre la causalidad. Esta metodología es especialmente valiosa en las ciencias sociales, la psicología, el marketing y otras disciplinas en las que las relaciones entre variables no son lineales y pueden involucrar tanto variables observables como latentes. Gracias a los SEM, los investigadores no solo pueden comprobar teorías existentes, sino también desarrollar nuevas hipótesis y modelos que reflejen la realidad de los fenómenos estudiados.
Los modelos de ecuaciones estructurales (MES) combinan el análisis factorial y la regresión lineal para evaluar la correspondencia entre los datos observados y el modelo hipotetizado, que se representa mediante un diagrama de senderos. Los MES proporcionan los valores asociados a cada relación del modelo y un estadístico que mide el ajuste de los datos y valida el modelo.
Una de sus principales fortalezas es la capacidad de construir variables latentes, es decir, variables no observables directamente, sino estimadas a partir de otras que covarían entre sí. Esto permite tener en cuenta explícitamente la fiabilidad del modelo. Además, el análisis factorial, el análisis de caminos y la regresión lineal son casos particulares dentro del enfoque de los MES.
Fundamentos teóricos
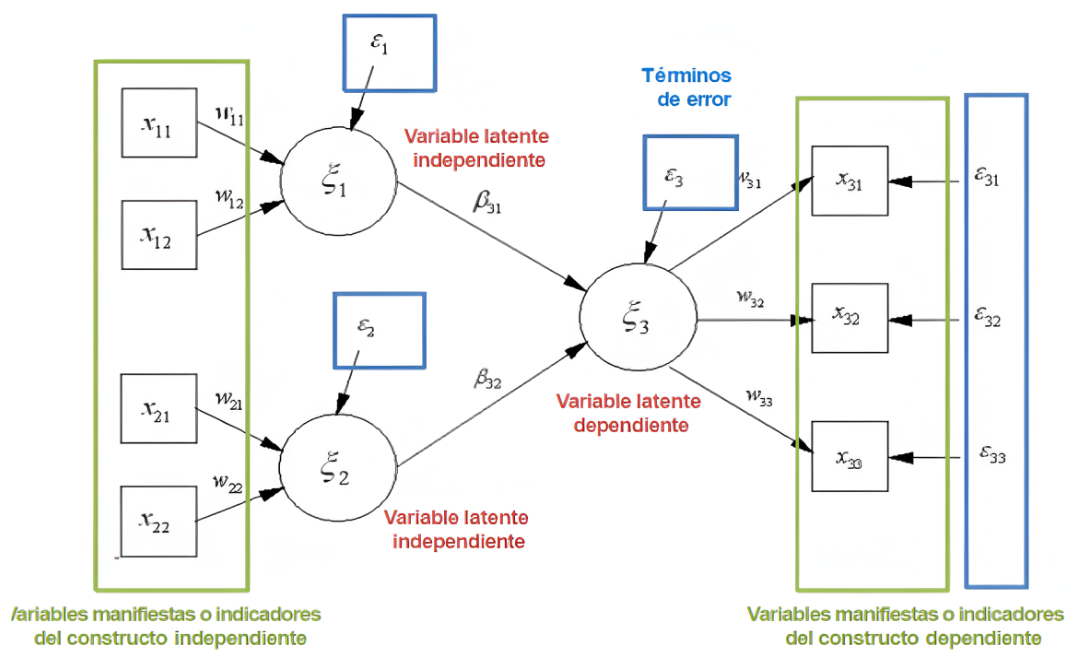
Variables latentes y observables:
- Variables latentes: son constructos teóricos que no pueden medirse directamente. Por ejemplo, la «satisfacción del cliente» o «lealtad a la marca» son variables latentes que se infieren a partir de las respuestas a encuestas o del comportamiento observable.
- Variables observables: son los indicadores que se utilizan para medir las variables latentes. Por ejemplo, en el caso de la satisfacción del cliente, las respuestas a preguntas específicas en una encuesta (como «¿Qué tan satisfecho está con nuestro servicio?»), son variables observables.
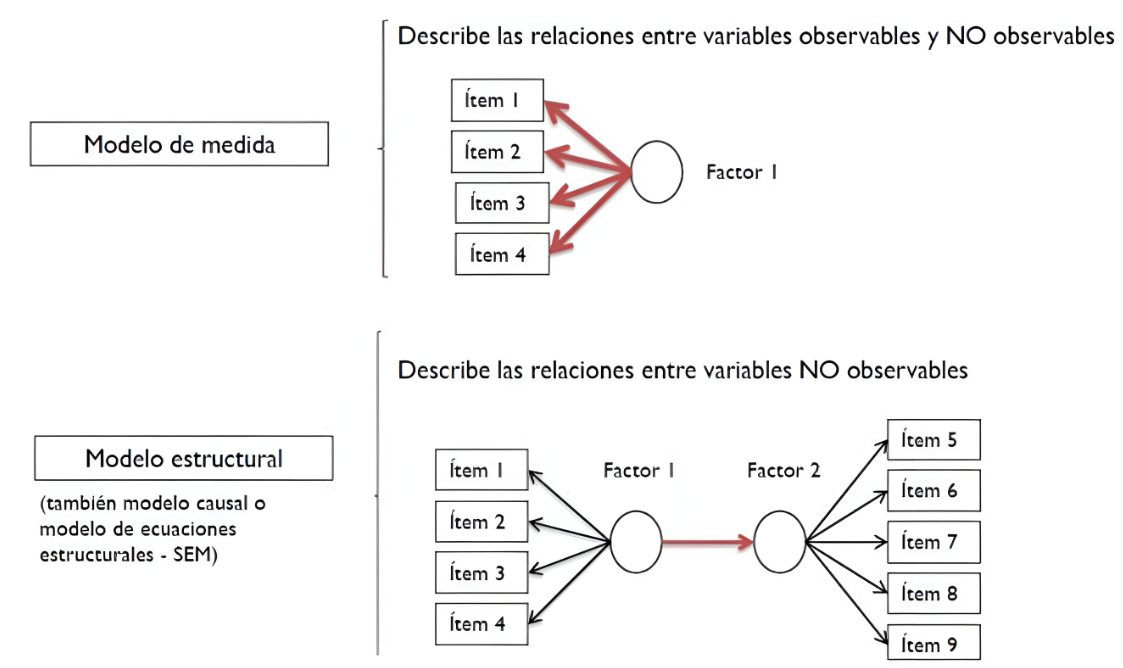
Modelo estructural vs. modelo de medida:
- Modelo estructural: describe las relaciones causales entre las variables latentes. Este modelo permite a los investigadores establecer hipótesis sobre cómo una variable puede influir en otra.
- Modelo de medida: establece cómo se relacionan las variables observables con las variables latentes. Es fundamental validar este modelo para garantizar que los indicadores reflejan realmente el constructo que se pretende medir.
Tipos de modelos
Existen dos enfoques principales en SEM:
Análisis de estructuras de covarianza (CB-SEM):
- Este enfoque se basa en la matriz de varianza-covarianza y es adecuado para contrastar teorías y probar hipótesis. CB-SEM es una técnica paramétrica que requiere que se cumplan ciertos supuestos estadísticos, como la normalidad multivariada y la independencia de las observaciones.
- Aplicaciones: Ideal para estudios confirmatorios donde se busca validar teorías existentes. Se utiliza comúnmente en investigaciones que requieren un alto nivel de rigor estadístico.
Mínimos cuadrados parciales (PLS-SEM):
- Este enfoque es más flexible y no requiere los mismos supuestos rigurosos que CB-SEM. PLS-SEM se centra en maximizar la varianza explicada de las variables latentes dependientes a partir de las variables latentes independientes.
- Ventajas: Funciona bien con muestras pequeñas y permite la inclusión de constructos formativos, lo que amplía su aplicabilidad en contextos donde los constructos son complejos y multidimensionales.
- Aplicaciones: Es especialmente útil en estudios exploratorios y en situaciones donde se busca hacer predicciones, como en el análisis de comportamiento del consumidor.
Metodología de PLS-SEM
La metodología de PLS-SEM se puede resumir en varias etapas clave:
- Inicialización: Se obtiene una primera aproximación a los valores de las variables latentes a partir de sus indicadores. Este paso es crucial para establecer un punto de partida en el proceso de estimación.
- Estimación de coeficientes de regresión: Se estiman los pesos o coeficientes de regresión de las variables latentes. Este proceso implica calcular las relaciones entre las variables latentes y sus indicadores, así como entre las variables latentes mismas.
- Optimización: Se busca maximizar el coeficiente de determinación (R²) de los factores latentes mediante un proceso iterativo. Este proceso de optimización es fundamental para mejorar la precisión de las estimaciones y asegurar que el modelo se ajuste adecuadamente a los datos.
- Evaluación de la validez y fiabilidad: Se analizan los constructos para asegurar que miden correctamente lo que se pretende medir. Esto incluye:
—Fiabilidad individual: Evaluación de la consistencia interna de cada indicador utilizando el alfa de Cronbach.
—Validez convergente: Medida a través de la varianza extraída (AVE), que debe ser superior a 0,5 para indicar que los indicadores reflejan el mismo constructo.
—Validez discriminante: Comparación de las correlaciones entre constructos para asegurar que cada constructo es significativamente diferente de los demás. Esto se puede evaluar utilizando el criterio de Fornell-Larcker, que establece que la raíz cuadrada del AVE de cada constructo debe ser mayor que las correlaciones entre constructos.
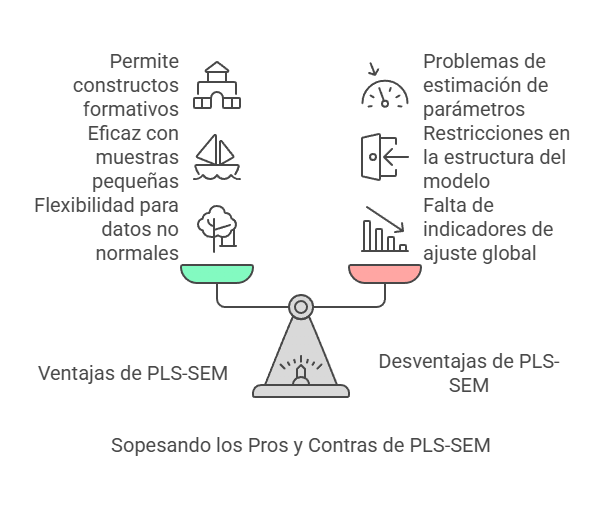
Ventajas y desventajas de PLS-SEM
Ventajas:
- Flexibilidad: PLS-SEM no requiere normalidad multivariada, lo que lo hace más accesible para investigadores en ciencias sociales que trabajan con datos no normales.
- Muestras pequeñas: Funciona bien con muestras pequeñas, lo que es ventajoso en estudios exploratorios donde la recolección de datos puede ser limitada.
- Constructos formativos: Permite la inclusión de constructos formativos, lo que amplía su aplicabilidad en contextos donde los constructos son complejos y multidimensionales.
Desventajas:
- Falta de indicadores de ajuste global: PLS-SEM no proporciona indicadores de ajuste global del modelo, lo que puede limitar la comparación entre modelos y la evaluación de su calidad.
- Restricciones en la estructura del modelo: Cada variable latente debe estar conectada a otra mediante una relación estructural, lo que puede ser restrictivo en algunos contextos.
- Estimaciones no óptimas: La estimación de parámetros no es óptima en términos de sesgo y consistencia a menos que se utilice el algoritmo PLS consistente, lo que puede afectar la validez de los resultados.
Presentación de resultados
Al presentar los resultados de un análisis SEM, se recomienda estructurarlos en tablas que resuman la fiabilidad y validez del instrumento de medida, así como los análisis de validez discriminante y las hipótesis contrastadas. Así se facilita la comprensión y la interpretación de los resultados por parte de otros investigadores y lectores. La presentación clara y concisa de los resultados es esencial para garantizar la reproducibilidad y la transparencia de la investigación.
Tablas recomendadas:
- Tabla de fiabilidad y validez: Resumen de los índices de fiabilidad (alfa de Cronbach, fiabilidad compuesta) y validez (AVE).
- Tabla de validez discriminante: Comparación de las correlaciones entre constructos y sus AVE.
- Tabla de resultados estructurales: Coeficientes de regresión, R² y significancia de las relaciones estructurales.
Conclusión
Los modelos de ecuaciones estructurales son una herramienta muy valiosa en la investigación social y del comportamiento, ya que permiten a los investigadores modelar y analizar relaciones complejas entre variables. La elección entre CB-SEM y PLS-SEM dependerá de los objetivos de la investigación, la naturaleza de los datos y las hipótesis planteadas. Con una correcta aplicación y validación, SEM puede proporcionar información significativa y fiable en diversas áreas de estudio, contribuyendo al avance del conocimiento en múltiples disciplinas. Para cualquier investigador que busque explorar las complejidades de las relaciones entre variables en su campo de estudio, es esencial comprender profundamente esta metodología y aplicarla correctamente.
Referencias:
Aldás, J. (2018). Modelización estructural mediante Partial Least Squares-PLSPM. Apuntes del seminario de modelización estructural.
Bagozzi, R. P., & Yi, Y. (1988). On the evaluation of structural equation models. Journal of the Academy of Marketing Science, 16(1), 74–94.
Fornell, C., & Bookstein, F. L. (1982). Two structural equation models: LISREL and PLS applied to consumer exit-voice theory. Journal of Marketing Research, 19(4), 440–452.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2014). A primer on partial least square structural equation modeling (PLS-SEM). California, United States: Sage.
López, S., & Yepes, V. (2024). Visualizing the future of knowledge sharing in SMEs in the construction industry: A VOS-viewer analysis of emerging trends and best practices. Advances in Civil Engineering, 2024, 6657677.
Yepes, V., & López, S. (2023). The knowledge sharing capability in innovative behavior: A SEM approach from graduate students’ insights. International Journal of Environmental Research and Public Health, 20(2), 1284.
Os dejo a continuación un artículo explicativo al respecto. Espero que os sea de interés.
Pincha aquí para descargar
También os pueden ser útiles algunos vídeos al respecto.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.