 El cerebro biológico representa la cúspide de la eficiencia evolutiva. Es un sistema capaz de procesar información con ruido, manejar datos inconsistentes y, lo más sorprendente, mantener su integridad operativa a pesar de la pérdida constante de unidades individuales.
El cerebro biológico representa la cúspide de la eficiencia evolutiva. Es un sistema capaz de procesar información con ruido, manejar datos inconsistentes y, lo más sorprendente, mantener su integridad operativa a pesar de la pérdida constante de unidades individuales.
En el auge de la inteligencia artificial moderna, las Redes Neuronales Artificiales (ANN) no surgen como meras calculadoras, sino como un espejo de silicio que busca replicar esa genialidad orgánica.
Estas redes no se basan en una programación rígida de causa-efecto, sino que «aprenden» a través de la experiencia y la reconfiguración de sus estados, transformando problemas abstractos en soluciones tangibles.
En otros artículos de este blog ya hemos hablado de este tema:
¿Qué es y para qué sirve una red neuronal artificial?
Redes neuronales aplicadas al diseño multiobjetivo de puentes postesados
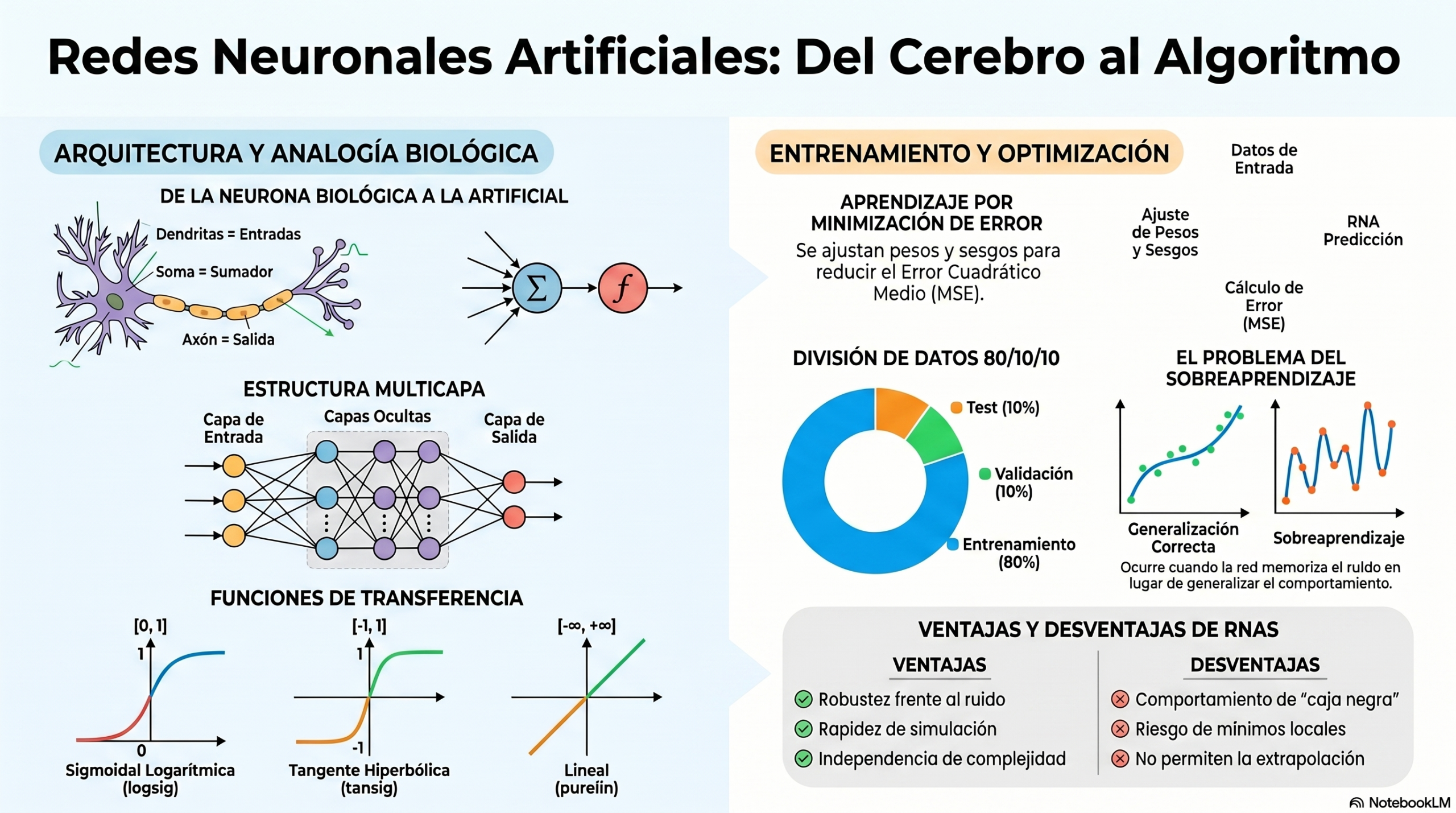
La Paradoja de la velocidad: neuronas biológicas frente a circuitos de silicio
Existe una disparidad fascinante entre el hardware biológico y el artificial. Una neurona biológica es intrínsecamente lenta, operando en una escala de milisegundos (10-3 s). En contraste, los circuitos eléctricos de silicio son un millón de veces más veloces, alcanzando los nanosegundos (10-9 s). Sin embargo, el cerebro humano aventaja a la máquina mediante un procesamiento masivamente paralelo, orquestado por aproximadamente 1011 neuronas y una red de 10.000 conexiones por cada una de ellas.
Para que las redes artificiales alcancen una efectividad real en la aproximación de funciones complejas, deben adoptar esta arquitectura paralela. Como especialistas, valoramos una lección fundamental de la biología: la robustez ante el fallo. En la naturaleza, «el cerebro es robusto; pueden morir neuronas sin que el rendimiento global se vea afectado«. Las redes artificiales aspiran a esta misma resiliencia, en la que la inteligencia no depende de un solo nodo, sino de la colectividad.
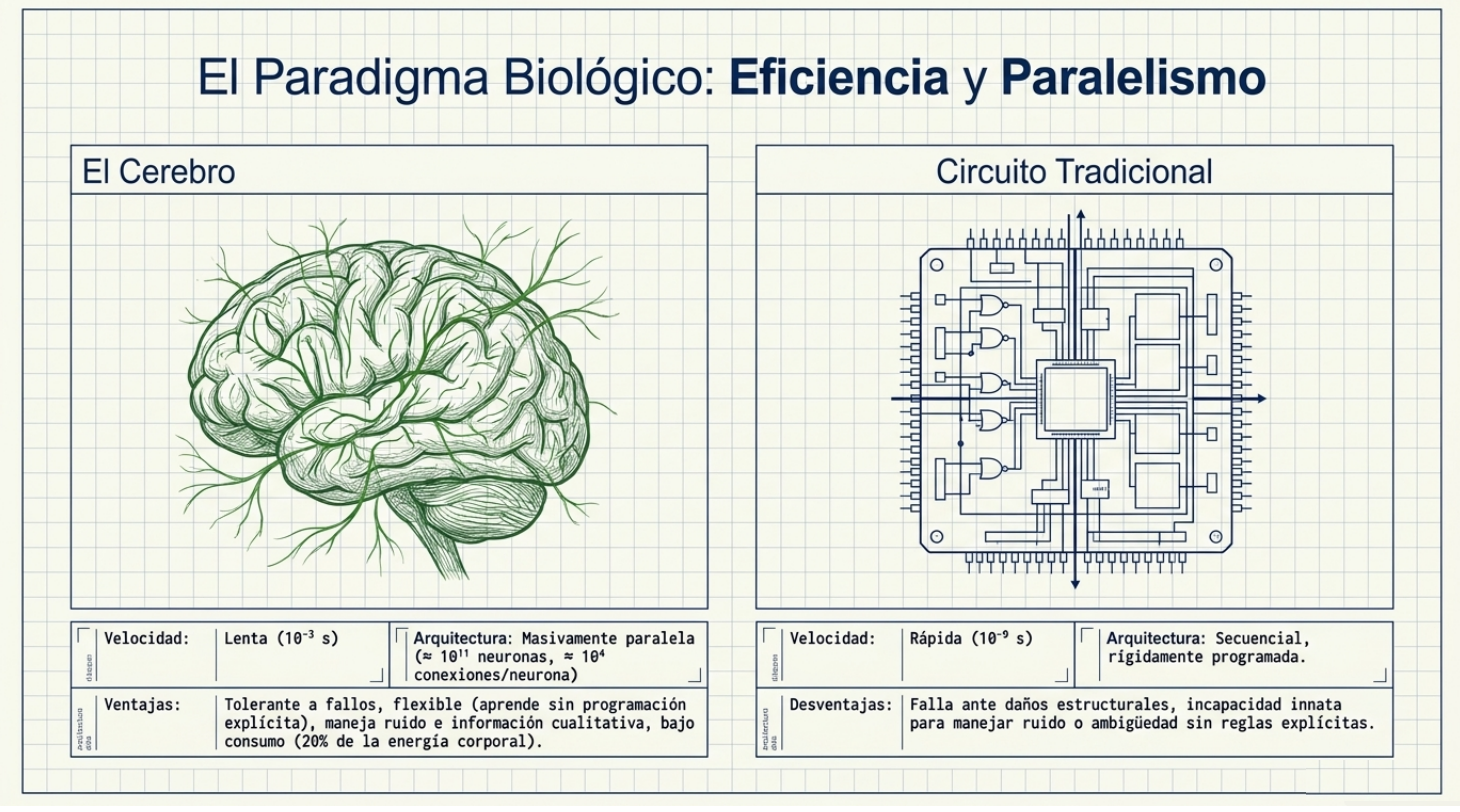
El conocimiento es un estado, no un lugar
En la computación tradicional, la información se almacena en una dirección de memoria específica, como un libro en un estante. En una red neuronal, el conocimiento es un concepto etéreo que reside en la interacción concertada entre sus componentes. No existe un lugar físico para un «dato»; el aprendizaje está codificado en la arquitectura y en la fuerza de las conexiones.
Este sistema se inspira en tres componentes fundamentales que definen el flujo de información:
- Dendritas (receptores): Fibras nerviosas que actúan como canales de entrada, captando señales de neuronas adyacentes para cargar el soma con un potencial eléctrico.
- Soma (procesador): El núcleo celular que integra y suma todas las señales recibidas. En IA, esto se traduce en multiplicadores (pesos) y en sumadores.
- Axón (transmisor): Una fibra cuya longitud varía de milímetros a varios metros, encargada de conducir el impulso si se supera un umbral de activación.
Un detalle técnico que suele pasar desapercibido es que la longitud de la sinapsis —el punto de contacto entre neuronas— está determinada por la complejidad del proceso químico que asegura la función de la red. En la IA, emulamos esto ajustando los «pesos» para fortalecer o inhibir señales, lo que permite que el sistema se autoorganice.
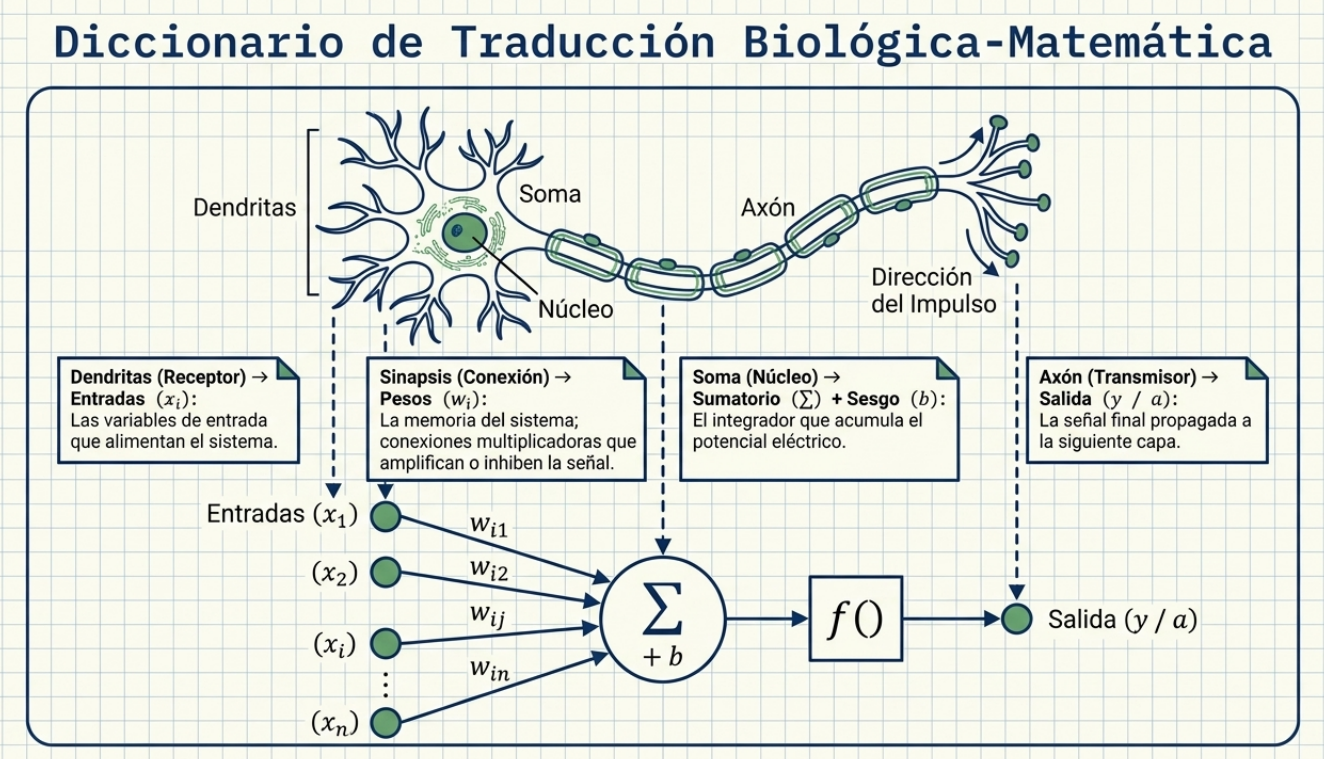
La paradoja del aprendizaje: cuando la memorización asfixia la inteligencia
Aprender en exceso es, a menudo, el camino más rápido hacia el fracaso. Este fenómeno, conocido como overfitting o sobreaprendizaje, ocurre cuando la red memoriza los datos de entrenamiento —incluyendo su ruido y errores— en lugar de comprender el patrón subyacente. Una red «sobreentrenada» es incapaz de generalizar ante datos nuevos, lo que la convierte en una herramienta inútil para la predicción real.
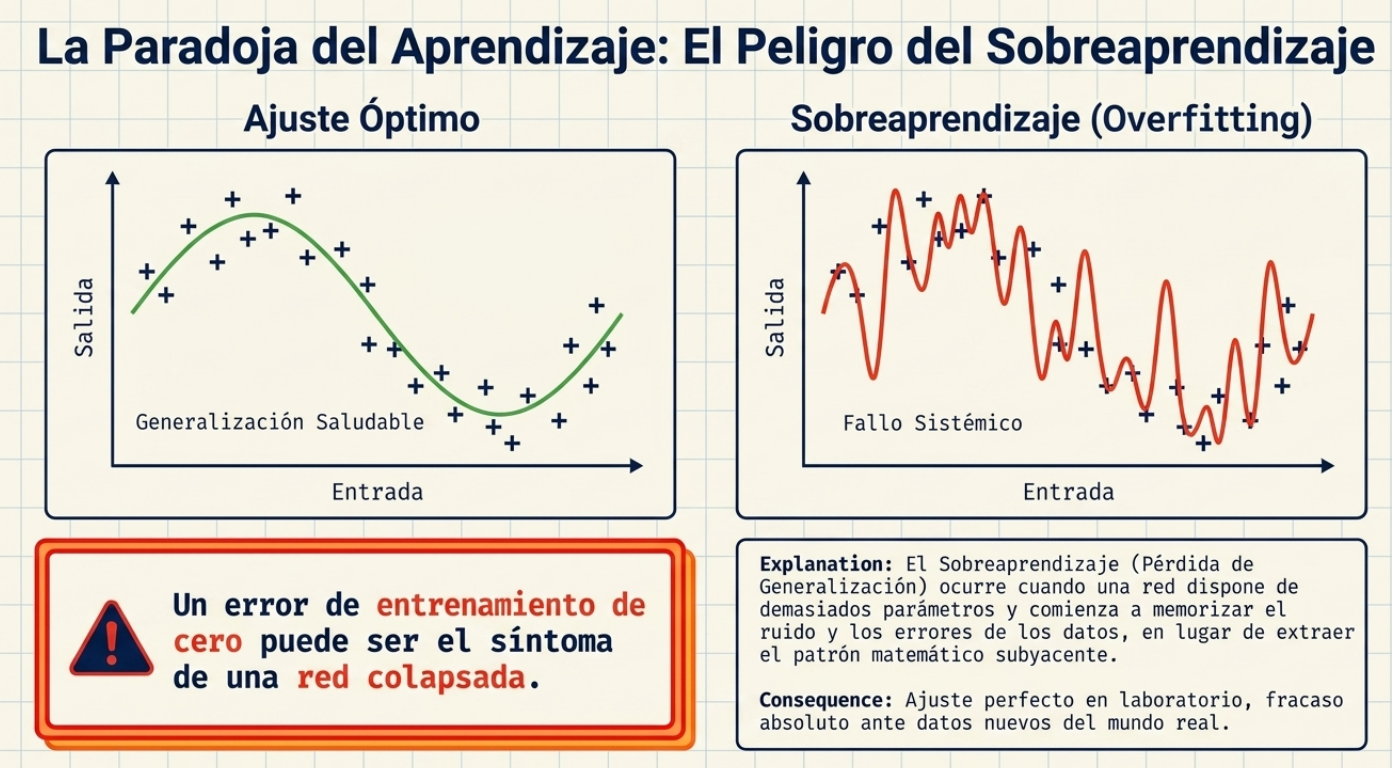
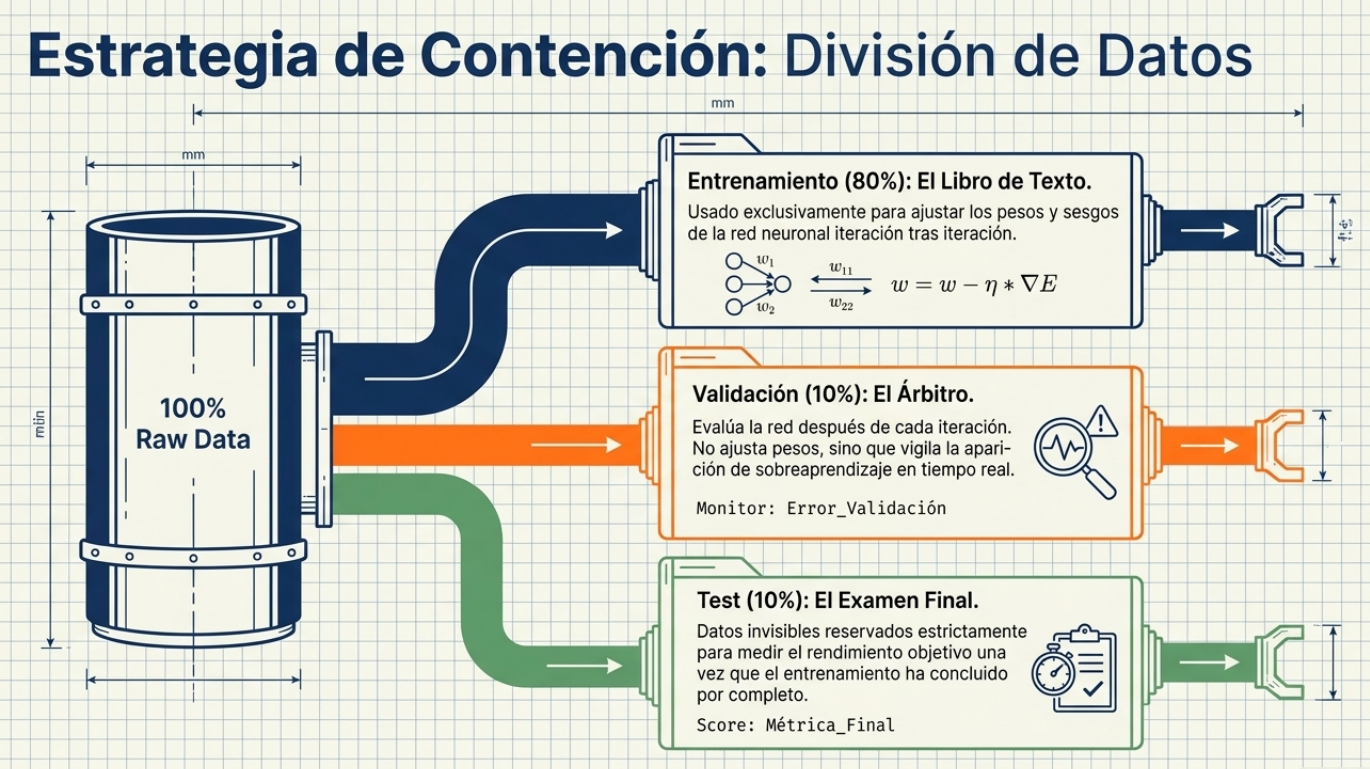
La solución de arquitectura más elegante es el early-stopping (parada temprana). Este proceso monitorea el error en un conjunto de validación y detiene el entrenamiento en el momento exacto en que el error comienza a aumentar, antes de que la red se vuelva demasiado rígida. Para garantizar el éxito, aplicamos la regla del 80/10/10:
- 80 % de entrenamiento: para ajustar pesos y sesgos.
- 10 % de validación: para detectar el punto óptimo de detención.
- 10 % de test: una evaluación final totalmente «ciega» para verificar la capacidad real del modelo.
La Navaja de Ockham en la IA: El poder de «podar» la red
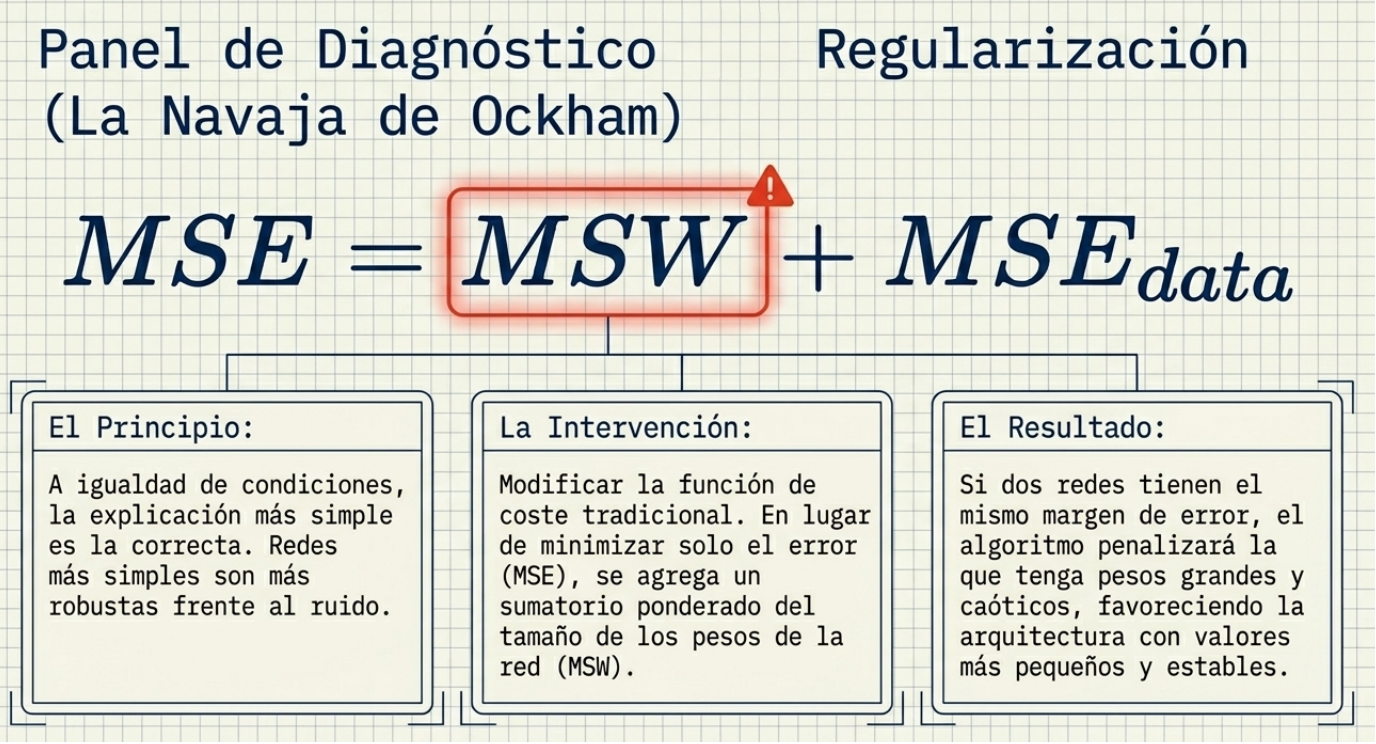
El principio de parsimonia sugiere que la explicación más simple suele ser la más acertada. En el diseño de redes, esto se traduce en redes podadas (pruned networks). Mediante la desconexión de neuronas redundantes o la eliminación de variables de entrada irrelevantes, logramos modelos más compactos y robustos.
Para guiar este proceso, utilizamos dos métricas críticas en la función de coste:
- MSE (Mean Squared Error): Su propósito conceptual es penalizar las diferencias entre el valor real y el calculado, elevándolas al cuadrado para dar prioridad matemática a la eliminación de los errores más grandes.
- PSE (Predicted Squared Error): Mientras que el MSE mide el error presente, el PSE penaliza activamente el número de parámetros de la red. Su fórmula, PSE = MSE \cdot (1 + 2p/(N-p)), asegura que no estemos añadiendo complejidad innecesaria, castigando los modelos con demasiados grados de libertad en relación con el número de datos disponibles.
El secreto está en la escala: por qué la estandarización es crucial
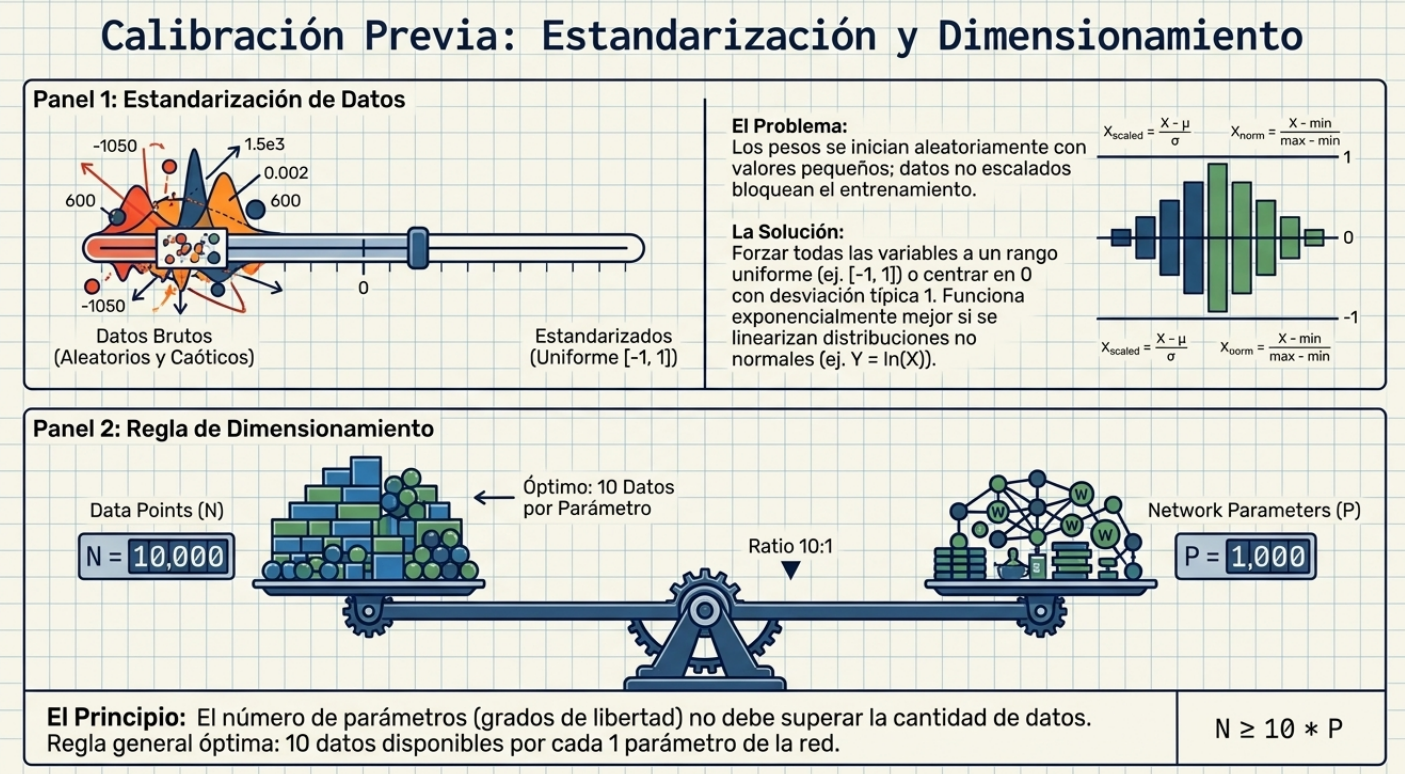
Aunque las redes neuronales son aproximadores universales, su entrenamiento puede resultar exasperantemente lento o fallar si no se cuida la escala de los datos. Los pesos de una red se inicializan con valores aleatorios pequeños; por ello, si las entradas son masivas, se producen errores iniciales gigantescos que saturan el sistema. Estandarizar los datos en rangos similares —como [-1, 1]— permite que el algoritmo de optimización converja con rapidez.
Además, si una variable presenta una distribución no lineal (como la exponencial), es imperativo linearizarla mediante logaritmos para facilitar el aprendizaje. No obstante, el mayor reto del arquitecto de IA es evitar los mínimos locales: soluciones subóptimas que parecen el fin del camino, pero no son el mejor resultado posible. La inicialización aleatoria y la estandarización son, en última instancia, estrategias para que la red «explore» el paisaje de soluciones sin quedar atrapada en los baches del error.
Conclusión: El laboratorio virtual y el futuro del diseño
Una red neuronal bien entrenada se convierte en un laboratorio virtual. En ingeniería, esto permite generar curvas de diseño de alta precisión; por ejemplo, podemos predecir el comportamiento del «rebase» de una estructura hidráulica al variar la «cota de coronación» mientras mantenemos constantes el resto de las variables. Esto nos ofrece una visión profunda de problemas complejos sin los costes de la experimentación física.
Sin embargo, nos enfrentamos a la naturaleza de «caja negra» de estos sistemas. Obtenemos soluciones perfectas, pero la lógica exacta tras miles de conexiones numéricas permanece oculta. Como sociedad tecnológica, nos acercamos a un umbral decisivo: ¿Estamos dispuestos a confiar plenamente en soluciones óptimas aunque no comprendamos exactamente el proceso intelectual que la red siguió para alcanzarlas? El futuro del diseño no solo depende de la potencia de cálculo, sino también de nuestra capacidad para convivir con esta nueva forma de inteligencia opaca pero infalible.
En esta conversación podéis escuchar las ideas más interesantes sobre estas redes neuronales.
Este vídeo resume bien los conceptos más importantes.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.