 ¿Te has detenido alguna vez a considerar por qué dos estudios sobre el mismo fenómeno pueden llegar a conclusiones diametralmente opuestas?
¿Te has detenido alguna vez a considerar por qué dos estudios sobre el mismo fenómeno pueden llegar a conclusiones diametralmente opuestas?
A menudo, la respuesta no se encuentra en un error de cálculo ni en la mala fe del investigador, sino en la estructura invisible que sustenta los datos. La estadística, lejos de ser un frío ejercicio de «contar» o promediar, es en realidad la aplicación de una lógica rigurosa y elegante conocida como diseño de experimentos.
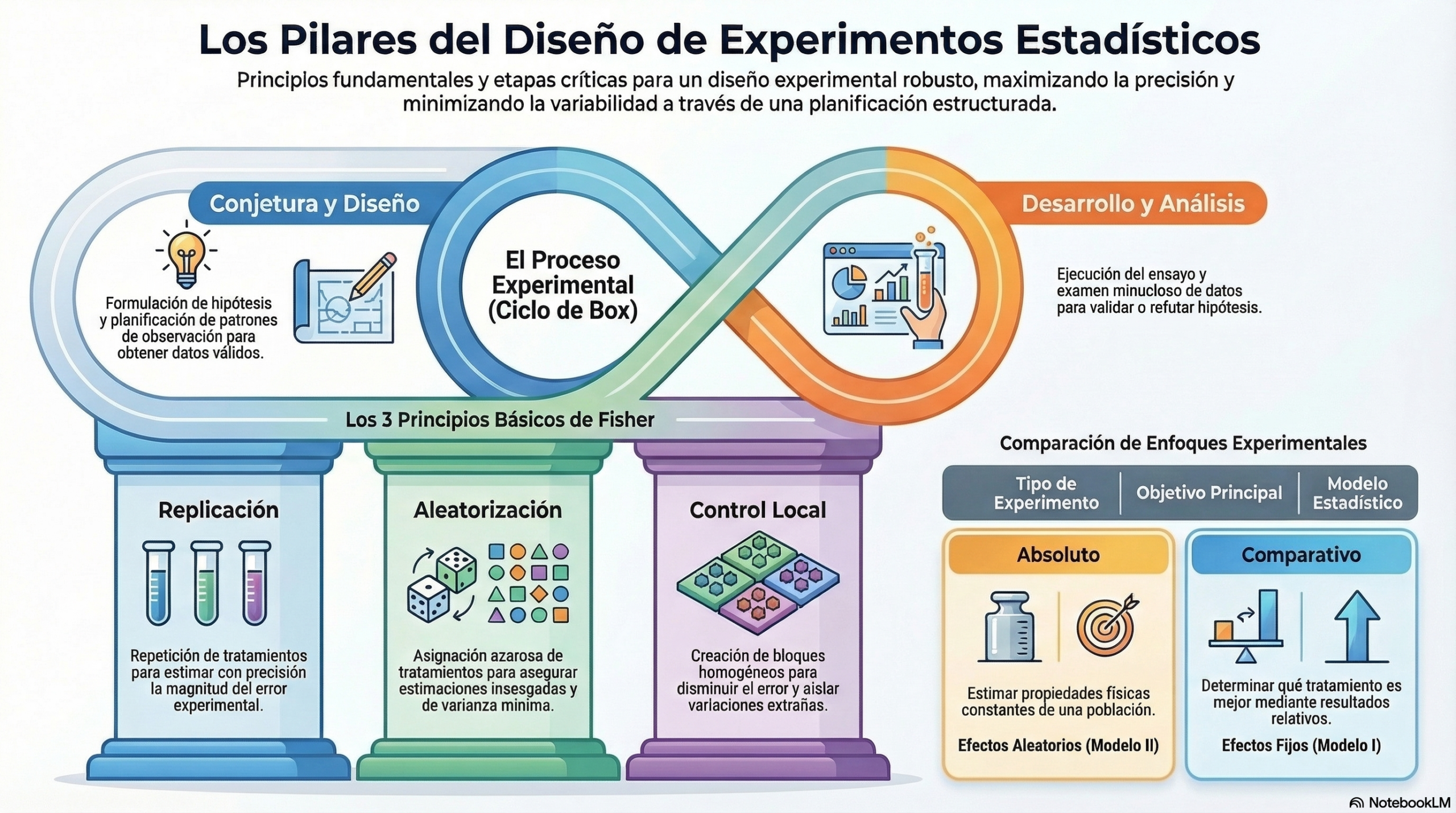
Como guía, mi objetivo es mostrarte que un experimento no es solo una observación, sino una prueba controlada en la que introducimos cambios deliberados para revelar verdades ocultas. Sin un diseño robusto, los números son solo ruido; con uno, se convierten en una herramienta de predicción capaz de silenciar la incertidumbre. Permíteme compartir contigo cinco pilares fundamentales que transformarán tu manera de interpretar la ciencia.
El conocimiento no es una línea recta, sino un círculo.
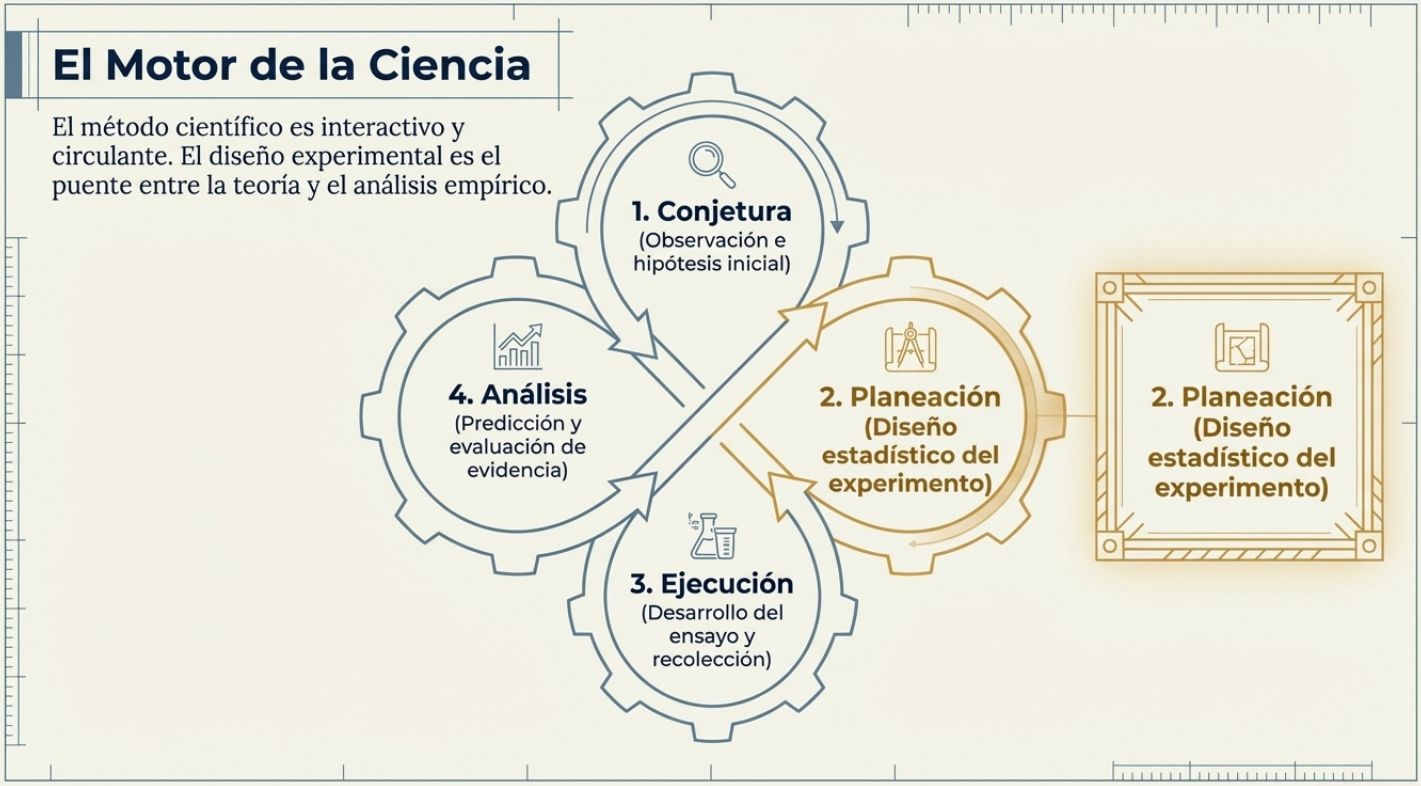
Tanto en la academia como en la industria, tendemos a ver el conocimiento como un monolito estático. Sin embargo, el método científico es circular e iterativo. Según Kempthorne (1952), la investigación es un ciclo perpetuo que se retroalimenta para aumentar la precisión.
Este proceso consta de cuatro etapas: la observación del fenómeno, la formulación de una teoría lógica, la predicción de eventos futuros y, por último, la toma de decisiones basada en pruebas. Pero aquí reside el secreto: el ciclo no termina ahí. Los resultados de la decisión modifican nuestras conjeturas originales y nos obligan a reiniciar el proceso. El objetivo no es solo repetir el experimento, sino aumentar nuestra capacidad de discriminación para distinguir con mayor claridad qué teorías son válidas y cuáles deben ser desechadas.
«El método científico no es estático; es de naturaleza circulante».
¿Por qué tu género no es un «tratamiento» (y por qué importa)?
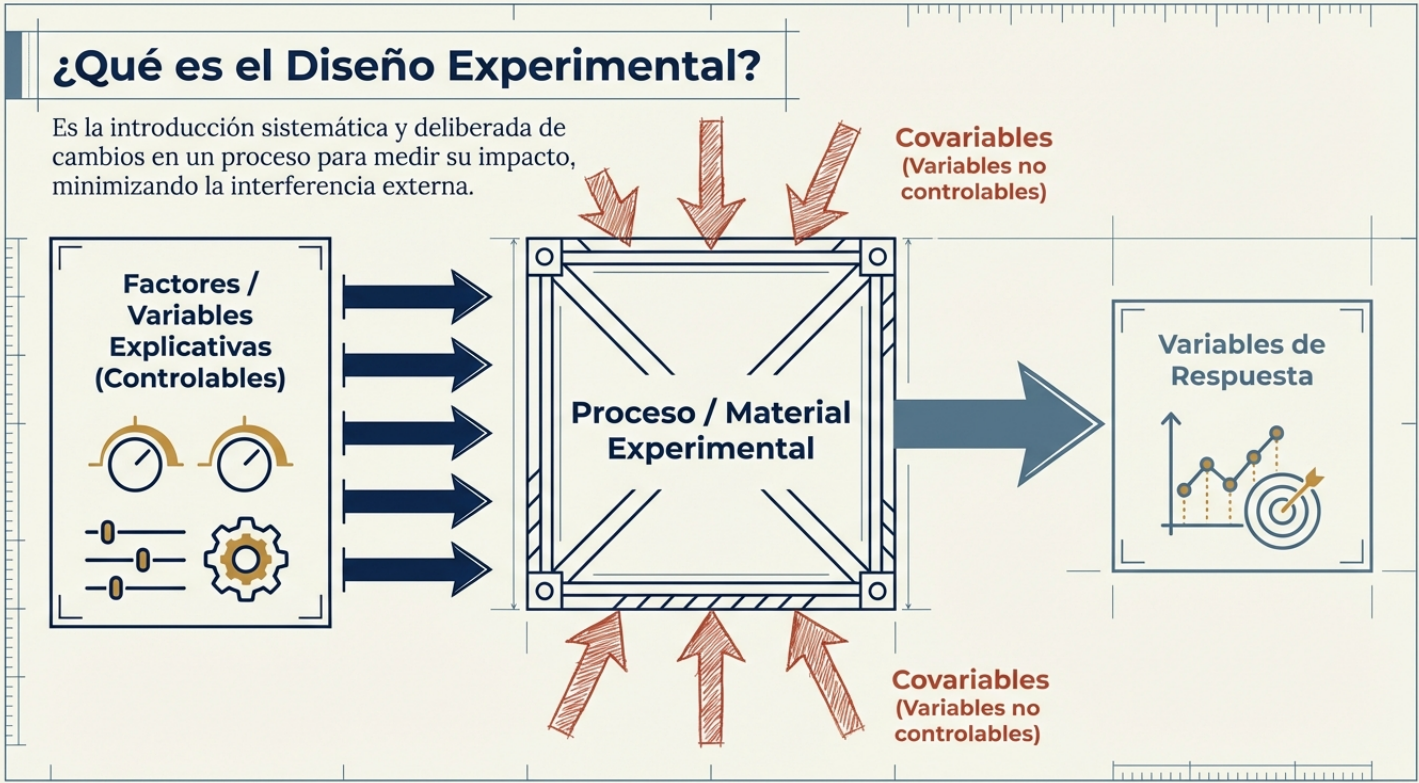
Uno de los conceptos más sutiles y cruciales que enseño a mis estudiantes es la distinción entre factores de tratamiento y de clasificación. Para que algo sea un «tratamiento», el investigador debe tener soberanía absoluta para asignar aleatoriamente dicho factor a las unidades de estudio.
Por ejemplo, un fármaco es un tratamiento porque el investigador decide quién lo recibe. En cambio, el género, el tipo de suelo o la especie de una madera son propiedades intrínsecas, denominadas factores de clasificación. No se puede «asignar» el género a un sujeto. Esta distinción es vital, ya que los factores de clasificación suelen actuar como fuentes extrañas de variación que, si no se identifican, pueden sesgar los resultados. Comprender que el género no es algo que «probamos», sino el contexto en el que lo probamos, es el primer paso hacia una inferencia honesta.
La unidad experimental: el arte de no medir lo que no debes.
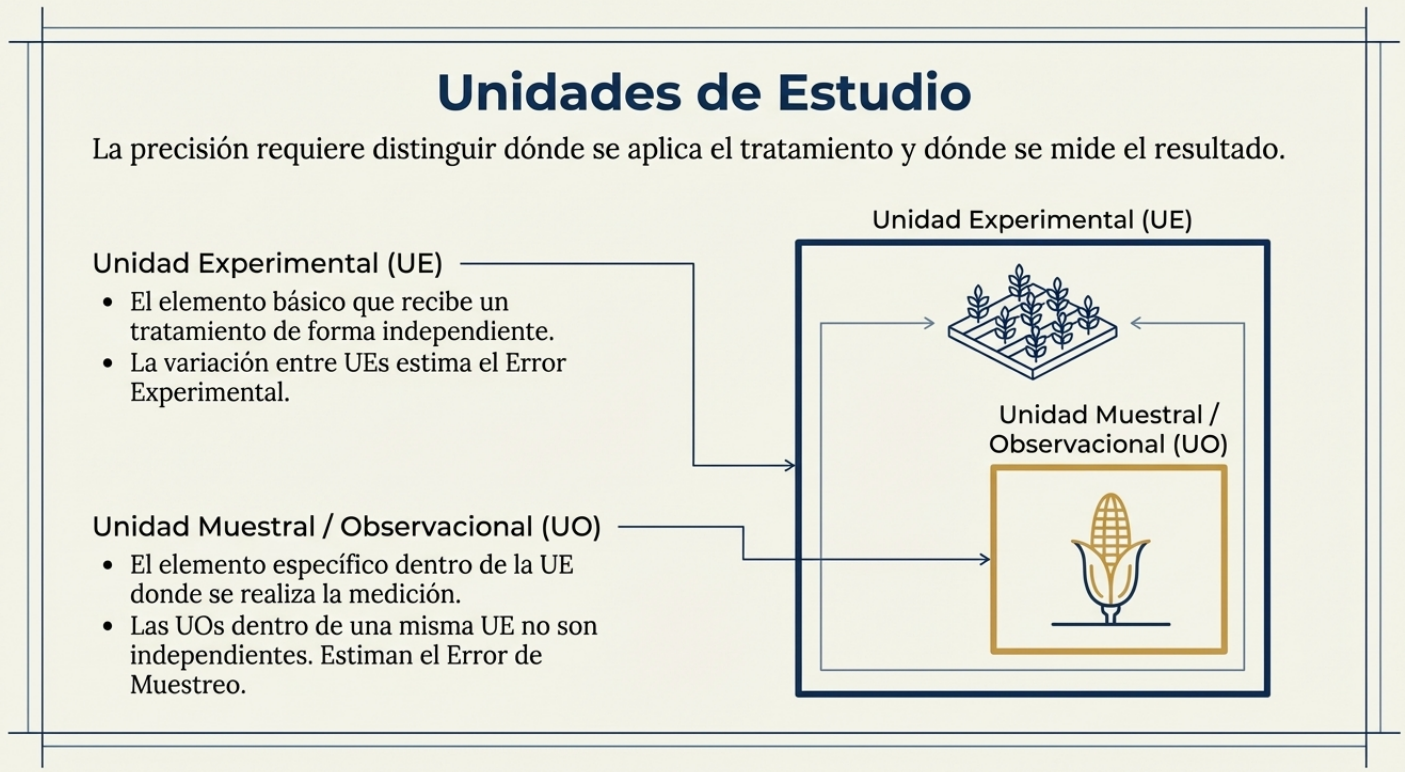
Existe un «espejismo estadístico» muy común: creer que medir muchas veces lo mismo aumenta la validez de un experimento. Para evitar este error, debemos distinguir entre la unidad experimental (UE) y la unidad muestral (UO).
- En el ámbito clínico, el paciente es la unidad experimental a la que se le asigna el tratamiento de forma independiente.
- En agricultura, una parcela completa es la UE, mientras que las plantas individuales dentro de ella son simples UO.
- En entomología, la UE puede referirse a un insecto, pero a menudo se refiere a la colonia entera como objeto de estudio.
- En estructuras, una viga de hormigón es la UE a la que se le aplica un método de curado específico, mientras que los diferentes sensores de deformación colocados en distintos puntos de esa misma viga actúan como unidades observacionales
El riesgo técnico consiste en confundir el error experimental (la variación entre distintas unidades experimentales) con el error de muestreo (la variación dentro de una misma unidad experimental). Si mide 50 plantas en una sola parcela, solo está reduciendo el error de muestreo. Para validar realmente un tratamiento y reducir el error experimental, se necesitan más parcelas independientes, no más plantas en la misma parcela. Medir lo que no debe solo aumenta artificialmente su confianza en un resultado que podría ser puramente aleatorio.
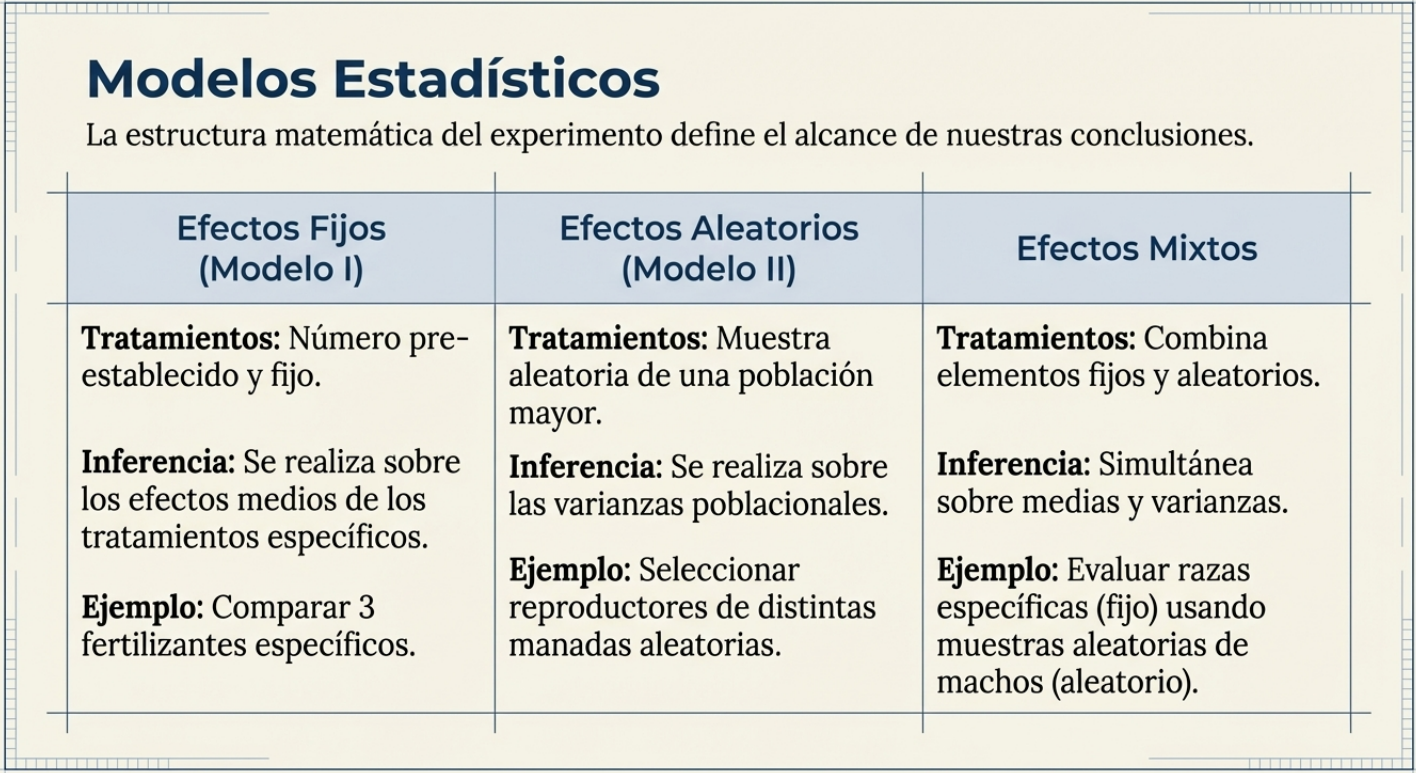
¿Busca conocimiento absoluto o quiere tomar una decisión?
No toda la ciencia busca lo mismo, por lo que saber qué tipo de experimento tiene delante cambiará su criterio. Anscombe (1947) nos legó una distinción fundamental:
- Experimentos absolutos: buscan determinar propiedades físicas constantes, como la velocidad de la luz. Se asocian a la ciencia pura y se rigen por el modelo II (efectos aleatorios), en el que los tratamientos se consideran una muestra de un universo infinito.
- Experimentos comparativos: son el corazón de las ciencias aplicadas y de la ingeniería. En estos casos, los valores absolutos pueden variar según el entorno, pero la relación entre los tratamientos permanece estable. Se rigen por el modelo I (efectos fijos), ya que el interés radica en determinar cuál de los tratamientos específicos es «mejor».
En el mundo de la gestión, casi siempre estamos ante experimentos comparativos. No buscamos una verdad universal e inmutable, sino la información necesaria para tomar una decisión administrativa acertada.
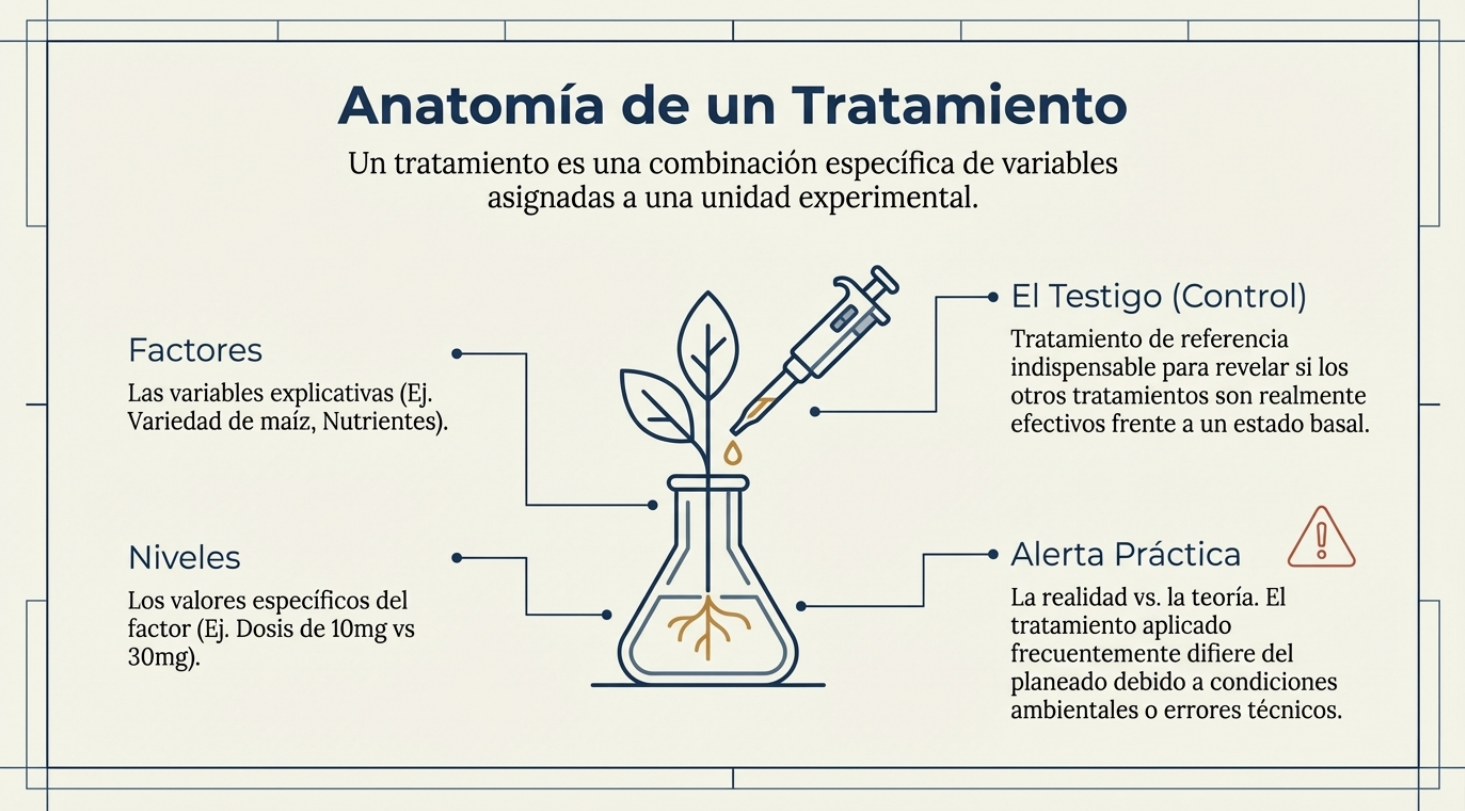
El «testigo»: el héroe invisible del control de variación.
A menudo se piensa que el tratamiento de control o de testigo es solo un requisito burocrático. Sin embargo, su función es lógica y profunda: es la única herramienta capaz de revelar si el entorno está «enmascarando» la realidad.
Imagine que intenta escuchar un susurro (el efecto de un nuevo fertilizante) en una habitación donde alguien está gritando (la alta fertilidad natural del suelo). Sin un testigo —una zona sin fertilizante—, se atribuiría el crecimiento de las plantas al producto, cuando en realidad sería el suelo quien haría todo el trabajo. El testigo es esencial cuando se desconoce la eficacia de lo que se prueba; es el punto de referencia que permite eliminar las interferencias del entorno y detectar la señal del tratamiento.
Conclusión: el diseño antes que el dato.
El diseño experimental es, en última instancia, el cálculo del grado de incertidumbre. Esto permite que la estadística trascienda la mera descripción de lo ocurrido y se convierta en una brújula predictiva. Un diseño robusto garantiza que las conclusiones tengan un rango de validez real y que los recursos, siempre limitados, no se malgasten en espejismos.
La próxima vez que te encuentres ante un informe con gráficos deslumbrantes, detente y reflexiona: ¿estos datos provienen de un diseño válido que controla la incertidumbre o son solo una colección de números que intentan ocultar la ausencia de una estructura lógica? Recuerda que, en ciencia, la calidad de tu respuesta nunca superará la del diseño de tu pregunta.
En esta conversación puedes escuchar una buena explicación sobre este tema.
El vídeo resume bien las ideas más importantes sobre el diseño de experimentos.
Experimental_Design_Foundations
Referencias:
Anscombe, F. J. (1947). The validity of comparative experiments. Journal of the Royal Statistical Society, 61, 181–211.
Box, G. E. P. (1952). Multi-factor designs of first order. Biometrika, 39(1), 49–57.
Fisher, R. A. (1935). The design of experiments. Oliver & Boyd.
Kempthorne, O. (1952). The design and analysis of experiments. John Wiley & Sons.
Melo, O. O., López, L. A., & Melo, S. E. (2007). Diseño de experimentos: métodos y aplicaciones. Universidad Nacional de Colombia, Facultad de Ciencias.

Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObraDerivada 4.0 Internacional.